标签:latest log index settings 9.png ext import 技术 ebs
1.创建一般的爬虫:一般来说,小于100次访问的爬虫都无须为此担心
(1)以爬取美剧天堂为例,来源网页:http://www.meijutt.com/new100.html,项目准备:
scrapy startproject meiju100
F:\Python\PythonWebScraping\PythonScrapyProject>cd meiju100
F:\Python\PythonWebScraping\PythonScrapyProject\meiju100>scrapy genspider meiju100Spider meijutt.com
项目文件结构:
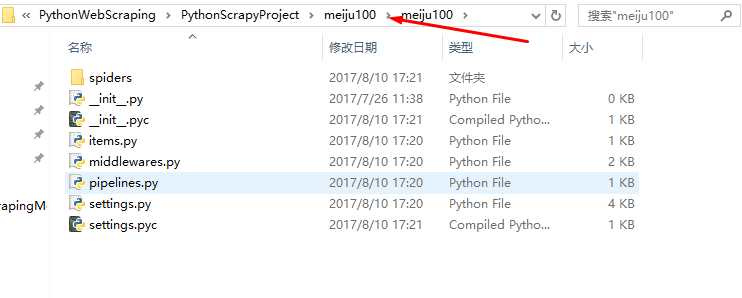
(2)修改items.py文件:
(3)修改meiju100Spider.py文件:
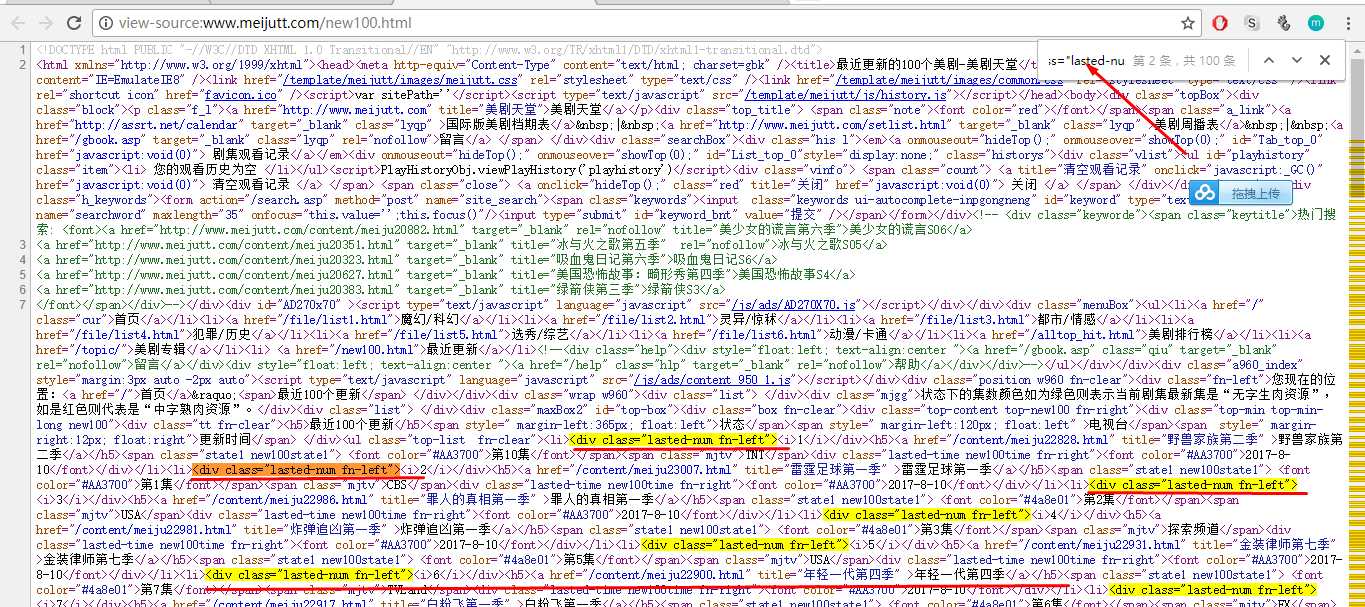
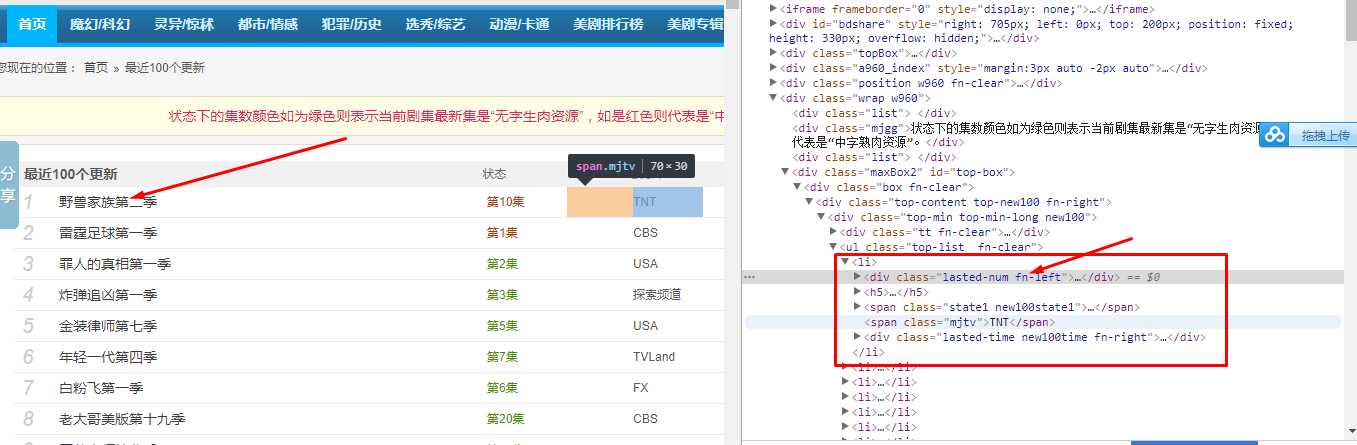
先检查网页源代码:发现<div class="lasted-num fn-left">开头的标签,包含所需数据:
# -*- coding: utf-8 -*-
import scrapy
from meiju100.items import Meiju100Item
class Meiju100spiderSpider(scrapy.Spider):
name = ‘meiju100Spider‘
allowed_domains = [‘meijutt.com‘]
start_urls = (
‘http://www.meijutt.com/new100.html‘
)
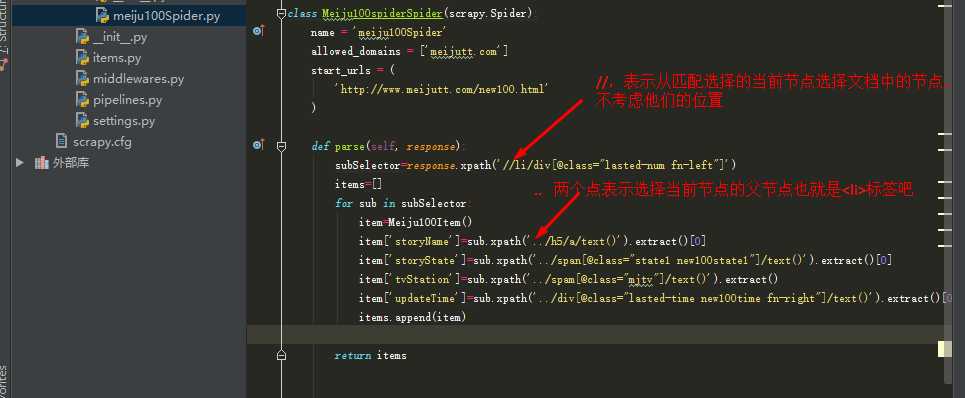
def parse(self, response):
