标签:des style blog http color io 使用 ar strong
基础—高级
以前用各种书籍载体在上面按照特定的格式记录信息,就像现在的excel表格,
但是,如果当数据有几千万条的时候,查询就非常慢了
所以我们需要一种高效的解决方案:数据库(其实也是操作一种特殊格式的文件)
数据库不仅仅要存储数据,还要提供方便快捷的查询,修改,删除等功能
需要做到:海量存储,快速查询,多用户同时查询,用户访问安全性,数据存储完整性(正确性)等
?
数据的仓库,货仓里有很多货架(库文件),货架有不同的种类,不同的架子放不同的货物,
管理仓库的就管理员就对应DBA
数据如何存储
?
?
数据库软件:
现在市面上有很多种数据库:mssqlserver,oracle,db2,access, SQLite等
mssqlserver是微软出品的,大型数据库,和net结合度很高
oracle是甲骨文公司,被谷歌收购了,大型数据库,注重数据安全性
db2也是一个大型数据库
access是微软的一个小型文件数据库,在office套件中
?
数据库实例:用来区别数据库引擎的名字,如果不写那就是默认的"MSSQLSERVER"
SUNCODERBOOK 机器名
115.21.23.58 IP地址
?
验证方式:
windows验证:使用登陆windows的账号和密码
sqlserver验证:填写账号和密码,
????????
?
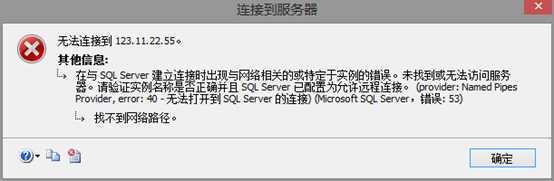
此错误是没有开数据库服务
?
数据库文件:磁盘上的文件
?
数据库服务:这个才是真正的数据库
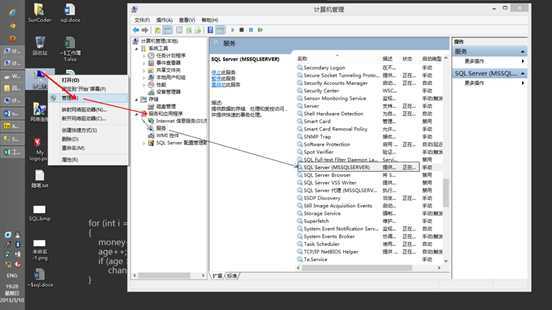

成功安装完数据库之后,会有一个"SQL Server Management Studio",
打开这个软件即可操作数据库,
但真正的数据库并不是这个软件,是系统内一个没有界面的服务程序,
由这个管理工具,发送指令操作这个服务,然后服务操作硬盘上一个".mdf"数据库文件
数据就是存在这个mdf文件里的
?
建库:建立数据库
注:一个数据库不仅仅只能是一个数据文件和一个日志文件,
?
表概念:在一个数据库(上述第二种概念),如同仓库里面的货架一样,不同的数据放在不同的表里面,根据放的数据不一样,对使用空间进行优化
列,行概念:一张表里面的每一项,就是表示这个表要包含写什么类型的数据,列叫做字段
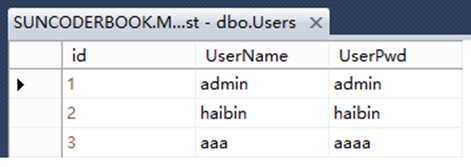
这张表包含 编号 用户名 用户密码 三列
一共有3条数据 每一行就是一条数据
安装好数据库后,可以使用自带的数据库管理工具进行管理,也可以使用visusl studio进行管理,也可以使用cmd命令管理,
用管理工具管理需要连接数据库
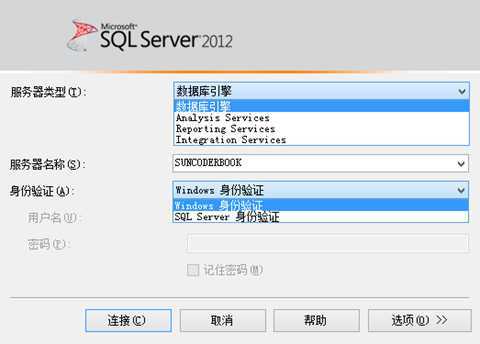
服务器类型:数据库不仅仅只有数据库引擎,还有其他的引擎,数据库引擎就是以存储数据为主要功能的程序核心
à服务器名称:服务器的地址,如果是网络线上服务器,填写这个服务器的ip地址,开发的时候一般数据库就装在本机上,所以这里可以直接填写计算机名字或者是实例名字
à实例名:同一台服务器用来区分多个运行的数据库引擎的名字,开发的时候一般只有一个实例,所以填写"."就可以了,如果安装的数据库版本是express版本的话那么就是"./express"
à身份验证:登陆数据库的验证模式
windows 身份验证,就是使用本机当前登陆的用户的账号密码登陆,
sqlserver身份验证,就是使用安装时或安装后自定义的一个账号和密码登陆
以上两种模式,在数据库安装的时候会有选项供选择
用管理工具连接上数据库之后,在对象资源管理器上右键,有新建数据库选项,点击打开窗口,填写相关信息
住:初始大小,路径
选项中:兼容级别
?
展开新建的表:在"表"上右键,有新建表选项,
?
?

