标签:cte 情况 变量命名 typeerror sci start ide 引入 分隔符
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串的输出格式:
>>>name = “test”
>>>print("my name is %s " %name) --输出结果:my name is test
PS: 字符串是 %s;整数 %d;浮点数%f
字符串的函数:
capitalize(),首字大写,其他小写
casefold(),转换成小写
lower(),转换成小写
name = "hi ni hao"
name2="hi Ni Hao"
s = ‘?‘
# capitalize首字大写,其他小写(make the first character have upper case and the rest lower case.)
print(name.capitalize()) #Hi ni hao
print(name2.capitalize())#Hi ni hao
print(name2.casefold())#hi ni hao
print(s.casefold()) #ss
print(s.lower())# ?
print(name2.lower())#hi ni hao
center(),指定特定宽度,居中,默认是空格
ljust(),指定特定宽度,居左,默认是空格
rjust(),指定特定宽度,居右,默认是空格
ss = "Hello world"
print(ss.center(20,"*")) #在指定的多少宽度中居中,默认是空格,****Hello world*****
print(ss.center(20))# Hello world 不指定默认是空格
print(ss.ljust(20,"*"))#Hello world*********
print(ss.rjust(20,"*"))#*********Hello world
count(),搜索特定的子串在字符串的个数(str.count(str, beg= 0,end=len(string))beg:从该指数开始搜索。第一个字符从索引0开始。end:搜索从该指数结束。第一个字符从索引0开始)
ss = "Hello world"
print(ss.count("l",3,10))#2
print(ss.count("l",2,10))#3
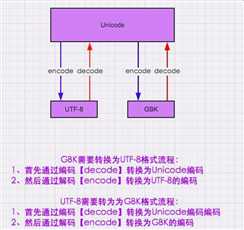
encode(),decode(),编码解码,python3.0默认编码为unicode,想转换成utf-8,gbk等,都要从unicode中转
ss = "Hello world"
print(ss.encode("gbk").decode("gbk"))#Hello world
print(ss.encode("gbk"))#b‘Hello world‘
endswith() 判断字符串是否以指定字符或子字符串结尾,常用于判断文件类型;
string: 被检测的字符串
str: 指定的字符或者子字符串(可以使用元组,会逐一匹配)
beg: 设置字符串检测的起始位置(可选,从左数起)
end: 设置字符串检测的结束位置(可选,从左数起)
如果存在参数 beg 和 end,则在指定范围内检查,否则在整个字符串中检查
s = ‘hello good boy doiido‘
print(s.endswith("do"))#True
print(s.endswith("do",4,15))#False
print(s.endswith("do",4))#True
print( s.endswith(‘‘))#True#匹配空字符集
print (s.endswith((‘t‘,‘b‘,‘o‘)))#True#匹配元组,元组中有一项匹配就ok,一个都不匹配,就false
f = ‘pic.jpg‘
if f.endswith((‘.gif‘,‘.jpg‘,‘.png‘)):
print (‘%s is a pic‘ %f)
else:
print(‘%s is not a pic‘ %f )
expandtabs()str.expandtabs(tabsize=8)tabsize:被替换为一个制表符‘\ T‘指定的字符数。返回一个字符串在标签字符,即副本
s = ‘he\tllo good boy doiido‘
print(s)#he llo good boy doiido
print(s.expandtabs(0))#hello good boy doiido
print(s.expandtabs(8))#he llo good boy doiido
find(),find(str, pos_start, pos_end)str:被查找“字串”pos_start:查找的首字母位置(从0开始计数。默认:0)pos_end: 查找的末尾位置(默认-1)返回值:如果查到:返回查找的第一个出现的位置。否则,返回-1
s = ‘hello good boy doiido‘
print(s.find("oo",1,10))#7
print(s.find("oo",1,4))#-1
format()
_name = input("name is:")
_age = input("age is:")
info = ‘‘‘
-----------info of {name}--------
the name is {name}
the age is {age}
‘‘‘.format(name=_name,age=_age)
print(info)
msg = "my name is {}, and age is {}"
print(msg.format("baby",22)) #my name is baby, and age is 22
msg = "my name is {1}, and age is {0}"
print(msg.format("baby",22))#my name is 22, and age is baby
msg = "my name is {name}, and age is {age}"
print(msg.format(age=22,name="baby"))#my name is baby, and age is 22
format_map()
msg = "my name is {name}, and age is {age}"
print(msg.format_map({‘name‘:‘baby‘,‘age‘:22}))#my name is baby, and age is 22
isdigit(),如果字符串只包含数字则返回 True 否则返回 False。
a = "111"
b= "test"
print(a.isdigit())#True
print(b.isdigit())#False
split()函数
语法:str.split(str="",num=string.count(str))[n]
参数说明:
str:表示为分隔符,默认为空格,但是不能为空(‘‘)。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]:表示选取第n个分片
注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
s = ‘hello good boy doiido‘
print(s.split("o",2))#[‘hell‘, ‘ g‘, ‘od boy doiido‘]
print(s.split("o",2)[0])#hell
print(s.split())#[‘hello‘, ‘good‘, ‘boy‘, ‘doiido‘]
u1,u2,u3 = s.split("o",2)#分割两次,并把分割后的三个部分保存到三个文件
print(u1)#hell
print(u2)# g
print(u3)#od boy doiido
os.path.split()函数
语法:os.path.split(‘PATH‘)
参数说明:
1.PATH指一个文件的全路径作为参数:
2.如果给出的是一个目录和文件名,则输出路径和文件名
3.如果给出的是一个目录名,则输出路径和为空文件名
import os
print(os.path.split("/dd/ff/python/"))#(‘/dd/ff/python‘, ‘‘)
print(os.path.split("/dd/ff/python"))#(‘/dd/ff‘, ‘python‘)
isidentifier()检测一段字符串可否被当作标志符,即是否符合变量命名规则
name = "1bb"
print(name.isidentifier())#False
name2 = "bb"
print(name2.isidentifier())#True
zfill()把调用的字符串变成width长,并在右对齐,不足部分用0补足
name2 = "bb"
print(name2.zfill(20))#000000000000000000bb
index()返回所在字符串的索引
ss = "hello world"
print(ss.index("w"))#6
expandtabs()把\t替换成空格
s = "b\tool"
print(s.expandtabs(5)#b ool
isalnum()是否是阿拉伯数字,包含英文字符和数字
s = "aabb?"
