标签:小数点 6.4 变化 rom idle 重启 排序 均值 block
在使用Linux服务器的过程中,16个命令可以帮助我们更好的了解服务器的运行状况,做到及时发现,及时处理。排名不分先后,一一道来
1. 性能分析之 iostat 命令使用
iostat命令显示的是你的存储系统的细节状态。iostat显示系统三种类型的报告:CPU利用率、设备使用报告和网络文件系统报告等是否正常,完全可以在用户抱怨服务器慢之前,通过这个命令发现系统I/O方面的问题。
不添加任何选项执行iostat命令,执行结果如下:
$ iostat Linux 2.6.32-504.el6.x86_64 (hostname) 08/06/2017 _x86_64_ (16 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 17.66 0.00 0.29 0.01 0.00 82.04 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 0.61 0.57 12.23 19046912 408492024 dm-0 0.06 0.12 0.35 4102616 11635208 dm-1 1.50 0.45 11.88 14930226 396856672 up-0 2.29 22.92 66.40 765535386 2217711216。。。。。。
单独执行iostat,显示的结果为从系统开机到当前执行时刻的统计信息。以上输出中,除最上面指示系统内核版本、主机名、日期、系统位数和逻辑CPU个数的一行外,另有两部分:
avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值
Device: 各磁盘设备的IO统计信息
对于cpu统计信息一行,我们主要看iowait的值,它指示cpu用于等待io请求完成的时间。
Device中各列含义如下:
Device: 以sdX形式显示的设备名称
tps: 每秒进程下发的IO读、写请求数量
Blk_read/s: 每秒读扇区数量(一扇区为512bytes)
Blk_wrtn/s: 每秒写扇区数量
Blk_read: 取样时间间隔内读扇区总数量
Blk_wrtn: 取样时间间隔内写扇区总数量
我们可以使用-c选项单独显示avg-cpu部分的结果,使用-d选项单独显示Device部分的信息。
iostat常见用法:
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盘读写速度单位为KB) iostat -d -m 2 #查看TPS和吞吐量信息(磁盘读写速度单位为MB) iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
iostat -c 1 10 #查看cpu状态
2. 性能分析之 top 命令使用
top命令可以显示系统中的进程信息。默认情况下,top会按照CPU使用率从高到低来显示系统中的进程,并且每5秒刷新一次排行榜。当然,你也可以让top按照PID、进程寿命、CPU耗时、内存消耗等维度对进程进行排序。(可以使用P和M快捷键,分别是按CPU利用率排序、按内存使用量排序)通过top命令,你可以很快的发现那些失去控制或不符合预期的进程。
top - 00:33:50 up 386 days, 14:03, 1 user, load average: 0.00, 0.04, 0.01 Tasks: 425 total, 1 running, 424 sleeping, 0 stopped, 0 zombie Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 99.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 264552000k total, 197559072k used, 66992928k free, 324000k buffers Swap: 134217724k total, 25448k used, 134192276k free, 190391340k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2184 oracle -2 0 125g 16m 14m S 1.3 0.0 8:26.37 oracle 2194 oracle 20 0 125g 111m 94m S 0.7 0.0 6:09.90 oracle 2212 oracle 20 0 125g 134m 131m S 0.3 0.1 2:29.48 oracle 2494 oracle 20 0 125g 26m 24m S 0.3 0.0 1:00.81 oracle 4853 deployer 20 0 15300 1484 928 R 0.3 0.0 0:00.02 top 24221 zabbix 20 0 18480 1608 1420 S 0.3 0.0 11:28.59 zabbix_agentd
。。。。。。
默认是每个进程按照CPU使用率由高到低排序的。
上面显示的结果介绍:
第一行: 00:33:50 — 当前系统时间 386 days, 14:03 — 系统已经运行了386天14小时03分钟(在这期间没有重启过) 1 users — 当前有1个用户登录系统 load average: 0.00, 0.04, 0.01 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
批注:load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行:
Tasks — 任务(进程),系统现在共有425个进程,其中处于运行中的有1个,424个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态 0.1% us — 用户空间占用CPU的百分比。 0.2% sy — 内核空间占用CPU的百分比。 0.0% ni — 改变过优先级的进程占用CPU的百分比 99.6% id — 空闲CPU百分比 0.0% wa — IO等待占用CPU的百分比 0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比 0.0% si — 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态 264552000k total — 物理内存总量 197559072k used — 使用中的内存总量 66992928k free — 空闲内存总量 324000k buffers — 缓存的内存量
第五行:swap交换分区 134217724k total — 交换区总量 25448k used — 使用的交换区总量 134192276k free — 空闲交换区总量 190391340k cached — 缓冲的交换区总量
第六行是空行
第七行以下:各进程(任务)的状态监控 PID — 进程id USER — 进程所有者 PR — 进程优先级 NI — nice值。负值表示高优先级,正值表示低优先级 VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA SHR — 共享内存大小,单位kb S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 %CPU — 上次更新到现在的CPU时间占用百分比 %MEM — 进程使用的物理内存百分比 TIME+ — 进程使用的CPU时间总计,单位1/100秒 COMMAND — 进程名称(命令名/命令行)
top的交互命令
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
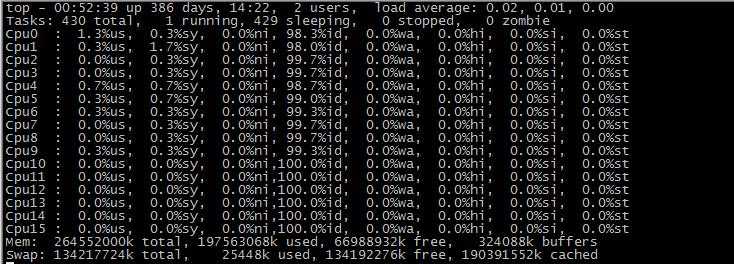
加亮显示一些重要信息
在top基本视图中,按键盘数字“B”,可监控每个逻辑CPU的状况:
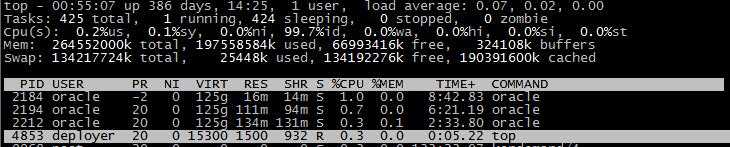
对于加亮显示x轴/y轴特别显示出来
我们发现进程id为10704的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
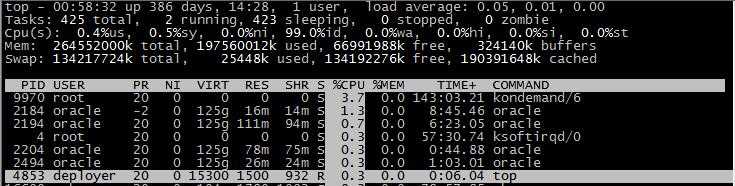
常用top操作总结:
top //每隔5秒显式所有进程的资源占用情况 top -d 2 //每隔2秒显式所有进程的资源占用情况 top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名) top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况 top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
3. 性能分析之 vmstat 命令使用
vmstat命令是Virtual Meomory Statistics(虚拟内存统计)的缩写,是常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率、内存使用、虚拟内存交换情况、IO读写情况。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
$ vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 1546380 234820 324792 309540 0 0 0 2 0 0 0 0 99 0 0
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
$ vmstat 2
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 1546380 235440 324796 309668 0 0 0 2 0 0 0 0 99 0 0
0 0 1546380 235308 324796 309668 0 0 0 78 857 1840 0 0 99 0 0
0 0 1546380 235640 324796 309688 0 0 0 20 1068 1959 0 1 99 0 0
0 0 1546380 235284 324796 309696 0 0 0 8 1517 2137 1 1 98 0 0
1 0 1546380 235284 324796 309696 0 0 0 14 986 1879 0 0 99 0 0
0 0 1546380 235284 324796 309700 0 0 0 0 948 1908 0 0 99 0 0
以上监控结果参数解释如下:
FIELD DESCRIPTION FOR VM MODE
Procs
r: The number of processes waiting for run time.
b: The number of processes in uninterruptible sleep.
Memory
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory. (-a option)
active: the amount of active memory. (-a option)
Swap
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
IO
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
4. 性能分析之 mpstat命令使用
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPU系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核cpu中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况。
mpstat使用语法:
mpstat [-P {|ALL}] [internal [count]]
参数 解释
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间、
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
mpstat使用示例如下:
查看多核CPU核心的当前运行状况信息, 每2秒更新一次,更新5次
$ mpstat 2 5 Linux 2.6.32-504.el6.x86_64 (resuathenan) 08/07/2017 _x86_64_ (8 CPU) 12:03:08 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 12:03:10 PM all 0.94 0.00 0.82 0.00 0.00 0.00 0.00 0.00 98.24 12:03:12 PM all 0.25 0.00 0.44 0.00 0.00 0.00 0.00 0.00 99.31 12:03:14 PM all 0.44 0.00 0.50 0.06 0.00 0.00 0.00 0.00 99.00 12:03:16 PM all 0.88 0.00 0.82 0.00 0.00 0.00 0.00 0.00 98.30 12:03:18 PM all 0.63 0.00 0.44 0.00 0.00 0.00 0.00 0.00 98.94 Average: all 0.63 0.00 0.60 0.01 0.00 0.00 0.00 0.00 98.76
如果要看每个cpu核心的详细当前运行状况信息,输出如下:
$ mpstat -P ALL 2 1 Linux 2.6.32-504.el6.x86_64 (resuathenan) 08/07/2017 _x86_64_ (8 CPU) 12:05:55 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 12:05:57 PM all 0.63 0.00 0.44 0.00 0.00 0.00 0.00 0.00 98.93 12:05:57 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 12:05:57 PM 1 0.51 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.49 12:05:57 PM 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 12:05:57 PM 3 0.50 0.00 0.50 0.50 0.00 0.00 0.00 0.00 98.50 12:05:57 PM 4 0.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.00 12:05:57 PM 5 2.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.00 12:05:57 PM 6 0.50 0.00 1.51 0.00 0.00 0.00 0.00 0.00 97.99 12:05:57 PM 7 1.01 0.00 1.01 0.00 0.00 0.00 0.00 0.00 97.99 Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 0.63 0.00 0.44 0.00 0.00 0.00 0.00 0.00 98.93 Average: 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 Average: 1 0.51 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.49 Average: 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 Average: 3 0.50 0.00 0.50 0.50 0.00 0.00 0.00 0.00 98.50 Average: 4 0.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.00 Average: 5 2.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.00 Average: 6 0.50 0.00 1.51 0.00 0.00 0.00 0.00 0.00 97.99 Average: 7 1.01 0.00 1.01 0.00 0.00 0.00 0.00 0.00 97.99
字段含义解释:
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100 %nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100 %sys 在internal时间段里,内核时间(%) (system/total)*100 %iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100 %irq 在internal时间段里,硬中断时间(%) (irq/total)*100 %soft 在internal时间段里,软中断时间(%) (softirq/total)*100 %idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
计算公式如下:
total_cur=user+system+nice+idle+iowait+irq+softirq total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq user=user_cur – user_pre total=total_cur-total_pre 其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
标签:小数点 6.4 变化 rom idle 重启 排序 均值 block
原文地址:http://www.cnblogs.com/secdata/p/7292166.html