标签:format 原因 nba 应用 目标 font log com time
很多应用中都会有类似组织机构的表,组织机构的表又通常是典型的层次结构(没有循环节点)。于是通过组织控制数据权限的时候,许多人都喜欢通过connect by获得组织信息,然后再过滤目标数据。
在有些情况下,这样写并没有什么问题,但有些情况下,这个就是一个大问题。
归根结底,这是connect by特性导致的,oracle无法知道connect by之后到底返回多少数据,所以有可能采取一些你所不期望的算法,结果自然不是你所期望的---非常慢。
下面,我就讨论在12.1.0.2中如果遇到这样的语句应该如何处理。
为了很好理解,我做了3表:
执行SQL:
SELECT A.CI, A.ENBAJ02 AS CELL_NAME FROM TDL_CM_CELL A, T_ORG_CELL_SCOPE S WHERE S.REGION_NAME = A.REGION_NAME AND S.CITY_NAME = A.CITY_NAME AND (S.ORG_ID) IN (SELECT ID FROM T_ORG O START WITH ID = 101021003 --1010210 --START WITH ID=1 CONNECT BY PARENT_ID = PRIOR ID)
实际使用的执行计划: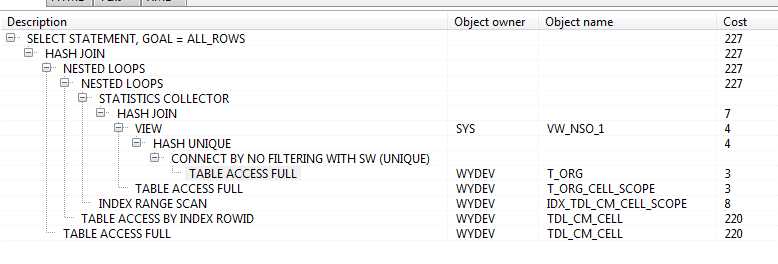
而不会采用自适应计划(adaptive plan):
Plan Hash Value : 2596385940
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2622 | 228114 | 227 | 00:00:01 |
| 1 | NESTED LOOPS | | 2622 | 228114 | 227 | 00:00:01 |
| 2 | NESTED LOOPS | | 2622 | 228114 | 227 | 00:00:01 |
| * 3 | HASH JOIN | | 1 | 31 | 7 | 00:00:01 |
| 4 | VIEW | VW_NSO_1 | 1 | 13 | 4 | 00:00:01 |
| 5 | HASH UNIQUE | | 1 | 20 | 4 | 00:00:01 |
| * 6 | CONNECT BY NO FILTERING WITH SW (UNIQUE) | | | | | |
| 7 | TABLE ACCESS FULL | T_ORG | 75 | 825 | 3 | 00:00:01 |
| 8 | TABLE ACCESS FULL | T_ORG_CELL_SCOPE | 85 | 1530 | 3 | 00:00:01 |
| * 9 | INDEX RANGE SCAN | IDX_TDL_CM_CELL_SCOPE | 257 | | 8 | 00:00:01 |
| 10 | TABLE ACCESS BY INDEX ROWID | TDL_CM_CELL | 2313 | 129528 | 220 | 00:00:01 |
-------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
------------------------------------------
* 3 - access("S"."ORG_ID"="ID")
* 6 - access("PARENT_ID"=PRIOR "ID")
* 6 - filter("ID"=101021003)
* 9 - access("S"."REGION_NAME"="A"."REGION_NAME" AND "S"."CITY_NAME"="A"."CITY_NAME")
Notes
-----
- This is an adaptive plan
原因在于,oracle无法知道connect by之后的数量,所以只能认为是很大的量
--
有一种方式就是,就是使用提示来解决:
SELECT /*+ no_merge(x) use_nl(a x) */ A.CI, A.ENBAJ02 AS CELL_NAME FROM TDL_CM_CELL A, (select s.city_name, s.region_name from T_ORG_CELL_SCOPE S WHERE (S.ORG_ID) IN (SELECT ID FROM T_ORG O START WITH ID = 101021003 --1010210 --START WITH ID=1 CONNECT BY PARENT_ID = PRIOR ID) ) x where x.REGION_NAME = A.REGION_NAME AND x.CITY_NAME = A.CITY_NAME
这样计划就是:
Plan Hash Value : 37846894
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2313 | 277560 | 227 | 00:00:01 |
| 1 | NESTED LOOPS | | 2313 | 277560 | 227 | 00:00:01 |
| 2 | NESTED LOOPS | | 2313 | 277560 | 227 | 00:00:01 |
| 3 | VIEW | | 1 | 64 | 7 | 00:00:01 |
| * 4 | HASH JOIN | | 1 | 31 | 7 | 00:00:01 |
| 5 | VIEW | VW_NSO_1 | 1 | 13 | 4 | 00:00:01 |
| 6 | HASH UNIQUE | | 1 | 20 | 4 | 00:00:01 |
| * 7 | CONNECT BY NO FILTERING WITH SW (UNIQUE) | | | | | |
| 8 | TABLE ACCESS FULL | T_ORG | 75 | 825 | 3 | 00:00:01 |
| 9 | TABLE ACCESS FULL | T_ORG_CELL_SCOPE | 85 | 1530 | 3 | 00:00:01 |
| * 10 | INDEX RANGE SCAN | IDX_TDL_CM_CELL_SCOPE | 257 | | 8 | 00:00:01 |
| 11 | TABLE ACCESS BY INDEX ROWID | TDL_CM_CELL | 2313 | 129528 | 220 | 00:00:01 |
---------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
------------------------------------------
* 4 - access("S"."ORG_ID"="ID")
* 7 - access("PARENT_ID"=PRIOR "ID")
* 7 - filter("ID"=101021003)
* 10 - access("X"."REGION_NAME"="A"."REGION_NAME" AND "X"."CITY_NAME"="A"."CITY_NAME")
如果一个应用的start id可能是一个很大的范围,如果强制使用提示,也会出现问题,所以如果有这样的应用,可以考虑使用oracle 12c的adaptive特性。
如果不行,就必须把不同范围的查询,定义为不同的功能提交给用户。
标签:format 原因 nba 应用 目标 font log com time
原文地址:http://www.cnblogs.com/lzfhope/p/7251772.html