标签:ast mailbox base tps html back www. optimize product
原文地址:https://dzone.com/articles/scalable-distributed-systems-using-akka-spring-boot-ddd-and-java
When data that needs to be processed grows large and can’t be contained within a single JVM, AKKA clusters provides features to build such highly scalable solution. This is an involved article since it touches many aspects of distributed computing. Please prepare to spend a good amount of time on the article, refer to the external links mentioned for a full understanding of each sub-topic and download and play around with provided AKKA initializer/util library to get a deeper understanding of the topics. The provided initializer library is annotated with good documentation that provides contextual meaning while going through the code.
The actors are the building block in AKKA. By using the AKKA cluster sharding technique, the actors can be created in one of the many available nodes within an AKKA cluster. The messages targeted for the cluster sharded AKKA actor gets routed using a sharding algorithm applied on the incoming message. Each cluster sharded actor, in many cases, represents, an Aggregate[root] from Domain-driven design (DDD).
AKKA persistence module can be used further to enable developers to create stateful actors, and the actor state gets persisted (event/command sourcing) and can be recovered during an actor or node failure. The above cluster sharded actor can be configured with AKKA persistence for resiliency.
The Spring framework is battle tested and comes with wide range of countless libraries. It is beneficial to integrate AKKA with Spring framework to benefit from best of both worlds.
Purpose
The purpose of this article to combine the set of technology listed in the introduction section. The article provides users with a reusable akka-initializer library that is built using this technology stack. Putting these libraries to use is not a trivial task; the article aims to simplify this activity. The akka-initializer library could be used to implement micro services based software or build large distributed systems.
Later part of the article takes an arbitrary use case example from banking domain. The example falls into the Complex Event Processing (CEP) domain. The article demonstrates a reference implementation of how to build a highly scalable and resilient CEP solution using the provided akka-initializer library and ESPER
Akka-initializer library comes out with a set of a few additional following features:
-
Make Cluster sharding implementation easier.
-
Make AKKA persistence implementation easier.
-
Make unit testing easier by providing set of utility classes.
-
Makes AKKA and Spring boot integration easier.
-
Provides a feature called time-to-live: When the cluster sharded actor implements this interface, the actor gets removed from the cluster automatically by the library including the clean-up of actors’ state from both persistence store and memory.
-
Provides a feature called Message-Expiry: When the state within a cluster sharded actor implements this interface the messages within the actor state gets expired automatically by the library at the specified interval.
AKKA-Initializer Library Explained
Clone akka initializer library in local machine from here, import it to IDE as a maven project, perform a git clean install and run the unit test cases. The following section explains core AKKA features supported by the AKKA initializer library. This section explains AKKA basics, also explains details of how initializer library.
AKKA actor basics: AKKA actor supports asynchronous message processing at its core. Each processing logic is represented as an actor and actor has a mailbox associated with it. Messages are send to the actor via mailbox and they are delivered in the order its received. These in-memory message boxes are created automatically by AKKA framework. Actors can be local actor, remote actor or in actor running inside an AKKA cluster. See Figure below.
