标签:地方 start other 子进程 存在 text config ict 析构
XML是可扩展标记语言(Extensible Markup Language)的缩写,其中的 标记(markup)是关键部分。您可以创建内容,然后使用限定标记标记它,从而使每个单词、短语或块成为可识别、可分类的信息。
‘‘‘
XML是不同语言或程序之间进行数据交换的协议 ‘‘‘ #利用ElementTree.XML将字符串解析成xml对象 from xml.etree import ElementTree as ET # 打开文件,读取XML内容 str_xml = open(‘test.xml‘, ‘r‘).read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root = ET.XML(str_xml) #利用ElementTree.parse将文件直接解析成xml对象 from xml.etree import ElementTree as ET # 直接解析xml文件 tree = ET.parse("test.xml") # 获取xml文件的根节点 root = tree.getroot() print(root) print(root.tag) #获取根节点的标签名 print(root.attrib) #获取根节点的属性 #makeelement(self, tag, attrib) 创建一个新节点 #append(self, subelement) 当前节点追加一个子节点 extend(self, elements) 为当前节点扩展 n 个子节点 insert(self, index, subelement) 在当前节点的子节点中插入某个节点,即:为当前节点创建子节点,然后插入指定位置 remove(self, subelement) 在当前节点在子节点中删除某个节点 find(self, path, namespaces=None) 获取第一个寻找到的子节点 findtext(self, path, default=None, namespaces=None) 获取第一个寻找到的子节点的内容 findall(self, path, namespaces=None) 获取所有的子节点 iterfind(self, path, namespaces=None) 获取所有指定的节点,并创建一个迭代器(可以被for循环) clear(self) 清空节点 get(self, key, default=None) 取当前节点的属性值 set(self, key, value) 为当前节点设置属性值 keys(self) 获取当前节点的所有属性的 key items(self) 获取当前节点的所有属性值,每个属性都是一个键值对 iter(self, tag=None) 在当前节点的子孙中根据节点名称寻找所有指定的节点,并返回一个迭代器(可以被for循环)。 itertext(self) 在当前节点的子孙中根据节点名称寻找所有指定的节点的内容,并返回一个迭代器(可以被for循环)。 ‘‘‘ ‘‘‘ 遍历XML文档的所有内容 利用ElementTree.parse将文件直接解析成xml对象 from xml.etree import ElementTree as ET # 直接解析xml文件 tree = ET.parse("test.xml") # 获取xml文件的根节点 root = tree.getroot() print(root.tag) #顶层标签 #遍历XML文档的第二层 for child in root: print(child.tag,child.attrib) #第二层节点的标签名和属性 #遍历XML文档的第三层 for i in child: print(i.tag,i.attrib,i.text) #第三层文档的标签名和属性、标签之间的文本内容 ‘‘‘ ‘‘‘ 遍历XML中指定节点 from xml.etree import ElementTree as ET
在程序中使用配置文件来灵活的配置一些参数是一件很常见的事情,配置文件的解析并不复杂,在Python里更是如此,在官方发布的库中就包含有做这件事情的库,那就是ConfigParser,这里简单的做一些介绍。
Python ConfigParser模块解析的配置文件的格式比较象ini的配置文件格式,就是文件中由多个section构成,每个section下又有多个配置项,
ConfigParser的函数方法
读取配置文件
read(filename) 直接读取ini文件内容
sections() 得到所有的section,并以列表的形式返回
options(section) 得到该section的所有option
items(section) 得到该section的所有键值对
get(section,option) 得到section中option的值,返回为string类型
getint(section,option) 得到section中option的值,返回为int类型
写入配置文件
add_section(section) 添加一个新的section
set( section, option, value) 对section中的option进行设置
write将内容写入配置文件。
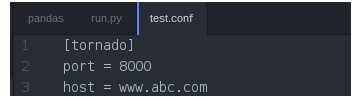
import ConfigParser conf = ConfigParser.ConfigParser() conf.read(‘test.conf‘) #读取配置文件 print conf.options(‘tornado‘) print conf.sections() #以列表形式 print conf.get(‘tornado‘, ‘port‘) print conf.getint(‘tornado‘, ‘port‘) #获取整数类型 conf.set(‘tornado‘, ‘domain‘, ‘123‘) #添加新的参数 conf.add_section("django") #添加新的模块 conf.set(‘django‘, ‘port‘, 80) conf.write(open(‘test.conf‘, ‘w‘))#写入文件
Python 中的 hashlib 模块用来进行 hash 或者 md5 加密。这里的加密,其实并非我们通常所说的加密,简单的说就是这种加密一般是不可逆的。这种加密算法实际上是被称之为摘要算法,包括 MD5,SHA1 等等。MD5的全称是Message-Digest Algorithm 5(信息-摘要算法)。SHA1的全称是Secure Hash Algorithm(安全哈希算法) 。SHA1基于MD5,加密后的数据长度更长。
