Python 3.0在2008年12月3日正式发布,在之后又经历了多个小版本(3.1,3.2,3.3……),本文梳理Python 3.0之后的新特性。已更新到3.6版,会持续更新下去。
其实每个版本都有大量更新,都写出来要几百页,这里只写主要的更新,以及我个人认为重要的。
因此难免有失偏颇,望见谅,可以点击小标题查看每个版本的完整What‘s New。
Python 3.1 2009年6月27日发布
▲用C语言实现io模块。在3.0,io模块是用Python语言实现的,性能很慢,现在比3.0快了2~20倍。
▲新增OrderedDict类,能记住元素添加顺序的字典。举个用例:读取一个.ini文件,处理之后还能按原始顺序输出。
▲嵌套的with语句可以写在同一行:
with A() as a, B() as b: suite # 等同于以前的 with A() as a: with B() as b: suite
▲更易懂的浮点数表示。由于浮点数在CPU内部的存在形式,repr(1.1)会显示为‘1.1000000000000001‘。现在显示为‘1.1‘,尽量确保eval(repr(f)) == f。
▲新增collections.Counter类,用于计数元素在序列中出现的次数:
>>> Counter([‘red‘, ‘blue‘, ‘red‘, ‘green‘, ‘blue‘, ‘blue‘]) Counter({‘blue‘: 3, ‘red‘: 2, ‘green‘: 1})
▲str.format()支持自动编号:
"{} is {} {}".format(‘A‘, ‘B‘, ‘C‘) # 相当于 "{1} is {2} {3}".format(‘A‘, ‘B‘, ‘C‘)
▲format()和str.format()支持千分位分隔符:
>>> format(1234567, ‘,‘) ‘1,234,567‘ >>> format(1234567.837, ‘,.2f‘) ‘1,234,567.84‘
▲新增tkinter.ttk模块。使tkinter控件呈现操作系统本地化风格,在windows下像windows,在mac下像mac,在linux下像linux。tkinter.ttk还包含了6个以前缺失的常用控件:Combobox, Notebook, Progressbar, Separator, Sizegrip, Treeview。
▲round(x, n),如果x是整数,则返回一个整数。之前返回的是一个浮点数。
▲itertools新增两个函数:

# 一个排列组合函数 combinations_with_replacement >>> [p+q for p,q in combinations_with_replacement(‘LOVE‘, 2)] [‘LL‘, ‘LO‘, ‘LV‘, ‘LE‘, ‘OO‘, ‘OV‘, ‘OE‘, ‘VV‘, ‘VE‘, ‘EE‘] # 一个按true进行选择的函数 compress >>> list(compress(data=[0,1,2,3,4,5,6,7,8,9], selectors=[0,0,1,1,0,1,0,1,0,0])) [2, 3, 5, 7]
▲如果一个目录或一个zip文件里有__main__.py文件,把目录名或zip文件名传给Python解释器就可以启动程序。
▲新增importlib模块。把import的功能做成模块,并提供一些相关API。
▲64位版的int快了27%~55%。以前32位版、64位版int的计算单元都是15比特,现在64位版是30个比特。
▲UTF-8、UTF-16、LATIN-1编码的decode速度是以前的2~4倍。
▲json模块用C语言扩展,性能更快。
Python 3.2 2011年2月20日发布
▲新增argparse模块,解析命令行参数。用于替代功能有限的optparse模块。
▲新增concurrent.futures模块。定义了异步运行callable对象的接口(Future类),并提供了两个异步运行管理器:线程池、进程池。
▲标准库进行了大量改进,主要的几个改进:
- email、mailbox、nntplib这3个模块能更好的处理bytes/str混合的情况。
- ssl模块加入许多新东西,更好的SSL连接和安全认证。
- 有更多的类实现了上下文管理器,可以用于with语句。
▲增加html模块。在Python 3.2里,只有escape一个函数,用于转义html字符:
>>> html.escape(‘x > 2 && x < 7‘) ‘x > 2 && x < 7‘
▲增加functools.lru_cache()装饰器,用于缓存函数的参数和返回值。以相同的参数再次调用函数时,不必再执行函数,直接返回缓存的返回值。
