标签:输入 long end images deepcopy 浮点数 3.2 ndt 信道
1.1 sys
#!/usr/bin/env python3 # Author: Sam Gao import sys print(sys.path) #打印PYTHONPATH环境变量 # [‘/home/sam/PycharmProjects/s14/day1‘, # ‘/home/sam/PycharmProjects/s14‘, # ‘/usr/lib/python35.zip‘, # ‘/usr/lib/python3.5‘, # ‘/usr/lib/python3.5/plat-x86_64-linux-gnu‘, # ‘/usr/lib/python3.5/lib-dynload‘, # ‘/usr/local/lib/python3.5/dist-packages‘, # ‘/usr/lib/python3/dist-packages‘] print(sys.argv)# 使用console 执行 python3 sys_mokuai.py test you are # 结果 [‘sys_mokuai.py‘, ‘test‘, ‘you‘, ‘are‘] print(sys.argv[2]) # 结果 you
1.2 os
import os print(os.system("ifconfig | grep 10.100 |awk ‘{print $2}‘")) # 执行系统命令,,并返回状态结果 #结果 # 10.100.211.48 # 0 print(os.popen("ifconfig | grep 10.100 |awk ‘{print $2}‘").read()) #返回命令执行的结果 #1 os.popen("ifconfig | grep 10.100 |awk ‘{print $2}‘") 返回内存地址,即把结果存进地址,使用read()读出了 #结果 #10.100.211.48
1.3 案例 把参数当作命令执行
[root@linux-node1 ~]# cat test.py #!/usr/bin/env python # -*- coding: gbk -*- import os,sys os.system(‘ ‘.join(sys.argv[1:]))
[root@linux-node1 ~]# python test.py ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.130.128 netmask 255.255.255.0 broadcast 192.168.130.255 inet6 fe80::20c:29ff:fec1:295a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:c1:29:5a txqueuelen 1000 (Ethernet) RX packets 181757 bytes 20497644 (19.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 29679 bytes 2669636 (2.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
2.1 自定义模块
[root@linux-node1 ~]# cat test.py #!/usr/bin/env python print ‘Hello World!‘
[root@linux-node1 ~]# cat test2.py #!/usr/bin/env python import test
[root@linux-node1 ~]# python test2.py Hello World!
注:test.py 必须放在环境变量的目录里,可使用print sys.path 查询,一般放在当前目录或者放在E:\Python36\Lib\site-packages 目录下,在E:\Python36\Lib\site-package\_pycache_ 多了test.pyc
2.2 认识pyc
2.2.1 Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2.2.2 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
2.2.3 Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
2.2.4 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
python3最重要的新特性大概要算对文本和二进制数据做了更为清晰的区分,文本总是unicode字符集,有str类型表示,二进制数据则有bytes类型表示。python3不会以任何隐式的方式混用str和bytes,正是这是的这两者的区别特别明显,你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然);我们不关心字符串在内部是如何被表示的,也不关心它用几个字节来表示每个字符。只有在将字符串编码成字节(如用于通信信道的传输)或将字节解码成字符串时,才考虑这些问题。
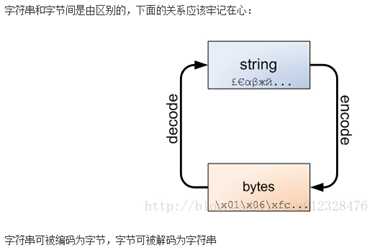
3.1 创建bytes类型数据
>>> a = bytes([1,2,3,4]) >>> a b‘\x01\x02\x03\x04‘ >>> type(a) <class ‘bytes‘> >>> >>> a = bytes(‘hello‘,‘ascii‘) >>> a b‘hello‘ >>> type(a) <class ‘bytes‘>
3.2 按utf-8的方式编码,转成bytes以及解码成字符串
>>> a = ‘hello world‘ >>> type(a) <class ‘str‘> >>> a ‘hello world‘
>>> b = a.encode(encoding=‘utf-8‘) >>> type(b) <class ‘bytes‘> >>> >>> b b‘hello world‘ >>> >>> >>> c = b.decode(encoding=‘utf-8‘) >>> type(c) <class ‘str‘> >>> c ‘hello world‘