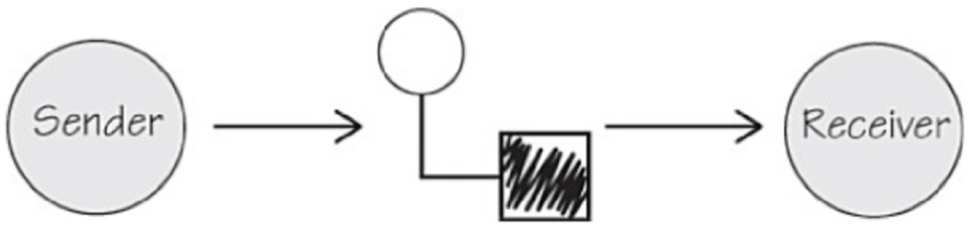
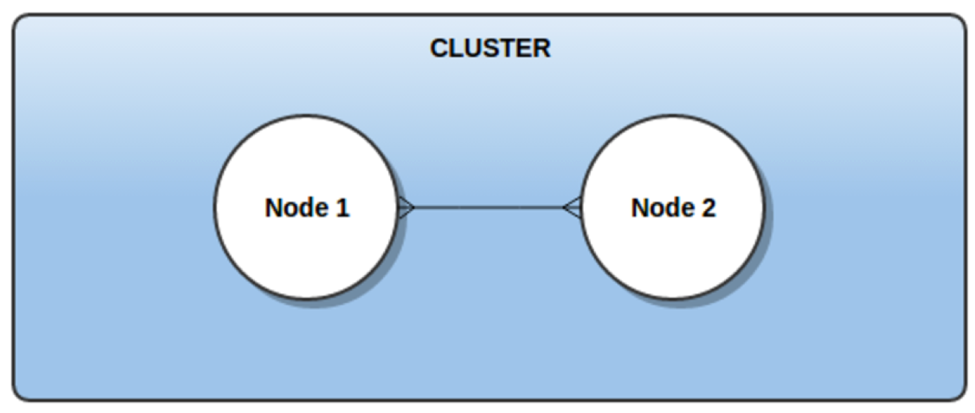
Multiple actor system nodes can be combined to form an AKKA cluster as shown in below Figure. This way actor system scales to multiple machines.
The Akka-initializer library makes it easy to create AKKAcluster shard actors. This section provides a high-level overview of how AKKA cluster sharding works internally and how akka-initializer library eases out to implement cluster sharding. Each sharded[Aggregate] actor needs to be running only on one of the available nodes in the AKKA cluster. Refer to these 3 diagrams below as you read through this section
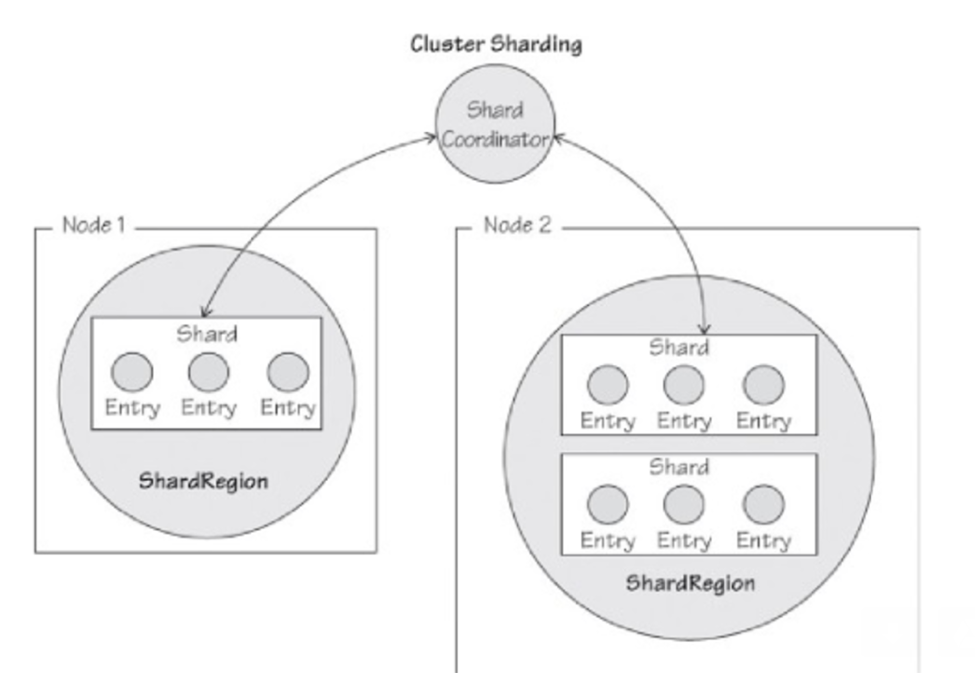
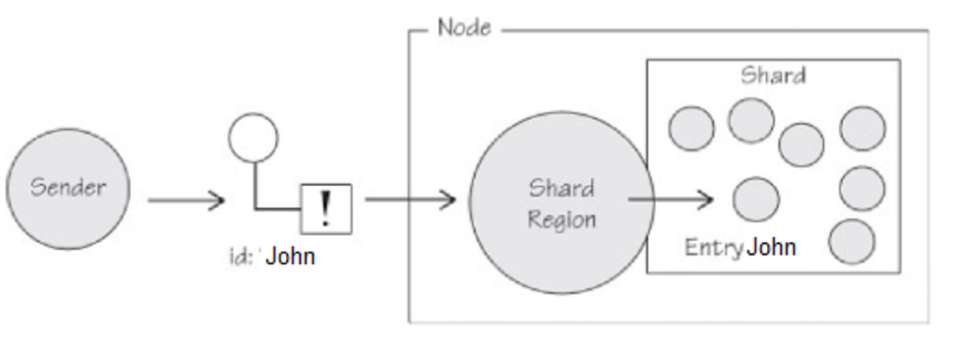
A shard-region extracts the shard and entity id to dispatch the message to the right sharded-entity actor.