▲itertools增加accumulate函数。累加(也可进行累减、累乘、累X等操作):
>>> from itertools import accumulate >>> list(accumulate([8, 2, 50])) [8, 10, 60]
▲字节串decode时支持‘strict‘和‘ignore‘错误处理,字符串encode时支持‘strict‘和‘replace‘错误处理。
▲优化表达式 x in {1, 2, 3}的性能。如果集合的元素都是常量,在编译时就会被放到一个frozenset里。
if extension in {‘xml‘, ‘html‘, ‘xhtml‘, ‘css‘}:
do(something)
▲优化pickle模块。性能快了数倍。
▲优化list.sort()和sorted()。当使用key参数时,比以前快15%~40%。
▲logging模块新增基于dict的配置方式,配置方式更灵活一些。
▲WSGI版本更新到1.0.1。WSGI是Python程序和Web服务器之间的一种通用接口(详细介绍),1.0.1仅为Python3做了少量修改。
▲定义了一套稳定的ABI(二进制接口)。以前,每发布一个版本的Python,就要把第三方扩展重新编译一遍;现在提供了一套有限但稳定的ABI,很多情况下不必重新编译了。见PEP 384。
▲改进.pyc文件的命名方式,以便区分不同版本Python生成的.pyc文件。
▲更新Unicode数据到6.0。
Python 3.3 2012年9月29日发布
▲新增yield from语法,见PEP 380:
yield from g # 等同于以前的 for v in g: yield v
此外,yield from在外部调用者和内部生成器之间建立一个透明通道,简化中间环节的一些处理,见参考1、参考2。
▲重新组织了操作系统相关异常的体系。更简化、有更好的粒度,并且基本上不必处理errno了。见PEP 3151。
▲新增lzma压缩模块,就是7-zip使用的压缩算法。
▲新增ipaddress模块,用于处理IPv4、IPv6的IP地址,详细介绍。
▲新增pathlib模块,用面向对象的方式表示磁盘路径。使代码独立于操作系统,可以在Windows上处理linux路径、或反之。
▲新增venv模块。用于创建虚拟环境,每个虚拟环境都能安装一套独立的第三方模块,可以更灵活的部署多个项目。
▲新增faulthandler模块。用于调试,能找出crash、超时、死锁等问题发生的位置。
▲新增unittest.mock模块。用于测试,可以模拟某个对象(类、实例、函数)的行为,从而方便测试。(详细介绍)
▲memoryview类的实现做了大量改进。memoryview可直接访问一个对象的内部数据(要求该对象支持Buffer Protocol协议),从而避免复制数据,当数据非常大时很有用。
▲用C语言重写了decimal模块,比以前快12倍(数据库操作)~120倍(高密度计算)。
▲随机hash。用一个随机数参与hash值的计算,这个随机数在启动python时生成。防止hash性能攻击。
▲字符串的内部存储更灵活。以前每个Unicode字符都占4字节,现在根据整个字符串的需要占1、2、4字节(日常使用的汉字基本上就用2个字节)。在一项Django测试中,内存使用比以前少了2~3倍。见PEP 393。
▲新增Windows下的启动器,py.exe和pyw.exe。
如果同时安装了多个版本的Python,比如python 2.7、3.2、3.3(32位版、64位版),可以指定启动的版本:
# 启动Python 3.2
py -3.2
# 用Python 2.7运行a.py py -2.7 a.py # 用Python 3的最高版本运行a.py py -3 a.py
# 用Python 3.3 32位版运行a.py py -3.3-32 a.py
另外,在.py文件的第一行像这样写上Python版本,用py a.py命令运行就会使用指定的版本:(类似linux的shebang line)
#! python2.7 #! python3
▲xml.etree.ElementTree默认使用C语言加速,以提高性能。
▲utf-8编码快了2~4倍,utf-16编码的encode最多快了10倍。
▲增加可以共享key的字典。同一个类的多个实例,它们储存属性的字典现在可以共享key和hash了,当有大量实例时能节省内存。见PEP 412。
▲增加python 2的字符串u修饰符:u‘this is a string‘。这个在python 3里没意义,仅仅是为了python 2程序迁移更方便。
▲更新Unicode数据到6.1。
Python 3.4 2014年3月16日发布
