标签:word sts 写入 年龄 structure maria 多少 超过 之间
nodejs是需要连接Mysql的,然后才是真正的服务器端语言,这里对数据库做一个简单的介绍。
等等等等,所有的信息存储都需要数据库。
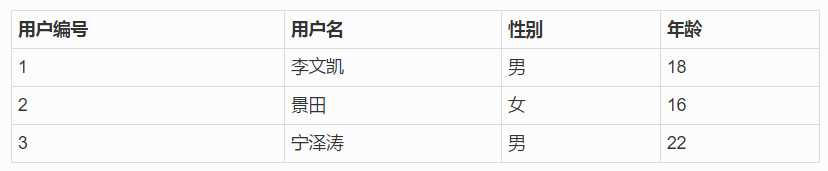
上图就是一个数据表,它是存放在数据服务器中的某一个数据库中的, 其中每一行就是一个记录,即数据行, 而数据字段就是用户编号、用户名、性别等。 这里使用的是汉字,如果是真实的,一定是用英文来表示的。
值得注意的是,数据表和数据表之间一般是由关系的, 后面会降到。
数据库服务器可以单独安装,但是使用xampp会更加方便一些,如下所示,其中apache和mysql就可以了。
可能出现的问题:
数据库安装完成,最重要的就是学习SQL语句了。 什么是SQL呢? 它是操作数据库的核心, Structured Query Language, 即结构化查询语言,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
SQL最重要的是关系数据库操作语言,学习好了MySQL总的SQL语句,其他的语法学起来也是万变不离其宗。
SQL语句按照其功能的不同可以分为三类:
在xampp面板的右上方点击shell, 然后输入mysql,就可进入mysql的环境。
如果有时候不能直接进入,就需要我们使用下面的方法登录了;
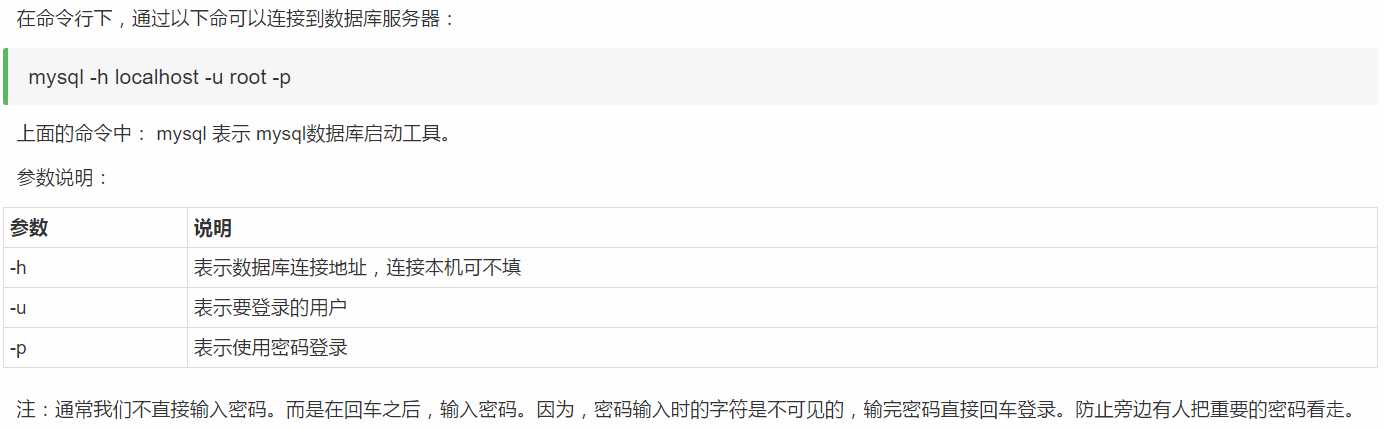
可以认为-h表示home在哪, -u表示user是谁, -p表示password是什么。 hup登入。
基本语法如下:
create database 数据库名;

注意: 在结尾一定要加分号。 query OK 表示请求成功,即执行命令成功。 1 row affected 表示本次操作只影响了数据库中的其中一行的记录。因为只是创建了一个数据库,所以database没有分号。
基本语法如下:
show databases;
即查看所有的数据库。
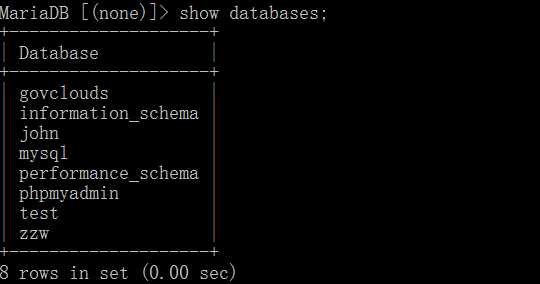
可以看到我的数据库服务器中存放了8个数据库。
基本语法如下:
use 数据库名;
即选中其中的某一个数据库,然后就可以对其操作了,当然这个数据库一定是属于show databases;中的某一个。
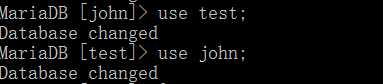
