标签:distance math font key gauss ges 一点 strong 高斯
上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,在此描述如何加权。
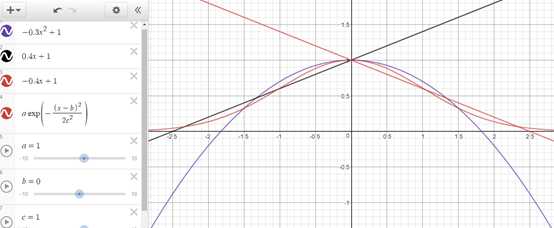
该方法最简单的形式是返回距离的倒数,比如距离d,权重1/d。有时候,完全一样或非常接近的商品权重会很大甚至无穷大。基于这样的原因,在距离求倒数时,在距离上加一个常量:
weight = 1 / (distance + const)
这种方法的潜在问题是,它为近邻分配很大的权重,稍远一点的会衰减的很快。虽然这种情况是我们希望的,但有时候也会使算法对噪声数据变得更加敏感。
高斯函数比较复杂,但克服了前述函数的缺点,其形式:
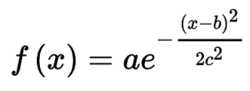
其中a,b,c∈R
高斯函数的图形在形状上像一个倒悬着的钟。a是曲线的高度,b是曲线中心线在x轴的偏移,c是半峰宽度(函数峰值一半处相距的宽度)。
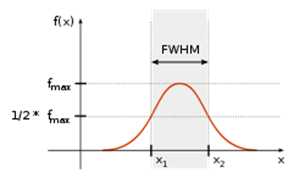
半峰宽度
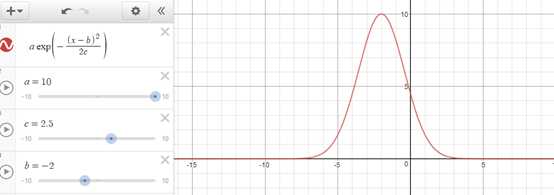
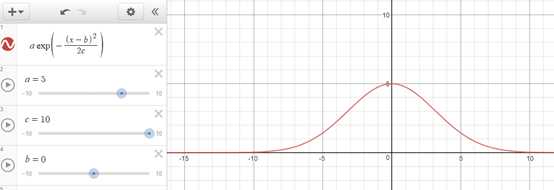
def gaussian(dist, a=1, b=0, c=0.3): return a * math.e ** (-(dist - b) ** 2 / (2 * c ** 2))
上面的高斯函数在距离为0的时候权重为1,随着距离增大,权重减少,但不会变为0。下图是高斯函数和其它几个函数的区别,其它函数在距离增大到一定程度时,权重都跌至0或0以下。
加权kNN首先获得经过排序的距离值,再取距离最近的k个元素。
1.在处理离散型数据时,将这k个数据用权重区别对待,预测结果与第n个数据的label相同的概率:
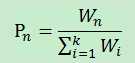
2.在处理数值型数据时,并不是对这k个数据简单的求平均,而是加权平均:通过将每一项的距离值乘以对应权重,让后将结果累加。求出总和后,在对其除以所有权重之和。

Di代表近邻i与待预测值x的距离,Wi代表其权重,f(x)是预测的数值型结果。每预测一个新样本的所属类别时,都会对整体样本进行遍历,可以看出kNN的效率实际上是十分低下的。
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
标签:distance math font key gauss ges 一点 strong 高斯
原文地址:http://www.cnblogs.com/bigmonkey/p/7387943.html