标签:style blog http color os io 使用 java strong
声明:本文题目来源于互联网,仅供即将从学校毕业的.Net码农(当然,我本人也是菜逼一个)学习之用。当然,学习了这些题目不一定会拿到offer,但是针对就业求职做些针对性的准备也是不错的。此外,除了技术上的准备外,要想得到提升,还得深入内部原理,阅读一些经典书籍(例如Jeffrey Richter的《CLR via C#》)以及借助Reflector或ILSpy反编译查看源码实现,知其然也知其所以然,方能得到感性认识到理性认识的飞跃!另外,本来想将本文标题取为就业求职宝典,但一想这名字太LOW了,而且太过浮华了,本文也根本达不到那个目标,于是将其改为储备,简洁明了。
注意:这里仅写出了最基本的js代码,至于什么二次封装和重构各位可以自行解决;
function ajax(method, url, callback) { var xhr = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xhr.open(method, url, true); xhr.onreadystatechange = function () { if (xhr.readyState == 4 && xhr.status == 200) { var result = xhr.responseText; callback(result); } } xhr.send(); }
这里主要理解记忆为四个步凑即可:
(1)创建XMLHttpRequest对象:如果你足够细心,还可以考虑一下各主流浏览器的兼容性;
(2)建立与服务器端的连接:借助open方法,GET还是POST?服务页面地址是?异步还是同步?
(3)设置响应完成后的回调函数:注意条件是readyState=4且status=200的情况下,下面给出了这些条件的具体含义
|
属性 |
描述 |
|
onreadystatechange |
每次状态改变所触发事件的事件处理程序 |
|
readyState |
对象状态值:
|
|
responseText |
从服务器进程返回的数据的字符串形式 |
|
responseXML |
从服务器进程返回的DOM兼容的文档数据对象 |
|
status |
从服务器返回的数字代码,比如404(未找到)或200(就绪) |
|
statusText |
伴随状态码的字符串信息 |
(4)最后正式发送请求:最后一步才是正式的发送此次Ajax请求,调用send方法;
PS:可以看看上面这段js方法具体如何应用的
 View Code<script type="text/javascript"> function getServerTime() { ajax("GET", "AjaxHandler.ashx?action=gettime", afterSuccess); } function afterSuccess(data) { if (data != null) { document.getElementById("spTime").innerHTML = data; } } function ajax(method, url, callback) { var xhr = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xhr.open(method, url, true); xhr.onreadystatechange = function () { if (xhr.readyState == 4 && xhr.status == 200) { var result = xhr.responseText; callback(result); } } xhr.send(); } </script> </head> <body> <div align="center"> <input id="btnAjax" type="button" value="Get Server Time" onclick="getServerTime()" /> <br /> <span id="spTime" style="font-weight:bold;"></span> </div> </body>
View Code<script type="text/javascript"> function getServerTime() { ajax("GET", "AjaxHandler.ashx?action=gettime", afterSuccess); } function afterSuccess(data) { if (data != null) { document.getElementById("spTime").innerHTML = data; } } function ajax(method, url, callback) { var xhr = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xhr.open(method, url, true); xhr.onreadystatechange = function () { if (xhr.readyState == 4 && xhr.status == 200) { var result = xhr.responseText; callback(result); } } xhr.send(); } </script> </head> <body> <div align="center"> <input id="btnAjax" type="button" value="Get Server Time" onclick="getServerTime()" /> <br /> <span id="spTime" style="font-weight:bold;"></span> </div> </body>
1.2 基本排序算法:冒泡排序与快速排序
(1)基本概念
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
下图是一个经典的冒泡排序过程图,可以看出,在排序过程中,大的记录像石头一样“沉底”,小的记录逐渐向上“浮动”,冒泡排序的名字也由此而来。

图1 冒泡排序过程模拟
(2)算法过程
①比较相邻的元素。如果第一个比第二个大,就交换他们两个。
②对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
