标签:创建 orm pycha 全局 write truncate 计数 输入参数 4.0
集合{ } set 无序 元素不可重复
用set可以将 列表 转化为 集合

求 1和2都有的那部分
可以用符号 & b = t & s
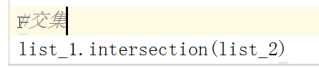
输出如下
4,6
并集
将1和2去重合并到一起
可以用符号 | a = t | s

输出如下
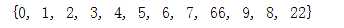
差集
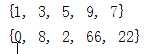
求1有但是2没有的那部分 就是集合1剪去都有的那部分
可以用符号 - c = t – s

输出
子集,父集
求3是否是1的子集 issubset() 返回布尔
求1部否是3的父集 issuperset()返回布尔

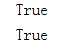
对称差集
相当于1和2合并之后,减去他们的交集
符号 ^ d = t ^ s

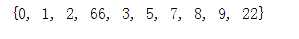
判断是否有交集,返回True 和 False

输出如下
False
添加
基本操作:
t.add(‘x‘) # 添加一项
s.update([10,37,42]) # 在s中添加多项
删除
使用remove()和discard()都可以删除指定项:
#如果删除项不存在,报错
t.remove(‘H‘)
#如果删除项不存在不会报错
t.discard(“ H”)
随机删除 任意一个元素
返回值是删除的这个元素
被删除的元素=List_1.pop()
集合的长度
len(s)
判断元素是否存在于集合中 字典,集合,字符串 都是此种写法
x in s
测试 x 是否是 s 的成员
x not in s
测试 x 是否不是 s 的成员
复制
返回 set “s”的一个浅复制
s.copy()
文件操作
#创建文件句柄 (得到文件在内存中的对象)
f=open("fiietext.txt","r".encode("utf-8"))
“r”是操作文件的模式 代表 只读
“r+” 代表 读 追加写入 最常用
“w” 代表写入 会覆盖原有文件
“a” 代表追加写入
“rb” 代表 用二进制的格式读取 还有“wb“ “ ab“ 等
f=open("fiietext.txt","rb")
读取一行
f.readline()
将文件内容 转化成列表 每行代表一个元素
f.readlines()
内容循环
高级写法:
每次读取一行,但读完一行就释放掉内存,效率更高
for i in f:
print(i)
如果循环到第9行处理。加个计数器就行
小文件使用:
先转化为列表
大文件会撑爆内存,因为会先把文件内容都读到内存,然后再转化成列
按行循环
#将文件转化成列表,然后按照列表的方式循环
for i in f.readlines():
#strip()去掉两边的空格和回车,字符串的方法
print(i,strip())
循环到第9行时跳过 还是列表中的方法

得到文件句柄 当前的指针 位置
f.tell()
设置文件句柄 指针的位置 设置到0代表,从开头开始操作
f.seek(0)
得到按什么字符集读取的
f.encoding
得到文件名称
f.name
判断是否是tty设备 如:打印机 在写底层代码的时候可能会用 返回布尔
f.isatty()
判断指针是否可操作 返回布尔
f.seekable()
判断文件是否可读 返回布尔
f.readable()
判断文件是否可写 返回布尔
f.writable()
强制刷新
因为磁盘的速度很慢,所以是先写到内存,当达到一定阈值的时候,再一起写入磁盘。当业务,对数据的实时性要求比较强的时候,例如银行业务,存钱进账。 就使用此方法。
立刻把内存中的数据,写入到磁盘。
f.flush()

截取字符 不写参数会清空文件 写10代表, 保留从文件开始到第10个字符的内容。如果设置指针的位置不会有用。他还是从头开时截取
f.truncate()
f.truncate(10)
判断文件是否关闭了 返回布尔
f.closed()
关闭对文件的操作
f.close()
文件修改
方法一:
准备打开两个文件
一个是原文件,一个是修改后的文件,使用迭代器,省内存。
f=open("t1","r",encoding="utf=8")
f2=open("t1_new","w",encoding="utf=8")
for line in f :
if "我在w" in line :
line=line.replace("我","大锤")
f2.write(line)
f.close()
f2.close()
方法二:
在原文件进行修改 使用权限r+
还是先把内容转列表加载到内存,费内存
好处是不用改文件名字了,只写入修改的文字
f3=open("t1","r+",encoding="utf=8")
list1=f3.readlines()
#在把文件转成列表之后,指针在最后的位置了,要把指针设置到文件开始位置
f3.seek(0)
for i in list1 :
line_new=i.replace("我","wang大锤")
f3.write(line_new)
f3.close()
高级close
同时打开多个文件,避免close忘掉关闭
f=open("yesterday2","r",encoding="utf=8")
f2=open("yesterday2","w",encoding="utf=8")
下面是高级写法