msg = "我爱你" print(msg) # 我爱你 print(msg.encode(encoding=‘utf-8‘)) # b‘\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0‘ print(b‘\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0‘.decode(encoding=‘utf-8‘)) # # 我爱你
参考自:http://www.cnblogs.com/zanjiahaoge666/p/6402907.html
>>> grilF = ‘Snow‘ if 2 > 1 else ‘Jey‘ >>> grilF ‘Snow‘ >>> grilF = ‘Snow‘ if 2 < 1 else ‘Jey‘ >>> grilF ‘Jey‘
5.1 数字
int(整型)在32位机器上,整数的位数为32位;在64位系统上,整数的位数为64位
long(长整型)自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。pyhton 3X没有长整型
float(浮点型)浮点数用来处理实数,即带有小数的数字。
complex(复数)复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
5.2 布尔值 真或假 1 或 0
6.1 字符串具有不可改变的特性
>>> str1 = ‘your‘ >>> str1 = str1 + ‘name‘ >>> str1 ‘yourname‘
当执行第二行的时候,在内存里又开辟了一个空间存储"yourname",而不是在原来存储“your”的地方修改,使得str1指向这个新地址
6.2 切片
>>> str=‘my name is sam, and i love girl‘ >>> str[1] ‘y‘ >>> str[3:7] ‘name‘ >>> str[-4:] #截取最后4个字符 ‘girl‘ >>> str[-1:-5:-1] #反序截取 ‘lrig‘
6.3 字符串长度
>>> str=‘my name is sam, and i love girl‘ >>> len(str) 31
6.4 包含
>>> str=‘my name is sam, and i love girl‘ >>> ‘name‘ in str # 不存在则报错 True >>> ‘tiger‘ not in str True
6.5 循环
>>> str=‘your name‘ >>> for i in str: ... print(i) ... y o u r n a m e
6.6 字符串其它方法
6.6.1 count
>>> ‘your name, ming zi‘.count(‘n‘) 2 >>> ‘your name, ming zi‘.count(‘n‘,6) 1 >>> ‘your name, ming zi‘.count(‘n‘,6,8) 0
6.6.2 capitalize
>>> "youy name".capitalize() ‘Youy name‘
6.6.3 center
>>> "youy name".center(50,‘-‘) ‘--------------------youy name---------------------‘
6.6.4 encode
>>> "youy name".encode(encoding=‘utf-8‘) b‘youy name‘
6.6.5 endwith
>>> "youy name".endswith("me") True
6.6.6 expandtabs
>>> "\tyouy name".expandtabs(10) ‘ youy name‘
6.6.7 format
>>> "I am %s, %d year old, I love %s" % (‘Sam‘,12, ‘dog‘) ‘I am Sam, 12 year old, I love dog‘ >>> "I am {}, {} year old, I love {}".format(‘Sam‘,12, ‘dog‘) ‘I am Sam, 12 year old, I love dog‘ >>> "I am {2}, {0} year old, I love {1}".format(12,‘dog‘, ‘Sam‘) ‘I am Sam, 12 year old, I love dog‘ >>> "I am {name}, {age} year old, I love {dong}".format(name=‘Sam‘,age=12, dong=‘dog‘) ‘I am Sam, 12 year old, I love dog‘
注:%s字符串,%d整型,%f浮点数
6.6.8 format_map
>>> ‘My name is {name}, I am {age} year old‘.format_map({‘name‘: ‘Sam‘, ‘age‘: 23}) ‘My name is Sam, I am 23 year old‘
6.6.9 find左边找 rfind右边找
>>> ‘My name is Sam, I am 23 year old‘.find(‘a‘) # 左边找 4 >>> ‘My name is Sam, I am 23 year old‘.find(‘a‘,5) 12 >>> ‘My name is Sam, I am 23 year old‘.find(‘a‘,13, 19) 18 >>> ‘yui‘.find(‘l‘) # 找不到则返回-1 -1 >>> ‘My name is Sam, I am 23 year old‘.rfind(‘a‘) # 右边找 26
6.6.10 index
>>> ‘My name is Sam, I am 23 year old‘.index(‘a‘) 4 >>> ‘My name is Sam, I am 23 year old‘.index(‘a‘,5) 12 >>> ‘My name is Sam, I am 23 year old‘.index(‘a‘, 13, 19) 18 >>> ‘yui‘.index(‘l‘) # 找不到则,报错 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
