标签:检查 nbsp inf 相同 enc ase growth 更新问题 3.2
(参考文献来自An Efficient Approach for Maintaining Association Rules based on Adjusting FP-tree Structure
Jia-Ling Koh and Shui-Feng Shieh Department of Information and Computer Education
其中有大量的删减,如果想直奔主题,看干货,可直接从3、调整FP_tree的策略 开始看起@OUYM)
1、Introduction
数据挖掘在数据库研究中引起了广泛的关注,因为它在许多领域中有着广泛应用。 在各种数据挖掘应用中,客户交易中的挖掘关联规则是重要的。客户交易记录通常由客户ID,交易时间和交易中购买的所有项目组成。这种数据库的挖掘关联规则是找出所有的规则,如“购买项目X和Y的客户中有n%的人在同一交易中也购买项目Z”,其中n,X,Y,Z最初是未知的。 这样的规则对于定制营销的决策是有用的。
已经提出了几种有效的算法用于寻找频繁项集,并且关联规则是从频繁项集推导出来的,如Apriori和DHP算法。这些“类Apriori”的算法受到(1)处理大量候选集(2)重复扫描数据库的限制。 韩家炜提出了一种频繁模式树(FP-tree)结构,用于存储关于频繁模式压缩结构和关键信息。此外,开发了一种称为FP-Growth的算法,用于从FP-tree中挖掘完整的频繁项集。这种方法避免了大量的候选集的产生和重复的数据库扫描的代价,这被认为是挖掘频繁项集的最有效的策略。
事务数据库的更新可能会使现有规则无效或引入新规则。更新“关联规则”以便更快的在更新的数据库中找到新的频繁项集集合。更新关联规则的一个简单的解决方案是重新挖掘整个更新的数据库。然而,这种方法的无效性(或者说效率底下)是显而易见的,因为在以前的挖掘中完成的所有计算都是浪费的。有人研究了如何者保留先前发现的关联规则,并在此基础上更新新的关联规则,提出了在添加新的事务数据时增加更新关联规则的FUP算法。为了解决一般情况的问题,包括数据库中事务的插入,删除和修改,FUP算法被修改并开发出FUP2算法。还有人提出了一种类似于FUP算法的增量更新技术,用于挖掘多层次关联规则。作为“类Apriori“的算法,所有FUP系列都必须产生大量的候选,并反复扫描数据库。
除了频繁项目集之外,有人提出的增量更新技术还保留了附加信息。有人提出了一种增量挖掘算法,用于寻找频繁的序列模式。在该算法中保留了前序列,其是具有较低支持阈值和上限阈值之间的支持的序列。需要从重新扫描原始数据库时确定的下限阈值和上限阈值派生的绑定。在另一个算法中,负边界与频繁项集保持一致。 如果将负边界外的项目集添加到频繁项集或其负边界,则该算法需要对整个数据库进行全面扫描。
