标签:星期六 env count 传递 中国移动 天空 开发者 b树 base
*DQL:数据查询语言
*DML:数据操作语言
*DDL:数据定义语言
DCL:数据控制语言
TPL:事务处理语言
CCL:指针控制语言
1、登录
Win+R—cmd—>sqlplus “/as sysdba” //以sysdba用户登录,这样可以管理权限,添加用户等
Win+R—cmd—>sqlplus username/password //以指定用户名密码登录
win+R —> cmd —–> sqlplus //按照提示,输入用户名密码
2、创建用户
create user username identified by password; 
3、给与权限
grant resource,connect to username;
resource:
create trigger
create sequence
create type
create procedure
create cluster
create operator
create indextype
create table
connect:
create session
4、切换用户显示当前用户
conn username/password 切换用户
show user 显示当前用户名
5、使用$后面跟window命令符可以使用window命令
cls清屏exit退出
7、查询当前系统时间
select sysdate from dual;
8、导入数据文件(sql语句表数据之类的)
因为数据文件默认语言环境为英语,当前系统是中文,中英文时间显示不一致,导致倒入失败,所以 需要先修改语言环境
alter session set nls_date_language=english;
alter session set nls_language=english;
然后开始导入文件使用:@ 文件全路径名 或者 start 文件全路径名
9、查看当前用户的所有表
select table_name from user_tables;
10、查看当前表结构
desc 表名字;
11、oracle服务意思 
1.OracleDBConsoleorcl oem控制台的服务进程
2.OracleJobSchedulerXE 定时器的服务进程
3.OracleOraDb10g_home1iSQL*Plus isql*plus的服务进程
4.OracleXETNSListener 监听器的服务进程
5.OracleServiceORCL 数据库服务进程
1、distinct关键字
distinct跟在select后面,代表去除重复的,这个重复是整体重复的。
select 子句后面指定要查询的列
from 后面跟要查询的表
2、select语句可以对指定的列的所有值进行算术运算。
语法:
select 要计算列的名字 运算符 数字from 表名;
3、取别名
select 列名 要修改的名字 from 表明
select 列名 as 要修改的名字 from 表明
4、使用||合并多个列之间添加字符串
要添加字符靠近列名的那一边需要加||,并且要添加的字符串需要用单引号
select ‘找到的id为:’||id||’ 找到的名字为’||last_name as Name from s_emp;
5、对空的值进行替换(替换的值一定是要同类型的)
select nvl(要判断是否有空值的列名,要替换列的同类型的值) from 表名
select nvl(要判断是否有空值的列名,不为空显示的值,为空显示的值) from 表名
1、在当前操作的命令行追加内容
a 追加的内容
2、在当前操作的命令行修改内容
c /命令行存在的内容/要被修改的内容
3、清空当前缓存的命令
clear buffer 清空当前缓存咋命令
4、删除当前操作行
del 要删除的行号
5、当前操作命令的下一行插入内容
i 直接i回车就可以在下一行添加内容
6、查看缓存命令
l 行号 :查看指定行号的缓存内容
直接输入l显示的是缓存中所有的
7、输入系统终端命令
Linux环境下使用 !后面跟着终端命令
Window环境下使用 后面跟终端命令例如调用window下的清屏使用cls
8、执行缓存命令
使用/就可以执行sql语句
9、修改对应行的内容
输入要修改行号,后面直接跟要修改内容就可以
1 要修改的内容
10、退出缓存输入
直接在要准备添加行回车就好
11、保存你缓存的命令到文件中
save 要保存的文件路径 append(这个代表追加到当前要保存的文件路径里面)
12、从文件提取到缓存
get 文件路径
13、执行文件中的sql命令
start 文件路径 或者 @ 文件路径
14、编辑文档
edit 文件路径 用系统默认的东西打开文件
15、保存你的sql语句和执行结果保存到文件(是追加保存的)
你从开始执行spool开始就开始记录了,知道spool off 关闭为止,所输入的所有东西在文件都有记录
spool 文件路径
sql1
result1
sql2
result2
…
spool off 关闭spool功能
1、定义要格式化的列或者给列起的名字
使用column关键字
colu 要修改的列名 format a15 //代表列显示的时候最多为15个子节长
2、colu first_name heading ‘Employ|Name’ format a5
给first_name 取了个名字叫做Employ|Name,|表示换行,a5表示5个字节
3、column salary JUSTIFY LEFT FORMAT $99,990.00 
Justify left代表列名向左对其
999,999.999代表每一位为0−9之间的数“,”是代表分割符,千分位000,000.000代表每一位为0-9之间的数,不足的用0补齐
4、column start_date format a8 null ‘not date’; 
代表列名如果为空,就用not date文本代替
format后面不能直接跟null 在a8后面写
这里的和替换空和nvl是有区别的,nvl必须要求类型匹配才可以替换
5、column显示所有对列格式的设置
6、显示指定列的设置情况
column 列名
7、删除指定列的设置和删除全部列的设置
column 列名 clear
clear column //删除全部
8、出错的时候
出错的时候不能显示就只显示#######
set linesize(line) 设置sqlplus输出的最大行宽 –
set pagesize 设置页面的最大行数
set newpage 设置页面之间的空行数
spool sqlplus屏幕的文件输入输出命令
edit 使用自定义的编辑器编辑指定文件 其实也可以使用ed.修改后直接使用/即可执行
save 保存当前session最近的sql语句至指定的文件中
host 返回到操作系统环境,类似!
