标签:分组 split image 编写 make 为什么 空白 组合 包括
Python中,表示时间的几种方式:
1、时间戳(timestamp):时间戳表示从1970年1月1日00:00:00开始按秒计算的偏移量。运行“type(time.time())”,返回的是float类型。time.time()显示时间戳:1487130156.419527
2、格式化的时间字符串(format_string):time.strftime("%Y-%m-%d %X")显示:‘2017-02-15 11:40:53‘
3、结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时),结构化的时间有2种如下图:
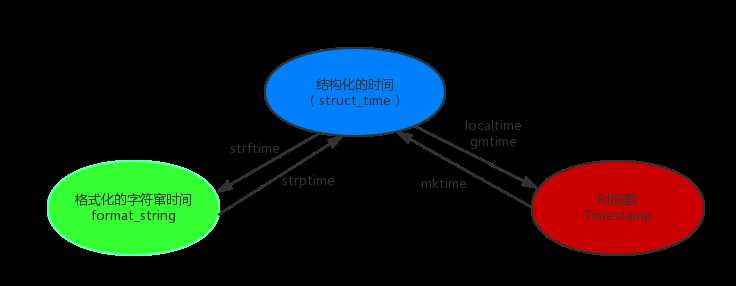
4、常用方法:
时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.localtime()
time.localtime(1473525444.037215)
gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
mktime(t) : 将一个struct_time转化为时间戳。
print(time.mktime(time.localtime()))#1473525749.0
strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和
time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个
元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56
time.strptime(string[, format])
把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime(‘2011-05-05 16:37:06‘, ‘%Y-%m-%d %X‘))
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,tm_wday=3, tm_yday=125, tm_isdst=-1)
在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:‘Sun Jun 20 23:21:05 1993‘。
如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())#Sun Sep 11 00:43:43 2016
ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,‘23‘,[4,5]]))#1或者23或者[4,5] print(random.sample([1,‘23‘,[4,5]],2))#列表元素任意2个组合 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
os使用方法:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。 >>> os.path.normcase(‘c:/windows\\system32\\‘) ‘c:\\windows\\system32\\‘ 规范化路径,如..和/ >>> os.path.normpath(‘c://windows\\System32\\../Temp/‘) ‘c:\\windows\\Temp‘ >>> a=‘/Users/jieli/test1/\\\a1/\\\\aa.py/../..‘ >>> print(os.path.normpath(a)) /Users/jieli/test1
常用方法:
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称
什么是序列化?
把对象从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization
为什么要序列化?
1:持久保存状态
2:跨平台数据交互
序列化对象后,可以把序列化后的内容写入磁盘,也可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
不同的编程语言之间传递对象,必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络 传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象。
shelve只有一个open函数,返回类似字典,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r‘abc.txt‘)
# f[a‘]={‘name‘:‘Andy,‘age‘:18}
# f[‘b]={‘name‘:‘axle‘,‘age‘:53}
# f[‘v‘]={‘website‘:‘http://www.pypy.org‘,‘city‘:‘beijing‘}
print(f[‘a‘][‘name‘])
f.close()
一:什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式),用于描述字符或者字符串的方法。它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹 配引擎执行。
二:常用匹配模式(元字符)
import re
#\w匹配字母数字下划线 \W匹配非字母下划线
# print(re.findall(‘\w‘,‘hello engon 123‘))
# print(re.findall(‘\W‘,‘hello engon 123 \n \t‘))
#\s匹配任意空白字符[\n\t\r] \S匹配任意非空白字符
# print(re.findall(‘\s‘,‘hello engon 123‘))
# print(re.findall(‘\S‘,‘hello engon 123‘))
#\d匹配数字,任意数字[0-9]\D匹配任意非数字
# print(re.findall(‘\d‘,‘hello engon 123‘))
# print(re.findall(‘\D‘,‘hello engon 123‘))
#匹配字符开始\A或^
# print(re.findall(‘\Ahe‘,‘hello engon 123‘))
# print(re.findall(‘^he‘,‘hello engon 123‘))
#匹配字符结束$或\Z
# print(re.findall(‘3\Z‘,‘hello engon 123‘))
# print(re.findall(‘he$‘,‘hello engon 123‘))
# 重复匹配:| . | * | ? | .* | .*? | + | {n,m} |
#.匹配任意字符,除了换行符,当re.DOTALL或re.S标记被指定时,则可以匹配换行符的任意字符
