标签:tor 编码 重要 for get 历史 beautiful 分享 name
前一篇小文中就提到了python的requests库可以获取网络编码中的所有内容,我们获取了自然就必须对它进行加工处理,就像我们学习一样,一本书,我们可以轻易的获取,但是它究竟是在讲哲学还是讲历史呢还是其他云云,需要我们认真分析,取其精华去其糟粕。而在python当然也有做这个工作的’人‘,就是我们需要安装库中的‘beautifulsoup’
我本来是想继续用昨天的网址来说明的,不过效果不佳,我一会这这篇小文的最后会附上源代码,供各位朋友或者自己再次的学习
html_doc = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc) print soup.text
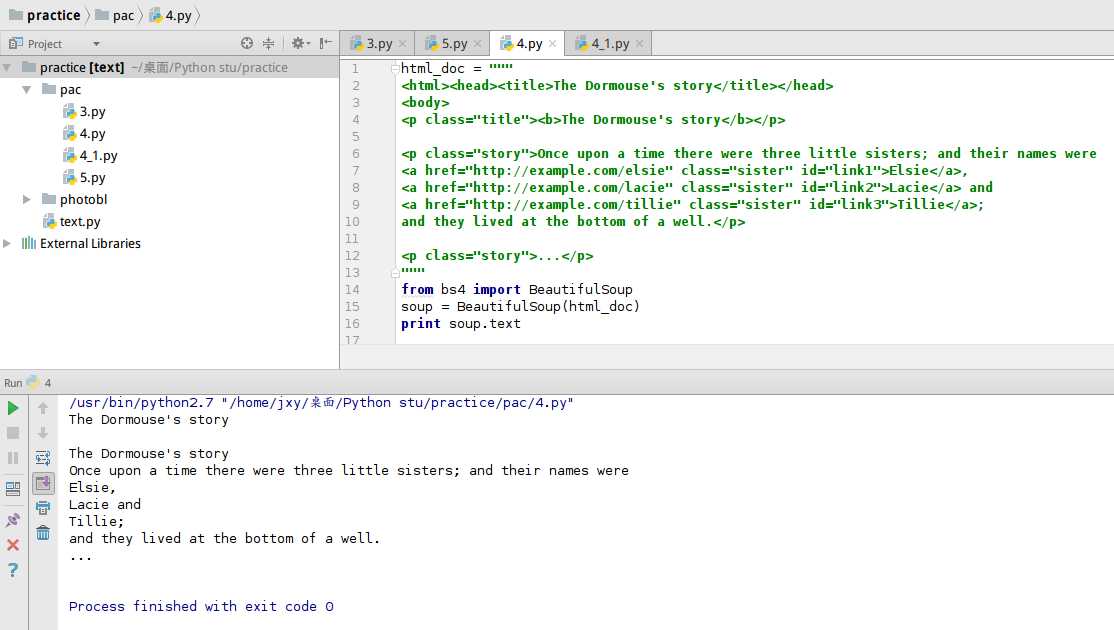
我引用了一个一段HTML代码,这是官方手册例子,也是这是爱丽丝梦游仙境的 的一段内容。
我们看到,提取出了它的关键的东西:去除看不懂的一些代码,留下了能理解的小说文字。
之所以学习需要一本书,重要的不是它的所有字的组合,而是部分字的精粹。
我们能提取出它的所有,当然也能够提取出我们想要的,比如我想提取这本书的名字:
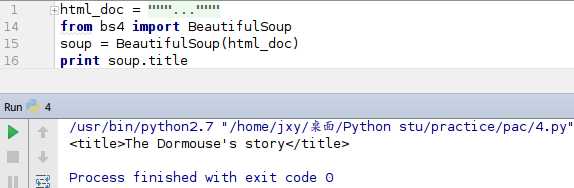
与
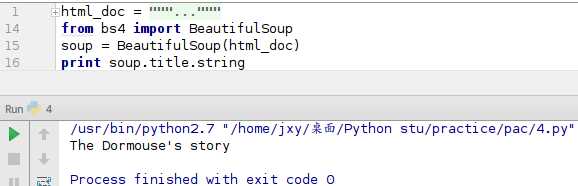
其实这是这个title是python中自带的获取标题的方法,在HTML代码中,可以看到有两个title,上面的是HTML设置网页的标题,下面是一个标示,soup.title代码爬的是HTML网页设置的标题
我还可以爬其他的东东 比如特定地点的网址,标识,id,名字...还是用原文HTML举例
在开始之前,我给介绍一个代码
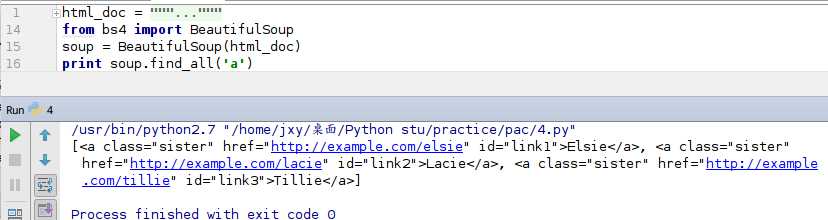
这个可以找到所有<a>标签
充分吸收后,可以继续学习了
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