③针对所有的元素重复以上的步骤,除了最后一个。
④持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
(3)代码实现
public static void BubbleSort(int[] array) { int temp; bool flag; for (int i = array.Length - 1; i >= 1; i--) { flag = false; for (int j = 1; j <= i; j++) { if (array[j - 1] > array[j]) { temp = array[j - 1]; array[j - 1] = array[j]; array[j] = temp; flag = true; } } if (!flag) { return; } } }
这里为什么要借助flag标志位来判断?因为如果在一趟排序中没有发生元素交换,那么数组中的数据都已经有序了,这时就无需再继续比较了,这也是冒泡排序算法结束的条件。
(4)测试结果
①这里首先使用一个包含10000个(本来想再对10万个,100万个进行测试,但是太懒了,所以...)随机数的int数组简单进行了五次测试,平均耗时每次812ms。
public static void BubbleSortDemo() { int maxSize = 10000; int[] array = new int[maxSize]; Random random = new Random(); for (int i = 0; i < maxSize; i++) { array[i] = random.Next(1, 10001); } Console.WriteLine("Before Bubble Sort:"); SortHelper.PrintArray(array); Stopwatch watcher = new Stopwatch(); watcher.Start(); SortHelper.BubbleSort(array); watcher.Stop(); Console.WriteLine("------------------------------------------------------------"); Console.WriteLine("After Bubble Sort:"); SortHelper.PrintArray(array); Console.WriteLine("Total Elapsed Milliseconds:{0}ms", watcher.ElapsedMilliseconds); }
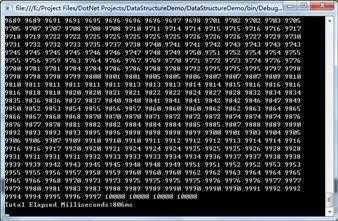
②这里再使用一个包含10000个有序数据的int数组进行几次测试,发现平均耗时均为0ms。
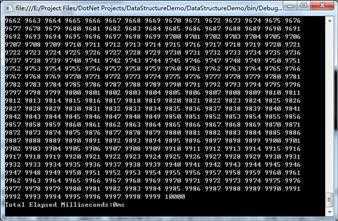
(5)复杂度分析
①时间复杂度
若待排序文件的初始状态是正序的,一趟扫描即可完成排序(这里也解释了我们为什么刚刚在代码中设置一个flag标志)。所需的关键字比较次数C和记录移动次数M均达到最小值: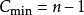 ,
,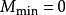 。所以,冒泡排序最好的时间复杂度为
。所以,冒泡排序最好的时间复杂度为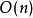 。
。
若待排序文件是反序的,需要进行 n - 1 趟排序。每趟排序要进行 n - i 次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
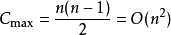
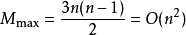
所以,冒泡排序的最坏时间复杂度为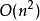 。
。
综上所述,冒泡排序总的平均时间复杂度为。
②空间复杂度
由算法代码可以清晰地看出,额外的辅助空间只有一个temp,因此空间复杂度为O(1)。
(1)基本概念
快速排序(Quick Sort)是对冒泡排序的一种改进,由C. A. R. Hoare在1962年提出。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
(2)算法过程
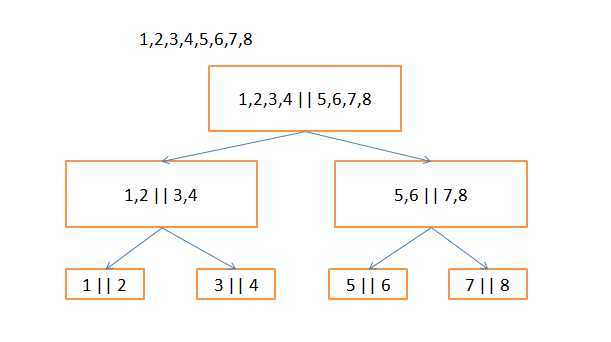
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。具体步骤为:
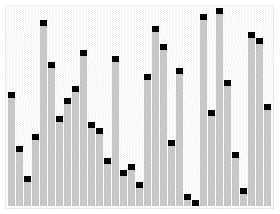
图2 快速排序过程模拟
(3)代码实现
public static void QuickSort(int[] array, int low, int high) { if (low < high) { int index = Partition(array, low, high); QuickSort(array, low, index - 1); QuickSort(array, index + 1, high); } } public static int Partition(int[] array, int low, int high) { int i = low; int j = high; int temp = array[low]; while (i != j) { // 先判断右半部分是否有小于temp的数,如果有则交换到array[i] while (i < j && temp < array[j]) { j--; } if (i < j) { array[i++] = array[j]; } // 在判断左半部分是否有大于temp的数,如果有则交换到array[j] while (i < j && temp > array[i]) { i++; } if (i < j) { array[j--] = array[i]; } } array[i] = temp; return i; }
(4)测试结果
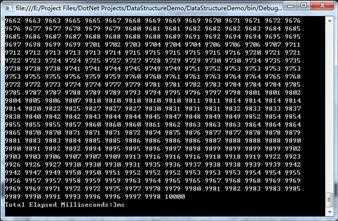
①这里仍然使用一个包含10000个随机数的int数组简单进行了五次测试,平均耗时每次3ms。相比冒泡排序的平均耗时800+ms,快速排序果然名不虚传,快的不是一点半点啊!