在输入基本命令之后,可以发现Database changed , 这表示数据库切换成功。
注意:我们不难发现,在切换了数据库之后,MariaDB后面的方括号中就是表示当前所在的数据库。 而最考试我们没有进入数据库时, MariaDB后面显示的none。
基本语法如下:
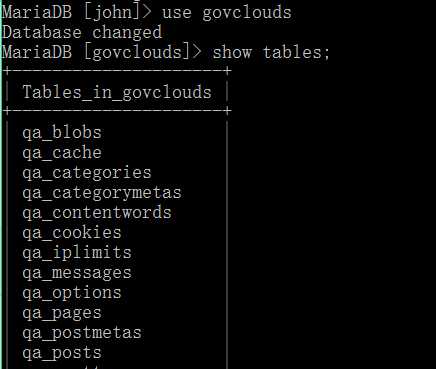
show tables;
表示显示当前数据库下的所有的数据表。
基本用法如下:
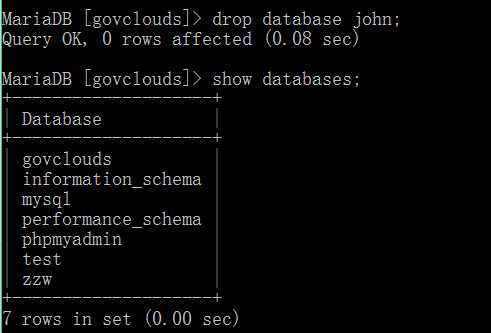
drop database 数据库名;
注意: 一旦删除了某个数据库,这个数据库下所有的数据表也会被删除了。
基本语法如下:
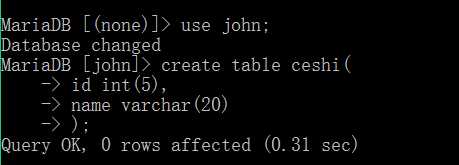
create table 数据表名(字段名1 字段类型, 字段名2 字段类型,..... , 字段名n 字段类型 );
其中的自动名就是id、sex、name等这样的名称。 而字段类型表示这个字段下是什么类型, 一般int代表整型、 float代表浮点型、char和varchar代表字符串。一般我们还可以在类型后添加长度,用()括起来。
注意: 在创建数据表的时候,我遇到的问题是创建失败,提示数据库时只读的, 解决方法是先去看stackoverflow。 上面的教程是将mysql中config下的某一行删除,然后重新使用mysql -h....这种形式登录即可。
这样就创建了一个数据表,其中包含id字段和name字段,id字段限定输入的是整型, name字段限定输入的是字符型。
在创建表最后,我们常用MyISAM或者InnoDB引擎。基本语法如下:
ENGINE=InnoDB
还可以制定默认字符集。基本语法如下:
DEFAULT CHARSET=utf8
最后组合起来即可:

基本语法如下:
desc 表名;
其中desc是描述的意思,即description。 当然这个操作必须在某个数据库的情况下进行操作。
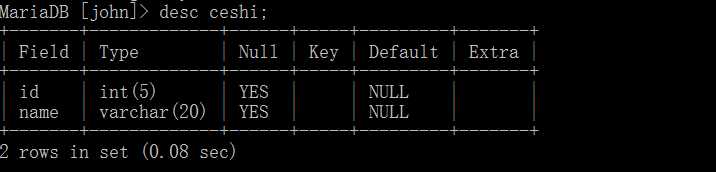
其中Field表示字段, Type表示这些字段的类型, Null表示是否支持输入为Null,即无内容时,我们可以使用Null来输入,并且默认也是Null。
基本语法如下:
show create table 数据表名 \G;
