标签:字符串类型 关键词 建立 limit 缩进 表结构 一个 distinct 存在
sql是Structured Query Language(结构化查询语言)的缩写。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
使用这门语言只需告诉它"做什么"
SQL规范
<1> 在数据库系统中,SQL语句不区分大小写(建议用大写) 。但字符串常量区分大小写。建议命令大写,表名库名小写;
<2> SQL语句可单行或多行书写,以“;”结尾。关键词不能跨多行或简写。
<3> 用空格和缩进来提高语句的可读性。子句通常位于独立行,便于编辑,提高可读性。
SELECT * FROM tb_table
WHERE NAME="YUAN";
<4> 注释:单行注释:--
多行注释:/*......*/
<5>sql语句可以折行操作
<6> DDL,DML和DCL
-- --SQL中 DML、DDL、DCL区别 .
-- -- DML(data manipulation language):
-- 它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的
-- 数据进行操作的语言
--
-- -- DDL(data definition language):
-- DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)
-- 的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
--
-- -- DCL(Data Control Language):
-- 是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)
-- 语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权
-- 力执行DCL
RDBMS术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
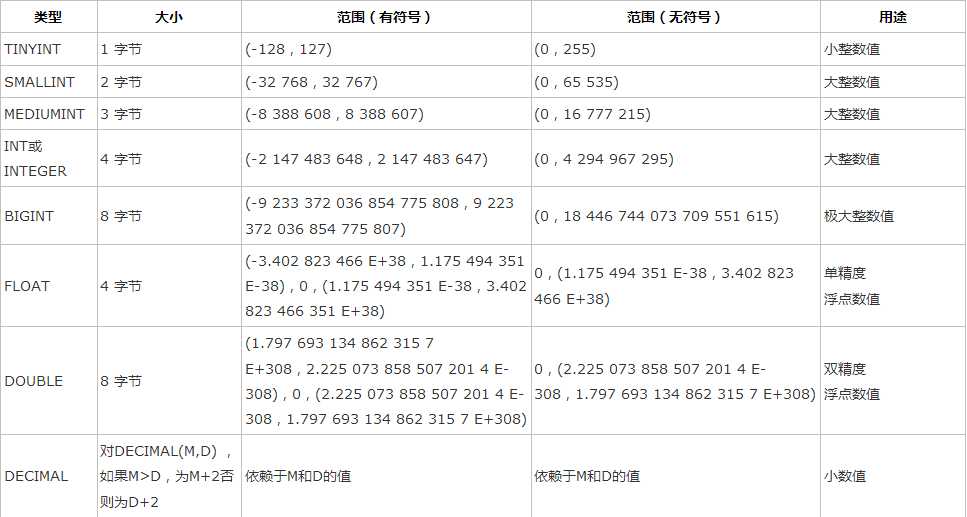
数字类型
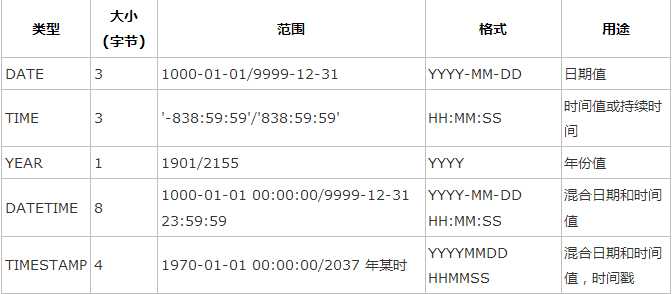
日期和时间类型
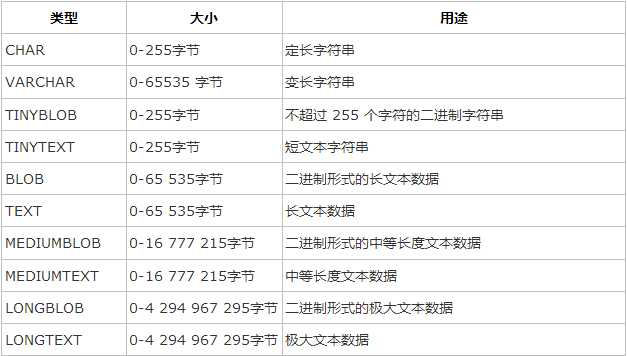
字符串类型
基础的sql数据库操作指令
-- 1.创建数据库(在磁盘上创建一个对应的文件夹)
create database [if not exists] db_name [character set xxx]
-- 2.查看数据库
show databases;查看所有数据库
show create database db_name; 查看数据库的创建方式
-- 3.修改数据库
alter database db_name [character set xxx]
-- 4.删除数据库
drop database [if exists] db_name;
-- 5.使用数据库
切换数据库 use db_name; -- 注意:进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换
查看当前使用的数据库 select database();
数据表的增删改查
创建表
-- 语法
create table tab_name(
f1 type[约束条件],
f2 type[约束条件],
)[charater set utf8]; --可设置字符编码或引擎
/* 约束:
primary key (非空且唯一) :能够唯一区分出当前记录的字段称为主键!
