标签:执行 lib ref 输出 wiki 数据 org 运行 链接
这里是前章,我们做一下预备。之前太多事情没能写博客~。。 (此博客只适合python3x,python2x请自行更改代码)
首先你要有bs4模块
windows下安装:pip3 install bs4,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install bs4安装bs4。
linux下安装:sudo pip3 install bs4
还有urllib.request模块
windows下安装:pip3 install urllib.request,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install urllib.request安装urllib.request模块
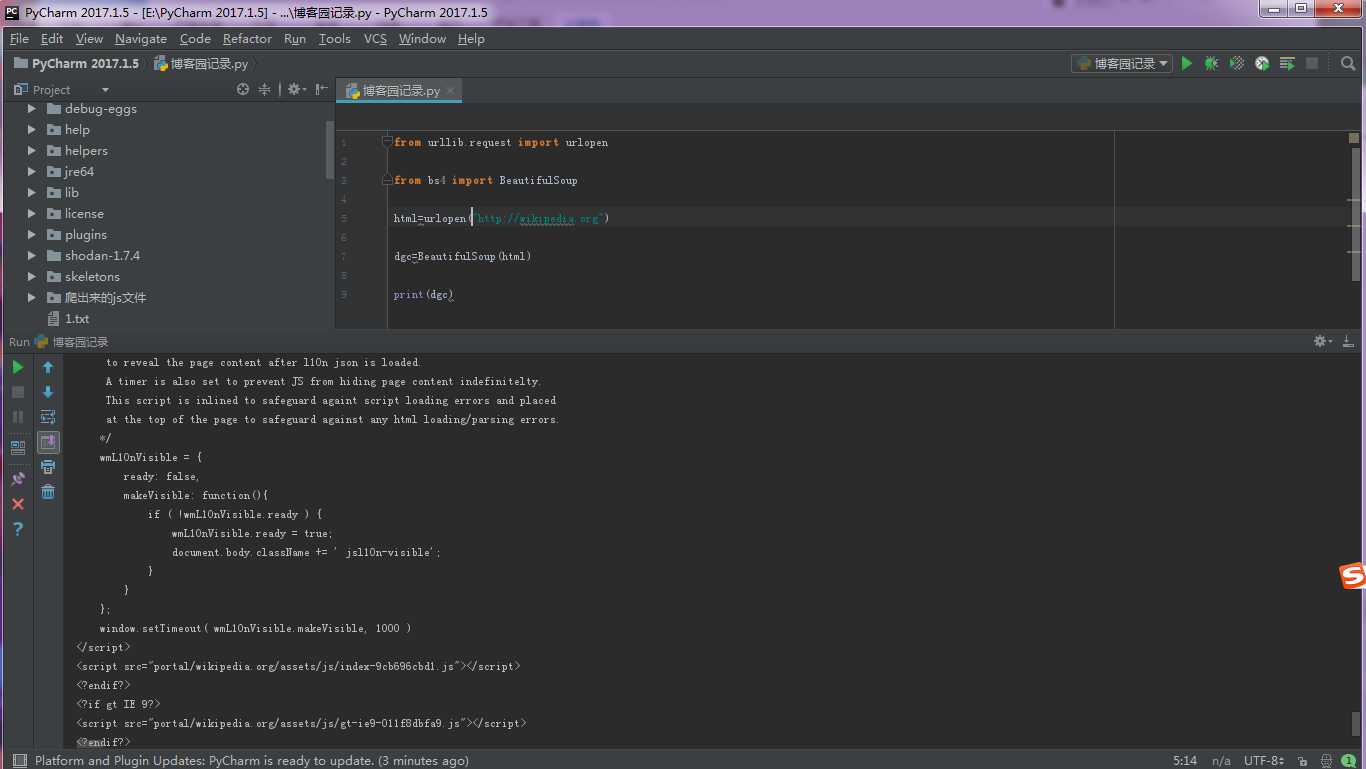
例子1:获取源码
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen("http://wikipedia.org")