subSelector=response.xpath(‘//li/div[@class="lasted-num fn-left"]‘)
items=[]
for sub in subSelector:
item=Meiju100Item()
item[‘storyName‘]=sub.xpath(‘../h5/a/text()‘).extract()[0]
item[‘storyState‘]=sub.xpath(‘../span[@class="state1 new100state1"]/text()‘).extract()[0]
item[‘tvStation‘]=sub.xpath(‘../span[@class="mjtv"]/text()‘).extract()
item[‘updateTime‘]=sub.xpath(‘//div[@class="lasted-time new100time fn-right"]/text()‘).extract()[0] //运行报错:IndexError: list index out of range,<div class="lasted-time new100time fn-right">不属于上边的父节点
items.append(item)
return items
(4)编写pipelinses.py文件,保存爬取的数据到文件夹:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don‘t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
class Meiju100Pipeline(object):
def process_item(self, item, spider):
today=time.strftime(‘%Y%m%d‘,time.localtime())
fileName=today+‘meiju.txt‘
with open(fileName,‘a‘) as fp:
fp.write("%s \t" %(item[‘storyName‘].encode(‘utf8‘)))
fp.write("%s \t" %(item[‘storyState‘].encode(‘utf8‘)))
if len(item[‘tvStation‘])==0:
fp.write("unknow \t")
else:
fp.write("%s \t" %(item[‘tvStation‘][0]).encode(‘utf8‘))
fp.write("%s \n" %(item[‘updateTime‘].encode(‘utf8‘)))
return item
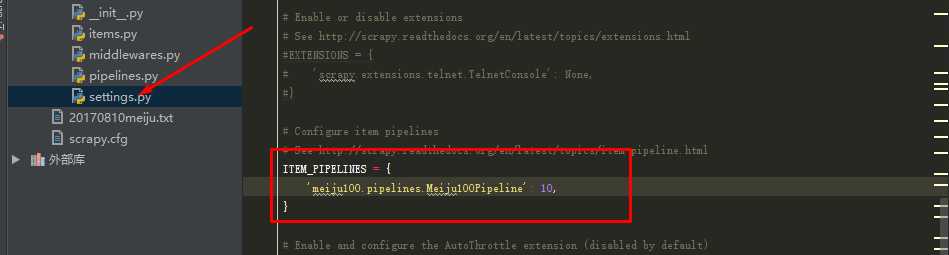
(5)修改settings.py文件:
(6)在meiju项目下任意目录下,运行命令:scrapy crawl meiju100Spider
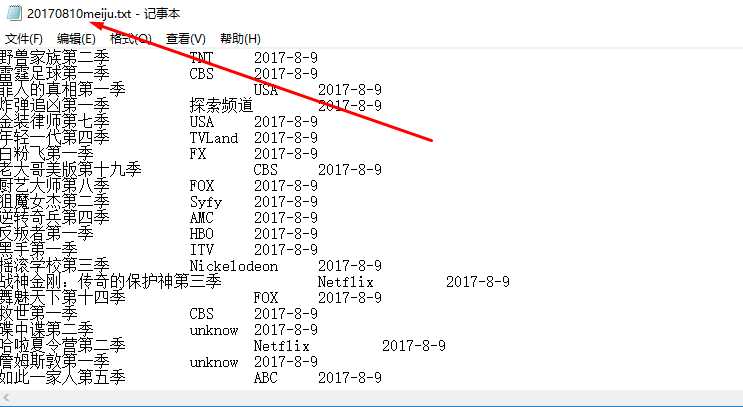
运行结果:
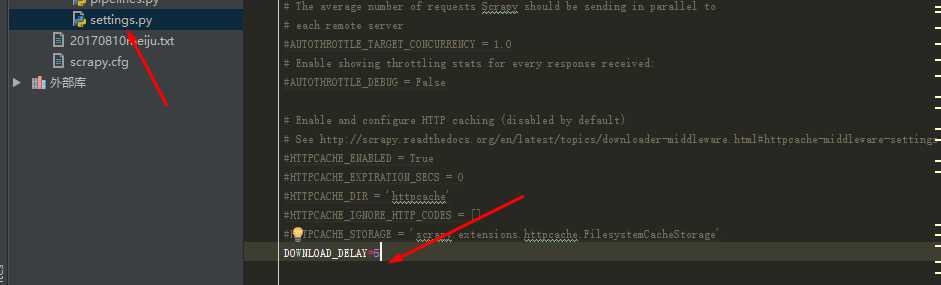
2.封锁间隔时间破解:Scrapy在两次请求之间的时间设置DOWNLOAD_DELAY,如果不考虑反爬虫的因素,这个值当然是越小越好,
如果把DOWNLOAD_DELAY的值设置为0.1,也就是每0.1秒向网站请求一次网页。
所以,需要在settings.py的尾部追加这一项即可:
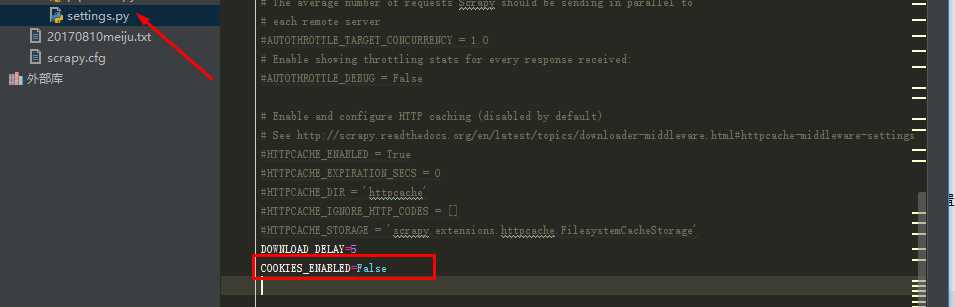
3.封锁Cookies破解:总所周知,网站是通过Cookies来确定用户身份的,Scrapy爬虫在爬取数据时使用同一个Cookies发送请求,这种做法和把DOWNLOAD_DELAY设置为0.1没什么区别。
所以,要破解这种原理的反爬虫也很简单,直接禁用Cookies就可以了,在Setting.py文件后追加一项:
标签:latest log index settings 9.png ext import 技术 ebs
原文地址:http://www.cnblogs.com/hqutcy/p/7340385.html
{kind=link}