- AKKA uses an internal shard actor to manage many sharded-entity actors. The shard actor helps to communicate with the cluster sharded-entity actors and takes care of failover and recovery of these actors. Shard-id and entity-id from the incoming message is used to determine which sharded actor this message should be sent.
- From the above diagram, the message with entity-id john always get routed to entity-actor called John. The shard-id from the message is first used to determine which akka node the message should be send and secondly the entity-id from the message is used to find which entity-actor within that akka node the message should be further routed. Shard-Region & Shard-Coordinator actors provided by AKKA framework helps to facilitate this process.
- The entity-actors such as John is fronted with a shard actor and shard actor belongs to a Shard Region. Communication with Shard Region is performed via Shard Coordinator. Read cluster sharding documentation for complete details.
- The sharded-entity actor gets created using shard-id and an entity-id of the incoming message. The Message interface in the akka-initializer library defines a contract that enforces the messages send through the system has a mandatory entity-id field and an optional shard-Id
- If Shard-Id is not present, akka-initializer library derives it from the entity-id of the message using a stable algorithm. This mechanism is present in DefaultMessageExtractor class. This class expects an externally defined property in YAML called akka.initializer.number.of.shards. Make sure this value is equivalent to the number of nodes in AKKA cluster times 10. For more details refer to java doc on DefaultMessageExtractor.maxNumberOfShards. Also, refer to the Javadoc on Message interface and DefaultMessage class.
- Instead of using the provide DefaultMessageExtractor in the framework. Users can plug-in a shard extractor of their choice by providing a spring bean implementation (@Component annotated) class that implements the following AKKA interface akka.cluster.sharding.ShardRegion.MessageExtractor. Make sure the annotated class is available in the class-path. Refer to Javadoc on class ShardRegionInitializer for details
- Entity-id is the Aggregate id and is used within the shard to determine the actual Aggregate to which the message needs to be end.
- The shards should be configured under a shard region and shard regions should be started on application start-up. During the start-up, the sharded actors can be optionally supplied with initialization parameters through a YAML file. Akka-initializer library makes these steps easier. To see a sample of how to specify a shard region and initialization parameters for a sharded actor, refer to src/test/resources/application.yaml and also refer classes ShardRegionInitializer, ClusterShardsConfig, AkkaManager and IncarnationMessage
- On failure of a node, AKKA restarts the shard region and automatically migrates the sharded-entity actors within that shard region to one of the available nodes.
- AKKA clustering can suffer from split brain issues. Refer to Additional notes section for resources to deal with this scenario.
Akka-initializer makes it easy to create AKKA persistence actors. This section provides a high-level overview of how AKKA persistence works and how framework makes it easy to use AKKA persistence. The framework also comes with few other features such as aggregate time-to-live and aggregate state’s message expiry. This section explains provides details on such features. Refer to these diagrams below as you read through this section.