▲集成了pip。用于安装、更新、卸载pypi上的第三方模块。
▲新增asyncio模块,关于协程的模块。这个模块提供了一个协程的事件循环器,以及一些具体工具。(线程、进程是互争资源,而协程是互让资源,主要用于异步处理并发I/O。协程是用生成器实现的。)
▲新增enum模块,提供枚举。好多人抱怨python没有枚举,现在有了,虽然是以模块的方式实现的。
▲新增statistics模块。提供了基本的统计功能,比如平均值、中位数、方差、标准差等。
▲新增selectors模块。基于已有的select模块,提供了一个更高级的接口。这两个模块用于IO复用模型(select、poll、epoll等)。
▲新增tracemalloc模块。一个调试工具,用于追踪、统计python的内存分配。
▲html模块新增unescape函数。用于反转义html字符。
>>> html.unescape(‘x > 2 && x < 7‘) ‘x > 2 && x < 7‘
▲functools模块新增singledispatch装饰器。用于定义单分派函数——传入不同类型的参数,函数可以有不同行为:
>>> @singledispatch ... def fun(arg): ... print(‘default‘, arg) ... >>> @fun.register(int) ... def _(arg): ... print(‘int‘, arg) ... >>> fun(‘hello‘) default hello >>> fun(123) int 123
▲pickle新增第4版协议。支持嵌套的类、巨大的对象、更多的类型,以及其它一些改进。但是直到python 3.6,pickle的默认协议还是第3版。
▲默认情况下,新创建文件的文件描述符不再允许被新进程(如子进程)使用。
▲python解释器的启动快了30%。
▲改进str和bytes的hash算法,更能抵御DOS攻击。并且允许在编译CPython时更换别的hash算法。
▲允许在编译CPython时更换内存分配器。
▲启用Argument Clinic。在C语言写的底层函数被Python代码调用时,须要把参数解析成C语言的形式,使用Argument Clinic能更简便的生成参数解析代码。见PEP 436。
▲更新Unicode数据到6.3。
Python 3.5 2015年9月13日发布
▲为协程新增async和await语句,见PEP 492(中文版):
1、把协程的概念从生成器独立出来,并为之添加了async/await语句。
async def read_data(db): data = await db.fetch(‘SELECT ...‘) ...
注:在CPython的内部实现,协程仍然是一个生成器。
2、增加“异步迭代器”,异步迭代器的__aiter__、__anext__函数是协程,可以将程序挂起。
async for data in cursor: ...
3、增加“异步上下文管理器”,异步上下文管理器的__aenter__、__aexit__函数是协程,可以将程序挂起。
async with lock:
...
▲新增矩阵乘法运算符@,如a @ b。
▲解包(unpacking)。*用于可迭代对象,**用于字典,见PEP 448:
>>> *range(4), 4 (0, 1, 2, 3, 4) >>> [*range(4), 4] [0, 1, 2, 3, 4] >>> {*range(4), 4, *(5, 6, 7)} {0, 1, 2, 3, 4, 5, 6, 7} >>> {‘x‘: 1, **{‘y‘: 2}} {‘x‘: 1, ‘y‘: 2}
▲新增zipapp模块。把Python程序用Zip打包到一个可执行的.pyz文件,见PEP 441。
# 生成.pyz可执行压缩包 python -m zipapp myapp -m "myapp:main" # 以后就可以这样运行myapp了,也可以鼠标双击.pyz文件运行 python myapp.pyz
▲允许bytes类型使用%格式化:
>>> b‘Hello %b!‘ % b‘World‘ b‘Hello World!‘ >>> b‘x=%i y=%f‘ % (1, 2.5) b‘x=1 y=2.500000‘
▲新增Type Hints和typing模块。方便(IDE等工具)静态分析代码,程序在实际运行时会忽略掉这些东西。见PEP 484。
# 使用Type Hints声明:参数name的类型是str,函数返回值的类型是int def namelength(name: str) -> int: return len(name)
其实在Python 3.0就增加了函数注释(Function annotation,PEP 3107),但是函数注释可以很随意:
def namelength(name: ‘参数是一个字符串‘) -> ‘返回值是一个整数‘: return len(name)
这次的Type Hints采用了函数注释的语法,结合一定规范、typing模块,可以精确定义参数、返回值的类型。
▲bytes、bytearray、memoryview新增.hex()函数:
>>> b‘\xf0\xf1\xf2‘.hex() ‘f0f1f2‘
▲math模块新增math.isclose()函数,判断两个数值是否相近,可以忽略浮点表示法带来的误差:
>>> math.isclose(1.1, 1.1000000000000001)
True
另增加math.gcd()函数,计算最大公约数。
▲新增os.scandir()函数,更快、更省内存的遍历文件夹。在POSIX系统上比以前快3~5倍,在Windows系统上快7~20倍。os.walk()目前也在使用此函数。
▲用C语言重写了OrderedDict,快了4~100倍。
▲functools.lru_cache()的大部分改用C语言实现,快了10~25倍。
▲Windows版由VC2015编译,并且要求所有扩展也用VC2015编译。
▲Python 3.5不再支持Windows XP及之前的系统,Python 3.4成了XP能用的最高版本。
▲提供Windows下的免安装绿色版,仅适合打包发布、不适合用于开发。在官网下载:Windows x86/x86-64 embeddable zip file。
▲不再使用.pyo文件名。-O和-OO选项不再生成xxx.pyo文件,而是分别生成xxx.opt-1.pyc和xxx.opt-2.pyc。
▲更新Unicode数据到8.0。
Python 3.6 2016年12月23日发布
▲在f""修饰的字符串里直接使用变量,见PEP 498:
>>> name = "Fred" >>> f"He said his name is {name}." ‘He said his name is Fred.‘ >>> age = 50 >>> f"My age next year is {age+1}." ‘My age next year is 51.‘
▲在代码中,可以用下划线增加数值的可读性。见PEP 515。
# 下划线可以出现在数字之间、进制指示符之后。
# 不能出现在首、尾,也不能出现连续的。 amount = 10_000_000.0 addr = 0xCAFE_F00D flags = 0b_0011_1111_0100_1110 # 也能作用于字符串转换 flags = int(‘0b_1111_0000‘, 2)
▲新增“异步生成器”。现在某些“异步迭代器”可以简化成“异步生成器”了,见PEP 525。
async def ticker(delay, to): """每隔delay秒,yield一个从0到to的数字""" for i in range(to): yield i await asyncio.sleep(delay)
▲新增“异步生成式”。在list、set、dict的生成式中,可以(通过async for)使用异步迭代器,也可以(通过await)调用协程。见PEP 530。
# 可以用async for语句使用异步迭代器 result = [i async for i in aiter() if i % 2] # 也可以用await语句调用协程 result = {await fun() for fun in funcs}
# 同时使用await和async for语句
result = {fun: await fun() async for fun in funcs if await something}
▲新增secrets模块,生成强随机数。以前的random模块只能生成伪随机数,官方推荐在涉及安全问题时不再使用random模块。
▲hashlib模块新增SHA-3算法。这个算法包括4个hash函数:SHA3-224、SHA3-256、SHA3-384、SHA3-512,输出是末尾数字指定的比特数;还包括2个扩展hash函数:SHAKE128、SHAKE256,输出是不大于128或256的任意比特数。
▲新增变量注释(Variable Annotations)。和Type Hints类似,用于(IDE等工具)静态分析代码。见PEP 526。
# 声明primes是列表,其元素的类型为int。并给primes赋值一个空列表。 primes: List[int] = [] # 声明captain的类型是str,注意这里无初始值 captain: str # 声明stats是类变量,类型是字典(key的类型为str、value的类型为int)。并给stats赋值一个空字典。 class Starship: stats: ClassVar[Dict[str, int]] = {}
▲更简便地自定义类的创建。有些情况下不必使用元类了,见PEP 487。
