标签:问题 python nbsp eth coding htm utf-8 class ima
1.因为人不可能一直无休止的学习,偶尔也想做点儿别的,昨天无聊就想写写Python,当然我承认我上班后基本都是在学工作方面的事情,在这个岗位我也呆了三年多了,还是那句话问我什么会不会我会给你说我啥都会,只是时间问题!好了不吐槽了,大家一起加油!直接给代码和结果。
2.程序代码:
# encoding:UTF-8
import re
from urllib import request
import gzip
def getHtml(url): #获取页面的源代码
page = request.urlopen(url)
html = page.read()
html = gzip.decompress(html)
html = html.decode(‘utf-8‘)
regall = r‘<td><b class="c_ba2636">.*</b>‘
balllist = re.findall(regall,html)
for i in balllist:
num = i[-17:-4]
print(i[-17:-4])
in_put = open(‘D:/爬虫/file‘, ‘a‘)
in_put.write(‘\n‘)
in_put.write(str(num))
in_put.close()
return num
print(getHtml(‘http://caipiao.163.com/award/qxc/‘))
3.结果
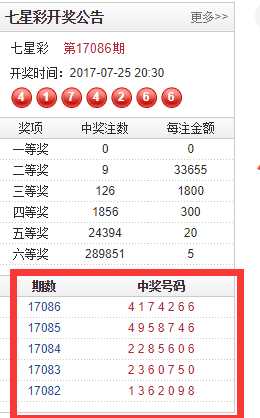
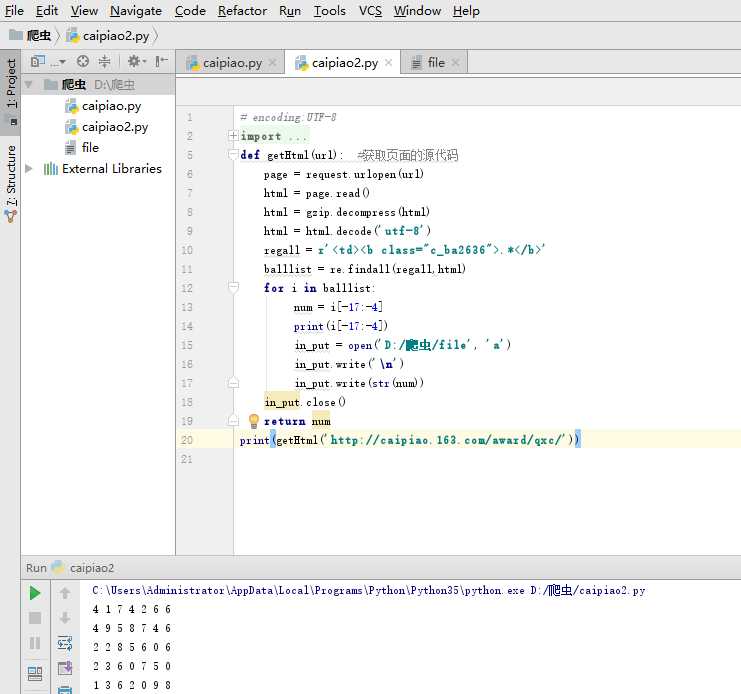
好不好玩,好玩!!!!!好玩就一起玩Python!
标签:问题 python nbsp eth coding htm utf-8 class ima
原文地址:http://www.cnblogs.com/Jt00/p/7244362.html