在本文中,我们提出一种称为AFPIM(增量挖掘调整FP-tree)的算法,以便事务数据库在添加,删除或修改新事务时,以最小的计算量来有效地查找新的频繁项集。 在我们的方法中,原始数据库的FP-tree结构除了频繁项目集之外都被维护。 在大多数情况下,不需要重新扫描整个数据库,通过根据插入和删除的事务调整之前的FP-tree来获得更新的数据库的FP-tree结构。 然后从新的FP-tree结构中挖掘更新数据库的频繁项集,并发现相应的关联规则。
2、Problem Dwscription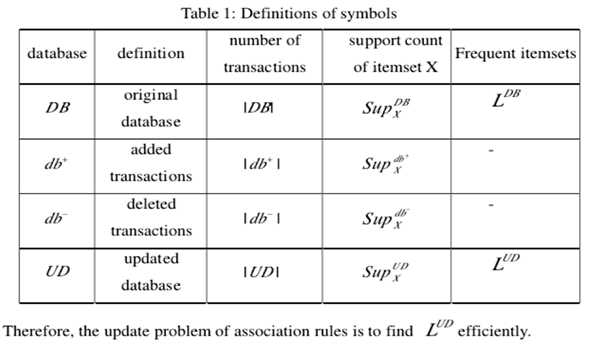
基本概念:
在本文中,应用了“前序列“(pre-large sequences)的概念。除了最小支持阈值之外,还指定了一个较小的阈值,称为”预最低支持“(pre-minimum support)。对于数据库中的每个项目X,如果其支持计数不小于最小支持,则将X命名为频繁项。如果X的支持次数小于最小支持,并且不低于”预最低支持“,则X称为“预先频繁项”。否则,X是非频繁的项目。在以下情况下,频繁项目和预先频繁项目被命名为“频繁或预先频繁项”。
为了有效解决更新问题,我们在挖掘原始数据库DB后维护以下信息。
1.数据库中的所有项目以及数据库中的支持计数。
2.数据库的FP树,根据DB中的频繁或预先频繁的项目构建。
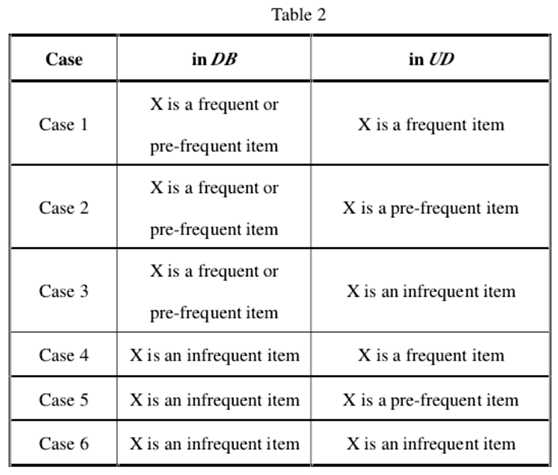
DB中的项目X是频繁的,预先频繁(pre-frequent)或在频繁(in-frequents)的项目,它们将成为UD中的频繁,预先频繁或在频繁的项目。
3、调整FP_tree的策略:
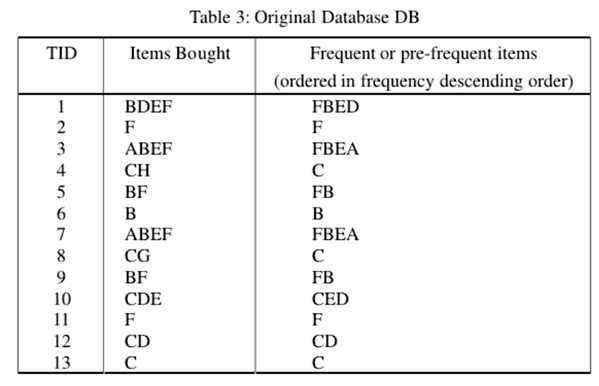
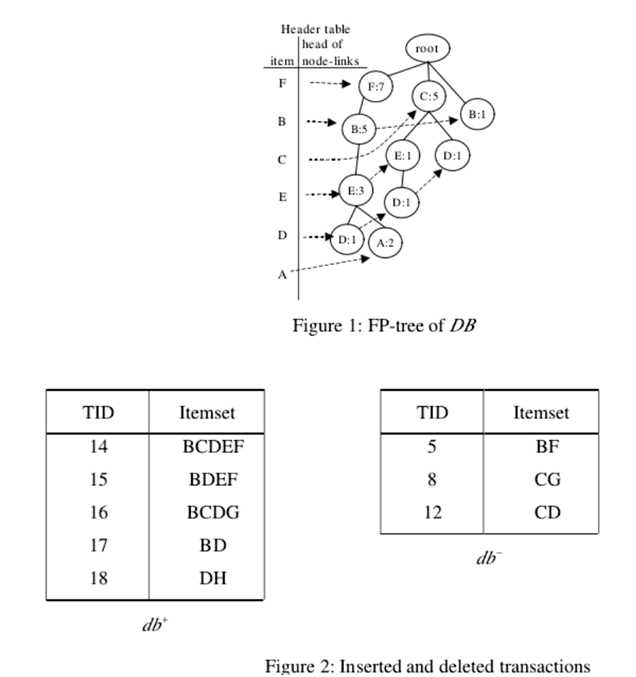
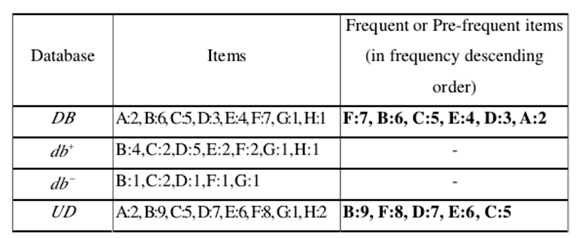
原始数据库DB。 最小支持为0.2,预先最小支持(pre-minimum support)为0.15。A:2,B:6,C:5,D:3,E:4,F:7,G:1和H:1(:表示支持计数)。支持的项目不小于2(即13×0.15 = 1.95)是DB中的频繁或预先频繁的项目。 因此,A,B,C,D,E和F是DB中的频繁项。 在按顺序排列所有频繁或预先频繁的项目后,结果为F:7,B:6,C:5,E:4,D:3和A:2。然后插入5个事务,并从DB中删除3个事务。db +和db-中的所有项目的支持计数都在上面。对于UD中的每个项目X,支持数可以通过简单的计算获得。 结果是A:2,B:9,C:5,D:7,E:6,F:8,G:1和H:2。在新数据库UD中,预先频繁或频繁的项目必须具有不少于3的支持计数。因此,以频率递减顺序显示的UD中频繁或频繁的1项集是B:9,F:8,D:7,E:6和C:5。