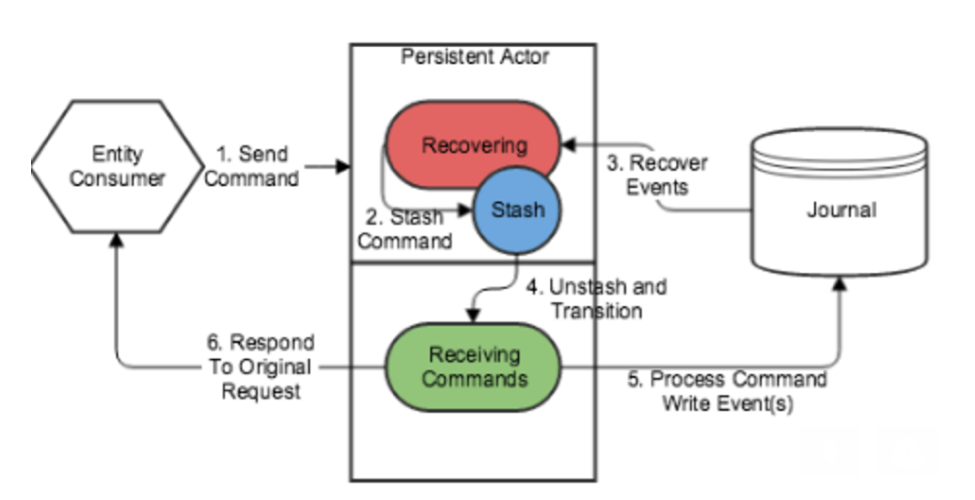
- AKKA persistence module makes it easy to implement event/command sourcing. So, when a node fails the state of the actor gets automatically recreated on one of the available nodes.
- The akka-initializer library makes all the above setup easier. Refer to Javadoc on akka.initializer.PersistenceActor for details: this is the base class Aggregate need to extend.
- Akka-initializer library makes it easy to use in-memory persistence store to make unit testing easier. For production scenario, a durable distrusted persistence storage such as Cassandra should be used.
- As the time progress, the cluster sharded persistence actor might itself needs to be terminated. The akka-initializer library comes with such features and can be achieved by implementing an interface called TimeToLive. For a detailed example on how to use this feature refer to Note2 at the end under Additional Notes section.
- As the time progresses, the older messages/data in the cluster sharded persistence actor instance state should be expired. From the user‘s point of view, they need to implement two interfaces. The cluster sharded persistence actor should implement MessageExpiry interface and the class that holds the state for the actor should implement MessageExpiryListener interface. The details of how framework uses these interfaces and inner working are explained below.
- MessageExpiry: This interface returns two objects: Message-expiry-time and MessageExpiryListener. Message-expiry-time (usually configured in a YAMLfile as part of cluster sharded actor start-up parameter, for e.g. refer src/test/resources/application.yaml) is the time frequency at which framework calls methods on the MessageExpiryListener to expire the older messages.
- MessageExpiryListener interface has further two methods expirySequenceNumber(timeWindow) and this should return the highest sequence number in the state objects for the provided time window, all the messages beyond this highest sequence number will be automatically expired by the akka-initializer library as explained here: Once akka-initializer library gets the highest sequence number, it will transparently delete the message from the persistence store (such as Cassandra) up to this sequence number asynchronously and once that is done it then calls cleanUp(…) method on MessageExpiryListener and pass the sequence number. At this point, it is the responsibility of the MessageExpiryListener implementing class to clean-up the message from its in-memory state. MessageExpiryListener provides a list of JDK 1.8 style default interface methods that help to clean-up data from a List, Set or Map type data-store. For a detailed example how this can be done refer to Note1 at the end under Additional Notes section. Also, refer to classes in the test package MessageExpiryDetector and MessageExpiryState.
During unit testing, there are needs to assert the messages in a predictable way. The akka-initializer library provides ResponseHandlerActor class that makes the unit and integration testing easier. Akka-initializer library also comes with an in-memory persistence storage to make the unit testing easier.
As stated, the later part of the article showcase how to implement a banking domain CEP use case by using the akka-initializer library. AnomalyPublisher interface and the associated classes inside these classes make the implementation of CEP use case easier. ObservableAnomalyPublisher is another class that makes writing CEP test cases easier. For an example on how to use this class visit SampleAnomalyCancelTest under src/test
Spring support: The library integrates well with spring framework 4.X+ so that logic can be implemented using spring framework. Refer to SpringActorProducer & SpringExtension
Banking Domain Complex Event Processing (CEP) Use Case
Let us take a look at the below sample CEP use case from a banking domain, the complete code is here. The use-case monitors the credit card & banking transactions for each customer. The anomaly detector checks for the following anomaly condition: For a customer, when there is Security risk event (represented using GenericEvent) followed by 2 credit-card transaction events of “Credit” type followed by 3 banking “Withdraw” transaction event type in the last 10 seconds, then a fraud anomaly should be generated.
