标签:blog items ide list tor lin 项目 nbsp imp
#看到贴吧大佬在发图,准备盗一下
#只是爬取一个帖子中的图片
1、先新建一个scrapy项目
scrapy startproject TuBaEx
2、新建一个爬虫
scrapy genspider tubaex https://tieba.baidu.com/p/4092816277
3、先写下items
#保存图片的url
img_url=scrapy.Field()
4、开始写爬虫
# -*- coding: utf-8 -*-
import scrapy
from TuBaEx.items import TubaexItem
class TubaexSpider(scrapy.Spider):
name = "tubaex"
#allowed_domains = ["https://tieba.baidu.com/p/4092816277"]
baseURL="https://tieba.baidu.com/p/4092816277?pn="
#拼接地址用 实现翻页
offset=0
#要爬取的网页
start_urls = [baseURL+str(offset)]
def parse(self, response):
#获取最后一页的数字
end_page=response.xpath("//div[@id=‘thread_theme_5‘]/div/ul/li[2]/span[2]/text()").extract()
#通过审查元素找到图片的类名,用xpath获取
img_list=response.xpath("//img[@class=‘BDE_Image‘]/@src").extract()
for img in img_list:
item=TubaexItem()
item[‘img_url‘]=img
yield item
url=self.baseURL
#进行翻页
if self.offset < int(end_page[0]): #通过xpath返回的是list
self.offset+=1
yield scrapy.Request(self.baseURL+str(self.offset),callback=self.parse)
5、使用ImagesPipeline,这个没什么说的,我也不太懂
# -*- coding: utf-8 -*- import requests from scrapy.pipelines.images import ImagesPipeline from TuBaEx import settings class TubaexPipeline(ImagesPipeline): def get_media_requests(self,item,info): img_link = item[‘img_url‘] yield scrapy.Request(img_link) def item_completed(self,results,item,info): images_store="C:/Users/ll/Desktop/py/TuBaEx/Images/" img_path=item[‘img_url‘] return item
6、配置下settings
IMAGES_STORE = ‘C:/Users/ll/Desktop/py/TuBaEx/Images/‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘TuBaEx (+http://www.yourdomain.com)‘ USER_AGENT="User-Agent,Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50" # Obey robots.txt rules ROBOTSTXT_OBEY = False #开启管道 ITEM_PIPELINES = { ‘TuBaEx.pipelines.TubaexPipeline‘: 300, }
7、执行
scrapy crawl tubaex
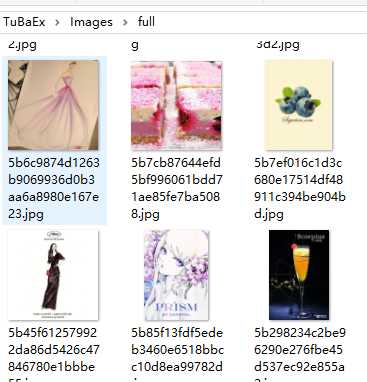
8、收获果实
标签:blog items ide list tor lin 项目 nbsp imp
原文地址:http://www.cnblogs.com/lljh/p/7341080.html