标签:防止 二维 结构 label computers 方式 程序 用户 pre
验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的人工智能技术的发展,传统的字符验证已经形同虚设。 所以,大家一方面研究和学习此代码时,另外一方面也要警惕自己的互联网系统的web安全问题。
Keywords: 人工智能,Python,字符验证码,CAPTCHA,识别,tensorflow,CNN,深度学习
全自动区分计算机和人类的公开图灵测试(英语:Completely Automated Public Turing test to tell Computers and Humans Apart,簡稱CAPTCHA),俗称验证码,是一种区分用户是计算机或人的公共全自动程序 [1]。
得益于基于卷积神经网络CNN的人工智能技术的发展,目前基于主流的深度学习框架的直接开发出 端到端不分割 的识别方式,而且在没有经过太多trick的情况下,已经可以达到95%以上的识别率。
传统的机器学习方法,对于多位字符验证码都是采用的 化整为零 的方法:先分割成最小单位,再分别识别,然后再统一。 卷积神经网络方法,直接采用 端到端不分割 的方法:输入整张图片,输出整个图片的标记结果,具有更强的通用性。
具体的区别如下图:
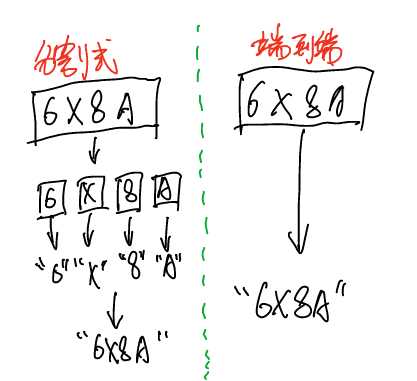
端到端 的识别方法显然更具备优势,因为目前的字符型验证码为了防止被识别,多位字符已经完全融合粘贴在一起了,利用传统的技术基本很难实现分割了。本文重点推荐的就是 端到端 的方法。
本文代码都参考自此文:
http://blog.topspeedsnail.com/archives/10858
斗大的熊猫--《WTF Daily Blog》
本项目主要解决的问题是对某一模式的字符型验证进行端到端的识别。
输入内容:
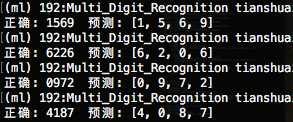
模型预测结果:
原作者代码中:
def train_crack_captcha_cnn(): output = crack_captcha_cnn() # loss #loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y)) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y)) # 最后一层用来分类的softmax和sigmoid有什么不同? # optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰 optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) ……
作者在代码的注释中出提出了这样的疑问:
对 softmax 和 sigmoid 的使用方式有疑问。
然后在文章下面读者评论区也都提到了此问题,在此进行整体解释一下。
原文中CNN的输出的维度是 MAX_CAPTCHA*CHAR_SET_LEN ,其实这些维度并不都是完全独立分布的, 但是使用sigmoid loss也是仍然可以的,相当于先用sigmoid进行了一次归一化,然后再将各个维度的值向目标值进行 回归 , 最后loss越小,两个向量的对应的值也越接近。 其实sigmoid是可以看成是一个多分类的问题,在这个例子上也能起到比较好的收敛效果。
当然,关于分类的问题,看所有的机器学习框架里面,都是建议使用softmax进行最后的归一化操作,这其实相当于是一种 马太效应 : 让可能性大的分类的值变得更大,让可能性小的分量值变得更小。但是这有个前提,就是参与到softmax运算的一组数据,必须是 相关联 的, 所以如果要使用 softmax_cross_entropy_with_logits ,只需要将网络进行简单修改即可。把输出的维度做成二维[MAX_CAPTCHA, CHAR_SET_LEN], 然后使用softmax loss。