print(s.isalnum())#False
s1 = "aab12"
print(s1.isalnum())#True
isalpha()判断是否是全英文
s = "aabb123"
s1 = "aabb"
print(s.isalpha())#False
print(s1.isalpha())#True
swapcase()大小写互换
s = "aabb123"
s1 = "AABBcc"
print(s.swapcase())#AABB123
print(s1.swapcase())#aabbCC
islower()/isupper()判断是否为小写/大写
s = "aabb"
s1 = "AABB"
s2="aB"
print(s.islower())#True
print(s1.isupper())#True
print(s1.islower())#False
print(s.isupper())#False
print(s2.islower())#False
print(s2.isupper())#False
isprintable()判断是否为可打印字符串/判断字符串中所有字符是否都属于可见字符,tty file driver file
s = "aabb"
s1 = "AABB\t"
print(s.isprintable())#True
print(s1.isprintable())#False
isspace()判断是否为空格
s = "aabb "
s1 = " "
print(s1.isspace())#True
print(s.isspace())#False
istitle()判断是否首字母大写,其他字母小写
s = "hello world"
s1 = "Hello world"
s2 = "Hello World"
print(s.istitle())#False
print(s1.istitle())#False
print(s2.istitle())#True
join() join(iterable)将字符串加入到可迭代对象里面去,iterable必须是每一个元素是字符串,否则会跑出TypeError异常
print("+".join(["1","2","3","4"]))#1+2+3+4
strip() strip([chars])去除字符串中以chars中的前缀和后缀,chars默认为空格
lstrip([chars]): 去掉左边
rstrip([chars]): 去掉后边
s = " Hell World "
print(s)# Hell World
print(s.strip(" "))#Hell World
partition()返回分隔符前的部分,分隔符,分隔符后的部分。如果没找到分隔符,则返回字符串本身以及两个空字符串。
rpartition(sep): 从右往左搜索
s = "Hell World"
print(s.partition(" "))#(‘Hell‘, ‘ ‘, ‘World‘)
s1 = "Hell+World"
print(s1.partition("+"))#(‘Hell‘, ‘+‘, ‘World‘)
replace(old, new[, count])替换count个old为新的new,count默认为全部
s = "Hell World"
print(s.replace("H","BB"))#BBell World
string.casefold和string.lower 区别
python 3.3 引入了string.casefold 方法,其效果和 string.lower 非常类似,都可以把字符串变成小写,那么它们之间有什么区别?他们各自的应用场景?
对 Unicode 的时候用 casefold
string.casefold官方说明:Casefolding is similar to lowercasing but more aggressive because it is intended to remove all case distinctions in a string. For example, the German lowercase letter ‘?‘ is equivalent to "ss". Since it is already lowercase, lower() would do nothing to ‘?‘; casefold()converts it to "ss".
The casefolding algorithm is described in section 3.13 of the Unicode Standard
lower() 只对 ASCII 也就是 ‘A-Z‘有效,但是其它一些语言里面存在小写的情况就没办法了。文档里面举得例子是德语中‘?‘的小写是‘ss‘:
s = ‘?‘
s.lower() # ‘?‘
s.casefold() # ‘ss‘
aa = "abcdf"
bb = "12345"
p = str.maketrans(aa,bb)
cc = "aa is bc or df"
print(cc.translate(p))#11 is 23 or 45
string.lower官方说明:Return a copy of the string with all the cased characters [4] converted to lowercase.
The lowercasing algorithm used is described in section 3.13 of the Unicode Standard
字符串常用功能:
移除空白
分割
长度
索引
切片
标签:cte 情况 变量命名 typeerror sci start ide 引入 分隔符
原文地址:http://www.cnblogs.com/fenny0907/p/7363853.html