标签:笔记 time ges 字母 font line 隐式转换 中间 image
第二周
模块 库 相当于java导包
标准库 不用安装
第三方 需要安装
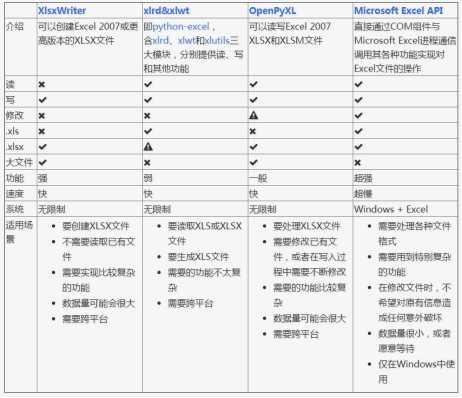
Python处理excel 读xlrd模块 写 XlsxWriter 模块
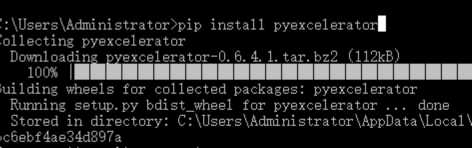
windows安装库很简单 python2执行 pip install pyexcelerator(模块名)
Python 执行 pip3 install XXXXXX(模块名)
创建包的名字和python文件的名字不能和 (模块名)库名一样,否则会调取自身
import sys
# 打印环境变量
print(sys.path)
#打印当前文件的路径
print(sys.argv)
import os 和系统交互比较多
#创建文件夹或者文件
os.mkdir("C:/Users/Administrator/Desktop/day02/")
#打印当前文件目录的列表
cmd= os.popen("dir").read()
print(cmd)
python执行先编译器 后解释器 .pyc文件是介于编译后的文件
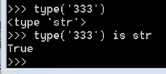
type(2)判断数据类型
python中的数据类型
在python2中如int超范围之后会自动转成long型(在32位机器当中int类型是 2的32次方 在32位机器当中int类型是 2的64次方)
在python3中 进行了优化 int超范围后还是int类型 可以正常使用
string和bytes
在python2中 str和bytes可以混用 互相拼接
python3 对str和bytes类型有看更明确的区分 不会隐式转换
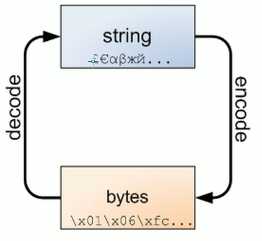
机器之间的相互的传输都是使用的二进制 bytes
#字符串转bytes
str="我是"
print(str.encode(‘utf-8‘))
#bytes转string
str2=b‘\xe6\x88\x91\xe6\x98\xaf‘.decode(‘utf-8‘)
print(str2)
输出如下
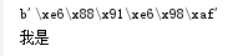
布尔类型
python中首字母是大写
True
False
求余数 %

返回除的整数部分

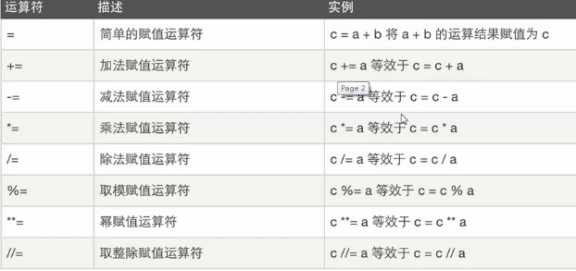


64 32 16 8 4 2 1
64>>2 = 16 相当于 除以2的2次方 64/4
64>>3 = 8 相当于 除以2的3次方 64/8
移几位就相当 除以几的2次方
以上的这种运算比 正常的除法快很多 <<相当于乘法 同理
三元运算
print("111") if 1>2 else print("222")
输出 222 左边位置是条件正确的结果 中间是条件 esle 右边是条件错误的结果
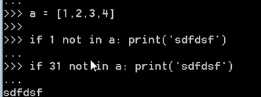
关于列表
name=["s",1,"qq"]
# 切片取数据 顾头不顾尾 取数据最后一位 要给给最后位置+1
print(name[0:3])
#或者不限制直接 :
print(name[0:])
#或者 输入负数 代表倒着数
print(name[-3:])
结果如下