We want to make use of the features from the akka-initializer library and implement a highly scalable, resilient CEP solution for this use-case that can scale to millions of users and runs on several JVM (AKKA cluster nodes). This section showcases how all the heavy lifting is taken care by the akka-initializer library and developer can focus on to business functionality. Below is a high-level design.
- The first step is to apply domain driven design principles and identify the Aggregate root. These Aggregate roots will be represented as a cluster-sharded persistence actor using the akka-initializer library. Let us choose the Customer Account actor as the aggregate root and account name acts as the actor id. (In real life use case customer account number or a GUID are better keys for an aggregate. https://vaughnvernon.co/?p=838 )
- Identify the expected stream of events for the alert: The events in our case are (a) Banking transaction events, (b) Credit card transaction events and (c) Security (Generic) events. The stream of events would be JSON messages.
- The next step is to configure set of business rules that should be applied against the stream of events. These rules will be configured inside the above Aggregate root actor. Esper is an excellent open source framework that works well to implement CEP use cases. More on Esper later
- Attach a listener within the Aggregate actor that gets fired when rule conditions are met.
- For this sample scenario the listener prints out the alerts on the console.
- Once all this is setup, then data can be streamed into the engine and watch for anomalies. We will showcase a spring based REST end-point to fire of events. Kafka would be a great choice to stream real-time events.
- For resiliency needs, the data streamed into the Aggregate needs to be command or event sources into a highly durable distributed storage. Cassandra (more on this later) is an excellent distributed storage for this purpose. Akka-initializer library comes with an in-memory persistence storage and that is only good for unit testing.
- For every unique customer, the framework would create a new instance of the Aggregate root to represent that customer and all the events related to that customer are streamed to that instance.
Esper Explained
Esper is an open source engine and can be directly embedded in JVM or can be used within the .NET runtime. Esper can be used to perform complex decision making on a single stream or multiple streams of data. Esper is a lightweight Java-based engine; it can be configured from java or Junit test code directly. Esper comes with a sophisticated EPL (Esper processing language) that can be used to configure the rules. It supports: sophisticated time/batch/length/accumulating/tumbling/sliding windowing functionalities over the stream of data, allows merging desperate streams, allows merging with an external data source, sub-queries, joins, splitting of streams, auditing, allows you to detect the absence of events and many more rich functionalities. Refer to Esper’s excellent documentation for details.
DataStax Cassandra Installation
- Download and install DataStax Cassandra.
- The version used or windows is 64-bit community version v3.0.9
- The version used for Mac is 3.9.0
- Start DataStax Cassandra service. The default port is 9042.
- On Mac go to the data-stax download folder and run the following command ~ /datastax-ddc-3.9.0$ ./bin/Cassandra
- On windows, it can be installed as a service and stopped and restart the service as needed. When installing make sure you don’t alter the installation path, if you do so there are possibilities that if you stop Cassandra service and restart it might not come up correctly. The reason being sometimes the log files Cassandra writes gets written under the standard path and it looks for such log during restart and if not present it does not start. One way to check if Cassandra is coming up ok and the reason for failure is by running, for Windows: C:\Program Files\DataStax Community\apache-cassandra\bin\cassandra.bat on command prompt and look for any errors.
- Access CQL prompt to make sure can connect to the Cassandra server.
- On Mac go to the data-stax download folder and run the following command ~ /datastax-ddc-3.9.0$ ./bin/cqlsh
- On windows run the bin\cqlsh.bat from a command prompt.
Banking CEP Use Case Implementation Using Akka-initializer
This project provides an anomaly/problem detector implementation example that makes use of the core library. The example is built for a fictitious banking domain use case explained earlier. The project makes use of Esper library for anomaly detection logic. The project is called cep-banking-use-case and it can be found to clone at https://github.com/ajmalbabu/distributed-computing/tree/master/cep-banking-master
Interface Definition
All the below interface is available as a Postman collection under the above GitHub root, The examples can be imported as postman verion1 or 2 and the examples are tried out using version2.