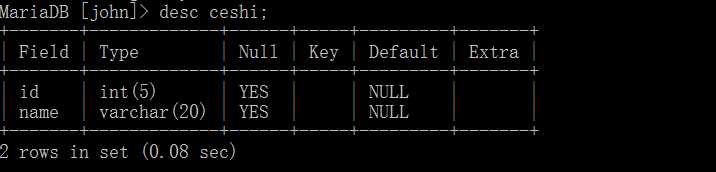
即这就是我之前创建的ceshi数据表的创建语句。
基本语法如下:
drop table 数据表名;

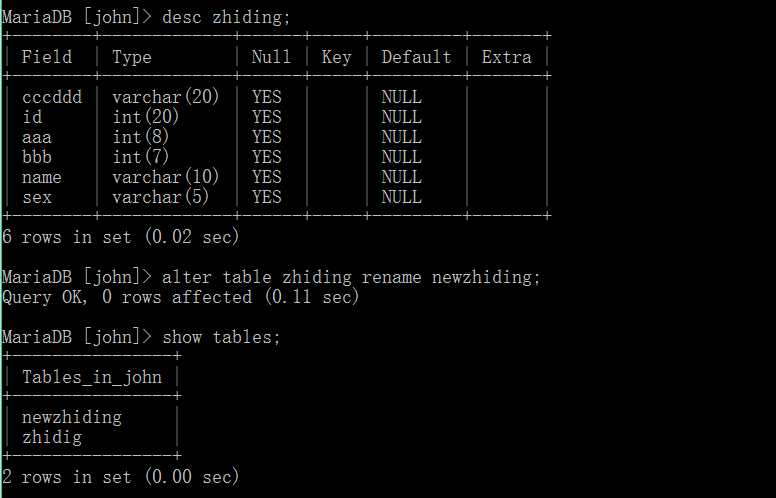
基本语法如下:
alter table 表名 rename 新表名;
基本语法如下:
show tables;
注意:这里的关键字是 修改、类型。 基本语法如下:
alter table 表名 modify 字段名 varchar(20);
即将表中的一个字段修改其类型为varchar(20)。
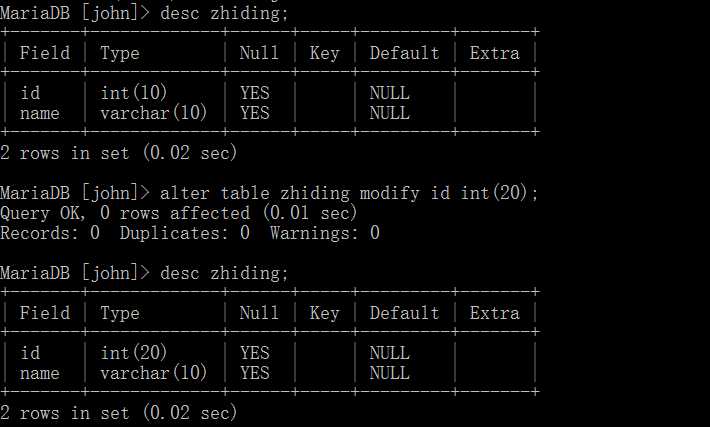
可以看到我们通过这种方式可以将其中的id字段的类型由int(10)修改为了int(20)。
基本语法如下:
alter table 表名 add column 字段名 字段类型;
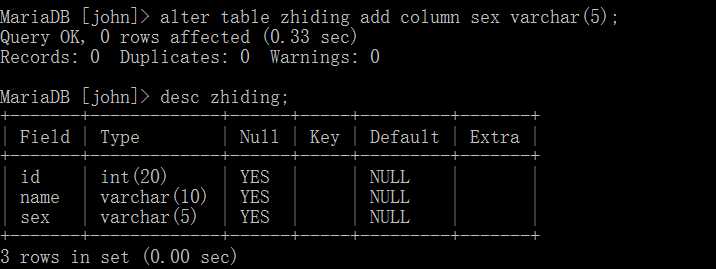
即在zhiding表中添加了类型为varchar(5)的字段sex。
刚刚我们再添加字段时,默认是添加在尾部的,如果我们希望添加到中间部分呢? 基本语法如下:
alter table 表名 add column 字段名 字段类型 after 字段名;
不同之处仅在于添加了after 字段名,表示在某个字段之后添加。如果希望添加在第一行,将after 字段名 直接替换成 first 即可。
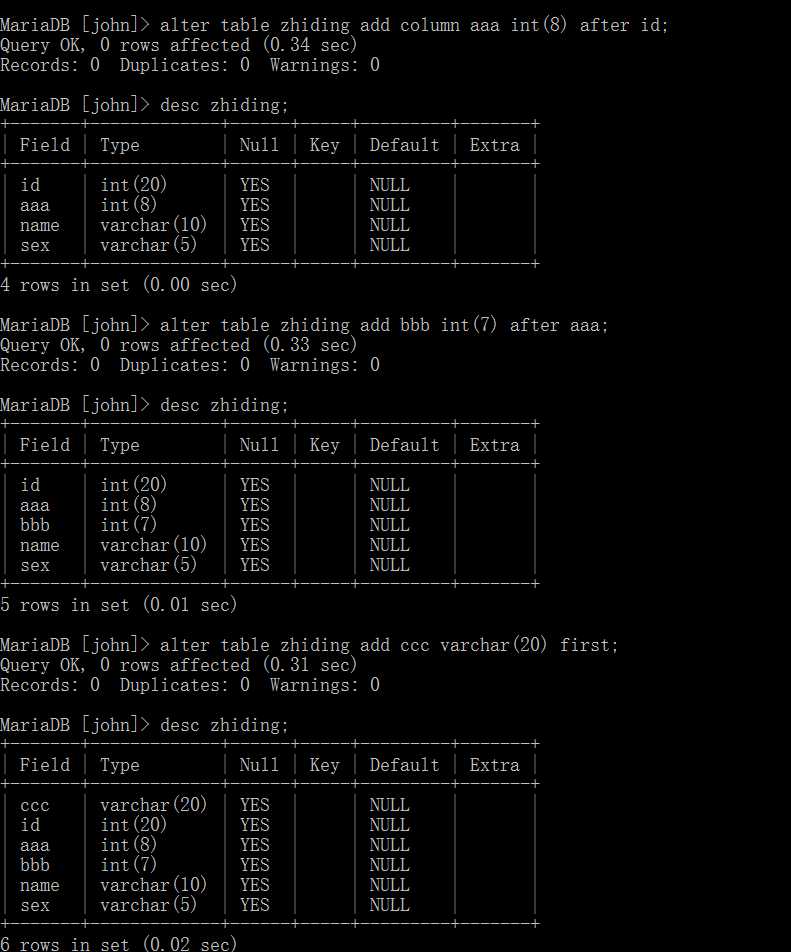
可以看到有没有column都是可以的。 并且在命令行中,是不区分大小写的。 所以使用大小写都是一样的。
基本语法如下:
alter table 表名 drop column 字段名;
基本语法如下:
alter table 表名 change 原字段名 新字段名 字段类型;
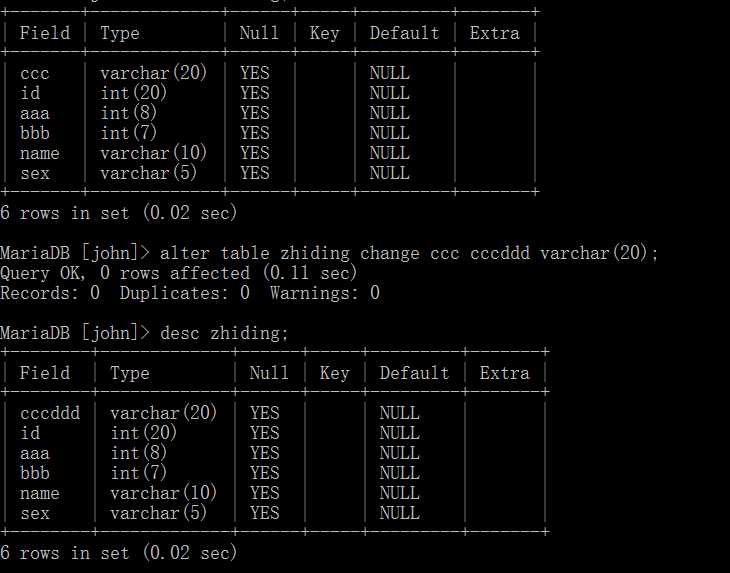
MySQL中存放的是数据,所以说数据就要有数据类型,我们再存放数据时也要规定数据的类型,并且要满足数据长度的要求。
在MySQL中我们将数据分为以下的类型:
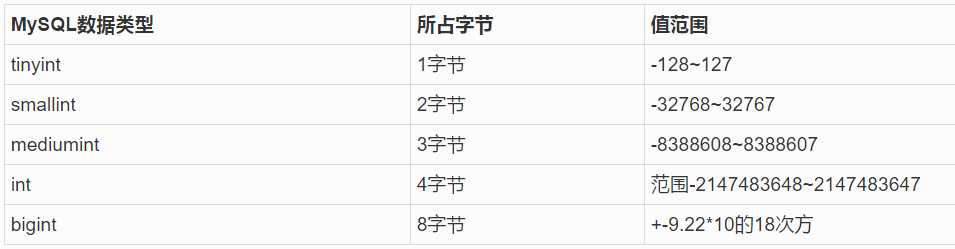
注意:
1.在创建表字段时,性别我们可以使用无符号的微小整型(tinyint)来表示。用0表示女、用1表示男。用2表示未知。
2.同样人类年龄也是,在创建表字段时可用用无符号的整型。因为人类的年龄还没有负数