unique
not null
auto_increment :用于主键字段,主键字段必须是数字类型
*/
查看表信息
desc tab_name --查看表结构
show columns from --tab_name 查看表结构
show tables --查看当前数据库中的所有的表
show create table tab_name --查看当前数据库表建表语句
修改表结构
-- (1)增加列(字段)
alter table tab_name add [column] 列名 类型[完整性约束条件][first|after 字段名];
alter table user add addr varchar(20) not null unique first/after username;
#添加多个字段
alter table users2
add addr varchar(20),
add age int first,
add birth varchar(20) after name;
-- (2)修改一列类型
alter table tab_name modify 列名 类型 [完整性约束条件][first|after 字段名];
alter table users2 modify age tinyint default 20;
alter table users2 modify age int after id;
-- (3)修改列名
alter table tab_name change [column] 列名 新列名 类型 [完整性约束条件][first|after 字段名];
alter table users2 change age Age int default 28 first;
-- (4)删除一列
alter table tab_name drop [column] 列名;
-- 思考:删除多列呢?删一个填一个呢?
alter table users2
add salary float(6,2) unsigned not null after name,
drop addr;
-- (5)修改表名
rename table 表名 to 新表名;
-- (6)修该表所用的字符集
alter table student character set utf8;
删除表
drop table tab_name;
表记录的增删改查
增加表记录
/*
#列与值要严格对应
数字和字符串的注意点
数字不必加单引号,字符串必须加单引号
*/
<1>插入一条记录:
insert [into] tab_name (field1,filed2,.......) values (value1,value2,.......);
<2>插入多条记录:
insert [into] tab_name (field1,filed2,.......) values (value1,value2,.......),
(value1,value2,.......)
... ;
<3>set插入:
insert [into] tab_name set 字段名=值
示例:insert into employee_new set id=12,name="alvin3";
修改表记录
/*
update 操作
改哪张表?
你需要给改哪几列的值?
分别改为什么值?
在哪些行生效
*/
update tab_name set field1=value1,field2=value2,......[where 语句]
/* UPDATE语法可以用新值更新原有表行中的各列。
SET子句指示要修改哪些列和要给予哪些值。
WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。*/
update employee_new set birthday="1989-10-24" WHERE id=1;
--- 将yuan的薪水在原有基础上增加1000元。
update employee_new set salary=salary+4000 where name=‘yuan‘;
删除表记录
语法 delete from tab_name [where ....]
