标签:ast 导入 linux orm 爬虫 xml配置 sql imp keyword
?? solr是基于lucene的一个全文检索服务器,提供了一些类似webservice的API接口,用户可以通过http请求solr服务器,进行索引的建立和索引的搜索。
索引建立的过程:用户提交的文本会经过分词器进行分词,分词后的关键字会存到索引库里,索引库是关键字和目标文档的映射集。
索引搜索的过程:用户提交的搜索文本也是会经过分析器,得到的关键字会去索引库查询对应的目标文档并返回给客户端,采用的是权重排序算法。
1.solr的安装

2.中文分词器的安装

配置信息:
<!--中文分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
3.1 DIH全量同步
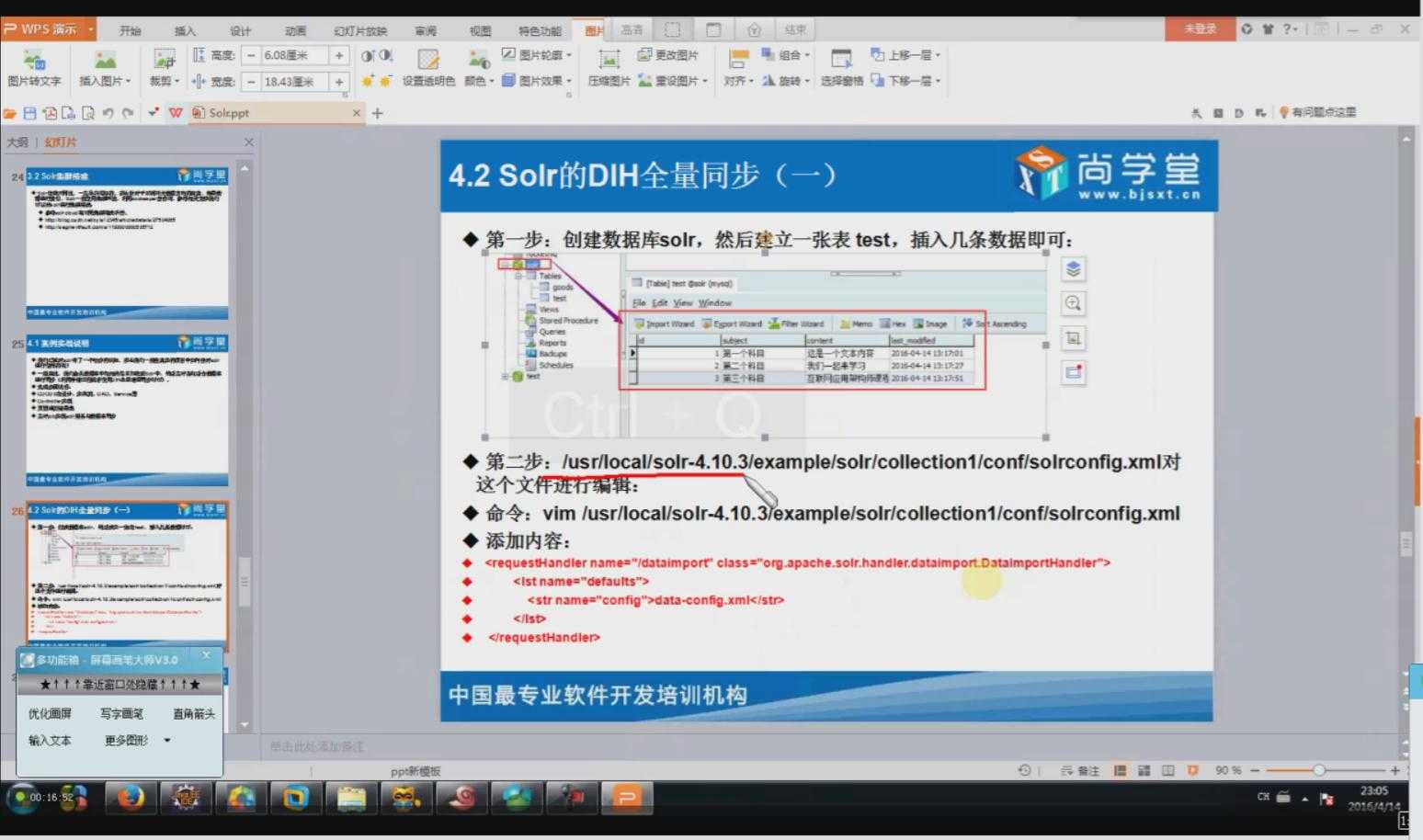
相关配置信息:
<!-- 数据导入配置 --> <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