3.在实际使用过程中。我们业务中最大需要存储多大的数值。我们创建表时,就选择什么样的类型来存储这样的值。

注意:
1.浮点是非精确值,会存在不太准确的情况
2.而decimal叫做定点数。在MySQL内部,本质上是用字符串存储的。实际使用过程中如果存在金额、钱精度要求比较高的浮点数存储,建议使用decimal(定点数)这个类型。
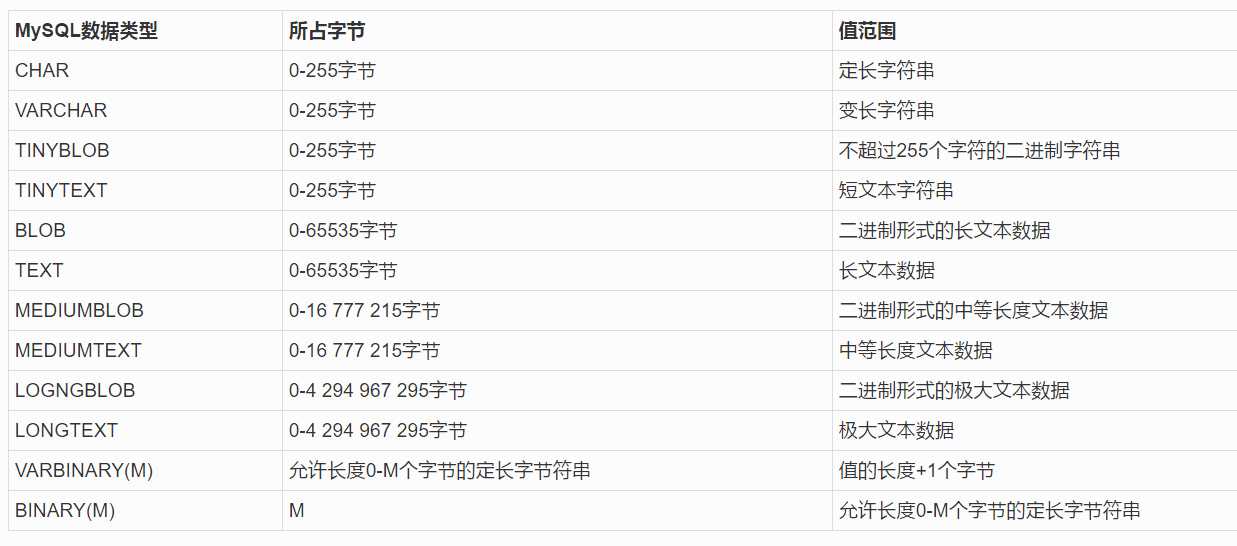
其中char类型表示定长字符串,如果比之规定的长,就截取; 如果比他规定的短,就用空格来填补。
而varchar不是定长的。因为 VARCHAR 类型可以根据实际内容动态改变存储值的长度,所以在不能确定字段需要多少字符时使用 VARCHAR 类型可以大大地节约磁盘空间、提高存储效率。
text类型与blob类型 对于字段长度要求超过 255 个的情况下,MySQL 提供了 TEXT 和 BLOB 两种类型。根据存储数据的大小,它们都有不同的子类型。这些大型的数据用于存储文本块或图像、
声音文件等二进制数据类型。
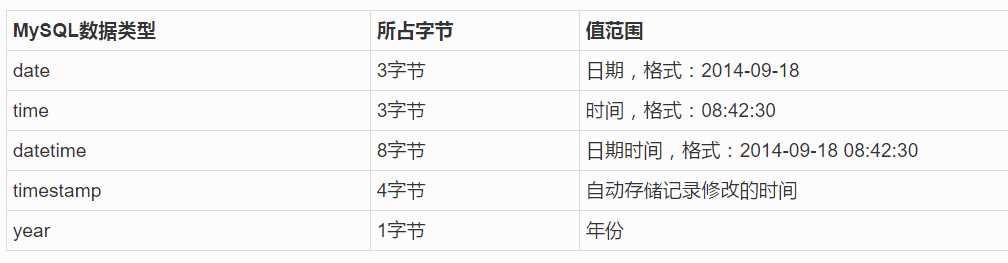
一般用的比较少,多用int来存储。

UNSIGNED(无符号)
主要用于整型和浮点类型,使用无符号。即,没有前面面的-(负号)。存储位数更长。tinyint整型的取值区间为,-128~127。而使用无符号后可存储0-255个长度。
创建时在类型后面接上 unsigned 即可。
ZEROFILL(0填充)
0(不是空格)可以用来真补输出的值。使用这个修饰符可以阻止 MySQL 数据库存储负值。
创建时在类型后面接上 zerofill 即可。
DEFAULT(默认)
default属性确保在没有任何值可用的情况下,赋予某个常量值,这个值必须是常量,因为MySQL不允许插入函数或表达式值。此外,此属性无法用于BLOB或TEXT列。如果已经为此列指定了NULL属性,没有指定默认值时默认值将为NULL,否则默认值将依赖于字段的数据类型。
NOT NULL (非NULL)
如果将一个列定义为not null,将不允许向该列插入null值。建议在重要情况下始终使用not null属性,因为它提供了一个基本验证,确保已经向查询传递了所有必要的值。
创建时在整型或浮点字段语句后接上 not null 即可。
举例如下所示:

CREATE TABLE IF NOT EXISTS demo ( id int(11) NOT NULL, username varchar(50) NOT NULL, password char(32) NOT NULL, content longtext NOT NULL, createtime datetime NOT NULL, sex tinyint(4) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
字符集就是将各种文字编码为二进制数字(十六进制也是可以的,本质一样)的方式, 即这是让一般文字存储在计算机的一种通用的规则, 字符集有很多, 我们常用的有下面几种:

ASCII:
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符 。 但是ASCII能表示的字符很少,所以中文是不支持的。单字节。
GBK:
GBK 向下与 GB 2312 编码兼容。是中华人民共和国定义的汉字计算机编码规范。早期版本为GB2312。 即这个仅仅是支持中文的。 但是仅仅表示中文的时候, 节约内存,因为他是双字节的 。
Unicode:
Unicode(统一码、万国码、单一码)Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。以满足跨语言、跨平台进行文本转换、处理的要求。 但是不难看出, 4字节还是非常消耗内存的。
UTF-8:
是一种针对Unicode的可变长度字符编码,也是万国码。因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Universal Transformation Format)
综上可知,在实际工作中,我们比较常用的编码方式就是unicode和UTF-8这两种编码方式。
MySQL的很大的一个特点就是他的插件式表引擎,根据不同的特点使用不同的存储引擎,使得存储性能最大化。在MySQL中使用下面的命令可以查看所支持的所有表引擎。
show engines;
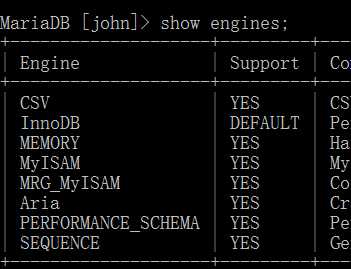
下面介绍几个常用的引擎和几个不常用的引擎。
MyISAM:
不支持事务,表锁(表级锁,加锁会锁住整个表),支持全文索引,操作速度快。常用于读取多的业务。
InnoDB:
InnoDB是为处理巨大数据量时的最大性能设计。
说明:
索引其实就类似于书中的目录,有了索引就更加方便我们查找。不使用索引,MySQL必须从第1条记录开始然后读完整个表直到找出相关的行。表越大,花费的时间越多。如果表中查询的列有一个索引,MySQL能快速到达一个位置去搜寻到数据文件的中间,没有必要看所有数据。MySQL中的索引类型有以下几种方式:

普通索引:
基本语法如下:
alter table 表名 add index(字段名)
即为某个表的某个字段增加索引。
唯一索引:
基本语法如下:
alter table 表名 add UNIQUE(字段名)
即为某个表的某个字段增加唯一索引。
全文索引:
基本语法如下:
alter table 表名 add FULLTEXT (字段名)
即为某个表的某个字段增加全文索引
主键索引:
基本语法如下:
alter table 表名 add PRIMARY KEY(字段)
即为某个表的某个字段增加主键索引。
在创建表时也可以声明索引,如下所示:
CREATE TABLE test ( id INT NOT NULL , username VARCHAR(20) NOT NULL , password INT NOT NULL , content INT NOT NULL , PRIMARY KEY (id), INDEX pw (password), UNIQUE (username), FULLTEXT (content) ) ENGINE = InnoDB;
对于数据库的操作实际上就是增删改查。 这些基本功做好了,对数据库的操作也就游刃有余了。
插入记录有两种基本语法。
语法一:
insert into 表名 values(值1, 值2 ... 值n);
语法二:
insert into 表名(字段1,字段2 ... 字段n) values(值1,值2 ... 值n);
显然,两种语法是有区别的:
另外,对于第一种语法,我们也可以一次性增加多各记录, 只要在values后添加多个()即可,用逗号隔开,如下所示:
insert into user(username,password,sex) values(‘黄晓明‘, ‘abcdef‘, 1), ( ‘angelababy‘, ‘bcdeef‘, 0), ( ‘陈赫‘, ‘123456‘, 1), (‘王宝强‘, ‘987654‘, 1);
为了查数据,首先我们创建一个数据表。
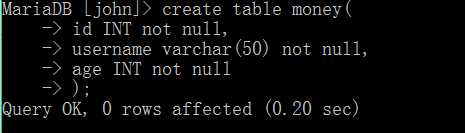