start或@ 执行文件中的命令
edit 使用自定义的编辑器编辑指定文件
define_editor 自定义sqlplus里的编辑器
exit或quit 退出sqlplus
column
column是sqlplus里最实用的一个命令,很多时候sql语句输出的列宽度不合适而影响查看,都需要
用到这个命令来更改select语句中指定列的宽度和标题。大部分时候,我们可以简写column为col即
可,主要有以下两种用法:
?修改列宽度
column c1 format a20 –将列c1(字符型)显示最大宽度调整为20个字符
column c1 format 9999999 –将列c1(num型)显示最大宽度调整为7个字符
?修改列标题
column c1 heading c2 –将c1的列名输出为c2
Where子句的使用(如果报from找不到,就要注意from是不是和某个列写到一起了!)
语法:
select 要查询的列名
from 表名
where 列名或别名
逻辑操作符
表达式 。。。
1、作用:对SQL语句返回的数据集进行筛选;
2、位置:紧跟在from子句后
3、 内容:由一至多个限定条件组成,限定条件由表达式, 比较符, 字面值组成。
4、 所有字符串和日期要用单引号括起来,数值不需要单引号。
日期在Oracle里有特定的格式,’DD-MON-YY’(具体看日期的显示格式),
否则作为一个字符串。
5、 几种常见的操作符:
1》逻辑比较操作符
= > < >= <= != <> ^=(后面三种都是不等于)
需求:查找工资大于1000的所有员工的last_name和工资。
需求:查找不在45号部门工作的所有员工的id,last_name和dept_id,并且按照dept_id 升序进行排序
select id,last_name,dept_id
from s_emp
where dept_id<>45
order by dept_id;
2》sql比较操作符(在where后面写,order by 前面)
between and:在什么范围之内
in(xx,xx,xx):在一个列表中的值
like:模糊查询,即值不是精确的值的时候使用
通配符,即可以代替任何内容的符号
%:通配0到多个字符

_: 当且仅当通配一个字符
转义字符:
默认为,可以指定 指定的时候用escape 符号指明即可,转义字符只能转义后面的一 个字符 ,下面这个代表是以_开头后面任意字符的last_name 
between 1 and 4: 包括起止值。限定内容为1到4。 
in (1,2,4): 限定内容为1,2,4。
is null:对null值操作特定义的操作符,不能使用=否定的Is not nul,not in ,not like ,not butween
3》逻辑操作符
当条件有多个的时候使用
and:且逻辑
or:或逻辑
注意:and逻辑比or逻辑要高
not:非逻辑
需求:
1.查找员工id在[5,20]之间的所有员工的id和last_name 
or 
2.查找员工id不在[5,20]之间的所有员工的id和last_name 
or
这个需要注意的是not匹配的是最近的一样,优先级相对于and是高的,所以加括号
3.查找在43或者44号部门的员工的id和last_name;

or
需求:查看员工名字以C字母开头的员工的id,工资。
练习:查看员工名字长度不小于5,且第四个字母为n字母的员工id和工资
需求:查看员工名字中包含一个_的员工id和工资 
需求:查看员工提成为为空的员工的id和名字
需求:查看员工部门id为41且职位名称为Stock Clerk(存库管理员)的员工id和名字
练习:查看员工部门为41 或者 44号部门 且工资大于1000的员工id和名字
查看员工部门为41且工资大于1000 或者 44号部门的员工id和名字
函数:这里的函数相当于Java中写好的一些方法,有名字,可以传递参数,实现某一项具体功能。
函数分为:
1.单行函数
1.字符函数
2.日期函数
3.数字函数
4.转换函数
2.分组函数(后面的章节再做学习)
学前须知:
哑表dual
dual是一个虚拟表,辅助查找和运算。通常用在select语句中,作为查询的目标表结构,oracle保证dual里面永远只有一条记录。
例如:
显示1+1的结果,可以看出,dual很多时候是为了构成select的标准语法
select 1+1 from dual;
1、字符函数
1) LOWER:转换成小写
2) UPPER:转换成大写
3) INITCAP:首字母变成大写,其余都小写
4) CONCAT:字符串的连接
5) SUBSTR(str,start,length)或者SUBSTR(str,start):字符串的截取
6) LENGTH:求字符串的长度
7) NVL : 转换null的值。(前边已经用过)
nvl2:
8) DECODE:
**LOWER 把字符转为小写**
例如:把‘HELLO‘转换为小写
select lower(‘HELLO‘)
from dual;
