标签:content news 表达 网络爬虫 python dataframe 标签 end compress
爬取前的准备:
- BeautifulSoup的导入:pip install BeautifulSoup4
- requests的导入:pip install requests
- 下载jupyter notebook:pip install jupyter notebook
- 下载python,配置环境(可使用anocanda,里面提供了很多python模块)
中文格式除了‘ utf-8 ’还有‘ GBK ’、‘ GB2312 ’ 、‘ ISO-8859-1 ’、‘ GBK ‘’等
用requests可获取网页信息
用BeautifulSoup可以将网页信息转换为可操作物块
1 soup = BeautifulSoup(res.text,‘html.parser‘) 2 # 将requests获取的网页信息转换为BeautifulSoup的物件存于soup中,并指明其剖析器为‘html.parser‘,否则会出现警告。
用beautifulSoup中的select方法可以获取相应的元素,且获取的元素为list形式,可以用for循环将其逐个解析出来
1 alink = soup.select(‘h1‘) 2 3 for link in alink: 4 print(link.text)
获取html标签值后,可以用[‘href’]获取‘href’属性的值,如
1 for link in soup.select(‘a‘): 2 print(link[‘href‘])
获取新闻编号:
* .strip()可以去除前后空白格,括号内加入字符串可以去除指定字符串,rstrip()可以去除右边的,lstrip()可以去除左边的;
* split(‘/‘)根据指定的字符对字符串进行切割
re正则表达式的使用:
1 import re 2 3 m = re.search(‘ doc-i(.*).shtml ‘,newsurl) # 返回在newsurl中匹配到的字符串 4 print(m.group(1)) # group(0)可以取得所有匹配到的部分,group(1)只可以取得括号内的部分
使用for循环获取新闻的多页链接
1 url = ‘http://api.roll.news.sina.com.cn/zt_list?channel=news&cat_1=gnxw&cat_2==gdxw1||=gatxw||=zs-pl||=mtjj&level==1||=2&show_ext=1&show_all=1&show_num=22&tag=1&format=json&page={}&callback=newsloadercallback&_=1501000415111‘ 2 3 for i in rannge(0,10): 4 print( url.format( i ) ) 5 # format可以将url里面的大括号(要修改的部分我们把它删去并换成大括号)换为我们要加入的值(如上面代码中的 i)
获取新闻发布的时间:
获取的信息可能会有包含的成分,即会获取到如出版社的其他我们不需要的元素,可以用contents将里面的元素分离成list形式,用contents[0]即可获取相应元素
1 # 获取出版时间 2 from datetime import datetime 3 4 res = requests.get(‘http://news.sina.com.cn/c/nd/2017-07-22/doc-ifyihrmf3191202.shtml‘) 5 res.encoding = ‘utf-8‘ 6 soup = BeautifulSoup(res.text,‘html.parser‘) 7 timesource = soup.select(‘.time-source‘) 8 print(timesource[0].contents[0])
时间字符串转换
1 # 字符串转时间:-strptime 2 dt = datetime.strptime(timesource,‘%Y年%m月%d日%H:%M ’) 3 4 # 时间转换字符串:-strftime 5 dt.strftime(‘%Y-%m-%d‘)
获取新闻内文:
检查其所属类后按照上面的 select 获取新闻内文,获取的内容为list形式,可用for循环将内容去除标签后加入到自己创建的的list中(如article = [])
* 其中可以用 ‘ \n ’.join( article ) 将article列表中的每一项用换行符‘ \n ’分隔开;
1 # 获取单篇新闻内容 2 article = [] 3 for p in soup.select(‘.article p‘): 4 article.append(p.text.strip()) 5 print(‘\n‘.join(article))
上面获取单篇新闻的代码可用一行完成:
1 # 一行完成上面获取新闻内容的代码 2 print(‘\n‘.join([p.text.strip() for p in soup.select(‘.article p‘)]))
获取评论数量:(在获取评论数量时会发现评论是用js的形式发送给浏览器的,所以要先把获取的内容转化为json格式读取python字典
1 # 取得评论数的数量 2 import requests 3 import json 4 comment = requests.get(‘http://comment5.news.sina.com.cn/page/info?version=1&format=js&c5 hannel=gn&newsid=comos-fyihrmf3218511&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20‘) # 从评论地址获取相关内容 6 comment.encoding = ‘utf-8‘ 7 jd = json.loads(comment.text.strip(‘var data=‘)) 8 jd[‘result‘][‘count‘][‘total‘]
完整代码(以获取新浪新闻为例):