即创建了包含id、username、age三个字段的表。
下面我们向其中添加字段:
查询全部:
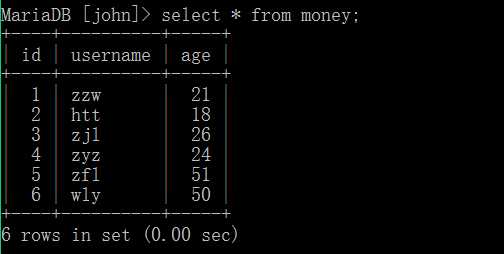
然后我们就可以查询,查询表中的所有记录的基本语法如下:
select * from 表名;
指定字段查询:
基本语法如下:
select 字段名 from 表名;
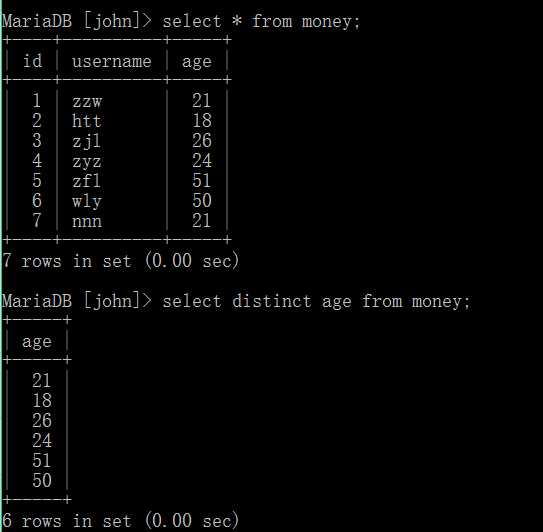
查询字段不重复的记录:
基本语法如下:
select distinct 字段名 from 表名;
为了演示,我新增一条记录,使得age有相等的两条记录。如下:
insert into money values(7, "nnn", 21);
条件查询where
基本语法如下:
select 字段名 from 表名 where 条件;
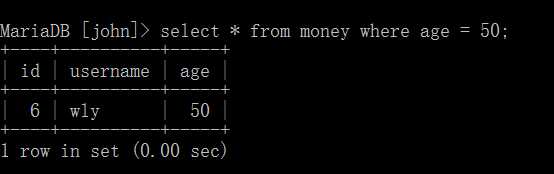
可以看到*表示的是如果有,就返回一条记录,而不是其中的字段, age=50即返回age等于50字段所在的记录。
下面的符号也是可以的:

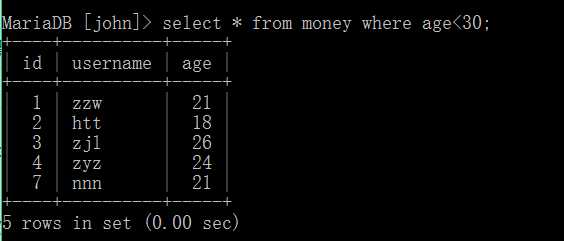
基本语法如下:
select 字段名 from 表名 order by 字段名 排序关键词
其中排序关键词有两个:
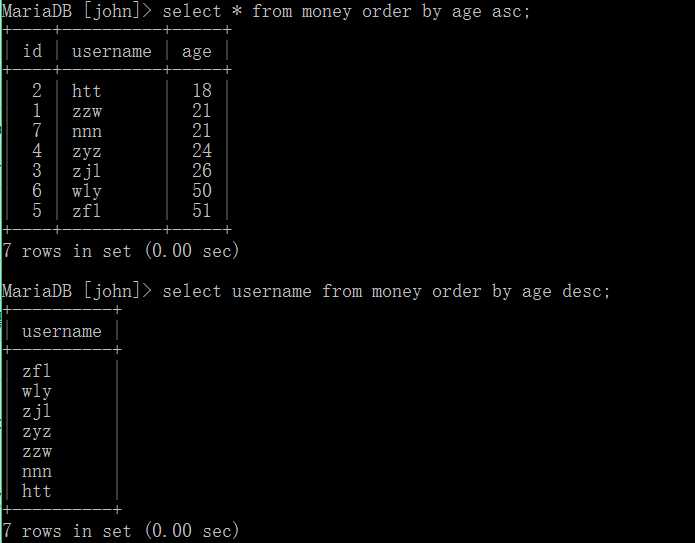
上面的例子是根据其中某一个字段来排序,现在我们可以进行多字段排序。 即第一个已经排好,则第二个不再生效,否则第二个生效。。。
基本语法如下:
select 字段名 from 表名 order by 字段名1 排序关键字, 字段名2 排序关键字;
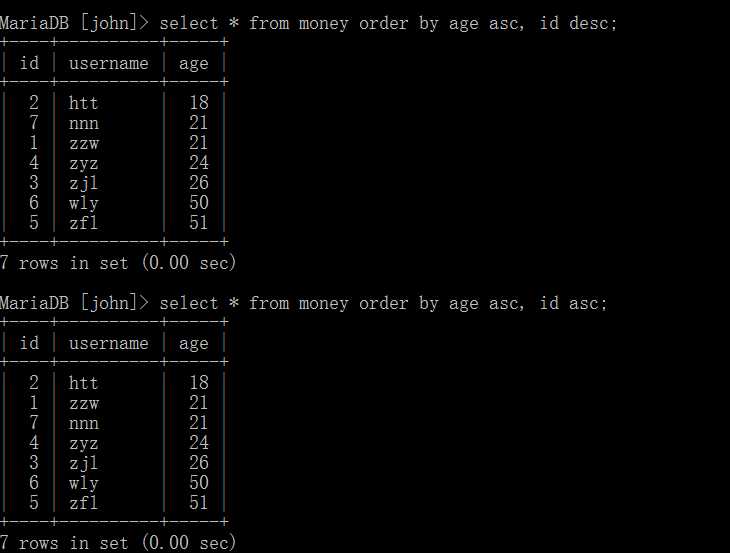
通过上面的两个例子,很容易看出他们的区别。
对于查询或者排序后的结果集,如果我们不希望显示全部,比如就想知道一次比赛中的前三名是谁,这就是结果集限制。
基本语法如下:
select 字段名 from 表名 limit 限制的数量;
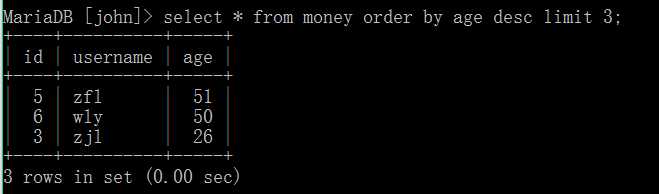
上例中我们就把年龄最大的三者筛选了出来。
上面我们是默认从第一条记录开始的,但是如果我们希望留下中间的几条呢,语法如下:
select 字段名 from 表名 limit 开始位置,结束位置;