6.6.11 isalnum 检查判断字符串是否包含字母数字字符
>>> ‘name‘.isalnum() True >>> ‘12‘.isalnum() True >>> ‘AAB‘.isalnum() True >>> ‘!fff‘.isalnum() False
6.6.12 isalpha检测字符串是否只由字母组成
>>> ‘asdf‘.isalpha() True >>> ‘1234‘.isalpha() False >>> ‘gh67‘.isalpha() False
6.6.13 isdecimal 非负整数 检查字符串是否只包含十进制字符。这种方法只存在于unicode对象
>>> ‘ghjjj‘.isdecimal() False >>> ‘12‘.isdecimal() True >>> ‘12.7‘.isdecimal() False
6.6.14 isdigit 非负整数 检测字符串是否以数字组成
>>> ‘12‘.isdigit() True >>> ‘12.8‘.isdigit() False >>> ‘-12‘.isdigit() False >>> ‘0‘.isdigit() True
6.6.15 isidentifier 检测字符串是否以字母开头
>>> ‘hhh‘.isidentifier() True >>> ‘77‘.isidentifier() False >>> ‘!@‘.isidentifier() False >>> ‘7ggg‘.isidentifier() False
6.6.16 islower lower
>>> ‘AhhBgggG‘.islower() False >>> ‘hhhhh‘.islower() True
6.6.17 isnumeric 检测字符串是否只由数字组成。这种方法是只针对unicode对象。
>>> ‘678‘.isnumeric() True >>> ‘678.9‘.isnumeric() False >>> ‘678.0‘.isnumeric() False
6.6.18 isprintable 判断字符串中所有字符是否都属于可见字符
>>> ‘hyyuuuu\nyyyyyy‘.isprintable() False >>> ‘hyyuuuuyyyyyy‘.isprintable() True
6.6.19 isspace 检测字符串是否为空格
>>> ‘jjjiiii‘.isspace() False >>> ‘ ‘.isspace() True
6.6.20 istitle 判断字符串是否适合当作标题(其实就是每个单词首字母大写) title
>>> ‘Your Name‘.istitle() True
6.6.21 isupper 判断字符串中所有字母字符是否都是大写字母 upper
>>> ‘fghhh‘.isupper() False >>> ‘FGGGGG‘.isupper() True
6.6.22 join 字符串列表连接
>>> ‘+‘.join(‘string‘) ‘s+t+r+i+n+g‘ >>> ‘+‘.join([‘i‘, ‘am‘, ‘your‘]) ‘i+am+your‘
6.6.23 strip lstrip rstrip 移除左右 空格 换行符
str = ‘ ggggggggggg \n‘ print(str) print(str.strip()) print(str.lstrip()) print(str.rstrip()) print(‘````````````‘)
6.6.24 ljust rjust 与center 类似
>>> ‘name‘.ljust(50, ‘*‘) ‘name**********************************************‘ >>> ‘name‘.rjust(50, ‘*‘) ‘**********************************************name‘
6.6.25 lower 将字符串的大写换成小写 islower
>>> ‘ASDF‘.lower() ‘asdf‘ >>> ‘AS7766!DF‘.lower() ‘as7766!df‘
6.6.26 maketrans translate
>>> tab = str.maketrans(‘abc‘,‘123‘) >>> ‘i am your hero sb‘.translate(tab) ‘i 1m your hero s2‘
6.6.27 partition rpartition 如果分隔符包含在字符串中,返回一个元组,第一个为分隔符左边字符串,第二个为分隔符,第三个为右边字符串
>>> ‘zxcvbnvbhjuu‘.partition(‘vb‘) # 匹配左边的 (‘zxc‘, ‘vb‘, ‘nvbhjuu‘) >>> ‘zxcvbnvbhjuu‘.partition(‘pp‘) (‘zxcvbnvbhjuu‘, ‘‘, ‘‘) >>> ‘zxcvbnvbhjuu‘.rpartition(‘vb‘) # 匹配右边的 (‘zxcvbn‘, ‘vb‘, ‘hjuu‘) >>> ‘zxcvbnvbhjuu‘.rpartition(‘pp‘) (‘‘, ‘‘, ‘zxcvbnvbhjuu‘)
6.6.28 replace
>>> ‘your name, i am a boy‘.replace(‘a‘, ‘B‘) ‘your nBme, i Bm B boy‘ >>> ‘your name, i am a boy‘.replace(‘a‘, ‘B‘, 1) ‘your nBme, i am a boy‘
6.6.29 split rsplit
>>> ‘your name, i am a boy‘.split(‘a‘) [‘your n‘, ‘me, i ‘, ‘m ‘, ‘ boy‘] >>> ‘your name, i am a boy‘.split(‘a‘,2) # 从左边划分 [‘your n‘, ‘me, i ‘, ‘m a boy‘] >>> ‘your name, i am a boy‘.rsplit(‘a‘,2) # 从右边划分 [‘your name, i ‘, ‘m ‘, ‘ boy‘]
6.6.30 splitlines
>>> ‘‘‘My name\n is Sam, I am\n 23 year old‘‘‘.splitlines() [‘My name‘, ‘ is Sam, I am‘, ‘ 23 year old‘]
