标签:磁盘 ons 重构 体系结构 全局 体系 group 集群配置 解决
Oracle RAC 运行于集群之上,为 Oracle 数据库提供了最高级别的可用性、可伸缩性和低成本计算能力。如果集群内的一个节点发生故障,Oracle 将可以继续在其余的节点上运行。Oracle 的主要创新是一项称为高速缓存合并的技术。高速缓存合并使得集群中的节点可以通过高速集群互联高效地同步其内存高速缓存,从而最大限度地低降低磁盘 I/O。高速缓存最重要的优势在于它能够使集群中所有节点的磁盘共享对所有数据的访问,数据无需在节点间进行分区。Oracle 是唯一提供具备这一能力的开放系统数据库的厂商。
RAC体系架构图:
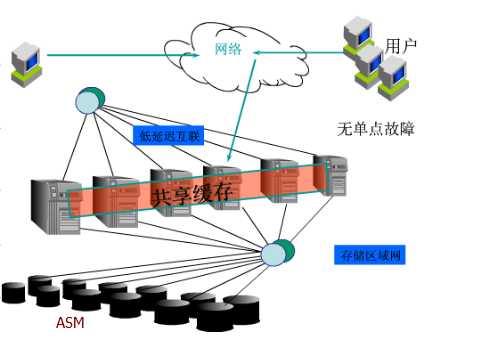
Oracle RAC 的核心是共享磁盘子系统,集群中所有节点必须能够访问所有数据、重做日志文件、控制文件和参数文件,数据磁盘必须是全局可用的,允许所有节点访问数据库,每个节点有它自己的重做日志,但是其他节点必须能够访问它们以便在那个节点出现系统故障时能够恢复。
一、RAC 的体系结构
RAC 是 Oracle 数据库的一个群集解决方案,是有着两个或者两个以上的数据库节点协调运作能力的。如下图所示:
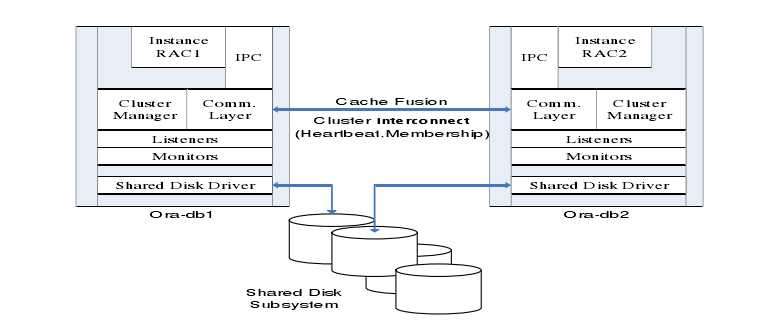
集群管理器(Cluster Manager)在集群系统中对其他各个模块进行整合,通过高速的内连接来提供群集节点之间的通信。各节点之间内连接使用心跳线互联,心跳线上的信息功能确定群集逻辑上的节点成员信息和节点更新情况,以及节点在某个时间点的运行状态,保证群集系统正常运行。
RAC 的结构组成和机制
二、RAC 服务进程
管理集群内高可用操作的基本程序
CRS管理的任何事务被称之为资源
数据库、实例、监听、虚拟IP、应用进程等等
CRS是跟据存储于OCR中的资源配置信息来管理这些资源
当一资源的状态改变时,CRS进程生成一个事件
管理集群节点的成员资格
控制哪 个结点为集群的成员、节点在加入或离开集群时通知集群成员来控制集群配置信息
此进程发生故障导致集群重启
事件管理守护进程
发布CRS创建事件的后台进程
ONS-事件的发布及订阅服务(Oracle Notification Service)
通信的快速应用通知事件的发布及订阅服务
集群注册文件,记录每个节点的相关信息
保存RAC集群的各种资源信息
类似于windows注册表
存储于共享磁盘上,所有实例共享
默认有2个互备磁盘
仲裁机制用于仲裁多个节点向共享节点财时写的行为,避免发生冲突
存储于共享磁盘上,所有实例共享
用于确定各个实例的关系
当有节点失效时,通过voting disk来决定驱逐哪个实例
默认有3个互备磁盘
三、RAC 后台进程
Oracle RAC 有一些自己独特的后台进程,在单一实例中不发挥配置作用。如下图所示,定义了一些 RAC 运行的后台进程。这些后台进程的功能描述如下。
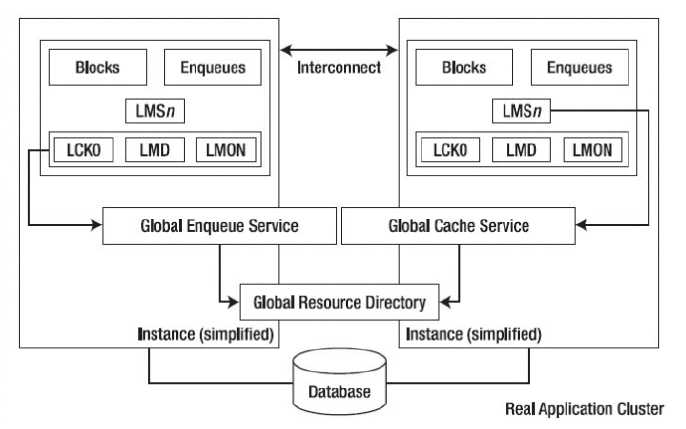