output = crack_captcha_cnn()#36×4 predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]) # 36行,4列 label = tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
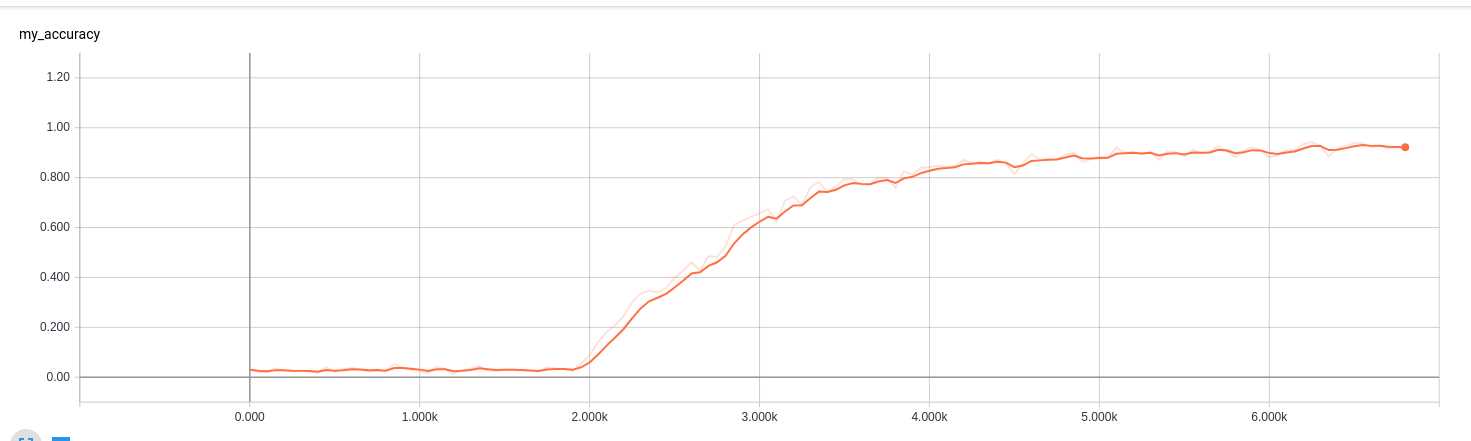
最后使用GPU训练的实验结果对比:
使用tensorboard对accuracy进行监控:
sigmoid-6千个step:
softmax-8千个step:
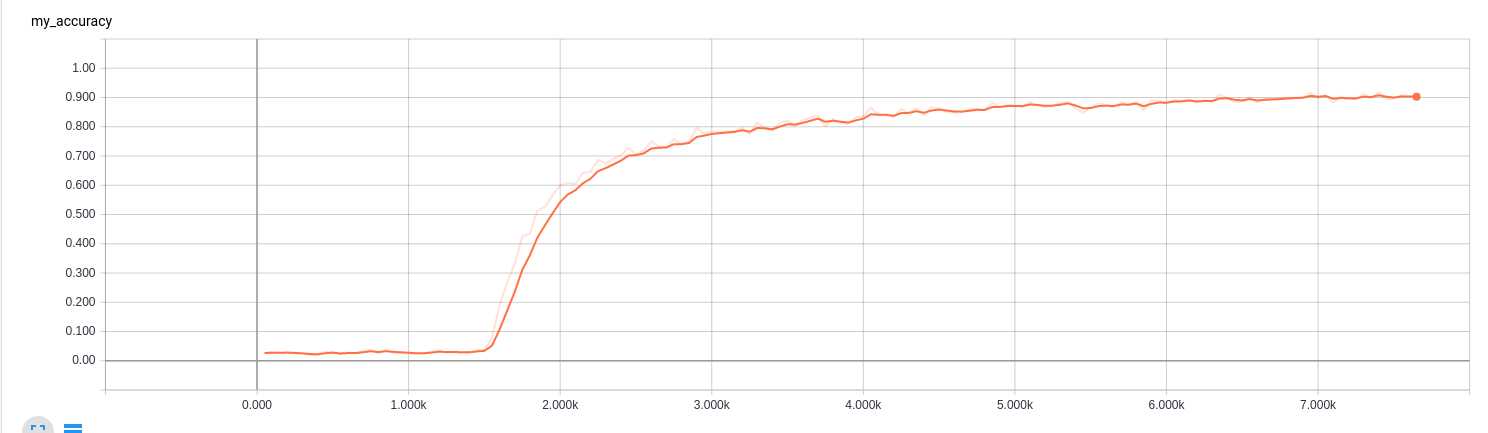
softmax-8万个step:
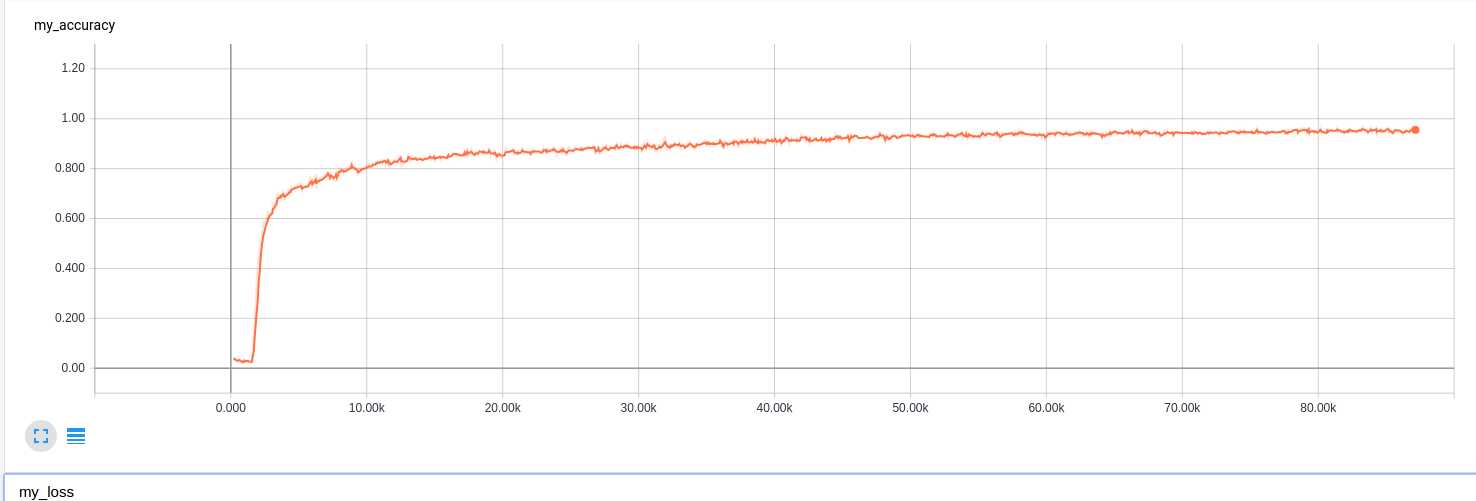
整体来说,在这个例子里面,好像 sigmoid的收敛速度快些,当然这个可能是本项目里面的外界因素有利于sigmoid吧,至于具体原因,等后续再进行研究和解释吧,当然有可能根本解释不了,因为对于CNN,目前主流的意见都是:,反正效果就是好,但是不知道为啥, 科幻得近于玄幻 的一种技术。
github源码地址:
https://github.com/zhengwh/captcha-tensorflow
项目文件介绍:
本文主要只写原作者没有提到的内容,想了解原文的,可以直接去原作者页面。
| [1] | wiki-CAPTCHA https://en.wikipedia.org/wiki/CAPTCHA |
如果有对相关技术有持续关注的兴趣的同学,欢迎加入QQ群: 592109504
或者手机QQ扫码加入:
基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
标签:防止 二维 结构 label computers 方式 程序 用户 pre
原文地址:http://www.cnblogs.com/beer/p/7392397.html