工资:monney类型
分类 | 备注和说明 | 类型 | 说明 |
二进制数据类型 | 存储非子符和文本的数据 | Image | 可用来存储图像 |
文本数据类型 | 字符数据包括任意字母、符号或数字字符的组合 | Char,8000 | 固定长度的非 Unicode 字符数据。固定长度的字符串相对于可变长度的字符串来说效率要高一些,在数据长度固定的情况下优先选用固定长度,省去了计算长度的过程,提高效率 |
Varchar,8000 | 可变长度非 Unicode 数据 | ||
Nchar,4000 | 固定长度的 Unicode 数据 | ||
Nvarchar,4000 | 可变长度 Unicode 数据 | ||
Text varchar(max) | 存储长文本信息(指针,2G) varchar(max),大字符串类型可以保存非常多的字符,但是对于这种类型的数据DBMS经常将它们保存到单独的空间中,这就导致了数据的保存和加载速度比较慢,因此除非必要,否则不要使用。 | ||
Ntext nvarchar(max) | Nvarchar(max)代替 | ||
日期和时间 | 日期和时间在单引号内输入 | Datetime | 日期和时间 |
数字数据 | 该数据仅包含数字,包括正数、负数以及分数 | int smallint | 整数 |
Float 小数,单精度 real | 数字 | ||
货币数据类型 | 用于十进制货币值,money 和 smallmoney 数据类型精确到它们所代表的货币单位的万分之一。 | Money(C#:double) 双精度 | ? |
Bit数据类型 | 表示是/否的数据 | Bit bool | 存储布尔数据类型(1-true 0-false) |
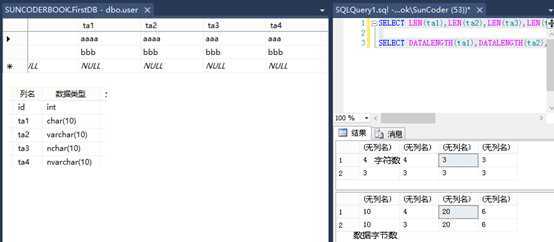
Char,8000 固定长度 非unicode
Varchar,8000 可变长度 非unicode
Nchar,4000 固定长度 unicode
Nvarchar,4000 可变长度 unicode
?
如果实际开发中,对于位数能确定的数据,就用固定长度的
如果有中文的,要用unicode
?
身份证号:18位 ,数字,字母,
银行卡:19 数字, char
?
?
?
?
不允许保存修改,要求重新创建,
?
Unicode 是用两个字节表示一个字符
工具-选项—设计器-去掉勾"阻止保存"
主键的作用
业务主键:
逻辑主键

为什么要有主外键 示例见批注
?
?
什么是sql语句
?
CREATE DATABASE HeiMaBlog
ON PRIMARY --默认就属于PRIMARY主文件组,可省略
(
NAME=‘HeiMaBlog‘, --主数据文件的逻辑名
FILENAME=‘D:\ HeiMaBlog_data.mdf‘, --主数据文件的物理名
SIZE=5mb, --主数据文件初始大小
MAXSIZE=10mb, --主数据文件最大的值
FILEGROWTH=15% --主数据文件的增长率
)
LOG ON -- 日志文件
(
NAME=‘HeiMaBlog_log‘,
FILENAME=‘D:\HeiMaBlog_log.ldf‘,
SIZE=3mb, --日志文件初始大小
MaxSize=20mb,
FILEGROWTH=1MB
)
GO
主数据文件名和日志文件名不能一样,主数据文件大小最小是5MB,日志文件最小是1MB
?
"GO"关键字是明确告诉管理工具,先把上面的代码执行了,然后在执行下面,该关键字不处于sql语法本身
USE HeiMaBlog--将当前数据库设置为HeiMaBlog
GO
CREATE TABLE Score
(
ScoreId INT IDENTITY(1,1),
SId INT NOT NULL ,
English INT NOT NULL,
Math INT NOT NULL
--Name Varchar(50) not null
)
?
?
create table Teacher
(
Id int identity(1,1),
Name nvarchar(10) not null,
Gender bit not null default 0,
Age int not null default 10,
Salary money not null,
Birthday datetime not null default getdate(),
)
?
insert into students values(null,‘new‘,‘男‘,0,getdate())
default
nvarchar N,
set identity_insert teacher off