# print(re.findall(‘a.b‘,‘a|b‘))
# print(re.findall(‘a.b‘,‘a1b a*b a b aaab‘))
# print(re.findall(‘a.b‘,‘a\nb‘))
# print(re.findall(‘a.b‘,‘a\nb‘,re.S))
# print(re.findall(‘a.b‘,‘a\nb‘,re.DOTALL))
#*匹配0个或多个的表达式
# print(re.findall(‘ab*‘,‘bbbbbbb‘))
# print(re.findall(‘a*‘,‘a‘))
# print(re.findall(‘ab*‘,‘abbbbbbb‘))
#?匹配0个或一个
# print(re.findall(‘ab?‘,‘a‘))
# print(re.findall(‘ab?‘,‘abbb‘))
#匹配所有包含小数在内的数字
# print(re.findall(‘\d+\.?\d‘,"asdfasdf123as1.13dfa12adsf1asdf3"))
#.*默认为贪婪匹配
# print(re.findall(‘a.*b‘,‘a1b22222222b‘))
#.*?为非贪婪匹配:推荐使用
# print(re.findall(‘a.*?b‘,‘a1b2222222222b‘))
#+匹配一个或多个的表达式
# print(re.findall(‘ab+‘,‘a‘))
# print(re.findall(‘ab+‘,‘abbbb‘))
#{n,m}
# print(re.findall(‘ab{2}‘,‘abbb‘))
# print(re.findall(‘ab{2,3}‘,‘abbbbbbb‘))
# print(re.findall(‘ab{1,}‘,‘abbbbbbbbbbbbbb‘))
# print(re.findall(‘ab{0,}‘,‘abbbbbbbbbbbbb‘))
#[]
# print(re.findall(‘a[1*-]b‘,‘a1b a*b a-b‘))
# #头或尾
# print(re.findall(‘a[^1*-]‘,‘a1b a*b a-b a=b‘))
# print(re.findall(‘a[0-9]b‘,‘a1b a*b a-b a=b‘))
# print(re.findall(‘a[a-z]b‘,‘a1b a*b a-b a=b aeb‘))
# print(re.findall(‘a[a-zA-Z]b‘,‘a1b a*b a-b a=b aeb aEb‘))
# print(re.findall(‘a\\\c‘,‘a\c‘))
# print(re.findall(r‘a\\c‘,‘a\c‘))
# print(re.findall(‘a\\\\c‘,‘a\c‘))
#():分组
# print(re.findall(‘ab+‘,‘ababab123‘))
# print(re.findall(‘(ab)+123‘,‘ababab123‘))
# print(re.findall(‘(?:ab)+123‘,‘ababab123‘))
# print(re.findall(‘compan(?:y|ies)‘,‘Too many companies have gone bankrupt, and the next one is my company‘))
#re的其它方法
#直到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符窜,如果字符窜没有匹配成功,则返回None
# print(re.search(‘e‘,‘alex make love‘).group())
#只找开始处,匹配到返回,匹配不到返回None
# print(re.match(‘1‘,‘alex make love‘))
#先按‘a‘分割到‘‘和‘bcd‘,再对‘‘和‘bcd‘分别按‘b‘进行分割
# print(re.split(‘[ab]‘,‘abcd‘))
# print(‘===>‘,re.sub(‘a‘,‘A‘,‘alex make love‘))
# print(‘===>‘,re.sub(‘a‘,‘A‘,‘alex make love‘,1))
# print(‘===>‘,re.sub(‘a‘,‘A‘,‘alex make love‘,2))
# print(‘===>‘,re.sub(‘^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$‘,r‘\5\2\3\4\1‘,‘alex make love‘))
# print(‘===>‘,re.sub(‘^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$‘,r‘\5\2\3\4\1‘,‘alex make love‘))
#6
# obj=re.compile(‘\d{2}‘)
# print(obj.findall(‘abc123eeee‘))
#此处就是通过 (?P=name)的方式,来引用,正则表达式中,前面已经命名tagName的group的
# print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
# print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<111>hello</111>"))
# print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group())
#
#
#
# print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").groupdict())
#
# # print(re.search(r"<(\w+)>\w+</(\w+)>","<h1>hello</h1>").group())
# print(‘===>>‘,re.search(r"<(\w+)>(\w+)</\1>","<h1>hello</h1>").group())
print(re.findall(r‘-?\d+\.*\d*‘,"1-12*(60+(-40.35/5)-(-4*3))")) #找出所有数字[‘1‘, ‘-12‘, ‘60‘, ‘-40.35‘, ‘5‘, ‘-4‘, ‘3‘]
print(re.findall(r"-?\d+\.\d+/\d+\.*\d+\.*\d+","1-2*(60+(-40.35/5)-(-4*3))"))
标签:分组 split image 编写 make 为什么 空白 组合 包括
原文地址:http://www.cnblogs.com/MouseCat/p/7343799.html