例如:把s_emp表中的last_name列的值转换为小写
select lower(last_name)
from s_emp;
upper 把字符转换为大写
例如:把’world’转换为大写
select upper(‘world’)
from dual;
例如:把s_emp表中的last_name列的值转换为大写
select upper(last_name)
from s_emp;
例如:查询s_emp表中名字为Ngao的人信息
这样是查不到:
select last_name,salary,dept_id
from s_emp
where last_name=‘NGAO‘;
这样就可以查询到了:
select last_name,salary,dept_id
from s_emp
where upper(last_name)=‘NGAO‘;
initcap 把字符串首字母大写
例如:把’hELLO’转换为首字母大写,其余字母小写
select initcap(‘hELLO’)
from dual;
concat 把俩个字符串连接在一起(类似之前的||的作用)
例如:把’hello’和’world’俩个字符串连接到一起,并且起个别名为msg
select concat(‘hello’,’world’) msg
from dual;
例如:把first_name和last_name俩个列的值连接到一起
select concat(first_name,last_name)
from s_emp;
substr 截取字符串
例如:截取’hello’字符串,从第2个字符开始,截取后面的3个字符
select substr(‘hello’,2,3)
from dual;
可以找到第二个字母开头的是什么字母,其他同理
length 获得字符串长度
例如:获得’world’字符串的长度
select length(‘world’)
from dual;
例如:获得s_emp表中last_name列的每个值的字符长度
select length(last_name)
from s_emp;
nvl 替换列中为null的值
在前面的章节已经使用过了
nvl(要输出的列名,为空的时候要被替换的值) //要替换的值类型必须要和之前保持一致 
例子:
1.查找last_name全小写的值为velasquez的员工的lastname 
2.查找last_name的长度>10的所有员工的last_name
instr查找字符串
instr(‘1234;5678’,’;’,1,1)-1
解释:1. ‘1234;5677’==>可以是表达式,也可以是具体数据
2. ‘;’==>为分离的标志,这里为两组数据中的“;”号
3. 第一个1为从左边开始,如果为-1,则从右边开始。
4. 第二个1为“;”出现的第几次。
2、数字函数
1) ROUND:四舍五入
2) TRUNC:截取,不进行四舍五入
3) MOD:取余
**round 四舍五入**
(切记-1代表保存小数点后一位,0保留到各位,1保留到10
round(arg1,arg2)第一个参数表示要进行四舍五入操作的数字
第二个参数表示保留到哪一位(负数代表小数点之前,0,正数代表小数点之后)0代表保留到个位!!-1代表保存到十位
select round(45.67) from dual; 46
select round(45.67,1) from dual; 45.7
select round(45.67,2) from dual; 45.67
select round(45.67,-1) from dual; 50
select round(45.67,-2) from dual; 0
select round(55.67,-2) from dual; 100
例如
保留到小数点后面2位
select round(45.923,2)
from dual;
保留到个位 (个十百千万...)
select round(45.923,0)
from dual;
保留到十位 (个十百千万...)
select round(45.923,-1)
from dual;
**trunc 截取到某一位**
trunc(arg1,arg2)
和round的用法一样,但是trunc只舍去不进位
select trunc(45.67) from dual; 45
select trunc(45.67,1) from dual; 45.6
select trunc(45.67,2) from dual; 45.67
select trunc(45.67,-1) from dual; 40
select trunc(45.67,-2) from dual; 0
select trunc(55.67,-2) from dual; 0
例如:
截取到小数点后面2位
select trunc(45.923,2)
from dual;
截取到个位 (个十百千万...)
select trunc(45.923,0)
from dual;
截取到十位 (个十百千万...)
