标签:它的 开发 class 第一个 是你 png 后缀名 删除 style
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤。
第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /spark.txt,即可。
第一:看整个代码视图
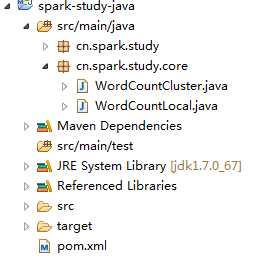
打开WordCountCluster.java源文件,修改此处代码:

第二步:
打好jar包,步骤是右击项目文件----RunAs--Run Configurations
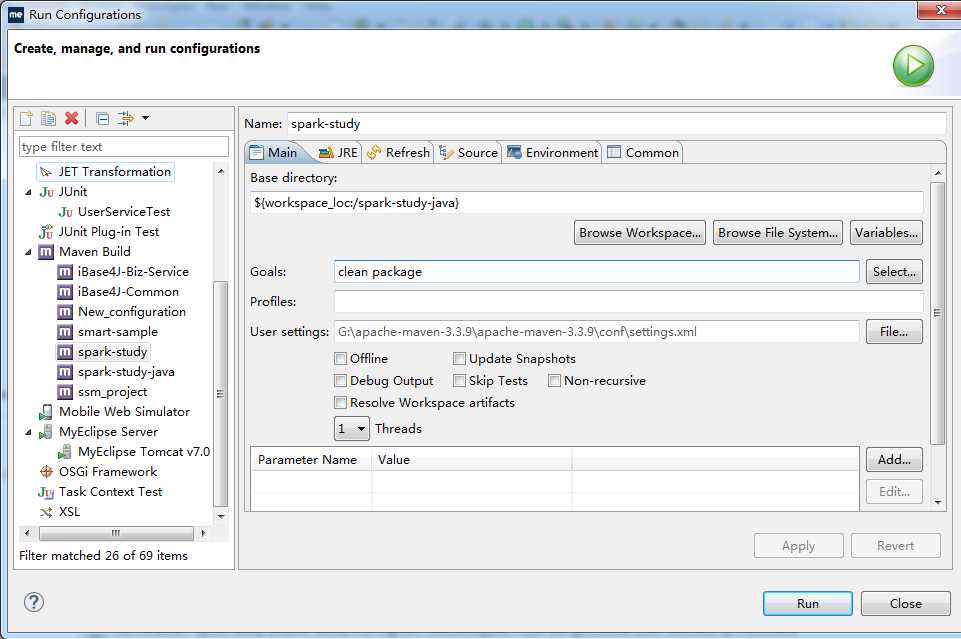
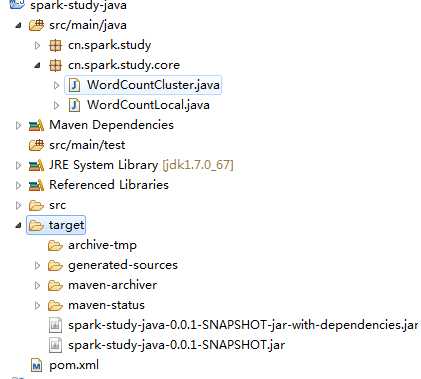
照图填写,然后开始拷贝工程下的jar包,如图,注意是拷贝那个依赖jar包,不是第二个
然后将复制到桌面的这个jar包和另外一个文件WordCount.sh上传到平台上,即拖拽到平台上
开始使用上传命令hadoop fs -put spark.txt /spark.txt。
第三步:要启动hadoop集群,启动方式见hadoop配置博文,注意,如果集群里面的datanode或者是namenode之一没有启动,则找到这样一个目录,并删除里面的文件,重新启动即可,如图:即home目录下的文件

打开home目录下的hadoop----dfs-----把里面的两个目录都删除掉,即可
第四步:此时hadoop集群已经启动,然后我们开始修改WordCount.sh配置文件
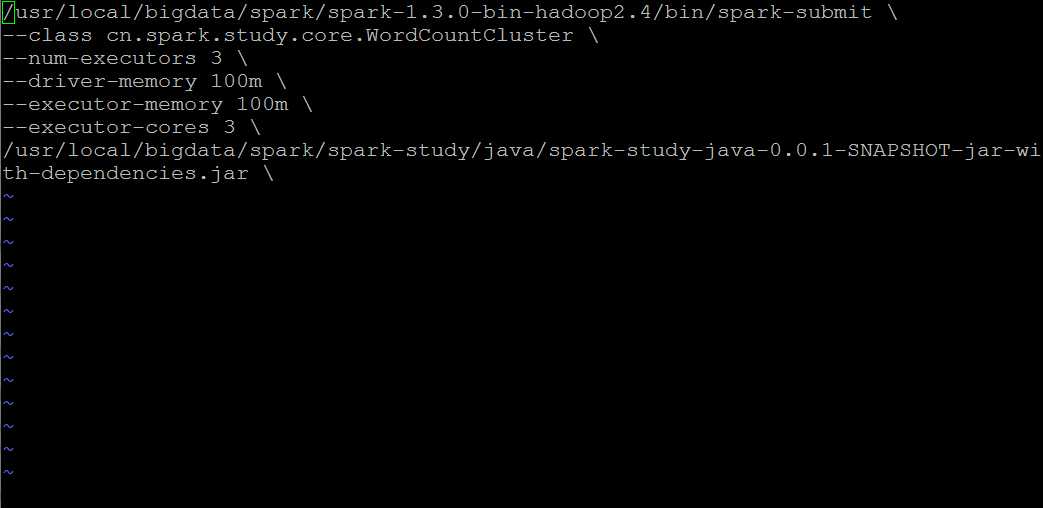
几点注意:
1,class目录必须对应你的eclipse工程下的项目目录
2,关于spark-submit提交工具,路径要和你的spark集群上面的路径一致 ,这里找的是spark集群下的bin目录里面的文件,不是spark-study下的文件,切记
3,最后一行路径就是你的上传程序jar包到平台上后的路径,注意一定是后缀为jar的文件包,不能上传其它的后缀名,一律无效。
4,注意:修改过本地eclipse的程序文件,一定要生效的话,就要重新上传打包,然后部署。
第五步,启动程序文件,即如下图,在wordcount.sh配置文件的目录下,执行以下命令即可
将java开发的wordcount程序提交到spark集群上运行
标签:它的 开发 class 第一个 是你 png 后缀名 删除 style
原文地址:http://www.cnblogs.com/hzh19870110/p/7289871.html