public static void QuickSortDemo() { int maxSize = 10000; int[] array = new int[maxSize]; Random random = new Random(); for (int i = 0; i < maxSize; i++) { array[i] = random.Next(1, 10001); } Console.WriteLine("Before Quick Sort:"); NewSortHelper.PrintArray(array); Stopwatch watcher = new Stopwatch(); watcher.Start(); NewSortHelper.RecursiveQuickSort(array, 0, array.Length - 1); watcher.Stop(); Console.WriteLine("------------------------------------------------------------"); Console.WriteLine("After Quick Sort:"); NewSortHelper.PrintArray(array); Console.WriteLine("Total Elapsed Milliseconds:{0}ms", watcher.ElapsedMilliseconds); }
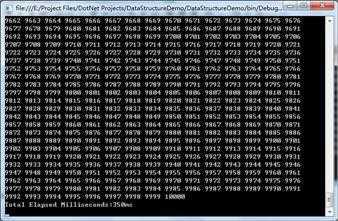
②同样,这里再使用一个包含10000个有序数据的int数组进行五次测试,发现平均耗时为343ms。这里也可以跟冒泡排序在此种情形下的耗时进行对比,发现快排在接近有序的情景时弱爆了。
(5)复杂度分析
①时间复杂度:
快速排序的时间主要耗费在划分(Partition)操作上,对长度为k的区间进行划分,共需k-1次关键字的比较。
假设有1到8代表要排序的数,快速排序会递归log(8)=3次,每次对n个数进行一次处理,所以他的时间复杂度为n*log n即O(n log n)。所以排序问题的时间复杂度可以认为是对排序数据的总的操作次数。
但是,比如一个序列5,4,3,2,1,要排为1,2,3,4,5。按照快速排序方法,每次只会有一个数据进入正确顺序,无法把数据分成大小相当的两份,很明显,排序的过程就成了一个歪脖子树,树的深度为n,那时间复杂度就成了O(n2)。这也就解释了为什么在刚刚的第二次有序数据测试时,快排仍然需要耗费一些时间了。
尽管快速排序的最坏时间为O(n2),但就平均性能而言,它是基于关键字比较的内部排序算法中速度最快者,快速排序亦因此而得名。它的平均时间复杂度为O(n log n)。
②空间复杂度:
这里快速排序是以递归形式进行的,而递归又需要栈的辅助,因此它所需要的辅助空间比冒泡排序多,因此其空间复杂度为O(log n)。这里可以看出,快速排序是典型的以空间换时间的经典案例。
顺序查找是一种最基本最简单的查找方法,它的基本思路是:从表的一段开始,顺序扫描线性表,依次将扫描到的关键字与给定值K进行比较,若比较相等,则查找成功;若扫描结束后,仍未发现关键字等于K的记录,则查找失败。
其代码实现也很简单:
public static int SimpleSearch(int[] array, int key) { int result = -1; for (int i = 0; i < array.Length; i++) { if (array[i] == key) { result = i + 1; break; } } return result; }
优点:最简单,对元素排列次序无要求,插入新元素方便。
缺点:速度慢,平均查找长度为(n+…+2+1)/n=(n+1)/2,约为表长度一半。
二分查找又称折半查找,它首先要求线性表是有序的,即表中记录按关键字有序(比如:递增有序或递减有序)。
其基本思路是:设有序表A[0]~A[n-1]
①首先取中点元素A[mid]的关键字同给定值K进行比较,若相等则查找成功;否则,若K< A[mid].key,则在左子表中继续进行二分查找;若K> A[mid].key,则在右子表中继续进行二分查找;
②这样,经过一次比较,就缩小一半查找空间,如此进行下去,直到查找成功,或者当前查找区间为空时为止(或区间的下界大于等于上界时为止)。
通过基本思路写出代码实现:
public static int BinarySearch(int[] array, int key) { int low = 0; int high = array.Length - 1; int mid = -1; while (low <= high) { mid = (low + high) / 2; if (array[mid] > key) { high = mid - 1; } else if (array[mid] < key) { low = mid + 1; } else { return mid + 1; } } return -1; }
通过以上的分析,我们也可以方便地得出其优缺点如下:
优点:时间复杂度为O(logn),查找速度快。
缺点:需要建立有序表,并且插入和删除会比较麻烦。另外,只适用于顺序存储的有序表,不适用于链接存储的有序表。
这里可以阅读Terry Lee的设计模式系列来理解学习一下
.NET设计模式(2):单件模式(Singleton Pattern)
http://terrylee.cnblogs.com/archive/2005/12/09/293509.html
.NET设计模式(3):抽象工厂模式(Abstract Factory)
http://terrylee.cnblogs.com/archive/2005/12/13/295965.html
.NET设计模式(19):观察者模式(Observer Pattern)
http://www.cnblogs.com/Terrylee/archive/2006/10/23/Observer_Pattern.html
.NET设计模式(10):装饰模式(Decorator Pattern)