LMS(Global cache service processes 全局缓存服务进程)进程主要用来管理集群内数据块的访问,并在不同实例的 Buffer Cache 中传输数据块镜像。直接从控制的实例的缓存复制数据块,然后发送一个副本到请求的实例上。并保证在所有实例的 Buffer Cache 中一个数据块的镜像只能出现一次。LMS 进程靠着在实例中传递消息来协调数据块的访问,当一个实例请求数据块时,该实例的 LMD 进程发出一个数据块资源的请求,该请求指向主数据块的实例的 LMD 进程,主实例的 LMD 进程和正在使用的实例的 LMD 进程释放该资源,这时拥有该资源的实例的 LMS 进程会创建一个数据块镜像的一致性读然后把该数据块传递到请求该资源的实例的BUFFER CACHE 中。LMS 进程保证了在每一时刻只能允许一个实例去更新数据块,并负责保持该数据块的镜像记录(包含更新数据块的状态 FLAG)。RAC 提供了 10 个 LMS 进程(0~9),该进程数量随着节点间的消息传递的数据的增加而增加。
LMON(Lock Monitor Process,锁监控进程)是全局队列服务监控器,各个实例的 LMON 进程会定期通信,以检查集群中各个节点的健康状况,当某个节点出现故障时,负责集群重构、GRD 恢复等操作,它提供的服务叫做 Cluster Group Service(CGS)。
LMON 主要借助两种心跳机制来完成健康检查。
LMD(THE GLOBAL ENQUEUE SERVICE DAEMON,锁管理守护进程)是一个后台进程,也被称为全局的队列服务守护进程,因为负责对资源的管理要求来控制访问块和全局队列。在每一个实例的内部,LMD 进程管理输入的远程资源请求(即来自集群中其他实例的锁请求)。此外,它还负责死锁检查和监控转换超时。
LCK(THE LOCK PROCESS,锁进程)管理非缓存融合,锁请求是本地的资源请求。LCK 进程管理共享资源的实例的资源请求和跨实例调用操作。在恢复过程中它建立一个无效锁元素的列表,并验证锁的元素。由于处理过程中的 LMS 锁管理的首要职能,只有一个单一的 LCK 进程存在每个实例中。
DIAG(THE DIAGNOSABILITY DAEMON,诊断守护进程)负责捕获 RAC 环境中进程失败的相关信息。并将跟踪信息写出用于失败分析,DIAG 产生的信息在与 Oracle Support 技术合作来寻找导致失败的原因方面是非常有用的。每个实例仅需要一个 DIAG 进程。
GSD(THE GLOBAL SERVICE DAEMON,全局服务进程)与 RAC 的管理工具 dbca、srvctl、oem 进行交互,用来完成实例的启动关闭等管理事务。
GCS 和 GES 两个进程负责通过全局资源目录(Global Resource Directory GRD)维护每个数据的文件和缓存块的状态信息。当某个实例访问数据并缓存了数据之后,集群中的其他实例也会获得一个对应的块镜像,这样其他实例在访问这些数据是就不需要再去读盘了,而是直接读取 SGA 中的缓存。GRD 存在于每个活动的 instance 的内存结构中,这个特点造成 RAC 环境的 SGA 相对于单实例数据库系统的 SGA 要大。其他的进程和内存结构都跟单实例数据库差别不大。
四、脑裂
Oracle集群件使用表决磁盘来解决分区集群中的集群成员资格问题。
例如一个8节点集群,其节点之间发生通信中断,4个节点不能与另外4个节点通信。此时表决磁盘帮助确定哪一组节点应当继续正常运行,而另一组节点应当停机。
所有表决磁盘都必须放在可以供所有节点访问的共享存储上。拥有多个表决磁盘就使表决磁盘不再是单一故障点,也不需要在外部镜像它们。
Oracle RAC(Real Application Clusters)
标签:磁盘 ons 重构 体系结构 全局 体系 group 集群配置 解决
原文地址:http://www.cnblogs.com/vadim/p/7282181.html