1 from bs4 import BeautifulSoup 2 soup = BeautifulSoup(html_doc) 3 for link in soup.find_all(‘a‘): 4 print (link.get(‘href‘))
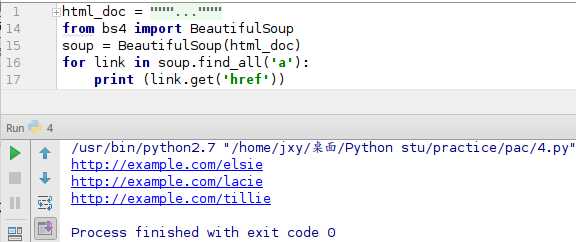
以上代码是从文档中找到所有<a>标签的链接,可以也找到<a>标签中的class,id,如果要测试,最好先去预测下会出现什么结果,说不定会有一个大惊喜。
但是名字是片段中的正文部分,还记得本小文第一个例子吧,爬取爱丽丝梦游仙境 的小说片段。
我用了一个巧妙的方法,把前面的知识结合起来:
既然 soup.find_all(‘a‘) 这个代码可以找到所有<a>标签的链接,我们就从这些链接入手,给它text
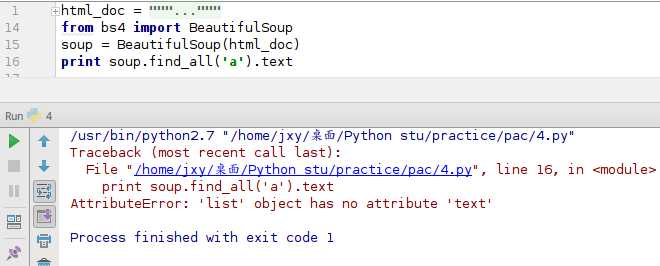
咦!说因为现在的是一个列表,这个不能text
既然是个列表[可以理解为数组吧,个人是这样理解的],我需要一个一个的提取正文
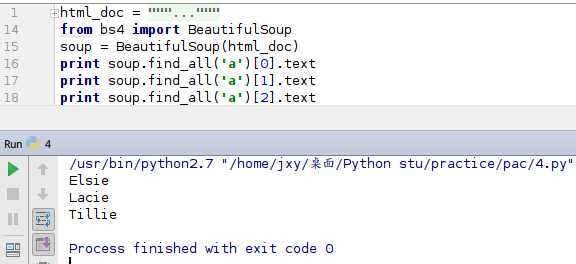
效果还不错,达到了我想要的效果
beautifulsoup这个库还有众多功能,小文只是九牛一毛的来说了一下,后面要用的时候再继续扩展,我也需要时间去学习,只有在实战中学习吸收效果才很好。
最后要说点什么:刚刚文章开始的时候,我不是说本来要把昨天的拿来用吗,但是效果不佳,至于为什么,我把代码附上,可以去试试
1 import requests 2 from bs4 import BeautifulSoup 3 res = requests.get("http://baike.sogou.com/v77860.htm?pid=baike.box") 4 soup = BeautifulSoup(res.text) 5 print soup.text
python爬虫学习日历2【基于ubuntu系统】beautifulsoup的强大之处
标签:tor 编码 重要 for get 历史 beautiful 分享 name
原文地址:http://www.cnblogs.com/ceroo/p/7264636.html