3.2
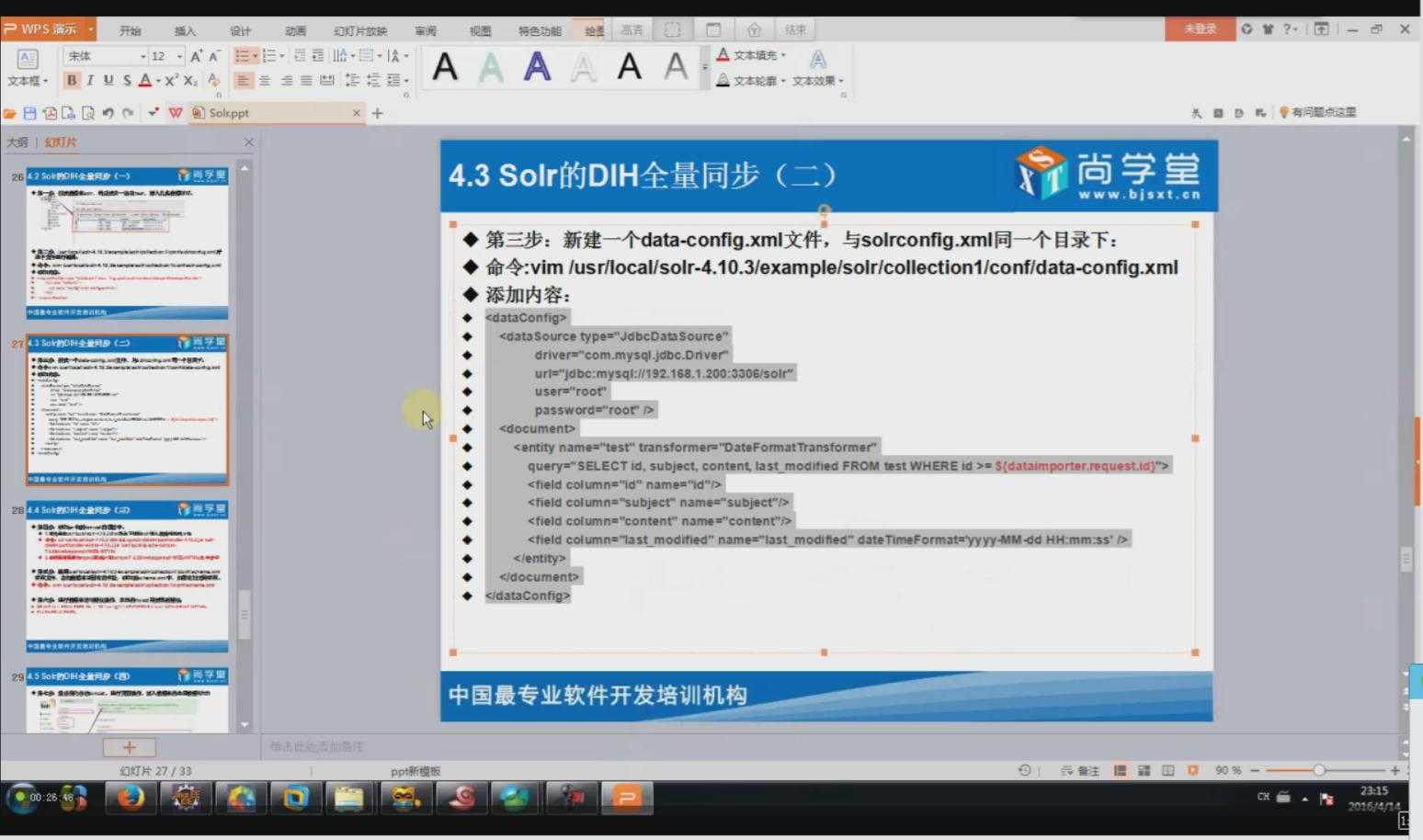
相关配置信息:
3.3 schema.xml同步字段配置
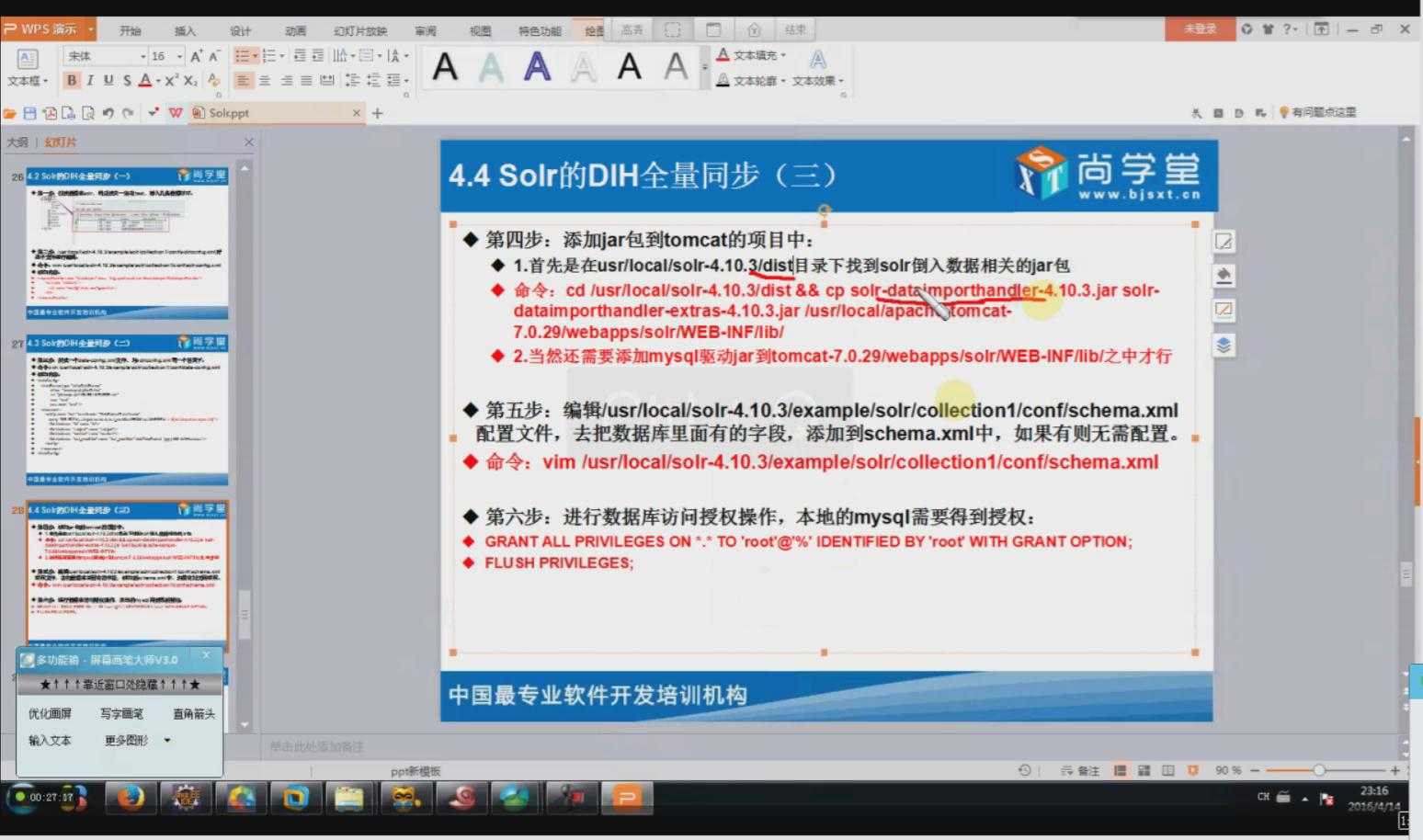
相关配置信息:
<!-- 同步mysql爬虫表的字段 --> <field name="create_date" type="date" indexed="true" stored="true"/> <field name="update_date" type="date" indexed="true" stored="true"/> <field name="news_url" type="text_general" indexed="true" stored="true"/> <field name="news_origin" type="text_general" indexed="true" stored="true"/> <field