/*
delete 操作
你要删除哪些表的数据
你要删除哪些行
delete from user where uid=4 #删除uid=4的行
delete from user; #删除全部
#删除整表
truncate table t; 删除整表
*/
/*
如果不跟where语句则删除整张表中的数据
delete只能用来删除一行记录
delete语句只能删除表中的内容,不能删除表本身,想要删除表,用drop
TRUNCATE TABLE也可以删除表中的所有数据,词语句首先摧毁表,再新建表。此种方式删除的数据不能在
事务中恢复。*/
-- 删除表中名称为’alex’的记录。
delete from employee_new where name=‘alex‘;
-- 删除表中所有记录。
delete from employee_new;-- 注意auto_increment没有被重置:alter table employee auto_increment=1;
-- 使用truncate删除表中记录。
truncate table emp_new;
查询表记录
/*
查哪张表的数据
你要选择哪些列来查询
要选择哪些行
*/
-- 查询语法:
SELECT *|field1,filed2 ... FROM tab_name
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
select 查询模型
select 查询模型(重要)
列是变量
变量可以计算
where是表达式,值为真假
select * from ExamResult where 1; #判断为真,取出user表的所有
select * from ExamResult where 0; #所有都不取出因为条件是假
select uid,name,age+1 from ExamResult where 1; #这些字段可以看作变量所以可以计算
奇怪的NULL
select * from ExamResult;
select * from ExamResult where name=‘liubei‘;
select * from ExamResult where name=NULL;
select ** from ExamResult where name != NULL;
select null=NULL; #这个判断条件是假
select * from ExamResult where name is null; #查看null表
select * from ExamResult where name is not null;
准备表和记录
---准备表
CREATE TABLE ExamResult(
id INT PRIMARY KEY auto_increment,
name VARCHAR (20),
JS DOUBLE ,
Django DOUBLE ,
OpenStack DOUBLE
);
---插入数据
INSERT INTO ExamResult VALUES (1,"yuan",98,98,98),
(2,"xialv",35,98,67),
(3,"alex",59,59,62),
(4,"wusir",88,89,82),
(5,"alvin",88,98,67),
(6,"yuan",86,100,55);
简单查询
-- (1)select [distinct] *|field1,field2,...... from tab_name
-- 其中from指定从哪张表筛选,*表示查找所有列,也可以指定一个列
-- 表明确指定要查找的列,distinct用来剔除重复行。
-- 查询表中所有学生的信息。
select * from ExamResult;
-- 查询表中所有学生的姓名和对应的英语成绩。
select name,JS ,name from ExamResu
from ExamResult; -- 过滤表中重复数据。 select distinct JS ,name from ExamResult;
-- (2)select 也可以使用表达式,并且可以使用: 字段 as 别名或者:字段 别名
-- 在所有学生分数上加10分特长分显示。select name,JS+10,Django+10,OpenStack+10 from ExamResult; -- 统计每个学生的总分。 select name,JS+Django+OpenStack from ExamResult; -- 使用别名表示学生总分。 select name as 姓名,JS+Django+OpenStack as 总成绩 from ExamResult; select name,JS+Django+OpenStack 总成绩 from ExamResult; select name JS from ExamResult; -- what will happen?---->记得加逗号
select name,JS+10,Django+10,OpenStack+10 from ExamResult;
-- 统计每个学生的总分。
select name,JS+Django+OpenStack from ExamResult;
-- 使用别名表示学生总分。
select name as 姓名,JS+Django+OpenStack as 总成绩 from ExamResult;
select name,JS+Django+OpenStack 总成绩 from ExamResult;
select name JS from ExamResult; -- what will happen?---->记得加逗号
使用where子句,进行过滤查询
-- 查询姓名为XXX的学生成绩
select * from ExamResult where name=‘yuan‘;
-- 查询英语成绩大于90分的同学
select id,name,JS from ExamResult where JS>90;
-- 查询总分大于200分的所有同学
select name,JS+Django+OpenStack as 总成绩 from
ExamResult where JS+Django+OpenStack>200 ;
-- where字句中可以使用:
-- 比较运算符:
> < >= <= <> !=
between 80 and 100 值在10到20之间
in(80,90,100) 值是10或20或30
like ‘yuan%‘
/*
pattern可以是%或者_,
如果是%则表示任意多字符,此例如唐僧,唐国强
如果是_则表示一个字符唐_,只有唐僧符合。两个_则表示两个字符:__
*/
-- 逻辑运算符
在多个条件直接可以使用逻辑运算符 and or not
order by排序
指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的别名。
-- select *|field1,field2... from tab_name order by field [Asc|Desc]
-- Asc 升序、Desc 降序,其中asc为默认值 ORDER BY 子句应位于SELECT语句的结尾。
-- 练习:
-- 对JS成绩排序后输出。
select * from ExamResult order by JS;
-- 对总分排序按从高到低的顺序输出
select name ,(ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0))
总成绩 from ExamResult order by 总成绩 desc;
-- 对姓李的学生成绩排序输出
select name ,(ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))
总成绩 from ExamResult where name like ‘a%‘
order by 总成绩 desc;
标签:字符串类型 关键词 建立 limit 缩进 表结构 一个 distinct 存在
原文地址:http://www.cnblogs.com/songcheng/p/7252382.html