dgc=BeautifulSoup(html)
print(dgc)
输出图如下:
这里我忘记加自定义错误了,当然你也可以不加。保险起见还是加
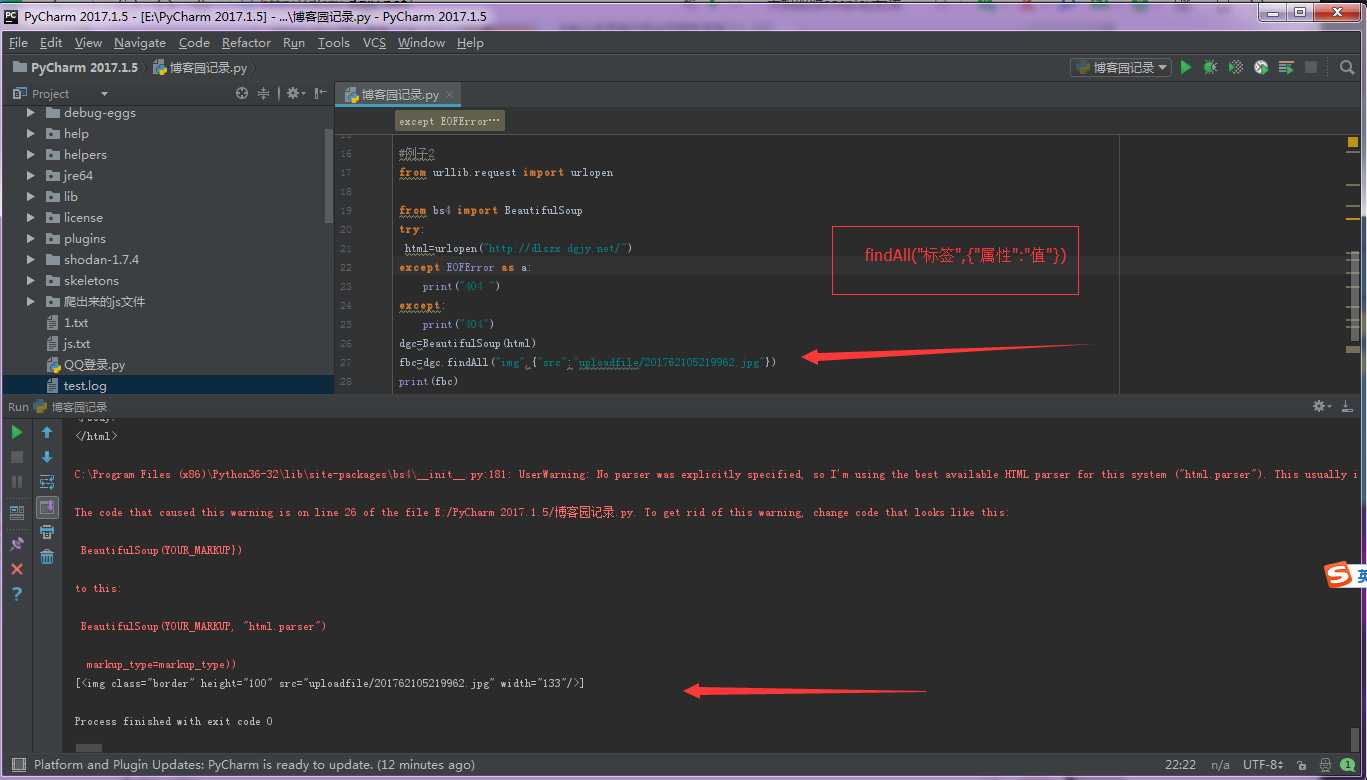
例子二:匹配对应的标签
from urllib.request import urlopen
from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":"uploadfile/201762105219962.jpg"})
print(fbc)
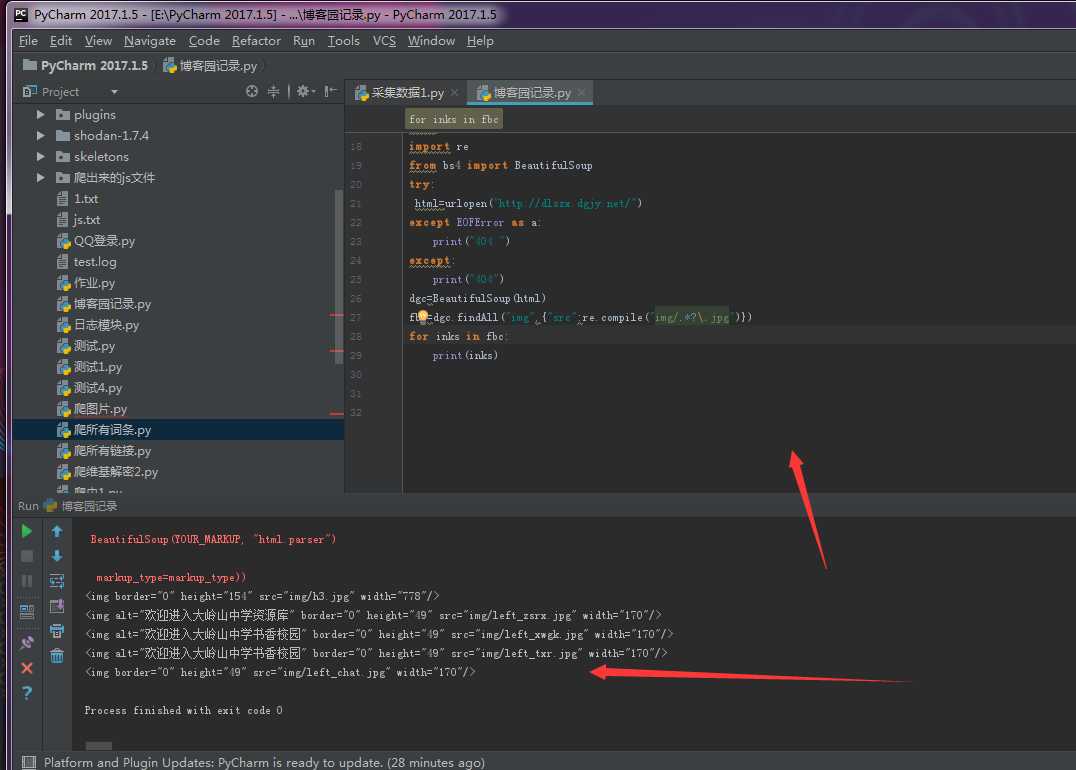
例子3:正则匹配所有对应的标签
不会正则的请去学习
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":re.compile("img/.*?\.jpg")})
for inks in fbc:
print(inks)