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。摘要算法就是通过摘要函数 f() 对任意长度的数据 data 计算出固定长度的摘要 digest。摘要算法可以用来检验数据是否改变。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算 f(data) 很容易,但通过 digest 反推 data 却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
hashlib是个专门提供hash算法的库,里面包括md5, sha1, sha224, sha256, sha384, sha512
import hashlib md5 = hashlib.md5() md5.update(‘how to use md5 in python hashlib?‘) print md5.hexdigest() 计算结果如下: d26a53750bc40b38b65a520292f69306 如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的: md5 = hashlib.md5() md5.update(‘how to use md5 in ‘) md5.update(‘python hashlib?‘) print md5.hexdigest() 试试改动一个字母,看看计算的结果是否完全不同。 MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。 另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似: import hashlib sha1 = hashlib.sha1() sha1.update(‘how to use sha1 in ‘) sha1.update(‘python hashlib?‘) print sha1.hexdigest() SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。 比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。 有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞,比如Bob试图根据你的摘要反推出一篇文章‘how to learn hashlib in python - by Bob‘,
并且这篇文章的摘要恰好和你的文章完全一致,这种情况也并非不可能出现,但是非常非常困难
摘要算法能应用到什么地方?举个常用例子:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password
--------+----------
michael | 123456
bob | abc999
alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。
正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password
---------+---------------------------------
michael | e10adc3949ba59abbe56e057f20f883e
bob | 878ef96e86145580c38c87f0410ad153
alice | 99b1c2188db85afee403b1536010c2c9
当用户登录时,首先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明口令输入正确,如果不一致,口令肯定错误。
加盐--防止暴力破解
password=‘alex3714‘
m=hashlib.md5(‘yihangbailushangqingtian‘.encode(‘utf-8‘))
m.update(password.encode(‘utf-8‘))
passwd_md5=m.hexdigest()
print(passwd_md5)
运行python的时候,我们都是在创建并运行一个进程。像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序。在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序。
subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用。另外subprocess还提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而在进程间使用文本通信。
subprocess.call() 父进程等待子进程完成 返回退出信息(returncode,相当于Linux exit code) subprocess.check_call() 父进程等待子进程完成 返回0 检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性,可用try...except...来检查 subprocess.check_output() 父进程等待子进程完成 返回子进程向标准输出的输出结果 检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性和output属性,output属性为标准输出的输出结果,可用try...except...来检查。 这三个函数的使用方法相类似,下面来以subprocess.call()举例说明: >>> import subprocess >>> retcode = subprocess.call(["ls", "-l"]) #和shell中命令ls -a显示结果一样 >>> print retcode 0 将程序名(ls)和所带的参数(-l)一起放在一个表中传递给subprocess.call() shell默认为False,在Linux下,shell=False时, Popen调用os.execvp()执行args指定的程序;shell=True时,如果args是字符串,Popen直接调用系统的Shell来执行args指定的程序,如果args是一个序列,则args的第一项是定义程序命令字符串,其它项是调用系统Shell时的附加参数。 上面例子也可以写成如下: >>> retcode = subprocess.call("ls -l",shell=True) 在Windows下,不论shell的值如何,Popen调用CreateProcess()执行args指定的外部程序。如果args是一个序列,则先用list2cmdline()转化为字符串,但需要注意的是,并不是MS Windows下所有的程序都可以用list2cmdline来转化为命令行字符串。 