select trunc(45.923,-1)
from dual;
mod 取余
mod(arg1,arg2)
第一个参数表示要进行取余操作的数字
第二个参数表示参数1和谁取余
“`
例如:
把10和3进行取余 (10除以3然后获取余数)
select mod(10,3)
from dual;
3、日期函数
1) MONTHS_BETWEEN:两个日期之间的月数,如果是正数前面的值大于后面的值
2) ADD_MONTHS:在指定日期上增加月数
3) NEXT_DAY:指定日期的下一个星期几是哪天
4) LAST_DAY:指定日期的最后一天
5) ROUND:对指定日期进行四舍五入
6) TRUNC:对指定日期进行截取
sysdate关键字
表示系统的当前时间
例如:
显示时间:当前时间
注意:sysdate进行加减操作的时候,单位是天
例如:
显示时间:明天的这个时候
例如:
显示时间:昨天的这个时候
例如:
显示时间:1小时之后的时候
months_between 俩个时间点之间相差多少个月(单位是月)
例如:
30天之后和现在相差多少个月
add_months 返回一个日期数据:表示一个时间点,往后推x月的日期
例如:
‘01-2月-2016’往后推2个月
例如:
当前时间往后推4个月
next_day 返回一个日期数据:表示一个时间点后的下一个星期几在哪一天
例如:
当前时间的下一个星期5是哪一个天 
注意:
如果要使用’FRIDAY’,那么需要把当前会话的语言环境修改为英文
last_day 返回一个日期数据:表示一个日期所在月份的最后一天
例如:
当前日期所在月份的最后一天
round 对日期进四舍五入,返回操作后的日期数据。逢16日往月份进一,逢7月往年份进一
round(sysdate,’year/y/yy/yyy/yyyy’) 年 7月节点
round(sysdate,’mm/month’) 月 16号节点
round(sysdate,’d/day’) 星期 星期四节点
round(sysdate,’dd’) : 天 -》 12点节点
例如:
把当前日期四舍五入到月(年月日.时 分 秒 把这个看错数字就可以了)
今天2016年9月5日四舍五入到月,就要看日是否大于16?大于进一,不大于不进一,同时舍弃为1 
把当前日期四舍五入到年
大致算一下,今天已经9月了,所以满足大于节点7进一位,同时舍弃年前面的值
trunc 对日期进行截取 和round类似,但是只舍弃不进位
trunc(sysdate,‘yyyy/year‘) --返回当年第一天。
trunc(sysdate,‘mm/month‘) --返回当月第一天。
trunc(sysdate,‘d/day‘) --返回当前星期的第一天。
trunc(sysdate,‘dd‘)--返回当前年月日
截取和round基本是一样的只是,不进位而已。
4、类型转换函数
1).TO_CHAR 将日期或者数值转换成字符串
2).TO_NUMBER 将字符串转换成数字
3).TO_DATE 将日期字符串转换成日期
to_char 把日期转换为字符
例如:
把当前日期按照指定格式转换为字符串
日期格式:
yyyy/YYYY:四位数的年份
rrrr:四位数的年份
yy:两位数的年份
rr:两位数的年份
mm:两位数的月份(数字)
D:一周的第几天
DD:一月的第几天
DDD :一年的第几天
YEAR:英文的年份
MONTH:英文全称的月份
mon:英文简写的月份
ddsp:英文的第几天
ddspth:英文序列数的第几天
DAY:全英文的星期
DY:简写的英文星期
hh:小时
mi:分钟
ss:秒
AM:上午
PM:下午
练习:显示当前时间,查询当前时间是这年的第几天?是这个星期的第几天?是这个月的第几天?
select ‘这年的第一几天:‘||to_char(sysdate,‘DDD‘)||‘ 这个星期的第几天:‘ ||to_char(sysdate,‘D‘)||‘ 这个月的第几天:‘||to_char(sysdate,‘DD‘) as 结果from dual;
(注意拼接字符串,只有一个别名,是一个整体)
例如:
测试常见的一些日期数据转换为字符串的格式
select to_char(sysdate,‘yyyy MM D DD DDD YEAR MONTH ddsp ddspth DAY DY‘) from dual;
select to_char(sysdate,‘dd-mm-yy‘)
from dual;
select to_char(sysdate,‘dd-mm-yy HH24:MI:SS AM‘)
from dual;
在早期的计算机的程序中规定了的年份仅用两位数来表示。也就是说,假如是1971年,在计算机里就会被表示为71,但是到了2000年的时候这个情况就出现了问题,计算机就会将其年份表示为00。这样的话计算机内部对年份的计算就会出现问题。这个事情当时被称为千年虫
数据库中表示日期中年份的有俩种: yy和rr
之前一直使用的时候yy格式,后来才有的rr格式
yy表示使用一个俩位数表示当前年份:
1990 ---yy数据库格式---> 90
1968 ---yy数据库格式---> 68
1979 ---yy数据库格式---> 79
如果日期中的年份采用的格式为rr,并且只提供了最后2位年份,那么年份中的前两位数字就由两部分共同确定:提供年份的两位数字(指定年),数据库服务器上当前日期中年份的后2位数字(当年)。确定指定年所在世纪的规则如下:
规则1 如果指定年在00~49之间,并且当前年份在00~49之间,那么指定年的世纪就与当前年份的世纪相同。因此,指定年的前两位数字就等于当前年份的前两位数字。例如,如果指定年为15,而当前年份为2007,那么指定年就是2015。
规则2 如果指定年在50~99之间,并且当前年份在00~49之间,那么指定年的世纪就等于当前年份的世纪减去1。因此,指定年的前两位数字等于当前年份的前两位数字减去1。例如,如果指定年为75,而当前年份为2007,那么指定年就是1975。
规则3 如果指定年在00~49之间,并且当前年份在50~99之间,那么指定年的世纪就等于当前年份的世纪加上1。因此,指定年的前两位数字等于当前年份的前两位数字加上1。例如,如果指定年为15,而当前年份为2075,那么指定年就是2115。
规则4 如果指定年在50~99之间,并且当前年份在50~99之间,那么指定年的世纪就与当前年份的世纪相同。因此,指定年的前两位数字就等于当前年份的前两位数字。例如,如果指定年为55,而当前年份为2075,那么指定年就是2055。
注意:rr格式并没有完全的解决俩位数年份保存的问题,思考里面还有哪些问题存在。
to_char 把数字转换为字符
L : 本地货币符号
:
. : 小数点
, : 千分符
9 : 0-9
0 : 0-9, 如果位数不足,强制补0
例如:
select to_char(salary,‘$999,999.00‘)
from s_emp;
fm表示去除结果显示中的开始的空格
L表示系统本地的货币符号