6.6.31 startswith
>>> ‘My name is Sam, I am 23 year old‘.startswith(‘My‘,4,10) False >>> ‘My name is Sam, I am 23 year old‘.startswith(‘me‘,4,10) False >>> ‘My name is Sam, I am 23 year old‘.startswith(‘ame‘,4,10) True
6.6.32 swapcase
>>> ‘ASfrtAAggg‘.swapcase() ‘asFRTaaGGG‘
6.6.33 title istitle
>>> ‘you name‘.title() ‘You Name‘
6.6.34 upper isupper
>>> ‘i am your hero sb‘.upper() ‘I AM YOUR HERO SB‘
6.6.35 zfill
>>> "youy name".zfill(50) ‘00000000000000000000000000000000000000000youy name‘
#!/usr/bin/env python3 # encoding: utf-8 # Author: Sam Gao #列表基础 # 1. 空列表 names = [] #2 names = [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘] # 查找 print(names) # [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘] print(names[3]) # xu print(names[-2]) # 取倒数第二位 xiang print(names[-2:]) # 取最后两位 [‘xiang‘, ‘xu‘] print(names[2:]) # 取names[2] 本身 及以后的元素 [‘xiang‘, ‘xu‘] print(names[1:3]) # 取names[1] names[2], 但不包括names[3]. [‘liu‘, ‘xiang‘] #默认从左到右取 print(names[-1::-1]) # 右到左 [‘xu‘, ‘xiang‘, ‘liu‘, ‘zhang‘] #跨两个元素取 步长切片 print(names[::2]) #names = [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘, ‘liu‘] #print(names.index(‘liu‘)) # 返回元素的下标 1 #print(names.count(‘liu‘)) # 返回元素的个数 2 # names.reverse() # 反转 # names.sort() # 排序, 按照ascii 排序 #print(names) # 增加 #1 names.append("gao") #加到最后 print(names) # [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘, ‘gao‘] #2 names.insert(2, ‘wang‘) # 插到第二位, 并后面的元素向后移动一位 print(names) # [‘zhang‘, ‘liu‘, ‘wang‘, ‘xiang‘, ‘xu‘, ‘gao‘] #3 # names2 = [‘du‘, ‘zi‘] # names.extend(names2) # 增加列表 # print(names) # [‘zhang‘, ‘liu‘, ‘wang‘, ‘xiang‘, ‘xu‘, ‘gao‘, ‘du‘, ‘zi‘] # 修改 names[2] = ‘zhou‘ print(names, names[2]) # [‘zhang‘, ‘liu‘, ‘zhou‘, ‘xiang‘, ‘xu‘, ‘gao‘] zhou # 删除 #1 names.remove("liu") print(names) # [‘zhang‘, ‘zhou‘, ‘xiang‘, ‘xu‘, ‘gao‘] #2 del names[0] # print(names) # [‘zhou‘, ‘xiang‘, ‘xu‘, ‘gao‘] #3 names.pop() # 默认删除最后一位 print(names) # [‘zhou‘, ‘xiang‘, ‘xu‘] names.pop(1) # 删除数字标号为1 的元素 print(names) # [‘zhou‘, ‘xu‘] #4 # names.clear() # 清除列表 # 复制 names = [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘, ‘liu‘] #1 浅copy,只能copy 第一层 names2 = names.copy() print(names2) # [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘, ‘liu‘] names[0] = ‘张‘ print(names) # [‘张‘, ‘liu‘, ‘xiang‘, ‘xu‘, ‘liu‘] print(names2) # [‘zhang‘, ‘liu‘, ‘xiang‘, ‘xu‘, ‘liu‘] names = [‘zhang‘, ‘liu‘, [‘sam‘, ‘yang‘],‘xiang‘, ‘xu‘, ‘liu‘] names2 = names.copy() print(names2) # [‘zhang‘, ‘liu‘, [‘sam‘, ‘yang‘], ‘xiang‘, ‘xu‘, ‘liu‘] names[2][0] = ‘山姆‘ print(names) # [‘zhang‘, ‘liu‘, [‘山姆‘, ‘yang‘], ‘xiang‘, ‘xu‘, ‘liu‘] print(names2) # [‘zhang‘, ‘liu‘, [‘山姆‘, ‘yang‘], ‘xiang‘, ‘xu‘, ‘liu‘] # copy模块 import copy names2 = copy.copy(names) # == names.copy() 浅copy == names2 = names[:] == names2 = list(names) names2 = copy.deepcopy(names) # 深copy 完全复制 # 循环 for i in names: print(i)