subprocess.Popen class Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0) 实际上,上面的几个函数都是基于Popen()的封装(wrapper)。这些封装的目的在于让我们容易使用子进程。当我们想要更个性化我们的需求的时候,就要转向Popen类,该类生成的对象用来代表子进程。 与上面的封装不同,Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block),举例: >>> import subprocess >>> child = subprocess.Popen([‘ping‘,‘-c‘,‘4‘,‘blog.linuxeye.com‘]) >>> print ‘parent process‘ 从运行结果中看到,父进程在开启子进程之后并没有等待child的完成,而是直接运行print。 对比等待的情况: >>> import subprocess >>> child = subprocess.Popen(‘ping -c4 blog.linuxeye.com‘,shell=True) >>> child.wait() >>> print ‘parent process‘ 从运行结果中看到,父进程在开启子进程之后并等待child的完成后,再运行print。 此外,你还可以在父进程中对子进程进行其它操作,比如我们上面例子中的child对象: child.poll() # 检查子进程状态 child.kill() # 终止子进程 child.send_signal() # 向子进程发送信号 child.terminate() # 终止子进程 子进程的PID存储在child.pid 子进程的文本流控制 子进程的标准输入、标准输出和标准错误如下属性分别表示: child.stdin child.stdout child.stderr 可以在Popen()建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE将多个子进程的输入和输出连接在一起,构成管道(pipe),如下2个例子: >>> import subprocess >>> child1 = subprocess.Popen(["ls","-l"], stdout=subprocess.PIPE) >>> print child1.stdout.read(), #或者child1.communicate() >>> import subprocess >>> child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE) >>> child2 = subprocess.Popen(["grep","0:0"],stdin=child1.stdout, stdout=subprocess.PIPE) >>> out = child2.communicate() subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走。child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。
你需要先了解一些面向对象语言的一些基本特征,在头脑里头形成一个基本的面向对象的概念,这样有助于你更容易的学习Python的面向对象编程。
接下来我们先来简单的了解下面向对象的一些基本特征。
创建类 使用class语句来创建一个新类,class之后为类的名称并以冒号结尾,如下实例: class ClassName: ‘类的帮助信息‘ #类文档字符串 class_suite #类体 类的帮助信息可以通过ClassName.__doc__查看。 class_suite 由类成员,方法,数据属性组成。 实例 以下是一个简单的Python类实例: 实例 #!/usr/bin/python # -*- coding: UTF-8 -*- class Employee: ‘所有员工的基类‘ empCount = 0 def __init__(self, name, salary): self.name = name self.salary = salary Employee.empCount += 1 def displayCount(self): print "Total Employee %d" % Employee.empCount def displayEmployee(self): print "Name : ", self.name, ", Salary: ", self.salary empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用 Employee.empCount 访问。 第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法 self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。 self代表类的实例,而非类 类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。 class Test: def prt(self): print(self) print(self.__class__) t = Test() t.prt() 以上实例执行结果为: <__main__.Test instance at 0x10d066878> __main__.Test 从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。 self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的: 实例 class Test: def prt(runoob): print(runoob) print(runoob.__class__) t = Test() t.prt() 以上实例执行结果为: <__main__.Test instance at 0x10d066878> __main__.Test
实例化类其他编程语言中一般用关键字 new,但是在 Python 中并没有这个关键字,类的实例化类似函数调用方式。
以下使用类的名称 Employee 来实例化,并通过 __init__ 方法接受参数。
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)
您可以使用点(.)来访问对象的属性。使用如下类的名称访问类变量:
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
完整实例:
实例
执行以上代码输出结果如下:
Name : Zara ,Salary: 2000
Name : Manni ,Salary: 5000
Total Employee 2
你可以添加,删除,修改类的属性,如下所示:
emp1.age = 7 # 添加一个 ‘age‘ 属性
emp1.age = 8 # 修改 ‘age‘ 属性
del emp1.age # 删除 ‘age‘ 属性
你也可以使用以下函数的方式来访问属性:
类的继承 面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。继承完全可以理解成类之间的类型和子类型关系。 需要注意的地方:继承语法 class 派生类名(基类名)://... 基类名写在括号里,基本类是在类定义的时候,在元组之中指明的。 在python中继承中的一些特点: 1:在继承中基类的构造(__init__()方法)不会被自动调用,它需要在其派生类的构造中亲自专门调用。 2:在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量。区别于在类中调用普通函数时并不需要带上self参数 3:Python总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。 如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。 语法: 派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示: class SubClassName (ParentClass1[, ParentClass2, ...]): ‘Optional class documentation string‘ class_suite 实例 #!/usr/bin/python # -*- coding: UTF-8 -*- class Parent: # 定义父类 parentAttr = 100 def __init__(self): print "调用父类构造函数" def parentMethod(self): print ‘调用父类方法‘ def setAttr(self, attr): Parent.parentAttr = attr def getAttr(self): print "父类属性 :", Parent.parentAttr class Child(Parent): # 定义子类 def __init__(self): print "调用子类构造方法" def childMethod(self): print ‘调用子类方法 child method‘ c = Child() # 实例化子类 c.childMethod() # 调用子类的方法 c.parentMethod() # 调用父类方法 c.setAttr(200) # 再次调用父类的方法 c.getAttr() # 再次调用父类的方法 以上代码执行结果如下: 调用子类构造方法 调用子类方法 child method 调用父类方法 父类属性 : 200 你可以继承多个类 class A: # 定义类 A ..... class B: # 定义类 B ..... class C(A, B): # 继承类 A 和 B ..... 你可以使用issubclass()或者isinstance()方法来检测。 issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup) isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
实例:
执行以上代码输出结果如下:
调用子类方法
下表列出了一些通用的功能,你可以在自己的类重写:
| 序号 | 方法, 描述 & 简单的调用 |
|---|---|
| 1 | __init__ ( self [,args...] ) 构造函数 简单的调用方法: obj = className(args) |
| 2 | __del__( self ) 析构方法, 删除一个对象 简单的调用方法 : del obj |
| 3 | __repr__( self ) 转化为供解释器读取的形式 简单的调用方法 : repr(obj) |
| 4 | __str__( self ) 用于将值转化为适于人阅读的形式 简单的调用方法 : str(obj) |
| 5 | __cmp__ ( self, x ) 对象比较 简单的调用方法 : cmp(obj, x) |
Python同样支持运算符重载,实例如下:
以上代码执行结果如下所示:
Vector(7,8)
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
__private_method:两个下划线开头,声明该方法为私有方法,不能在类地外部调用。在类的内部调用 self.__private_methods
Python 通过改变名称来包含类名:
1
2
2
Traceback (most recent call last):
File "test.py", line 17, in <module>
print counter.__secretCount # 报错,实例不能访问私有变量
AttributeError: JustCounter instance has no attribute ‘__secretCount‘
Python不允许实例化的类访问私有数据,但你可以使用 object._className__attrName 访问属性,将如下代码替换以上代码的最后一行代码:
.........................
print counter._JustCounter__secretCount
执行以上代码,执行结果如下:
1
2
2
2
__foo__: 定义的是特列方法,类似 __init__() 之类的。
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
Python3 :
新式类的查找顺序:广度优先
新式类的继承:
class A(object): Python2 3 都是了
MRO算法--生成一个列表保存继承顺序表
不找到底部
Python2 中有新式类 和 经典类
Python2 默认的是经典类
经典类的继承是 深度优先
找到最深的,然后从头开始找
python和其他面向对象语言类似,每个类可以拥有一个或者多个父类,它们从父类那里继承了属性和方法。如果一个方法在子类的实例中被调用,或者一个属性在子类的实例中被访问,但是该方法或属性在子类中并不存在,那么就会自动的去其父类中进行查找。
继承父类后,就能调用父类方法和访问父类属性,而要完成整个集成过程,子类是需要调用的构造函数的。