select to_char(salary,‘fmL999,999.00‘)
from s_emp;
to_number 把字符转换为数字
例如:
select to_number(‘1000‘)
from dual;

//这个写法是错的 abc不能转换为数字
select to_number(‘abc’)
from dual;
to_date 把字符转换为日期
.TO_DATE(char, [‘fmt’]):例如
select TO_DATE (‘10-September-1992’,’dd-Month-YYYY’) from dual
.使用format的元素格式 
例如:
select to_date(‘10-12-2016’,’dd-mm-yyyy’)
from dual;
select to_date(‘25-5月-95‘,‘dd-month-yy‘)
from dual;
//session语言环境设置为英文下面可以运行
select to_date(‘25-MAY-95‘,‘dd-MONTH-yy‘)
from dual;
这个是不能改用什么连接的
oracle数据库中表示一个日期数据的几种方式
1.sysdate
2.oracle默认的日期格式 例如:‘25-MAY-95‘
3.to_date函数转换
oracle中extract()函数从oracle 9i中引入,用于从一个date或者interval类型中截取到特定的部分
//语法如下:
EXTRACT (
{ YEAR | MONTH | DAY | HOUR | MINUTE | SECOND }
| { TIMEZONE_HOUR | TIMEZONE_MINUTE }
| { TIMEZONE_REGION | TIMEZONE_ABBR } FROM { date_value | interval_value } )
//我们只可以从一个date类型中截取 year,month,day(date日期的格式为yyyy-mm-dd);
//我们只可以从一个 timestamp with time zone 的数据类型中截取TIMEZONE_HOUR和TIMEZONE_MINUTE;
select extract(year from date‘2011-05-17‘) year from dual;
YEAR
----------
2011
select extract(month from date‘2011-05-17‘) month from dual;
MONTH
----------
5
select extract(day from date‘2011-05-17‘) day from dual;
DAY
----------
17
//获取两个日期之间的具体时间间隔,extract函数是最好的选择
select extract(day from dt2-dt1) day
,extract(hour from dt2-dt1) hour
,extract(minute from dt2-dt1) minute
,extract(second from dt2-dt1) second
from (
select to_timestamp(‘2011-02-04 15:07:00‘,‘yyyy-mm-dd hh24:mi:ss‘) dt1
,to_timestamp(‘2011-05-17 19:08:46‘,‘yyyy-mm-dd hh24:mi:ss‘) dt2
from dual)
/
DAY HOUR MINUTE SECOND
102 4 1 46
–
select extract(year from systimestamp) year
,extract(month from systimestamp) month
,extract(day from systimestamp) day
,extract(minute from systimestamp) minute
,extract(second from systimestamp) second
,extract(timezone_hour from systimestamp) th
,extract(timezone_minute from systimestamp) tm
,extract(timezone_region from systimestamp) tr
,extract(timezone_abbr from systimestamp) ta
from dual
/
YEAR MONTH DAY MINUTE SECOND TH TM TR TA
2011 5 17 7 14.843 8 0 UNKNOWN UNK
//
EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT … FROM…), 我将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
Exists是子查询的一种条件形式,通过判断Exists的选择表达式(括号内的部分)的结果,如果存在一行或多行结果记录,则Exists整个子查询结果为真,否则为假。由于我们采用Exists来实现子查询,只需要关心是否存在满足条件的记录,所以选择表达式的选择列表采用*来实现,当然,你也可以在选择列表指明具体的某些列,但这些列将在整个搜索过程中被忽略。
Exists实例
SQL 代码
select Resc_id from dbo.Res_Coach
where EXISTS (select * from Res_Coach where Resc_id is null)
查询原理:
遍历dbo.Res_Coach每一条,同时处理where条件(EXISTS (select * from Res_Coach where Resc_id=0) 判断结果为true或者false),为true时拿出该条,false时,放弃该条记录。
SQL 代码
– 1、 where条件中的子查询和主查询没关系
select Resc_id
from dbo.Res_Coach
where EXISTS (select Rese_id from dbo.Res_Excellent where Rese_id Is null )
– 2、 where条件中得子查询和主查询有关系
select Resc_id
from dbo.Res_Coach
where EXISTS (select Resc_id from dbo.Res_Coach where Resc_id Is null )
实例备注:不管where条件中得子查询和主查询有没有关系,遍历主查询中得每一条时,判断where条件,exists结果为真,where条件返回true,拿出该条记录,where条件返回false, 不返回该记录。
Exists 和 In 的选择
如果查询的两个表大小相当,那么用in和exists差别不大。如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