注意事项!!!:不要拿findAll去搜索引擎匹配,乱的你想死
搜索引擎正则匹配要求很高:http:\/\/[a-zA-z].*?\[a-z]
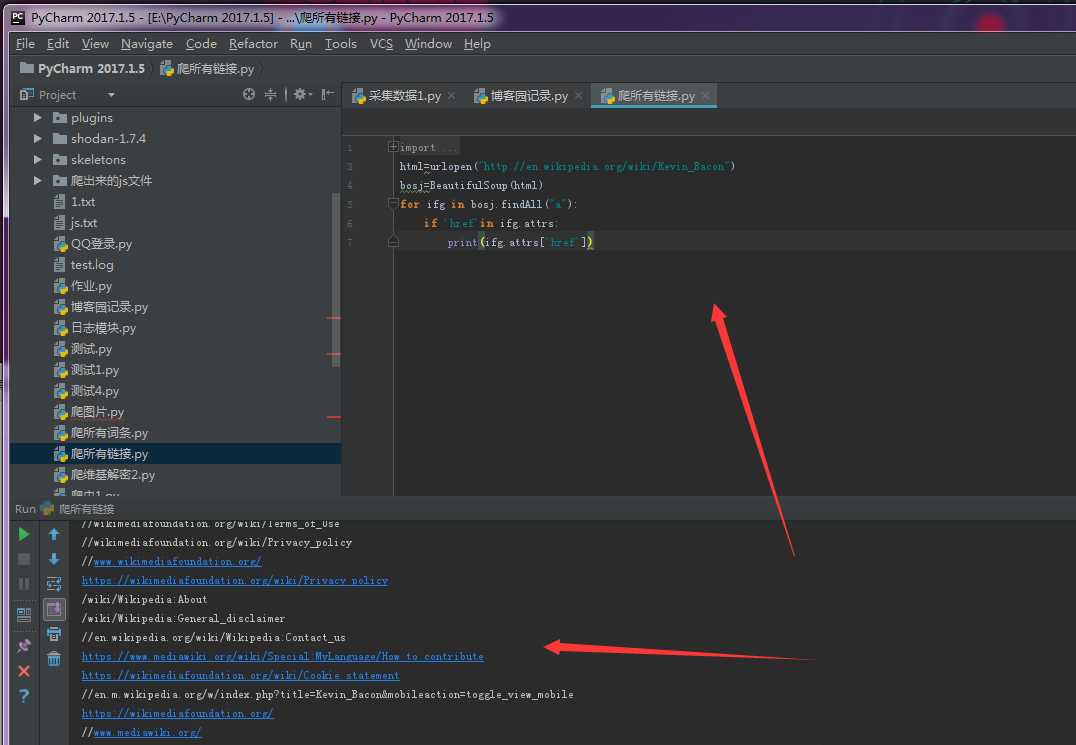
例子4:
匹配网站所有的链接
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://wikipeda.org")
except EOFError as a:
print("EOFError")
except:
print("I dont EOFError")
gfc=BeautifulSoup(html)
for inks in gfc.findAll("a")
if ‘href‘ in inks.attrs:
print("inks.attrs["href"]")
现在的时间是
2017-8-13-13:38
标签:执行 lib ref 输出 wiki 数据 org 运行 链接
原文地址:http://www.cnblogs.com/haq5201314/p/7353257.html