delete truncate
drop table Teacher

?
非空约束
????建表的时候每一个字段后面的null复选框
?
主键约束(PK) primary key constraint
????设置主键就可以了,数据不重复 且 不能为空
?
唯一约束 (UQ)unique constraint
唯一 允许为空,但只能出现一次
右键"索引/键"里面有
?
默认约束 (DF)default constraint 默认值
????建表设置默认值的时候就添加了这个约束
?
检查约束 (CK)check constraint 范围以及格式限制
????在表的设计界面,在字段上右键,有check约束
????
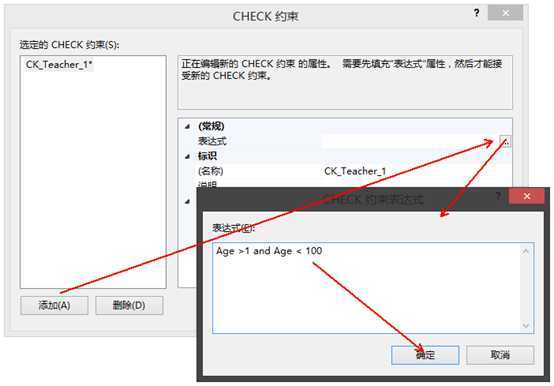
?
外键约束 (FK)foreign key constraint 表关系:保证外键值来源于主键
增加外键约束时,设置级联更新、级联删除:
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
?
?
最基本的检索代码
between 。。and。。。:数据库效率,在数据库内部做过特殊优化的;优先使用;。。。范围表识相当于>=,<=
?
select top 10 * from Teacher
查出前面10行
select top 20 percent * from Teacher
查出前面20%的数据
select distinct(age) from teacher
查询年龄列,但只要不重复的
select distinct age,name from teacher
查询两个列都不重复的,可以有其中一个是相等的
distinct:去除重复数据,是针对查询结果去除重复行;distinct先于top执行,也要写在top前面。
max, min, avg, count ······
?
?
% _ [] ^ not like
Is null
AES DESC 汉字
一个班级一张表,然后有个小组表,小组的表的信息只有"一组,二组,三组"这些信息,没有组员名字,年龄等信息,
一个小组包含多个组员的信息,要知道小组的名字,不知道到底要拿哪一个显示
根据"什么"分组,那么可以想象这个分组的名字就是"什么"
5>…Select 5-1>选择列,5-2>distinct,5-3>top
1>…From 表
2>…Where 条件
3>…Group by 列
4>…Having 筛选条件
6>…Order by 列
从某某表查询大于多少小于多少的数据,然后根据某某分个组,筛选下不想要的组
?
?
CAST CONVERT
使用注意点:
要求在一个表格中查询出学生的英语最高成绩、最低成绩、平均成绩
建库脚本à
查询每位老师的信息,包括姓名、工资,并且在最后一行加上平均工资和最高工资
建库脚本à
declare @str varchar(10) = ‘ aa ‘
定义一个变量,并且赋值
select LTRIM(@str)--aa --
union all
select CONVERT(varchar,DATALENGTH(LTRIM(@str)))—5
union all
select RTRIM(@str)-- aa-
union all
select CONVERT(varchar,DATALENGTH(RTRIM(@str)))—5
union all
select LTRIM(RTRIM(@str))--aa—
union all
select CONVERT(varchar,DATALENGTH(LTRIM(RTRIM(@str))))--2
select left(‘abcdefg‘,3)--abc
select right(‘abcdefg‘,3)--efg
select SUBSTRING(‘abcdefg‘,3,4)--cde
select SUBSTRING(‘abcdefg‘,3,40)--cdefg
9.1 从第三个字符截取四十个长度,长度不足,不会报错
select SUBSTRING(‘abcdefg‘,30,40)
9.2 从第三十个字符截取四十个长度,长度不足,不会报错
补充:
?
select GETDATE()--2013-02-27 10:25:32.532
获取当前日期
select DATEADD(day,2,getdate())--2013-03-01 10:27:327
在现有基础上加上两天
select DATEDIFF(day,‘2012-05-05‘,GETDATE())--298
取得日期的特定部分
select DATEPART(year,getdate())--2013
select DATEPART(MONTH,GETDATE())--2
select DATEPART(day,GETDATE())--27
select DATEPART(hour,getdate())--10
select DATEPART(minute,GETDATE())--43
select DATEPART(SECOND,GETDATE())--14
select DATEPART(MILLISECOND,GETDATE())--817
?
select * from users where DATEPART(year,dat)=1990
建库脚本à
?
标签:des style blog http color io 使用 ar strong
原文地址:http://www.cnblogs.com/tmacsilence/p/3956271.html