运行project后后台报错:
org.springframework.jdbc.BadSqlGrammarException: StatementCallback; bad SQL grammar [select wmsys.wm_concat(RoleID) from dlsys.tcrole a,dlsys.tcUnit b,dlsys.tcHuman c where a.UnitID = b.UnitID and b.UnitID = c.UnitID and c.HumanID = 161 and RoleID not in(152)]; nested exception isJava.sql.SQLException: ORA-00904: “WMSYS”.”WM_CONCAT”: 标识符无效
原因:
11gr2和12C上已经摒弃了wm_concat函数,当时我们很多程序员在程序中确使用了该函数,导致程序出现错误,为了减轻程序员修改程序的工作量,只有通过手工创建个wm_concat函数,来临时解决该问题,但是注意,及时创建了该函数,在使用的过程中,也需要用to_char(wm_concat())方式,才能完全替代之前的应用。
解决办法:
一.解锁sys用户
alter user sys account unlock;
二.创建包、包体和函数
以sys用户登录数据库,执行下面的命令
CREATE OR REPLACE TYPE WM_CONCAT_IMPL AS OBJECT
-- AUTHID CURRENT_USER AS OBJECT
(
CURR_STR VARCHAR2(32767),
STATIC FUNCTION ODCIAGGREGATEINITIALIZE(SCTX IN OUT WM_CONCAT_IMPL) RETURN NUMBER,
MEMBER FUNCTION ODCIAGGREGATEITERATE(SELF IN OUT WM_CONCAT_IMPL,
P1 IN VARCHAR2) RETURN NUMBER,
MEMBER FUNCTION ODCIAGGREGATETERMINATE(SELF IN WM_CONCAT_IMPL,
RETURNVALUE OUT VARCHAR2,
FLAGS IN NUMBER)
RETURN NUMBER,
MEMBER FUNCTION ODCIAGGREGATEMERGE(SELF IN OUT WM_CONCAT_IMPL,
SCTX2 IN WM_CONCAT_IMPL) RETURN NUMBER
);
/
–定义类型body:
CREATE OR REPLACE TYPE BODY WM_CONCAT_IMPL
IS
STATIC FUNCTION ODCIAGGREGATEINITIALIZE(SCTX IN OUT WM_CONCAT_IMPL)
RETURN NUMBER
IS
BEGIN
SCTX := WM_CONCAT_IMPL(NULL) ;
RETURN ODCICONST.SUCCESS;
END;
MEMBER FUNCTION ODCIAGGREGATEITERATE(SELF IN OUT WM_CONCAT_IMPL,
P1 IN VARCHAR2)
RETURN NUMBER
IS
BEGIN
IF(CURR_STR IS NOT NULL) THEN
CURR_STR := CURR_STR || ‘,‘ || P1;
ELSE
CURR_STR := P1;
END IF;
RETURN ODCICONST.SUCCESS;
END;
MEMBER FUNCTION ODCIAGGREGATETERMINATE(SELF IN WM_CONCAT_IMPL,
RETURNVALUE OUT VARCHAR2,
FLAGS IN NUMBER)
RETURN NUMBER
IS
BEGIN
RETURNVALUE := CURR_STR ;
RETURN ODCICONST.SUCCESS;
END;
MEMBER FUNCTION ODCIAGGREGATEMERGE(SELF IN OUT WM_CONCAT_IMPL,
SCTX2 IN WM_CONCAT_IMPL)
RETURN NUMBER
IS
BEGIN
IF(SCTX2.CURR_STR IS NOT NULL) THEN
SELF.CURR_STR := SELF.CURR_STR || ‘,‘ || SCTX2.CURR_STR ;
END IF;
RETURN ODCICONST.SUCCESS;
END;
END;
/
--自定义行变列函数:
CREATE OR REPLACE FUNCTION wm_concat(P1 VARCHAR2)
RETURN VARCHAR2 AGGREGATE USING WM_CONCAT_IMPL ;
/
三.创建同义词并授权
create public synonym WM_CONCAT_IMPL for sys.WM_CONCAT_IMPL
/
create public synonym wm_concat for sys.wm_concat
/
grant execute on WM_CONCAT_IMPL to public
/
grant execute on wm_concat to public
/
已经实践过证明可行再使用该函数的时候不能带用户名
create table test(id number,name varchar2(20));
insert into test values(1,‘a‘);
insert into test values(1,‘b‘);
insert into test values(1,‘c‘);
insert into test values(2,‘d‘);
insert into test values(2,‘e‘);
insert into test values(3,‘f‘);
insert into test values(3,‘g‘);
四.使用子定义的wm_concat
select id,wm_concat(name) from test group by id;
使用方法:
1、比较大小
select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; --取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
例如:
变量1=10,变量2=20
则sign(变量1-变量2)返回-1,decode解码结果为“变量1”,达到了取较小值的目的。
其实decode第一参数是if判断语句的第一个参数,第二个参数是if判断语句的第二个参数
If(12-12==-1)else
12
if else(12-12==1)else
1….