删除非频繁节点:
假设项目I在UD中非频繁,表示I的节点必须从FP树中删除。 从项目I开始,在FP-tree头部和跟随I节点链接之后,可以逐个获得表示I的所有节点。 对于每个节点N,使得N.item-name = I,将其子节点设置为其父节点的子节点,并从I节点链路中删除N。 最后,删除标题表中的I条目。A在UD中不是频繁的或预先频繁的项目。 因此,表示A的节点从FP树中移除。
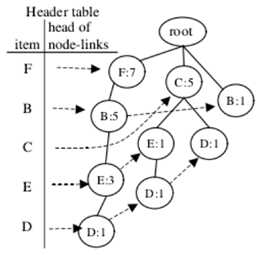

DB中支持数降序的频繁或预先频繁项目的列表,应用冒泡排序算法来确定在UD中满足相邻项目的支持降序的交换方式。 如上图所示,需要进行4次交换,以调整DB中的支持降序以符合UD中的顺序。 在决定要交换的项目对之后,在DB的FP-tree中,必须调整包含一对交换项目的路径。 调整方法如下所述。假设在DB的FP-tree中存在路径,其中节点Y是节点X的子节点,并且必须交换节点X和Y中表示的项目。
另外,节点P是X的父节点。如果X.count大于Y.count,执行步骤1到3。 否则,执行步骤2到3。
【步骤1】插入: 插入节点P的子节点X‘,其中X‘.count设置为X.count
- Y.count。 X除了节点Y的所有子节点都被分配为X‘的子节点。 另外,X.count被重置为等于Y.count。
【步骤2】交换:分别交换节点X和节点Y的父链接和子链路。
【步骤3】合并:检查是否存在P节点,表示为节点Z,Z.item-name = Y.item-name。 如果节点Z存在,则将Z.count相加到Y.count中,并且删除节点Z。
第一次迭代调整:项目F和B的交换节点
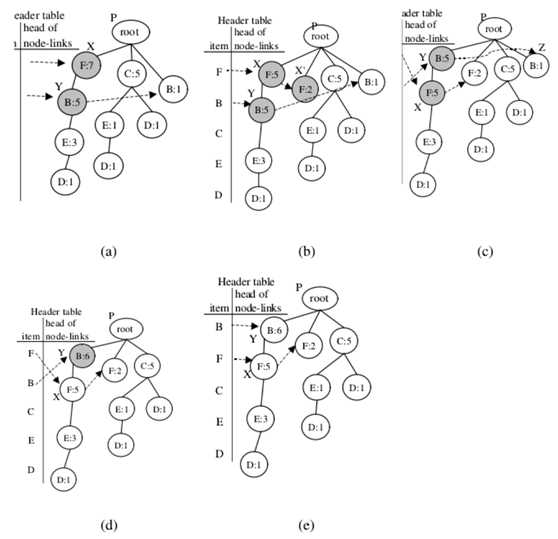
从FP-tree的头表中,可以获得项目F的节点链接。先来把携带项目名称F的节点被表示为节点X,存在X的子节点Y,使得名称为B。因此,执行调整方法。
(1)插入:对于X的父节点,在这种情况下,根节点插入一个子节点
节点X‘携带项目名称F. X‘的计数字段分配为2,(即7-5)。此外,X.count被重新分配为等于Y.count,5。最后,将X‘插入到F的节点链接中。
(2)交换:交换节点X和节点Y。
(3)合并:存在根节点的另一个子节点Z,使得“Z”携带与”Y”相同的项目名称B。因此,在节点中的计数值Z被合并到节点Y中,Z被去除。
得到携带项目名称F的下一个节点。但是,该节点没有名称为B的子节点,因此已到达项目F的节点链接的终端,这个迭代是完整的;
第二次调整迭代:项目C和E的交换节点
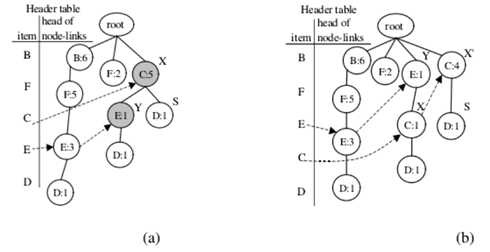
与第一次迭代的过程类似,携带项目名称C的第一个节点是表示为节点X,并且发现其携带项目名称E的子节点Y。