如果子类和父类都有构造函数,子类其实是重写了父类的构造函数,如果不显式调用父类构造函数,父类的构造函数就不会被执行,导致子类实例访问父类初始化方法中初始的变量就会出现问题。
在子类中,构造函数被重写,但新的构造方法没有任何关于初始化父类的namea属性的代码,为了达到预期的效果,子类的构造方法必须调用其父类的构造方法来进行基本的初始化。有两种方法能达到这个目的:调用超类构造方法的未绑定版本,或者使用super函数。 方法一:调用未绑定的超类构造方法 修改代码,多增一行: class A: def __init__(self): self.namea="aaa" def funca(self): print "function a : %s"%self.namea class B(A): def __init__(self): #这一行解决了问题 A.__init__(self) self.nameb="bbb" def funcb(self): print "function b : %s"%self.nameb b=B() print b.nameb b.funcb() b.funca() class A: def __init__(self): self.namea="aaa" def funca(self): print "function a : %s"%self.namea class B(A): def __init__(self): #这一行解决了问题 A.__init__(self) self.nameb="bbb" def funcb(self): print "function b : %s"%self.nameb b=B() print b.nameb b.funcb() b.funca() 如上有注释的一行解决了该问题,直接使用父类名称调用其构造函数即可。 这种方法叫做调用父类的未绑定的构造方法。在调用一个实例的方法时,该方法的self参数会被自动绑定到实例上(称为绑定方法)。但如果直接调用类的方法(比如A.__init),那么就没有实例会被绑定。这样就可以自由的提供需要的self参数,这种方法称为未绑定unbound方法。 通过将当前的实例作为self参数提供给未绑定方法,B类就能使用其父类构造方法的所有实现,从而namea变量被设置。 方法二:使用super函数 修改代码,这次需要增加在原来代码上增加2行: #父类需要继承object对象 class A(object): def __init__(self): self.namea="aaa" def funca(self): print "function a : %s"%self.namea class B(A): def __init__(self): #这一行解决问题 super(B,self).__init__() self.nameb="bbb" def funcb(self): print "function b : %s"%self.nameb b=B() print b.nameb b.funcb() b.funca() #父类需要继承object对象 class A(object): def __init__(self): self.namea="aaa" def funca(self): print "function a : %s"%self.namea class B(A): def __init__(self): #这一行解决问题 super(B,self).__init__() self.nameb="bbb" def funcb(self): print "function b : %s"%self.nameb b=B() print b.nameb b.funcb() b.funca() 如上有注释的为新增的代码,其中第一句让类A继承自object类,这样才能使用super函数,因为这是python的“新式类”支持的特性。当前的雷和对象可以作为super函数的参数使用,调用函数返回的对象的任何方法都是调用超类的方法,而不是当前类的方法。 super函数会返回一个super对象,这个对象负责进行方法解析,解析过程其会自动查找所有的父类以及父类的父类。 方法一更直观,方法二可以一次初始化所有超类 super函数比在超累中直接调用未绑定方法更直观,但是其最大的有点是如果子类继承了多个父类,它只需要使用一次super函数就可以。然而如果没有这个需求,直接使用A.__init__(self)更直观一些。
>>> class foo(): clssvar=[1,2] def __init__(self): self.instance=[1,2,3] def hehe(self): print ‘haha‘ >>> foo.hehe <unbound method foo.hehe> >>> a=foo() >>> a.hehe <bound method foo.hehe of <__main__.foo instance at 0x01D60468>> >>> foo.hehe() Traceback (most recent call last): File "<pyshell#35>", line 1, in <module> foo.hehe() TypeError: unbound method hehe() must be called with foo instance as first argument (got nothing instead) 非绑定方法必须被实例调用 class foo(): foovar=1 def __init__(self): self.avar=3 def method(self): methodvar=2 print ‘hello‘,methodvar class foo1(foo): foo1var=4 def __init__(self,nm): foo.__init__(self) #调用非绑定方法——父类构造器 self.fooo=self.avar print self.fooo def method(self): pass a=foo1(2) #1.这是我根据Python核心编程上的例子写的,我们要弄清楚一点:类里面的方法就是非绑定方法,实例里面的方法就是绑定的。 #2.既然上面说非绑定方法只能被实例调用,那么我们是如何调用一个类的非绑定方法的呢?实际上用类不能调用非绑定方法,无非是没有给 self参数,那么我们给它就是。 >>> foo.hehe(a) haha #self=a 同样的道理,调用父类构造器给子类用,那么直接给self(就是子类对象)就可以啦! # 我们一般都是通过实例来调用,但也可以使用类来调用,比如上面通过调用父类的构造器可以避免子类调用时需要大量参数传递的情况
标签:地方 start other 子进程 存在 text config ict 析构
原文地址:http://www.cnblogs.com/slfenng/p/7375283.html