1、插入测试数据
insert into student_score (name,subject,score)values(‘zhang san‘,‘Chinese‘,90);
insert into student_score (name,subject,score)values(‘zhang san‘,‘Mathematics‘,80);
insert into student_score (name,subject,score)values(‘zhang san‘,‘English‘,79);
测试一:
select name,subject,decode(subject, ‘Chinese‘,score,0) from student_score;
结果如下:
如果是中文课程的话, 显示分数, 其他课程分数为零。
这条SQL 看上去使用意义不大。
测试二:
select name,sum(decode(subject, ‘Chinese‘,score,0)) as CHINESE from student_score group by name;
统计中文课程的分数。看上去有点意义。
总体看来, decode 的使用看上去和case when 有点类似。如果只是用作以上两种状况,看上去意义不大。
select name,sum(decode(subject, ‘Chinese’,score,0)) as CHINESE from student_score group by name;
select name,score as CHINESE from student_score;
使用的两句使用后的效果一样,看上去使用decode 多此一举。
2、行转列-有意义的使用
往以上table 再插入一些其他学生的成绩:
insert into student_score (name,subject,score)values(‘li shi‘,‘Chinese‘,96);
insert into student_score (name,subject,score)values(‘li shi‘,‘Mathematics‘,86);
insert into student_score (name,subject,score)values(‘li shi‘,‘English‘,76);
insert into student_score (name,subject,score)values(‘wang wu‘,‘Chinese‘,92);
insert into student_score (name,subject,score)values(‘wang wu‘,‘Mathematics‘,82);
insert into student_score (name,subject,score)values(‘wang wu‘,‘English‘,72);
使用以下SQL:
select name,
sum(decode(subject, ‘Chinese‘, nvl(score, 0), 0)) "Chinese",
sum(decode(subject, ‘Mathematics‘, nvl(score, 0), 0)) "Mathematics",
sum(decode(subject, ‘English‘, nvl(score, 0), 0)) "English"
from student_score
group by name;
将行的数据转化为列, 是不是很有意义了。
使用case then 也可以达到相同的效果。
select name,
sum(case when subject=‘Chinese‘
then nvl(score,0)
else 0
end) "Chinese",
sum(case when subject=‘Mathematics‘
then nvl(score,0)
else 0
end) "Mathematics",
sum(case when subject=‘English‘
then nvl(score,0)
else 0
end) "English"
from student_score
group by name;
概念:所谓多表查询,又称表联合查询,即一条语句涉及到的表有多张,数据通过特定的连接进行联合显示。
语法: select column_name,....
from table1,table2
条件。。。。
学前须知:
笛卡尔积
在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y.
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
在数据库中,如果直接查询俩张表,那么其查询结果就会产生笛卡尔积
例如:
select *from 表1,表2;
链接查询分类:
为了避免笛卡尔基的产生,我们可以使用连接查询来解决这个问题。
连接查询分为:
1、等值连接
2、不等值连接
3、外连接
a)左外连接
b)右外连接
c)全链接
4、自链接
1、等值连接:
利用一张表中的某个列的值和另外一张表中的某个列的值相等的关系,把两张表连接起来
语法:
select tb_name.col_name,tb_name.col_name,...
from tb_name,tb_name,...
where tb_name.col_name = tb_name.col_name
and
tb_name.col_name = tb_name.col_name
...