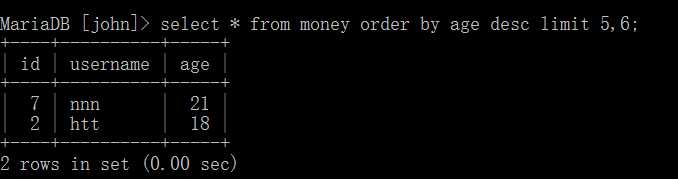
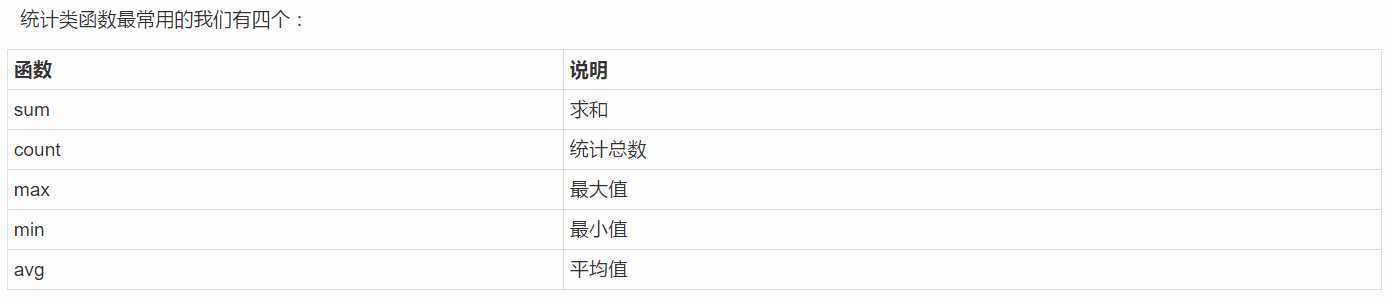
基本使用语法如下:
select 函数名(字段名) from 表名;
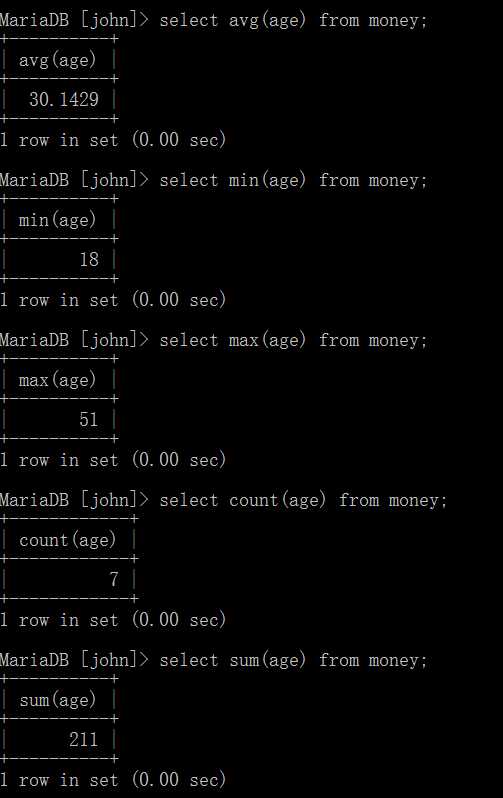
基本语法如下:
select 字段名 from 表名 group by 字段名;
比如我们再查询用户购买情况时,至少需要两张表,第一张保存了用户的基本信息,包括name,password,id等。 第二章表上保存了用户的购买记录。 即一旦有一个用户购买,就将这个记录插入表中。
于是这样的查询就是联合查询,而要做到联合查询就要进行表连接。
表连接分为内连接和外连接。 具体定义后面会讲到。
既然需要进行表连接,那么就得有两个表!
http://www.shouce.ren/api/view/a/13995
这一部分只是等到需要的时候再学吧。
修改一个字段,语法如下:
update 表名 set 字段名=字段值 where 条件;
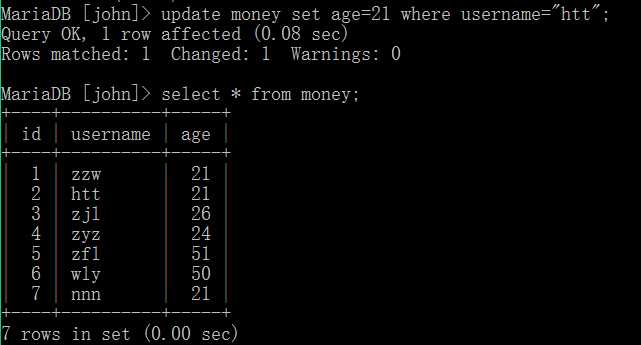
这里是修改其中一个字段,我们还可以修改多个字段。
基本语法如下所示:
update 表名 set 字段名1=值1, 字段名2=值2 where 条件;
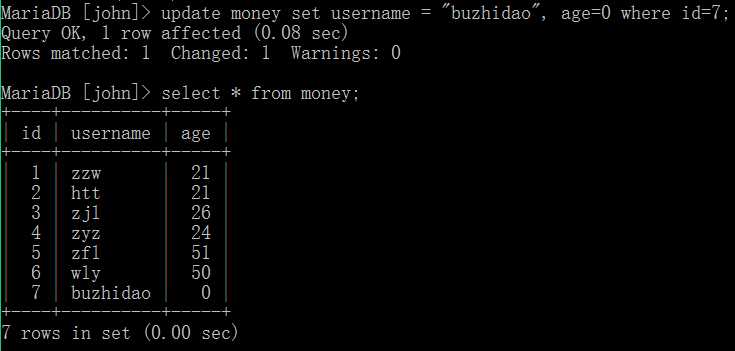
关键: 对于其中的username下的值,他们都是字符串,所以一定要写成 username="zuzhidao", 而不是username=buzhidao, 因为系统会将buzhidao当做一个变量,而这个变量又没有声明和定义,所以会报错。
删除记录的基本语法如下:
delete from 表名 where 条件。
注意:这里一删除就是删掉一条记录,而不难只删除其中的一个字段。
清空表记录基本语法如下:
trunkate table 表名;
这条命令会直接将一个表删除。
http://study.163.com/course/courseLearn.htm?courseId=706085#/learn/video?lessonId=866408&courseId=706085
标签:word sts 写入 年龄 structure maria 多少 超过 之间
原文地址:http://www.cnblogs.com/zhangsongren/p/7345069.html