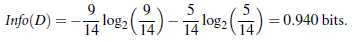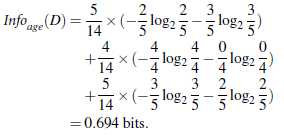标签:天气情况 信息 ima over 贪心 比特 之间 blog fit
1、什么是决策树(Decision Tree)
决策树是一个类似于流程图的树结构,其中每一个树节点表示一个属性上的测试,每一个分支代表一个属性的输出,每一个树叶节点代 表一个类或者类的分布,树的最顶层是树的根节点。
举一个例子。小明同学想根据天气情况是否享受游泳运动:
这里包含了6个属性,一条样例即为一个实例,待学习的概念为“是否享受运动”,学习目标函数:f:X->Y。
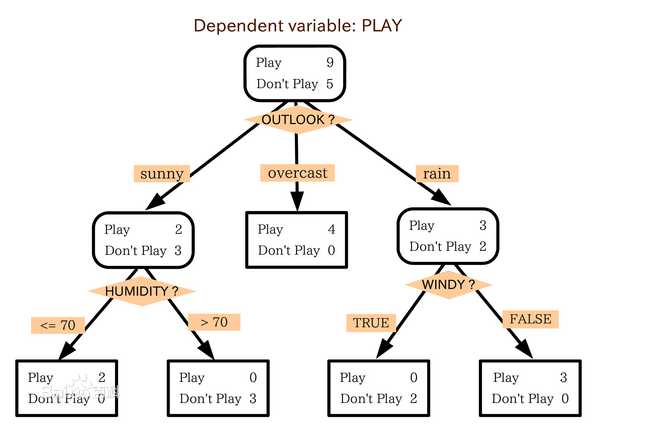
根据上面的表中实例,我们可以试着用一个树结构的流程图来表示小明根据那6个属性决定是否享受运动:
从上面这个树状图中,我们可以看到,总共的实例有14个(出去运动的实例有9个,不运动的实例有5个),从树顶往下看,首先看到菱形的选项,意思是天气如何?然后分出了三个分支——晴天,阴天,雨天。实例中是天气属性为晴天,并决定要去运动的有2个,不去运动的有3个;天气属性为阴天,并决定去运动的有4个,不运动的有0个;天气属性为雨天,并决定去运动的有3个,不运动的有2个。从图中我们可以看到,当标记中的正例或者反例为0个时,树就不继续往下扩展了(比如天气属性为阴天的时候,不去运动的实例为0个)。假如正例或者反例都不为0时,那么就要根据属性继续往下扩展树。
决策树是机器学习中分类方法中的一个重要算法。
2、如何构造一个决策树算法
(1)信息熵
信息是一种抽象的概念,那么如何对信息进行一个量化的操作呢?1948年,香农提出了“信息熵”的概念。一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确定的事情,或者说我们对一件事情一无所知,就需要了解大量的信息,信息量的度量就等于不确定性的多少。
举个例子,NBA总决赛的夺冠球队,假设你对NBA球队一无所知,你需要猜多少次?(假设每个球队的夺冠几率都是一样的)这里我们可以给进入季后赛的NBA球队进行编号(NBA季后赛会选出16支球队),然后使用二分法进行猜测(猜测冠军队伍在1-8号球队之间,是的话,在进行二分;不是的话就在9-16号球队之间),这样我们要猜测的次数最多是4次(2^4=16嘛)。
信息熵使用比特(bit)来衡量信息的多少,计算公式如下:
-(P1*log2 P1+P2*log2 P2+...P16*log2 P16)---->计算NBA季后赛总冠军的夺冠球队的信息熵值,含义是每一个球队的夺冠概率乘以,以2为底这个队夺冠的对数。P1、P2...PN表示哪一支球队的夺冠概率,假设每一个球队夺冠的概率都相等的话,那么这里算出的信息熵值就是4,当然这种情况是不太可能存在的,因为每一个球队的实力不一样嘛。
变量的不确定越大,熵的值也就越大。
(2)决策树归纳算法(ID3)
这个算法是1970-1980年,由J.Ross.Quinlan发明的。
在决策树算法中,比较重要的一点是我们如何确定哪个属性应该先选择出来,哪个属性应该后选择出来当做树的节点。这里就涉及到了一个新的概念,叫做信息获取量,公式如下:
Gain(A)=Info(D)-Info_A(D) ---->A属性的信息获取量的值就等于,不按任何属性进行分类的时候的信息量加上有按A这个属性进行分类的时候的信息量(注意这里信息量的符号是负号,所以说“加上”)。
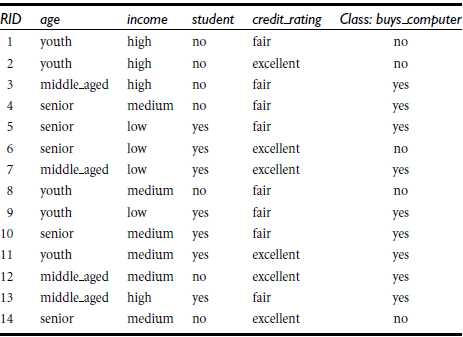
以是否购买电脑的案例为例子,给出了14个实例,如下图所示:
不按任何属性进行分类的情况下,计算信息获取量Info(D):
以年龄属性进行分类的情况下,计算信息获取量:
所以,Gain(age)=0.940-0.694=0.246 bits
同理,我们可以算出Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048。比较大小,年龄的信息获取量是最大的,所以选择年龄作为第一个根节点。再次同理,后面的节点选择也是按照这样的计算方法来决定以哪个属性作为节点。
(3)结束条件
当我们使用递归的方法来创建决策树时,什么时候停止节点的创建很关键。综上,停止节点创建的条件有以下几点:
a、给定节点的所有样本属性都属于同一种标记的时候,比如(2)中的例子,以年龄为属性创建的节点下,有三个分支: senior,youth、middle_age。其中middle_age的所有实例的标记都是yes,也就是说中年人都会买电脑,这种情况下,这个节点就可以设置成树叶节点了。
b、当没有剩余属性用来进一步划分样本时,就停止节点的创建,采用多数表决。
c、分枝
3、其它算法
C4.5、CART算法。这几个算法都是贪心算法,自上而下,只是选择属性的度量方法不同。
4、树剪枝叶 (避免overfitting)
当树的深度太大时,设计的算法在训练集上的表现会比较好,但是在测试集上的表现却会很一般,这时我们就要对树进行一定的裁剪:
(1)先剪枝
当分到一定程度,就不向下增长树了。
(2)后剪枝
把树完全建好后,根据类的纯度来进行树的裁剪。
5. 决策树的优点:
直观,便于理解,小规模数据集有效
6. 决策树的缺点:
处理连续变量不好;类别较多时,错误增加的比较快;可规模性一般。
机器学习入门之决策树算法
标签:天气情况 信息 ima over 贪心 比特 之间 blog fit
原文地址:http://www.cnblogs.com/getMyCodes/p/7259422.html