案例

#!/usr/bin/env python3 # encoding: utf-8 # Author: Sam Gao commoditys = [(‘car‘, 10000), (‘ipad‘, 5000), (‘pen‘, 10), (‘house‘, 5000)] shopping_cart = [] while True: salary = input(‘pis input you salary:‘) if salary.isdigit(): print(‘welcome shopping mall‘) blance = int(salary) break else: print(‘pls input valid salary!‘) add_info = ‘added [%s] to your shopping cart, your blance is \033[31;1m[%d]\033[0m‘ while True: for commodity in commoditys: # for index, item in enumerate(commoditys): print(commoditys.index(commodity), ":", commodity) user_chice = input("Do you want to shoppping? ") if user_chice.isdigit(): user_chice = int(user_chice) if user_chice in range(len(commoditys)): select_commodity = commoditys[user_chice] if select_commodity[1] <= blance: blance -= select_commodity[1] shopping_cart.append(select_commodity[0]) print(add_info % (select_commodity[0], blance)) else: print("your current blance is not enugh") else: print(‘commodity is not in the list!‘) elif user_chice == ‘q‘: print("-----------------shopping list------------------") for item in shopping_cart: print(item) print(‘------------------------------------------------‘) print(‘your current blance is %d‘ % blance) exit() else: print(‘invlid option‘)
元组就是不可变的列表,只能读取,不能修改
8.1 元组定义
>>> name=(‘Sam‘, ‘Gao‘, ‘jey‘) >>> name (‘Sam‘, ‘Gao‘, ‘jey‘) >>> team=(‘ops‘,) >>> team (‘ops‘,) >>> type(team) <class ‘tuple‘>
8.2 元组只有两种方法
names = (‘gao‘, ‘sam‘, ‘gao‘) names.count(‘gao‘) names.index(‘gao‘)
#!/usr/bin/env python3 # encoding: utf-8 # Author: Sam Gao info = { ‘stu1‘: ‘gao‘, ‘stu2‘: ‘liu‘, ‘stu3‘: ‘ma‘, ‘stu4‘: ‘cang‘ } print(info) # {‘stu3‘: ‘ma‘, ‘stu1‘: ‘gao‘, ‘stu4‘: ‘cang‘, ‘stu2‘: ‘liu‘} # 字典是无序的 # 查找 print(info[‘stu2‘]) # liu 不存在则报错 print(info.get(‘stu1‘)) # 不存在不报错,返回none # 修改 info[‘stu1‘] = ‘wang‘ print(info[‘stu1‘]) # wang # 增加 info[‘stu5‘] = ‘mazi‘ # 删除 del info[‘stu1‘] info.pop(‘stu2‘) info.popitem() # 随便删除 # 判断 print(‘stu4‘ in info) # 修改+增加 info = { ‘stu1‘: ‘gao‘, ‘stu2‘: ‘liu‘, ‘stu3‘: ‘ma‘, ‘stu4‘: ‘cang‘ } info.setdefault("stu1", "jey") # 如果info 里面存在stu1, 则修改。不存在,则增加 info1 = { ‘stu4‘: ‘gao‘, ‘stu10‘: ‘snow‘ } info.update(info1) # 右则修改,没有则增加 ### 其它 info = { ‘stu1‘: ‘gao‘, ‘stu2‘: ‘liu‘, ‘stu3‘: ‘ma‘, ‘stu4‘: ‘cang‘ } print(info.items()) # dict_items([(‘stu4‘, ‘cang‘), (‘stu1‘, ‘gao‘), (‘stu3‘, ‘ma‘), (‘stu2‘, ‘liu‘)]) 还有 keys() values() new_list = dict.fromkeys([1,2,3], ‘test‘) # {1: ‘test‘, 2: ‘test‘, 3: ‘test‘} 注: 所有的key 共享一个value test ,即,内存地址一样的 print(new_list) # 循环 for i in info: print(i) #结果stu2 # stu4 # stu1 # stu3 for k, v in info.items(): print(k, v) #结果 #stu2 liu # stu4 cang # stu1 gao # stu3 ma #注: 第一种循环要比第二种循环高效很多
标签:输入 long end images deepcopy 浮点数 3.2 ndt 信道
原文地址:http://www.cnblogs.com/gaosy-math/p/7352223.html