http://terrylee.cnblogs.com/archive/2006/03/01/340592.html
.NET设计模式(8):适配器模式(Adapter Pattern)
http://terrylee.cnblogs.com/archive/2006/02/18/333000.html
假设数据库有一张Student表,其中有四个字段:S#-学号,Sname-姓名,Sage-年龄,Ssex-性别;我们先新增一个页面,取名为AdoNetDemo,html中不添加任何内容;在.cs文件中,写入以下代码,通过ADO.Net访问数据库,并将性别为男生的学生信息输出到页面中;
public partial class AdoNetDemo : System.Web.UI.Page { protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { BindDataInfos(); } } private void BindDataInfos() { string connstr = ConfigurationManager.ConnectionStrings["connStr"].ConnectionString; using (SqlConnection con = new SqlConnection(connstr)) { con.Open(); using (SqlCommand cmd = con.CreateCommand()) { cmd.CommandText = "select * from Student where Ssex=@sex"; cmd.Parameters.Add(new SqlParameter("@sex", "男")); using(SqlDataAdapter adapter = new SqlDataAdapter(cmd)) { DataTable dt = new DataTable(); adapter.Fill(dt); if(dt != null) { foreach(DataRow row in dt.Rows) { Response.Write(string.Format("学号:{0},姓名:{1},年龄:{2}</br>", row["S#"].ToString(), row["Sname"].ToString(), row["Sage"].ToString())); } } } } } } }
这里主要是看BindDataInfos这个方法,借助ADO.Net中最基本的几个对象(Connection、Command、Adapter等)实现对指定数据库表的访问,并将其取出放到DataTable中,再根据指定格式输出到页面中。这里使用了using语句,其实质是帮我们自动生成try-finally,在离开using语句块后会自动调用Dispose方法释放资源,因为像Connection、Command这种对象是非托管资源,GC无法对其进行自动回收。
这里封装了一个最基本的SQLHelper,实现了ExecuteNonQuery、ExecuteScalar、ExecuteDataTable,以及对Object类写了两个扩展方法,用于在C#类型和数据库类型之间的转换。
public static class MsSqlHelper { public static readonly string connstr = ConfigurationManager.ConnectionStrings["connStr"].ConnectionString; #region 00.OpenConnection public static SqlConnection OpenConnection() { SqlConnection con = new SqlConnection(connstr); con.Open(); return con; } #endregion #region 01.ExecuteNonQuery public static int ExecuteNonQuery(string cmdText, params SqlParameter[] parameters) { using (SqlConnection con = new SqlConnection(connstr)) { con.Open(); return ExecuteNonQuery(con, cmdText, parameters); } } public static int ExecuteNonQuery(SqlConnection con, string cmdText, params SqlParameter[] parameters) { using (SqlCommand cmd = con.CreateCommand()) { cmd.CommandText = cmdText; cmd.Parameters.AddRange(parameters); int result = cmd.ExecuteNonQuery(); return result; } } #endregion #region 03.ExecuteScalar public static object ExecuteScalar(string cmdText, params SqlParameter[] parameters) { using (SqlConnection con = new SqlConnection(connstr)) { con.Open(); return ExecuteScalar(con, cmdText, parameters); } } public static object ExecuteScalar(SqlConnection con, string cmdText, params SqlParameter[] parameters) { using (SqlCommand cmd = con.CreateCommand()) { cmd.CommandText = cmdText; cmd.Parameters.AddRange(parameters); object result = cmd.ExecuteScalar(); return result; } } #endregion #region 04.ExecuteDataTable public static DataTable ExecuteDataTable(string cmdText, params SqlParameter[] parameters) { using (SqlConnection con = new SqlConnection(connstr)) { con.Open(); return ExecuteDataTable(con, cmdText, parameters); } } public static DataTable ExecuteDataTable(SqlConnection con, string cmdText, params SqlParameter[] parameters) { using (SqlCommand cmd = con.CreateCommand()) { cmd.CommandText = cmdText; cmd.Parameters.AddRange(parameters); using (SqlDataAdapter adapter = new SqlDataAdapter(cmd)) { DataTable dt = new DataTable(); adapter.Fill(dt); return dt; } } } #endregion #region 05.ExtendMethod public static object ToDBValue(this object value) { return value == null ? DBNull.Value : value; } public static object FromDBValue(this object dbValue) { return dbValue == DBNull.Value ? null : DBNull.Value; } #endregion }
注意:这里的问题没有标准答案,大家可以自己总结,有兴趣的园友可以搜搜相关内容,并可以在留言中发起讨论。
PS:简历上写的一定要熟悉,提前准备好,涉及到的技术点一定要有所了解。
PS:客户端缓存、页面缓存、数据源控件缓存、ViewState处理、自定义缓存、IIS启用内核模式缓存和用户模式缓存、IIS启用压缩、服务器端应用和数据库分离等等;
URL传送门:http://www.cnblogs.com/bigmonster/archive/2011/05/14/2046427.html
URL传送门:http://blog.zhaojie.me/2011/03/my-interview-questions-for-dotnet-programmers.html
URL传送门:http://www.cnblogs.com/anders06/archive/2011/03/04/1971078.html
URL传送门:http://www.cnblogs.com/Creator/archive/2011/06/07/2074607.html
URL传送门:http://www.cnblogs.com/leotsai/p/aspnet-tech-test.html
(1)SQL调优之降龙十八掌系列—钢铁心脏:http://www.cnblogs.com/engine1984/p/3454499.html
(2)数据库优化实践系列—elysee:http://www.cnblogs.com/hnlshzx/p/3498722.html
URL传送门:http://www.cnblogs.com/Terrylee/archive/2006/07/17/334911.html
URL传送门:http://www.cnblogs.com/edisonchou/p/3773828.html
转眼之间,又是9月份了,校园招聘的浪潮又要袭来,各位即将从学校毕业的园友们,你们准备好了吗?其实,我个人是不建议也不喜欢刷面试题的,上面这些内容我也只看了一点,不过将一少部分面试题作为复习验收检测以查漏补缺还是有一定益处的。就如我开篇所说:就算你都学习了这些题目,甚至把这些题目的回答都记住了,你也不一定能拿到offer,技术学习不是死记硬背,重在理解与思路。自从进入园子以后,就看到各路大神的技术文章,对大神们顶礼膜拜,觉得以前把什么XX伦、XX华、XX友、XX迅啊视为偶像简直就是弱爆了(这里没有其他意思,就是一个自嘲,请各路fans一笑而过),现在你的偶像可能是XX楠、赵X、X涛、XX军、XX阳...。但是,你可想到这些大神的牛逼也并非一日而就,Nothing can replaces hardwork,只有一步一步的继续努力,不满足于现状,坚持学习(比如要想当.Net大神还得深入.Net内部原理,阅读大牛的经典书籍并加以实践),善于总结(学习并不是盲目的,也不是拼数量的,高效地总结所学会事半功倍),乐于分享(把学习到的东东写成一篇篇的博客发到园子里就是一种分享)才会当上CTO、赢取白富美、走上人生巅峰(这句话源自:万万没想到)。
对于未来,我不想过多设想,因为我智商平平,学校很渣,技术也不算好,实习经历也很渣,但我会踏实走好每一步:我会努力地工作,也会继续活跃在博客园,争取翻译一些Code Project上比较好的技术文章(不得不承认,一些印度三哥的技术文章写得真tmd好!),也要争取写一些有质量的原创文章发到首页与各位园友分享。至于将来的目标,那就是向园子里的各位大神看齐,向他们学习,使用技术改变生活(写得了代码做得好产品服务于客户),同时也要热爱生活(下得了厨房踢得了足球无愧于内心)。最后,借用大神老赵的一句话来做结尾,也与各位即将从学校毕业的码农朋友们共勉:“先做人,再做技术人员,最后做程序员”。
标签:style blog http color os io 使用 java strong
原文地址:http://www.cnblogs.com/edisonchou/p/3935122.html