Customer credit card transaction event submitted via Http post as shown below is the first type of event. Customer first name is chosen as the identifier for the message (In practice customer id could be a better key). CustomerTransactionEvent.java is the corresponding POJO for this JSON
URL:
http://127.0.0.1:8082/cep-api/v1/customerTransactionEvent
HTTP POST JSON Payload:
The customer bank withdraw transaction event submitted via Http post as shown below is the second type of event. Customer first name is the identifier for the message. CustomerTransactionEvent.java is the corresponding POJO for this JSON
URL:
http://127.0.0.1:8082/cep-api/v1/customerTransactionEvent
HTTP POST JSON Payload:
Another event of interest is Global security event as shown below posted to the URL, note that the URL has a url-parameter that specifies to which aggregate (Peter) this event is targeted. GenericEvent.java is the corresponding POJO for this JSON. Note: Consider to use AKKA distributed data http://doc.akka.io/docs/akka/2.4.17/scala/distributed-data.html if you want to target global events to all aggregates.
URL:
http://127.0.0.1:8082/cep-api/v1/genericEvent?
HTTP POST JSON Payload:
When these events occur in the following fashion a global security event followed by 2 credit-card transaction events of credit subtype followed by three banking withdrawal transaction event sub type in the last 10 seconds. The system should generate an anomaly.
System Detailed Design
The rest end-points that accepts the incoming events are: BankTransactionRestApi.java
The anomaly detector (Aggregate) that detects anomaly for bank and credit card transaction is named BankAndCreditCardAnomalyDetector.java
- This is a cluster-sharded-persistence actor, a unique instance of an actor gets created for each unique customer (customer name is the id in this example and we are using Peter as the customer in this example throughout).
- The Aggregate actor accepts all the incoming events for a specific customer. Note: If a new customer (e.g. a new event for customer name Jon) event occurs then a new actor in one of the available nodes in the cluster gets created to manage that customer’s event.
- Command sourcing is good enough in this scenario to store the incoming events for a failover scenario. Note: This example does not need any enriched data from the incoming events or collected from other external sources. So the incoming command does not get enriched and converted to an event, hence event sourcing is not needed. In some other cases, event sourcing may be needed.
- BankAndCreditCardAnomalyDetector.java should be configured with Esper engine and register the type of events that this actor expects. This is done inside the BankAndCreditCardExpectedEventDefinition.java class. There are three events that this actor configured (a) credit card transaction event, (b) bank withdraw transaction, and (c) Global security event. These events are sent directly to the instance of this actor from the REST endpoint. The actor stores all these events in its local internal state in a class called BankAndCreditCardTransactionState.java. Note: Instead of sending global events to each instance of the customer actor (such as “Peter”, “Jon” etc.) a better approach is to make such global events available to all actors via AKKA distributed data http://doc.akka.io/docs/akka/2.4.17/scala/distributed-data.html
- BankAndCreditCardRuleAuthor.java is the class where the esper specific rules are defined, this class applied the rule across the incoming events and trigger anomaly when conditions are met
- BankAndCreditCardRuleListener.java gets notified when a rule condition is met and this class can notify other external systems etc.
- BankAndCreditCardAnomalyDetector actor command sources the messages appear into it, store them in its internal state object and passes over the events to Esper engine to check for anomalies.
- BankAndCreditCardAnomalyDetector should be configured under a shard region. It is done in the cep-banking-configuration/application.yaml file under element akka.initializer.cluster.shards.config.clusterShardList
- The above shard automatically gets started by the system (refer to akka-initializer library behavior) and the REST endpoint accesses the BankAndCreditCardAnomalyDetector via the shard region.
- The shard-Id of the message should be carefully created (Refer for section 3.1 earlier for details)
- Let us say an Esper rule got fired and listener notifies the external system of the events. At this point say if the node on which rule gets fired fails, then the system automatically restarts the actor on another node and replays all the events. This failover can trigger a duplicate rule condition match scenario and can lead to the firing of a duplicate anomaly. To avoid any such duplicate, each time an anomaly is generated add the anomaly to the internal state BankAndCreditCardTransactionState as well. And check for the presence of the anomaly on a replay of events to avoid sending of duplicate anomalies. This feature is not implemented in the example.