1 # 获取新闻的标题,内容,时间和评论数 2 import requests 3 from bs4 import BeautifulSoup 4 from datetime import datetime 5 import re 6 import json 7 import pandas 8 9 def getNewsdetial(newsurl): 10 res = requests.get(newsurl) 11 res.encoding = ‘utf-8‘ 12 soup = BeautifulSoup(res.text,‘html.parser‘) 13 newsTitle = soup.select(‘.page-header h1‘)[0].text.strip() 14 nt = datetime.strptime(soup.select(‘.time-source‘)[0].contents[0].strip(),‘%Y年%m月%d日%H:%M‘) 15 newsTime = datetime.strftime(nt,‘%Y-%m-%d %H:%M‘) 16 newsArticle = getnewsArticle(soup.select(‘.article p‘)) 17 newsAuthor = newsArticle[-1] 18 return newsTitle,newsTime,newsArticle,newsAuthor 19 def getnewsArticle(news): 20 newsArticle = [] 21 for p in news: 22 newsArticle.append(p.text.strip()) 23 return newsArticle 24 25 # 获取评论数量 26 27 def getCommentCount(newsurl): 28 m = re.search(‘doc-i(.+).shtml‘,newsurl) 29 newsid = m.group(1) 30 commenturl = ‘http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-{}&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20‘ 31 comment = requests.get(commenturl.format(newsid)) #将要修改的地方换成大括号,并用format将newsid放入大括号的位置 32 jd = json.loads(comment.text.lstrip(‘var data=‘)) 33 return jd[‘result‘][‘count‘][‘total‘] 34 35 36 def getNewsLinkUrl(): 37 # 得到异步载入的新闻地址(即获得所有分页新闻地址) 38 urlFormat = ‘http://api.roll.news.sina.com.cn/zt_list?channel=news&cat_1=gnxw&cat_2==gdxw1||=gatxw||=zs-pl||=mtjj&level==1||=2&show_ext=1&show_all=1&show_num=22&tag=1&format=json&page={}&callback=newsloadercallback&_=1501000415111‘ 39 url = [] 40 for i in range(1,10): 41 res = requests.get(urlFormat.format(i)) 42 jd = json.loads(res.text.lstrip(‘ newsloadercallback(‘).rstrip(‘);‘)) 43 url.extend(getUrl(jd)) #entend和append的区别 44 return url 45 46 def getUrl(jd): 47 # 获取每一分页的新闻地址 48 url = [] 49 for i in jd[‘result‘][‘data‘]: 50 url.append(i[‘url‘]) 51 return url 52 53 # 取得新闻时间,编辑,内容,标题,评论数量并整合在total_2中 54 def getNewsDetial(): 55 title_all = [] 56 author_all = [] 57 commentCount_all = [] 58 article_all = [] 59 time_all = [] 60 url_all = getNewsLinkUrl() 61 for url in url_all: 62 title_all.append(getNewsdetial(url)[0]) 63 time_all.append(getNewsdetial(url)[1]) 64 article_all.append(getNewsdetial(url)[2]) 65 author_all.append(getNewsdetial(url)[3]) 66 commentCount_all.append(getCommentCount(url)) 67 total_2 = {‘a_title‘:title_all,‘b_article‘:article_all,‘c_commentCount‘:commentCount_all,‘d_time‘:time_all,‘e_editor‘:author_all} 68 return total_2 69 70 # ( 运行起始点 )用pandas模块处理数据并转化为excel文档 71 72 df = pandas.DataFrame(getNewsDetial()) 73 df.to_excel(‘news2.xlsx‘)
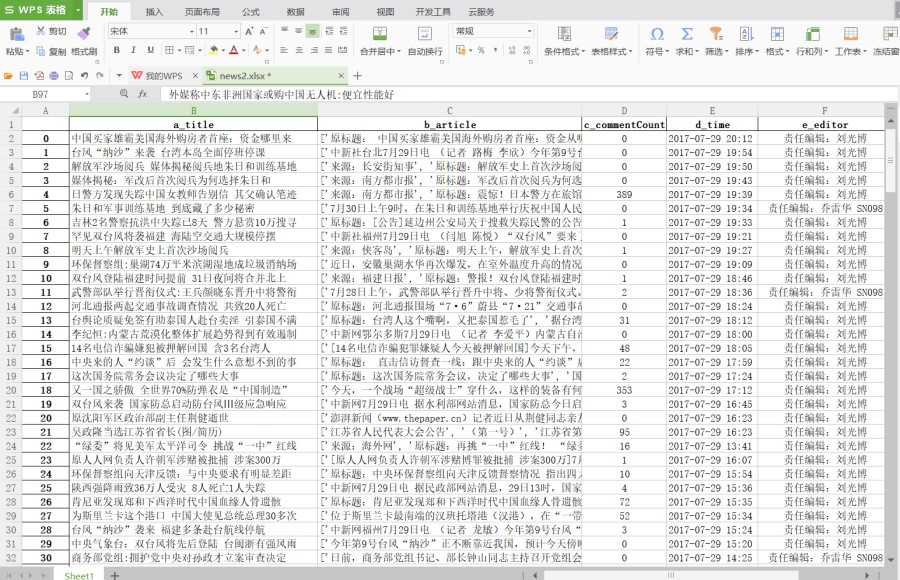
存储的excel文档如下:
TIPS:
问题:在jupyter notebook导入pandas时可能会出现导入错误
解决:不要用命令行打开jupyter notebook,直接找到软件打开或者在Anocanda Navigator中打开
2017-07-29 21:49:37
标签:content news 表达 网络爬虫 python dataframe 标签 end compress
原文地址:http://www.cnblogs.com/zengbojia/p/7220190.html