然后进行调整方法。 在这种情况下,节点X除节点Y之外还有另一个子节点S.因此,节点S被分配为新添加的节点X‘的子节点;
第三次调整:项目C和D的交换节点:
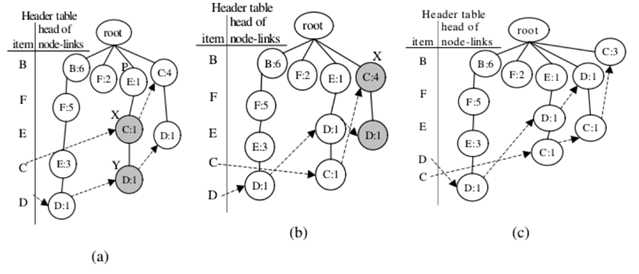
携带项目名称C的第一个节点及其子节点携带项目名称D.,分别表示为节点X和Y在这种情况下,X.count等于Y.count。 因此,只有步骤2和步骤3进行调整方法。下一组项目C和D的节点,表示为节点X和Y执行调整方法并进行交换标题表中项目F和B的条目;
第四次迭代调整:项目E和D的交换节点。
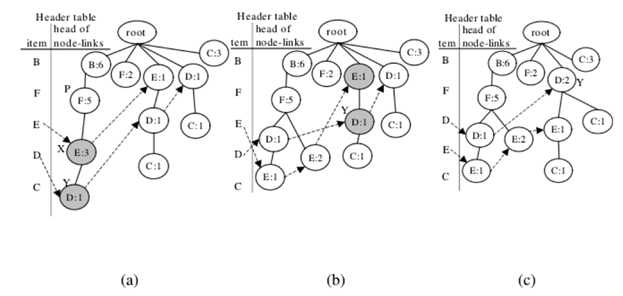
4、插入或者删除数据:
在FP-tree里面调整节点的路径后,所得FP-tree中的每个路径都遵循UD中频繁或前缀频繁项的频率降序。 对于db +中的每个事务T,选择T中包含的UD的频繁或预先频繁的项目,并按降序排序。 事务T将被插入到FP-tree中作为构建FP-tree的过程。 同样,每个事务T在db-从FP树中删除。
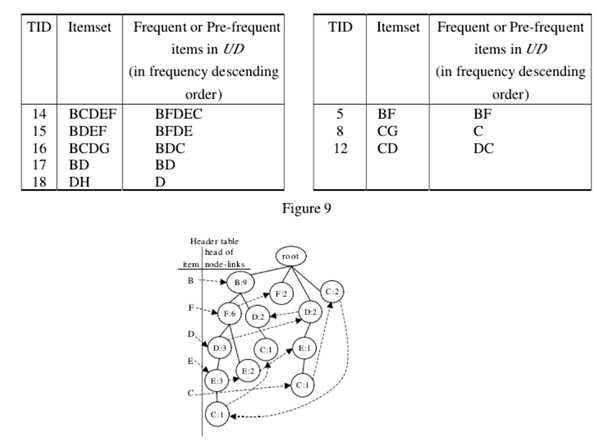
5、AFPIM算法:
基于上述描述的策略,我们有以下AFPIM算法调整增量挖掘频繁项集的FP-tree结构。
【步骤1】阅读DB中的项目及其DB中的支持计数。
【步骤2】扫描数据库db+和db- 一次,分别列出在db+和db-所有项目及其支持数。对于每个项目X,计算UD中的X的支持计数根据公式:
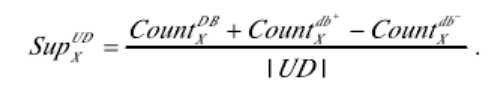
然后在UD中收集频繁或预先频繁的项目。
【步骤3】判断是否所有的UD频繁项目是否都在DB的FP-tree中覆盖。
【步骤3.1】如果在FP-tree中存在UD的频繁项目,则整个UD需要要扫描一次,以便根据频繁重建UD的FP树或UD中的前缀项目。
【步骤3.2】否则,读入存储的数据库的FP-tree。
【步骤3.2.1】对于UD中的每个不频繁的项目,从中删除相应的节点FP树。
【步骤3.2.2】根据DB和UD中的支持数降序的排列顺序,应用冒泡排序算法来交换项目顺序。然后重复使用路径调整方法来调整结构FP-tree中的路径。
【步骤3.2.3】扫描数据库db+ 和db- 第二次,调用函数tree_insert_delete插入事务db+和删除事务db- 。最后,得到了所得到的UD的FP树。
【步骤4】应用FP-Growth算法和TD-FP-Growth算法分别从UD的FP树中找出UD中的频繁项集
伪代码:

标签:检查 nbsp inf 相同 enc ase growth 更新问题 3.2
原文地址:http://www.cnblogs.com/zhaoby451/p/7365917.html