Local Development Testing
- Start the Cassandra data-stax service on default port 9042.
- Export akka-initializer-master and perform a mvn clean install to install the akka-initializer library into maven local repository.
- Export the maven project from cep-banking-master
- Start the spring boot Application.java by providing the following JVM arguments (adjust according to the local)
- On Windows: -Xbootclasspath/p:C:\workspace\distributed-computing\cep-banking-master\cep-banking-configuration -Dspring.profiles.active=local
- On Mac: -Xbootclasspath/p:/software/workspace/distributed-computing/cep-banking-master/cep-banking-configuration -Dspring.profiles.active=local
- The sample file Cep-bank-messages.postman_collection-v2.json has the sample messages, import this collection into postman.
- Open postman and within 10 seconds POST a Generic event first and then send 2 Credit event followed by 3 Bank withdraw events the log should show anomaly is being generated. The HTTP POST URL and JSON content is listed in the early part of the documentation.
- Refer to The cep-banking-master/README.md file for tips on how to clean-up the event sourced data from Cassandra key-space in between running.
Unit Testing
- The default spring boot behavior is to look for a Cassandra instance up and running since it sees the Cassandra driver in the class-path and tries to eagerly bring up Cassandra session class. This is not good for unit testing, so for unit testing classes in this package com.cep.bank.service.common helps to bring up a fake Cassandra session when Cassandra is not running. To make this fake session active a spring profile called isolate should be active and it is set to active in the test/application.yaml. Basically, all this will make the unit testing working without having a Cassandra instance running transparently for the user.
- The framework comes with features and classes to make a unit test of the end-to-end CEP detection logic easier.
- Unit test code can fire of a spring container and can create Aggregate cluster shard persistence actors. These actors live in the unit test JVM instance. The event sourced messages are stored in the JVM memory.
- Refer to BankAnomalyServiceTest that show-case the previous anomaly detection scenario completely tested within junit test code and asserts the response.
- There is a class in the akka-initializer library called ResponseMessage that help to tap the response message send back by the Aggregates.
- There is a class in the akka-initializer library called ObservableAnomalyPublisher that can be injected into the Aggregate so that any anomaly published by the Aggregate goes into the above ObservableAnomalyPublisher. And the anomalies can be captured and asserted in the test case.
Final Thoughts
The provided akka-initializer library eases out the implementation of large scale highly scalable solutions. The akka-initializer library can be used to build microservices, and other complex distributed systems. The later part of article showcases how to use the akka-initializer library to implement a high scale CEP use-case.
Additional Notes
Note 1: There is a message expiry feature to expire the message within Aggregates, refer to akka-initializer library class MessageExpiryTest for a detailed example on how to implement this feature.
Note 2: There is ab TimeToLive interface that helps to remove an Aggregate automatically when it reaches a specified time. Refer to akka-initializer library class ActorTimeToLiveTest & ActorRecoveryTest for a detailed example on how to implement this feature
Note 3: Esper has a concept called Context Partition that can be used to partition the data and it works well to partition the data within a single JVM.
Note 4: Use split brain resolver when using AKKA clustering to avoid split brains and to have a predictable cluster partitioning behavior. Few useful links
Note 5: Consider Zipkin and Spring sleuth for distributed tracing.
Note 6: Currently objects are made serializable using java Serializable; change it to use proto-buf
Note 7: The above core akka-initializer library can be used for other micro service development needs. CEP is one of the implementations that fits nicely into the framework.
Note 8: BankAndCreditCardRuleAuthor class creates EPL statement and each entity actor creates such statement. There are opportunities to optimize the creation of statement so that there is only single statement per JVM, follow Esper documentation for best practices on this.
Note 9: To run the banking example as an AKKA cluster: For each cluster node, update the hostname and port number in the cep-banking-configration/cep.akka.conf file cluster accordingly.
Note 10: The complete source code used for the the article can be found here
Scalable, Distributed Systems Using Akka, Spring Boot, DDD, and Java--转
标签:ast mailbox base tps html back www. optimize product
原文地址:http://www.cnblogs.com/davidwang456/p/7357158.html