name="key_word" type="text_general" indexed="true" stored="true"/> <field name="news_html" type="text_ik" indexed="true" stored="true"/> <field name="is_publish" type="int" indexed="true" stored="true"/> <field name="is_del" type="int" indexed="true" stored="true"/> <field name="flag_number" type="text_general" indexed="true" stored="true"/> <field name="out_line" type="text_ik" indexed="true" stored="true"/> <field name="state" type="int" indexed="true" stored="true"/> <!-- 同步mysql爬虫表的字段end -->
4.1DIH的增量同步(其实就是修改data-config.xml配置文件)
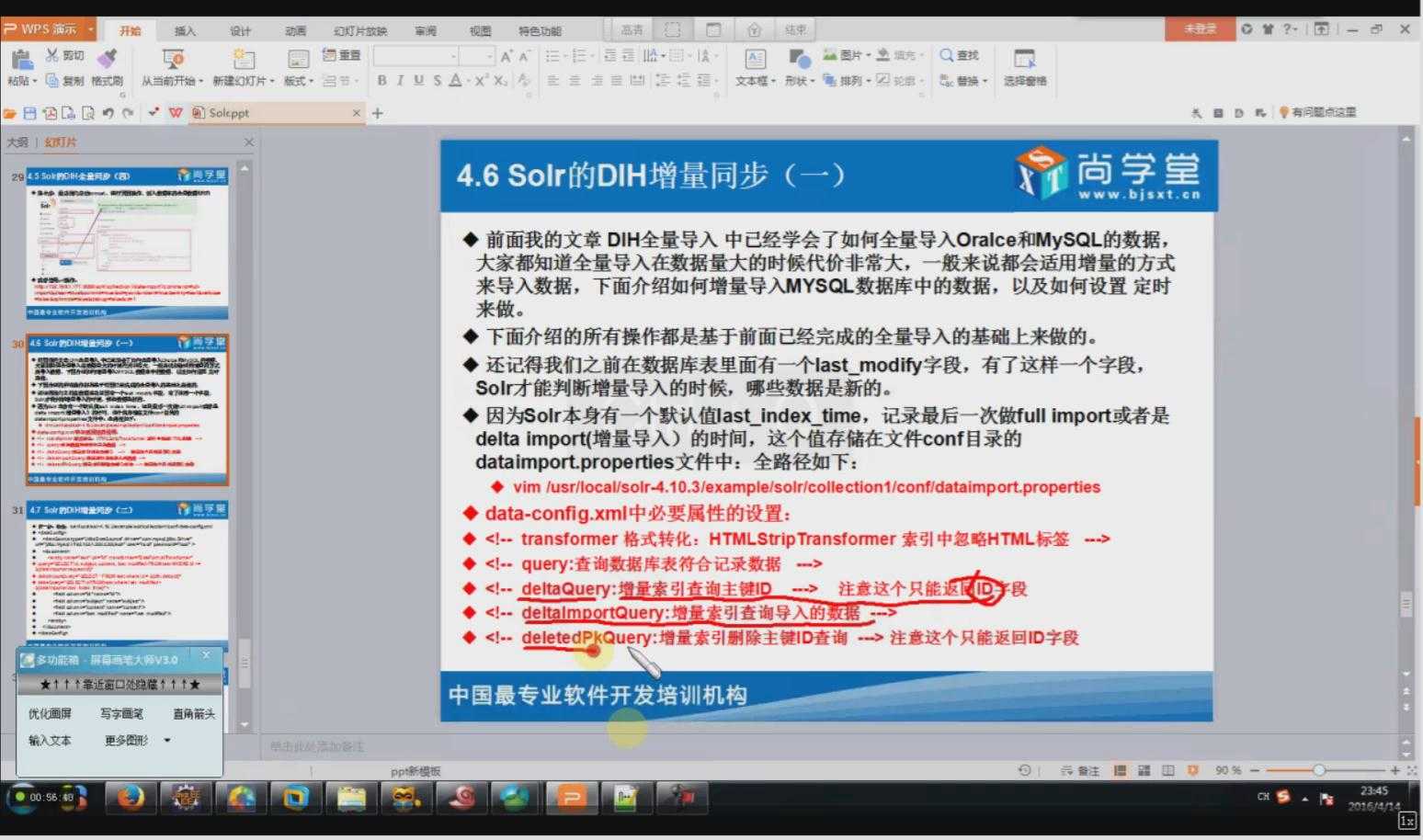
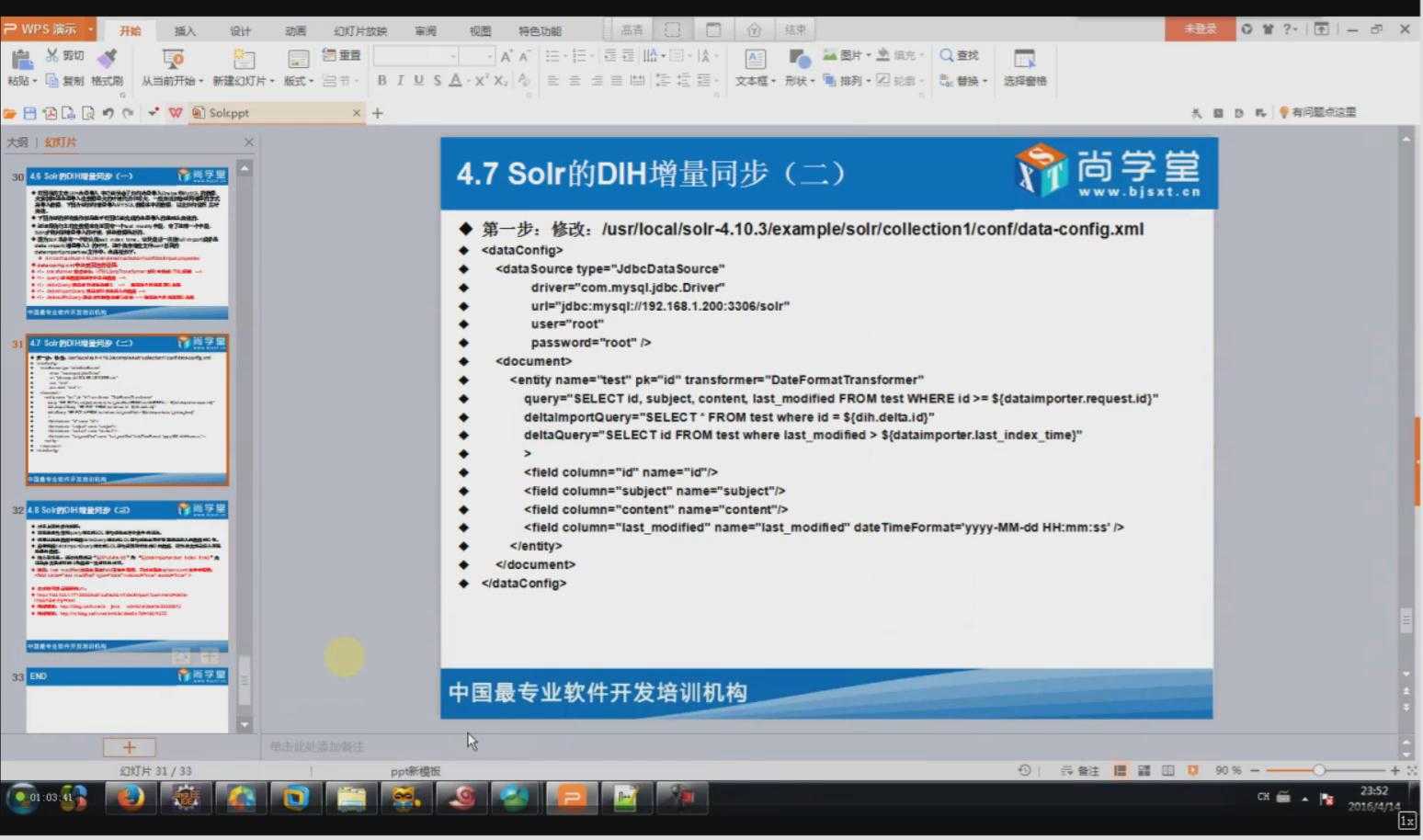
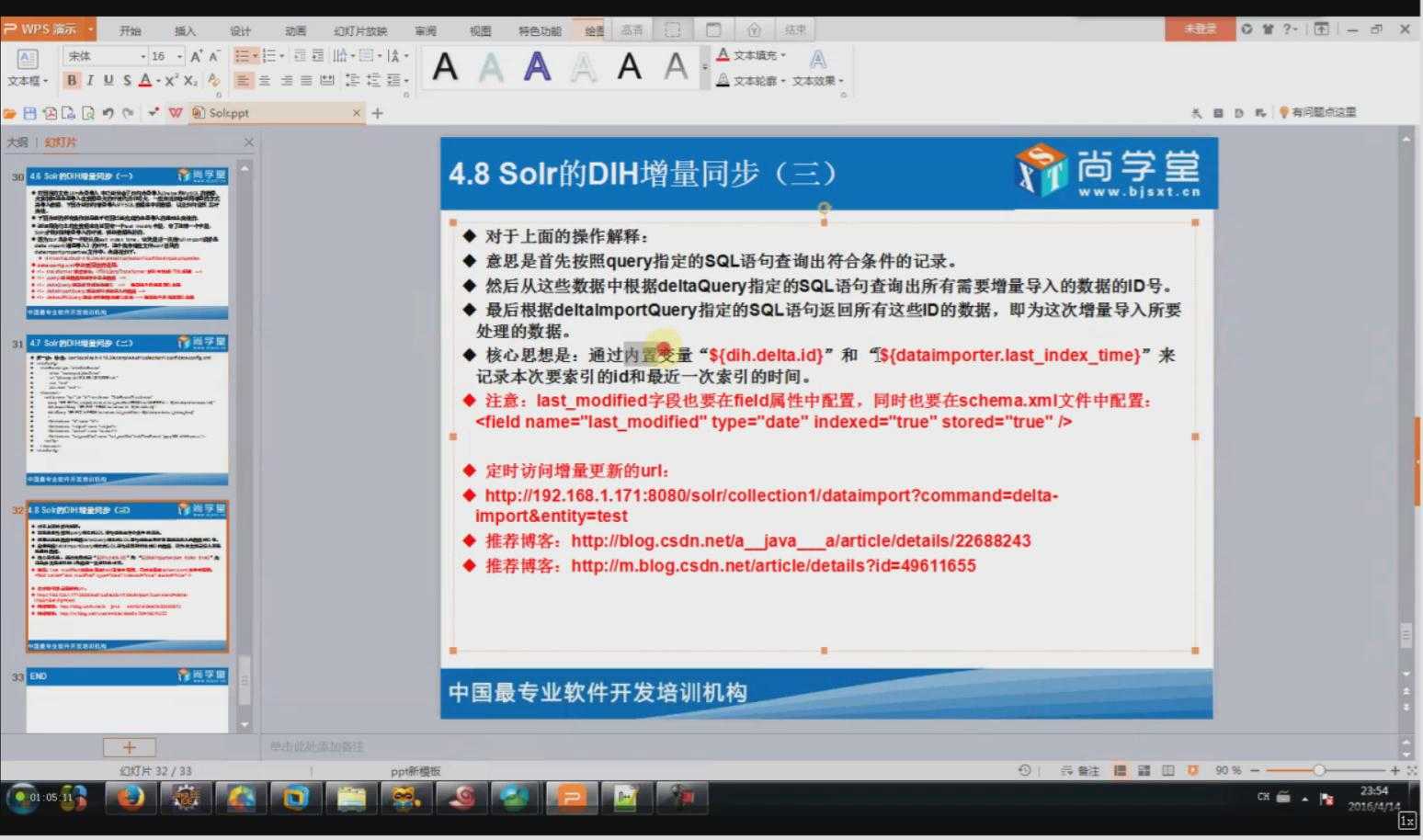
相关配置信息:
<dataConfig> <dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.40.1:3306/shanghang" user="root" password="root" /> <document> <entity name="consensus_data2" pk="id" transformer="DateFormatTransformer" query="select * from consensus_data2 where id >= ‘${dataimporter.request.id}‘" deltaImportQuery="select * from consensus_data2 where id = ‘${dih.delta.id}‘" deltaQuery="select id from consensus_data2 where create_date > ‘${dataimporter.last_index_time}‘"> <field column="id" name="id" /> <field column="create_date" name="create_date" dateTimeFormat=‘yyyy-MM-dd HH:mm:ss‘/> <field column="update_date" name="update_date" dateTimeFormat=‘yyyy-MM-dd HH:mm:ss‘ /> <field column="news_url" name="news_url" /> <field column="news_origin" name="news_origin" /> <field column="keyWord" name="key_word" /> <field column="news_html" name="news_html" /> <field column="is_publish" name="is_publish" /> <field column="is_del" name="is_del" /> <field column="flag_number" name="flag_number" /> <field column="out_line" name="out_line" /> <field column="state" name="state" /> </entity> </document> </dataConfig>
标签:ast 导入 linux orm 爬虫 xml配置 sql imp keyword
原文地址:http://www.cnblogs.com/3chi/p/7262080.html