文件改名
import os
os.rename("原文件名","新文件名")
字符编码
ASCII 英文1个字节 没有中文
Utf-8 中文3个字节
英文1个字节 采用ASCII的
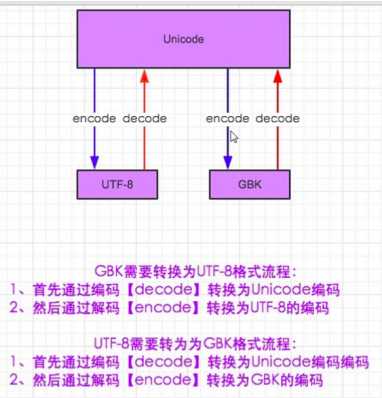
Pyrhon2不支持中文,需要在文件开头加入

S.decode(“之前的编码格式”).encode(“转成的编码格式”)

Utf-8是Unicode的扩展集 可以不用转化
Gbk和Unicode 需要转换
打印默认的字符集
import sys
print(sys.getdefaultencoding())
注意:gbk在转成utf-8后,需要当前的读取环境也是utf-8的,不然还是乱码。
反之utf-8转成gbk也一样
在python3中,encode的时候,会把字符串转成 byte类型的,读取需要再次转成字符串。
byte类型 前面有个b
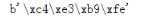
Pychaem改编码的地方 这里改的是编码格式
函数
函数

过程 也叫做没有返回值的函数

打印时间

return 返回值 并结束程序
没有返回值 默认返回None
一个返回值 返回给的值
多个返回值 返回一个元组 如下图:

输出如下:
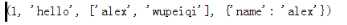
默认参数
y参数可有可无 不输入则是默认值 2

输出 1,2
参数组 输入参数的个数不固定时使用
输入多个位置参数会被当做元组输入进去
写法 形参名前加个* 可以和其他参数结合 默认参数 位置参数等 他需要

输出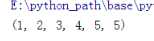
把N个关键字参数,转换成字典的方式
写法 形参名前加个** 可以和其他参数结合 默认参数 位置参数等

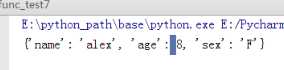
局部变量
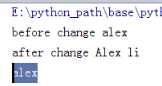
在函数里定义,只在函数里生效, 如name 虽然在函数里name=Alex li但输出的还是小写

输出如图
全局变量
在最外层的上方定义 在整个程序都生效
如:在最上方定义 shool=Oldboy edu虽然在函数里改了值,但值依然是初始 设定的那个
如果要改全局变量的值
1.不在函数里修改
2.在函数里 添加 global school 如下图 不建议用,容易发生逻辑混乱
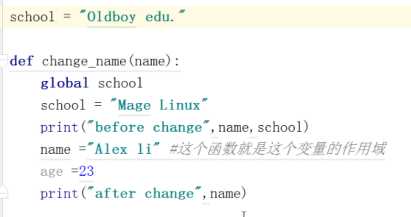
在外边没有全局变量,在里边声明使用 global 定义全局变量
非常不建议使用 实在不行就用上一种,先在外边定义。代码规范。

只有字符串和数字 不能在函数里修改
列表,字典,集合,类 都可以在函数里修改
递归 再返回时调用自身 最大深度999层
特点:必须有结束条件
问题规模逐渐变小
层次过多 会导致内存溢出

函数式编程
和python的函数没关系,指的是数学里的函数
输入是确定的 输出就是确定的
Python是一门全面向对象的语言,只有一部分支持函数式编程
高阶函数
把函数当做参数 传给 另一个函数
输出如下:
标签:创建 orm pycha 全局 write truncate 计数 输入参数 4.0
原文地址:http://www.cnblogs.com/HL-blog/p/7362359.html