#给最后一个位置增加元素
name.append("sssss")
#给指定位置添加元素
name.insert(1,‘kkkk‘)
#删除元素,指定元素
name.remove("kkkk")
#删除指定位置的元素
name.pop(2)
#空白,删除最后一个元素
name.pop()
#通过元素,得到他的位置下标
name.index("sssss")
#清空列表
name.clear()
#统计列表里有多少相同的元素
print(name.count("sssss"))
#对列表的顺序进行反转
name.reverse()
#列表排序 排序的优先级如下 特殊符号>数字>大写字母>小写字母
name.sort()

和并列表 吧name2 列表合并到 names 中 name2依然存在
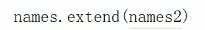
.copy,是浅copy,会复制第一层,如果里边 在套一个列表A,那么 列表A就会指向同一个内存地址,可以实现类似联合账号的效果,一个账户花钱,总账户都减少
copy.deepcopy() 是深度copy 完全复制一份
需要导入 import copy
import copy
name1=["aaa",‘bbb‘,"ccc",[‘100‘,‘fff‘]]
#浅copy
name2=name1.copy()
#深度copy
name3=copy.deepcopy(name1)
name1[3][0]="50"
print("name1: ",name1)
print("name2: ",name2)
print("name3: ",name3)
输出如下 name2[3][0]随着name1的改变,而改变 name3不会变 在列表套列表会发生
得到列表的长度 len()
intaa=[1,3,4,5,7,55,5555,43]
print(len(intaa))
输出如下
列表循环

跳着进行切片 隔一个取一个
如果是 第一个下标,或者是最后一个下标 可以忽略 下边两个种写法效果一样

元组 一旦创建不能修改 不能添加 也被称为只读列表 只有两种方法
name1=("aaa",‘bbb‘,‘aaa‘)
#统计相同元素个数
print(name1.count("aaa"))
#得到元素下标
print(name1.index("bbb"))
输入如下

元组 tupl 转化为list 列表
举个简单的例子,代码如下:
a=(1,2,3)
b=list(a) #b是由a转化而来的
结束整个程序 exit():
字符串操作
判断是否是整数格式,isdigit

循环打印下标 和数据 名称是随便起的 enumerate

数字颜色
有很多种颜色 改变31这个数字即可
\033[31;1m 需要变色的字符 \033[0m
print("\033[31;1m我是红色的\033[0m")
结果如下

name = "my name is hanlei"
首字母变大写
print(name.capitalize())
将所有字母都变成大写
print(name.upper())
将所有字母都变成小写
print(name.lower())
去掉左边的空格和回车
print(" sdd ".lstrip())
去掉右边的空格和回车
print(" sdd ".rstrip())
去掉两边的空格和回车
print(" sdd ".strip())
统计相同字符的个数
print(name.count("a"))
打印50个字符,位数不够“—”来凑
print(name.center(50,‘-‘))
输出如下
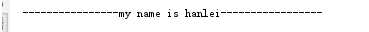
用“-”部位 在左边凑够50个
print(name.rjust(50,"-"))
输出如下

用“-”部位 在左边凑够50个
print(name.ljust(50,"-"))
输出如下
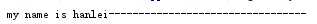
判断字符串以什么结尾的 返回的结果是 True 或者 False
print(name.endswith("lei"))
把\t变成30个空格
name = "my n\tame is hanlei"
print(name.expandtabs(tabsize=30))
find可以获取字符串的下标 用它也可以切分字符串 如果查不到 返回-1
name = "my name is hanlei"
print(name [name.find("h"):-2])
和fina相类似 如果查不到 会抛异常
print(name.index("m"))
判断字符串是否 包含字母和数字 返回True False
print("Ab222".isalnum())
判断字符串是否 包含字母 返回True False
print("Bbc".isalpha())
判断字符串是否是整数 返回True False
print("655".isdigit())
判断字符串是否是 合法的变量名 不能以数字,特殊字符开头 等等 返回True False
print("a_sss".isidentifier())
判断首字母是否是 大写 返回True False
print("My Name Is".istitle())
判断所有字母是否是 大写 返回True False
print("MY NAME IS".isupper())
join用于把列表中的元素,按什么分隔出来
print("+".join([‘1‘,‘2‘,‘3‘]))
输出如下
对字符串进行对照(替换)处理 hanlei 6个字母分别 对应123456
对应的是单个字符,并非是整个字符串
p=str.maketrans("hanlei","123456")
把p 传入到 translate()中,对 hanleiqqqqq 进行 替换
print("hanleiqqqqq".translate(p))
输出如下 看到 hanlei已经被转成 123456
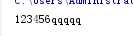
替换字母,替换h为w,替换2个
print("han lei hh".replace("h","w",2))
输出如下
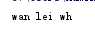
得到 字母h 最右边位置的下标
print("han lei hh".rfind("h"))
输出如下
9
对字符串进行切分 可以是空格“”,可以是\n ,也可以是任意的字符
切分后会变成一个列表
print("han lei hh".split(" "))
输出如下