class Philosopher: # 增加__init_subclass__方法 # 在创建子类时,会调用父类的__init_subclass__,cls参数是子类 def __init_subclass__(cls, default_name, **kwargs): super().__init_subclass__(**kwargs) cls.default_name = default_name class AustralianPhilosopher(Philosopher, default_name="Bruce"): pass
PEP 487另给descriptor增加__set_name__方法。在创建descriptor所属的类时被调用,让descriptor可以感知被赋予的变量名。
▲普通的字典现在能记住元素的添加顺序。
这不是Python的改动,仅是CPython的改动,因此官方并不鼓励用户依赖它的顺序。
▲得益于字典的顺序,3.6有两个改动:
1,函数的参数**kwargs可以保留顺序,见PEP 468。
def save(node, **kwargs): .... # 现在能记住参数id、href、title出现的顺序了 save(mynode, id=i, href=url, title=s)
2,能记住“类属性”的定义顺序,见PEP 520。在以前,需要定义一个元类才能知道a、b、c的定义顺序。
class MyClass: a = 1 b = 2 c = 3
▲现在,global和nolocal语句必须出现在实际使用该变量之前。不这样的话,在以前仅会给一个SyntaxWarning。
▲新增(文件系统)路径协议:如果一个对象有.__fspath__(self)函数、并且返回值是str或bytes类型,则说明这个对象能表示路径。同时增加os.fspath函数,与__fspath__配套使用。
主要目的:(1)防止不相关的对象在str(obj)后被误当作路径使用,(2)统一各模块表示路径的接口。见PEP 519。
▲给datetime.time和datetime.datetime的对象增加.fold属性。用于区分两个相同(但UTC不同)的当地时间,常见于夏令时结束的那天。如图,横轴是UTC时间,纵轴是当地时间:
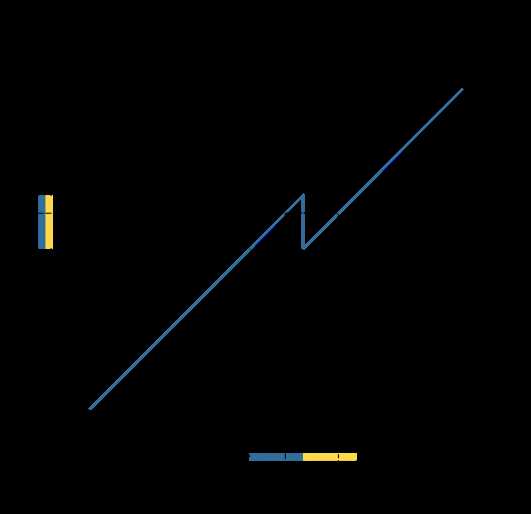
▲在Windows操作系统上,CPython与控制台的通讯使用Unicode编码(CPython <-> utf-8 <-> utf-16-le <-> Windows操作系统),而不再使用当前的Code Page。见PEP 528。
好处是可以print、input所有Unicode字符(前提是字体也支持)。
# 一段代码,print一个印度字符 print(‘?‘) # 在Python 3.5上,?被encode成当前Code Page发往控制台,会出现异常: Traceback (most recent call last): File "test.py", line 2, in <module> print(‘\u0d33‘) UnicodeEncodeError: ‘gbk‘ codec can‘t encode character ‘\u0d33‘ in position 0: illegal multibyte sequence # 在Python 3.6上,会encode成unicode(先utf-8、再utf-16-le)发往控制台,可以打印。
# (由于控制台字体的原因,可能会显示成方块): ?
与此类似,CPython与Windows文件系统的通讯编码也从当前的Code Page改成Unicode了,见PEP 529。
▲用C语言实现asyncio.Future类和asyncio.Task类,asyncio程序的性能快了25%~30%。
▲glob模块的glob()函数和iglob()函数现在使用os.scandir()函数。快了3~6倍。
▲pathlib.Path模块的glob()函数现在使用os.scandir()函数。快了1.5~4倍。
▲增加一个frame evaluation的C语言API,为第三方给CPython实现函数级JIT引擎提供了可能,IDE也可以用这个API实现性能更快的调试功能,见PEP 523。
▲更新Unicode数据到9.0。Unicode 9.0支持西夏文字。
Python 3.7 预计2018年6月15日发布
……