标签:方法 计算 dex learn 好的 选择 learning ima 缺点
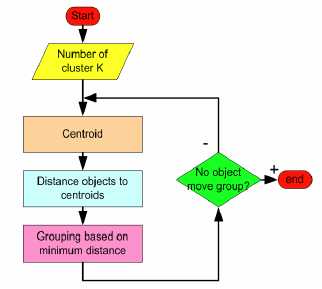
1.归类:
2.举例:
输入:k, data[n];
4.2 一个药物分类的例子:

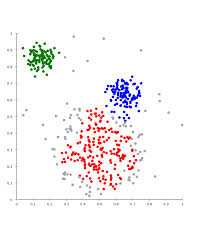
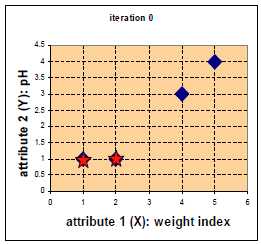
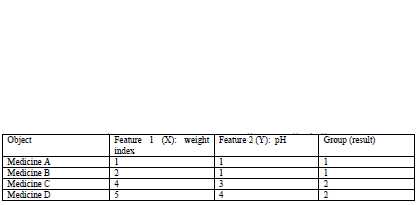
四中药物给予了 weight index 和 pH 两个特征。
在二维坐标系中的分布如下:
D0为第一次迭代,第一行为4个点到c1的距离,第二行为4个点到c2的距离。
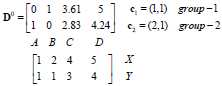
G0为第一次迭代后的归类情况,将各点到c1、c2的距离进行比较,哪个的距离小就为哪一类。
归类如下:c1为第一类,c2、c3、c4为第二类。
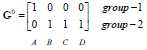
第二类的中心点更新如下:
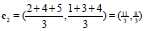
重新计算中心点如下(星为中心点):(若该类中的点变化,则更新该类的中心点;否则不更新)
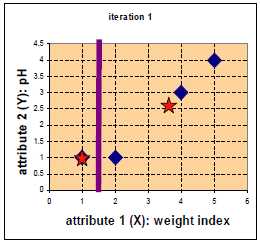
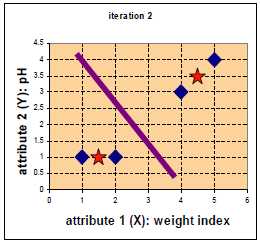
第二次迭代。
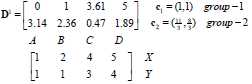
G1为第二次迭代后的归类情况。
归类如下:c1、c2为第一类,c3、c4为第二类。
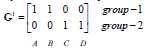
更新第一类、第二类的中心点如下:
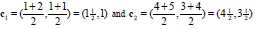
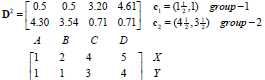
归类没有发生变化(达到终止条件)
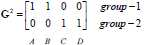
停止。
标签:方法 计算 dex learn 好的 选择 learning ima 缺点
原文地址:http://www.cnblogs.com/bahcelor/p/7277268.html