把字符串按照行进行切分,可以被上一种代替,但在不同系统换行符,是不一样的
用它,可以不用考虑是什么系统
a="han lei hh".splitlines()
字母大小写颠倒
print("HAN lei hh".swapcase())
输出如下
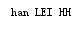
截取字符串 输入下标截取
str="HAN lei hh"
str[1:4]
将 列表格式的字符串 转化成 列表
str2="[[‘a a‘,2], [3,4], [5,6], [7,8], [9,0]]"
a=eval(str2)
print(type(a))
print(a)
输出如下

字典操作 map
字典是无顺序的 ,没有下标位置,靠key存取
创建一个字典
info = {
‘stu1101‘: "TengLan Wu",
‘stu1102‘: "LongZe Luola",
‘stu1103‘: "XiaoZe Maliya",
}
修改和增加 通过key如果存在就修改,不存在就增加
info["stu1104"] = "苍井空"
删除 指定key的 元素
info.pop(‘stu1101‘)
随机删除一对,但一般都删除末尾对
info.popitem()
获取
存在取出 不存在返回None
info.get("stu1102")
取出所有的key
info.keys()
取出所有的value
info.values()
判断
判断stu1104在不在,如果在就返回True,不在就返回False
print(‘stu1104‘ in info)
在python2中是如下这种写法
info.has_key("1103")
判断‘stu1103‘在不在,如果在就返回已有的结果,不做改变。如果没有,就增加
中间是逗号
info.setdefault(‘stu1103‘,"chongtianxingling")
合并 update info中相同的key会被b取代
info = {
‘stu1101‘: "TengLan Wu",
‘stu1102‘: "LongZe Luola",
‘stu1103‘: "XiaoZe Maliya",
}
b ={
‘stu1101‘: "Alex",
1:3,
2:5
}
info.update(b)
输出如下

把字典转化为列表
print(info.items())
输出如下
![]()
初始化一个字典,并赋一个默认值
注意:此方法赋的默认值如果只有一层,会复制,是独立的。
如果有多层,就变成地址引用。改其中一个值,其他的都会变。
c=dict.fromkeys(["a","b","c"],["test"])
print(c)
输出如下
![]()
字典循环
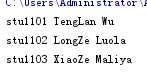
方法1:
i循环的是key info[i]循环的velue
info = {
‘stu1101‘: "TengLan Wu",
‘stu1102‘: "LongZe Luola",
‘stu1103‘: "XiaoZe Maliya",
}
for i in info:
print(i,info[i])
输出如下
方法2:
和上一种比效率较低,先把字典转成列表,再进行输出,数据量
大的时候会非常慢
for k,v in info.items():
print(k,v)
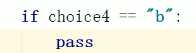
pass占位符 什么也不做
字符串和列表写入文件
把下边这个列表写入文本
product_list = [
(‘Iphone‘,5800),
(‘Mac Pro‘,9800),
(‘Bike‘,800),
(‘Watch‘,10600),
(‘Coffee‘,31),
(‘Alex Python‘,120),
]
写入:
#先打开一个文件,用操作,没有会自己创建 w是写权限,
files = open("shopping_cart.txt","w") # "w"
#这一步就把列表转成了字符串,“”是随便写的,加个“ww”也行,目的就是转下格式
但类型还是list,不知为啥
product_list.append(" ")
#循环列表 循环写入,每次打印都加个,号
for i in product_list:
files.write(str(i))
files.write(",")
#关闭连接
files.close()
读取:
# r是读权限
f = open("shopping_cart.txt","r") # "w"
#读取一行
first_line = f.readline()
#这个文件用的是上边写入的那个,末尾多了东西,切片取
str=first_line[0:-3]
#用这个函数转字符串为列表
b=eval(str)
print(b)
标签:笔记 time ges 字母 font line 隐式转换 中间 image
原文地址:http://www.cnblogs.com/HL-blog/p/7348598.html