标签:基本 梯度 image 操作 目标 ace display pac isp
I. 牛顿迭代法
给定一个复杂的非线性函数f(x),希望求它的最小值,我们一般可以这样做,假定它足够光滑,那么它的最小值也就是它的极小值点,满足f′(x0)=0,然后可以转化为求方程f′(x)=0的根了。非线性方程的根我们有个牛顿法,所以
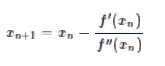
然而,这种做法脱离了几何意义,不能让我们窥探到更多的秘密。我们宁可使用如下的思路:在y=f(x)的x=xn这一点处,我们可以用一条近似的曲线来逼近原函数,如果近似的曲线容易求最小值,那么我们就可以用这个近似的曲线求得的最小值,来近似代替原来曲线的最小值了:
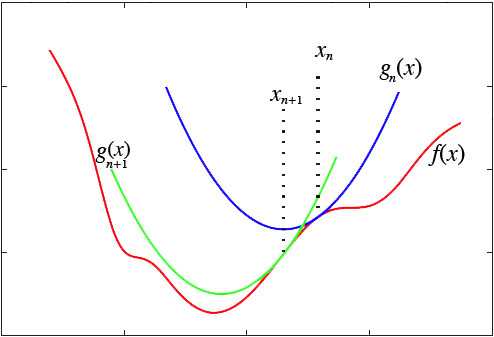
显然,对近似曲线的要求是:
1、跟真实曲线在某种程度上近似,一般而言,要求至少具有一阶的近似度;
2、要有极小值点,并且极小值点容易求解。
这样,我们很自然可以选择“切抛物线”来近似:
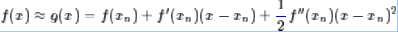
该抛物线具有二阶的精度。对于这条抛物线来说,极值点是
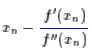
所以我们重新得到了牛顿法的迭代公式:
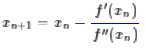
如果f(x)足够光滑并且在全局只有一个极值点,那么牛顿法将会是快速收敛的(速度指数增长),然而真实的函数并没有这么理想,因此,它的缺点就暴露出来了:
1、需要求二阶导数,有些函数求二阶导数之后就相当复杂了;
2、因为f″(xn)的大小不定,所以g(x)开口方向不定,我们无法确定最后得到的结果究竟是极大值还是极小值。
II. 梯度下降
这两个缺点在很多问题上都是致命性的,因此,为了解决这两个问题,我们放弃二阶精度,即去掉f″(xn),改为一个固定的正数1/h:
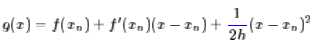
这条近似曲线只有一阶精度,但是同时也去掉了二阶导数的计算,并且保证了这是一条开口向上的抛物线,因此,通过它来迭代,至少可以保证最后会收敛到一个极小值(至少是局部最小值)。上述g(x)的最小值点为
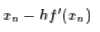
所以我们得到迭代公式
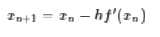
对于高维空间就是
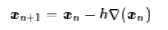
这就是著名的梯度下降法了。当然,它本身存在很多问题,但很多改进的算法都是围绕着它来展开,如随机梯度下降等等。
这里我们将梯度下降法理解为近似抛物线来逼近得到的结果,既然这样子看,读者应该也会想到,凭啥我一定要用抛物线来逼近,用其他曲线来逼近不可以吗?当然可以,对于很多问题来说,梯度下降法还有可能把问题复杂化,也就是说,抛物线失效了,这时候我们就要考虑其他形式的逼近了。事实上,其他逼近方案,基本都被称为EM算法,恰好就只排除掉了系出同源的梯度下降法,实在让人不解。
V. K-Means
K-Means聚类很容易理解,就是已知N个点的坐标xi,i=1,…,N,然后想办法将这堆点分为K类,每个类有一个聚类中心cj,j=1,…,K,很自然地,一个点所属的类别,就是跟它最近的那个聚类中心cj所代表的类别,这里的距离定义为欧式距离。
所以,K-Means聚类的主要任务就是求聚类中心cj。我们当然希望每个聚类中心正好就在类别的“中心”了,用函数来表示出来,就是希望下述函数L最小:
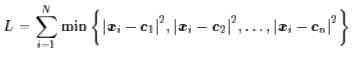
其中,min操作保证了每个点只属于离它最近的那一类。
如果直接用梯度下降法优化L,那么将会遇到很大困难,不过这倒不是因为min操作难以求导,而是因为这是一个NP的问题,理论收敛时间随着N成指数增长。这时我们也是用EM算法的,这时候EM算法表现为:
1、随机选K个点作为初始聚类中心;
2、已知K个聚类中心的前提下,算出各个点分别属于哪一类,然后用同一类的所有点的平均坐标,来作为新的聚类中心。
这种方法迭代几次基本就能够收敛了,那么,这样做的理由又在哪儿呢?
我们依旧是近似曲线逼近的思路,但问题是,现在的min不可导怎么办呢?可以考虑用光滑近似,然后再取极限,答案在这里:《寻求一个光滑的最大值函数》。取一个足够大的M,那么就可以认为(最小值等于相反数的最大值的相反数)
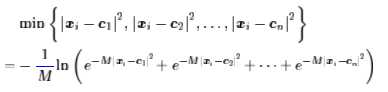
目标函数:
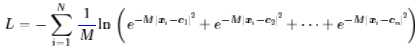
梯度: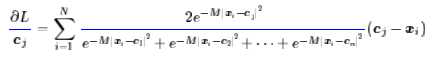
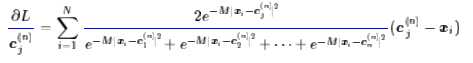
根据这个式子的特点,我们可以寻找这样的近似曲线(应该是超曲面了):
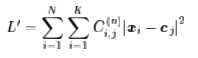
其中$C_{i,j}^{n}$待定,它在每一轮都是一个常数,所以这只是一个二次函数,不难求得它的最小值点是
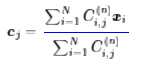
即xi的加权平均。
同样地,我们希望它这个近似曲线跟原函数比,至少具有一阶近似,因此我们求它的导数:
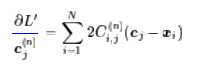
对比原函数的导数,不难得到
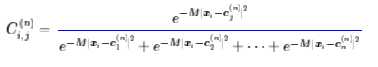
这时候我们就得到迭代公式:
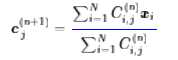
至此,我们对各个步骤都推导完毕,但我们还是使用连续近似,最后我们要取M→∞的极限了,取极限后问题可以化简。由上式可以推得:

说白了,将$Δ_{i,j}^{n}$看成是N行K列的矩阵,那么矩阵的每一行只能有一个1,其它都是0;如果第i行中是第j个元素为1,就意味着距离xi最近的类别中心为cj。这时候,迭代公式变为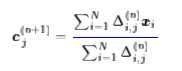
根据$Δ_{i,j}^{n}$的含义,这无外乎就是说:$c_j^{(n+1)}$就是距离$c_j^{n}$最近的那些点的平均值。
这就得到了通常我们在求解K-Means问题时,所用的迭代算法了,它也被称为EM算法。
转自:
http://spaces.ac.cn/archives/4277/
标签:基本 梯度 image 操作 目标 ace display pac isp
原文地址:http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/7274943.html