标签:style blog http color os io 使用 java ar
原文链接 http://www.cnblogs.com/nanxin/archive/2013/03/27/2984320.html
前言
最近做一个搜索项目,需要爬取很多网站获取需要的信息。在爬取网页的时候,需要获得该网页的编码,不然的话会发现爬取下来的网页有很多都是乱码。
分析
一般情况下,网页头信息会指定编码,可以解析header或者meta获得charset。但有时网页并没没有指定编码,这时就需要通过网页内容检测编码格式,通过调研,最好用的还是cpdetector。
cpdetector自动检测文本编码格式,谁先返回非空,就以该结果为字符编码。内置了一些常用的探测实现类,这些探测实现类的实例可以通过add方法加进来,如
 等,detector按照“谁先返回非空的探测结果,就以谁的结果为准”的原则返回探测到的字符集编码。
等,detector按照“谁先返回非空的探测结果,就以谁的结果为准”的原则返回探测到的字符集编码。
1、首先,可从header中解析charset
网页头信息中的Content-Type会指定编码,如图:
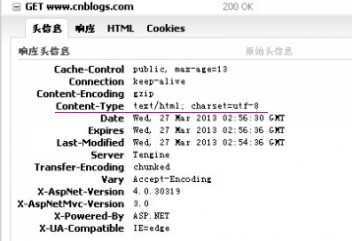
可以通过分析header,查找字符编码。

Map<String, List<String>> map = urlConnection.getHeaderFields();
Set<String> keys = map.keySet();
Iterator<String> iterator = keys.iterator();
// 遍历,查找字符编码
String key = null;
String tmp = null;
while (iterator.hasNext()) {
key = iterator.next();
tmp = map.get(key).toString().toLowerCase();
// 获取content-type charset
if (key != null && key.equals("Content-Type")) {
int m = tmp.indexOf("charset=");
if (m != -1) {
strencoding = tmp.substring(m + 8).replace("]", "");
return strencoding;
}
}
}
2、其次,可从网页meta中解析出charset
正常情况下,在写网页时,会指定网页编码,可在meta中读出来。如图:
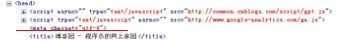
首先获取网页流,因为英文和数字不会乱码,可以解析meta,获得charset。
StringBuffer sb = new StringBuffer();
String line;
try {
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream()));
while ((line = in.readLine()) != null) {
sb.append(line);
}
in.close();
} catch (Exception e) { // Report any errors that arise
System.err.println(e);
System.err
.println("Usage: java HttpClient <URL> [<filename>]");
}
String htmlcode = sb.toString();
// 解析html源码,取出<meta />区域,并取出charset
String strbegin = "<meta";
String strend = ">";
String strtmp;
int begin = htmlcode.indexOf(strbegin);
int end = -1;
int inttmp;
while (begin > -1) {
end = htmlcode.substring(begin).indexOf(strend);
if (begin > -1 && end > -1) {
strtmp = htmlcode.substring(begin, begin + end).toLowerCase();
inttmp = strtmp.indexOf("charset");
if (inttmp > -1) {
strencoding = strtmp.substring(inttmp + 7, end).replace(
"=", "").replace("/", "").replace("\"", "")
.replace("\‘", "").replace(" ", "");
return strencoding;
}
}
htmlcode = htmlcode.substring(begin);
begin = htmlcode.indexOf(strbegin);
}
3、当使用1、2解析不出编码时,使用cpdetector根据网页内容探测出编码格式
可以添加多个编码探测实例:
public static void getFileEncoding(URL url) throws MalformedURLException, IOException {
CodepageDetectorProxy codepageDetectorProxy = CodepageDetectorProxy.getInstance();
codepageDetectorProxy.add(JChardetFacade.getInstance());
codepageDetectorProxy.add(ASCIIDetector.getInstance());
codepageDetectorProxy.add(UnicodeDetector.getInstance());
codepageDetectorProxy.add(new ParsingDetector(false));
codepageDetectorProxy.add(new ByteOrderMarkDetector());
Charset charset = codepageDetectorProxy.detectCodepage(url);
System.out.println(charset.name());
}
}
标签:style blog http color os io 使用 java ar
原文地址:http://www.cnblogs.com/qingchen1984/p/3955289.html