需求:查看每个员工的id,last_name以及所属部门名称
(要用别名,就用表的别名,在用列明名的话会有问题的) 
需求:查找员工工资所属的等级名称
如果想使用关键字进行连接查询在from后面写join on(on想当与where)

2、不等值连接
使用的是除=以外的操作符号的多表查询
例如:使用between and
select t1.col_name,t2.col_name
from t1,t2
where t1.col_name between t2.col_name
and t2.col_name;
3、外连接
Outer是可以省略的。加号放在值少的一方,就可以让少的一方值显示,一般来说+所在列的位置,的相反位置就是当前的连接是什么连接!反过来
当使用一个表的记录在另外一张表中不存在的时候,我们仍旧需要显示,使用外链接就可以了
平常规律:加号写法跟在
外连接分为:
右外连接(right join/rigth outer join)
左外连接(right join/left outer join)
全外连接(full join /full outer join)
右外连接的语法:
Select
这是是Join right的写法,join left是反过来的,就不写了

这个是+的写法 
加号只能写一个,写两个不代表全部外连接; 
全外连接:就是两个表中不存在的都不会显示
4、自链接
自己和自己连
5、集合连接
:对查询结果集的操作。
union:将上下结果取并集,去除掉重复的记录(重复的只显示一次)
union all:将上下结果全部显示
minus:取差集 A-B
可以用来做分页查询
intersect:取交集(取相同的结果
以上前提条件是:两个结果集中查询的列要完全一致。
6、oracle伪列 rownum
伪列rownum,就像表中的列一样,但是在表中并不存储。伪列只能查询,不能进行增删改操作。它会根据返回的结果为每一条数据生成一个序列化的数字。rownum是oracle才有的伪列
在 Oracle 里面 ROWNUM 主要有可以完成两个任务:
· 取得第一行数据;
· 取得前 N 行数据。 范例:查询第一行数据
rownum 只能等于1 如果让其等于其他数 则查不到数据
例如:
select last_name
from s_emp
where rownum=1
范例:查询前 N 行记录
rownum 大于0 可以查到所有的数 如果让其大于其他数 则查不到数据
例如:
select last_name
from s_emp
where rownum>0
rownum 可以小于任何数
例如:
select last_name
from s_emp
范例:取出 emp 表之中的 5~10 条
SELECT * FROM (
SELECT empno,ename,job,ROWNUM rn
FROM emp
WHERE ROWNUM<=10) temp
WHERE temp.rn>5 ;
7、Oracle伪列RowID
现在每一行的记录都发现有自己的数据列,而除了这些数据列之外,还存在有每一行数据的唯一的物理地址,而这 个物理地址就只能够通过 ROWID 取得。
那么每一个 ROWID 数据都是包含有存储数据的,以:“AAAR3qAAEAAAACHAAC”为例做一个简单解释:
· “AAAR3q”:数据的对象编号;
· “AAE”:数据保存的相对文件编号;
· “AAAACH”:数据保存的块号;
· “AAC”:保存的数据行号。 数据库之中的所有数据都是在磁盘之中,保存,所以来讲,根据不同的数据会分配不同的空间,而 ROWID 就可以清楚的记录这些空间的信息。
面试题:现在有一张数据表,由于设计的时候缺少一些限制,同时后期使用的过程之中出现了大量的重复数据,要求将重复的数据删除掉,只保留最原始增加的数据。 准备过程:
1、 为了方便观察问题,首先将 dept 表复制为 mydept 表;
CREATE TABLE mydept AS SELECT * FROM dept ;
2、 观察现在的 mydept 表之中的数据和 ROWID(这个时候的数据就是最重要保存的数据)。
SELECT ROWID ,deptno,dname,loc FROM mydept ;
4、向 mydept 数据表之中增加重复数据。
INSERT INTO mydept(deptno,dname,loc) VALUES (10,‘ACCOUNTING‘,‘NEW YORK‘) ;
INSERT INTO mydept(deptno,dname,loc) VALUES (10,‘ACCOUNTING‘,‘NEW YORK‘) ;
INSERT INTO mydept(deptno,dname,loc) VALUES (30,‘SALES‘,‘CHICAGO‘) ;
INSERT INTO mydept(deptno,dname,loc) VALUES (30,‘SALES‘,‘CHICAGO‘) ;
5、
INSERT INTO mydept(deptno,dname,loc) VALUES (30,‘SALES‘,‘CHICAGO‘) ;
正式问题:
将 mydept 表之中现在所有的重复删除掉,保留最早增加的数据。
SELECT ROWID ,deptno,dname,loc FROM mydept ;

解决问题:
1、在 mydept 表之中可以发现重复数据,而且重复数据都重复的很有规律,在 deptno、dname、loc 都重复,于是换个思路,查询出所有数据之中最早的 ROWID,(MIN(ROWID))
SELECT deptno,dname,loc,MIN(ROWID) FROM mydept GROUP BY deptno,dname,loc ;
2、 不在此范围的数据删除就行了,使用 NOT IN,而且之前的查询返回的是多行单列。
DELETE FROM mydept WHERE ROWID NOT IN ( SELECT MIN(ROWID) FROM mydept GROUP BY deptno,dname,loc) ;

PS:如果你没遇见此类题目,那么你就不用复习了,如果觉得会遇见,你就好好看。
在以后的分析之中,ROWID 依然会出现,只需要记住,ROWID 就像身份证一样,是作为一行具体数据的唯一的物 理标记出现的。
1.Rowid的显示形式
我们从rowid伪列里select出来的rowid是基于base64编码,一共有18位,分为4部分:
OOOOOOFFFBBBBBBRRR
其中:
OOOOOO: 六位表示data object id,根据object id可以确定segment。关于data object id和object id的区别,请参考http://www.orawh.com/index.php/archives/62
FFF: 三位表示相对文件号。根据该相对文件号可以得到绝对文件号,从而确定datafile。关于相对文件号和绝对文件号,请参考http://blog.itpub.net/post/330/22749
BBBBBB:六位表示data block number。这里的data block number是相对于datafile的编号,而不是相对于tablespace的编号。
RRR:三位表示row number。
Oracle提供了dbm_rowid来进行rowid的一些转换计算。
SQL> create table test(id int,name varchar2(30));
Table created.
SQL> insert into test values(1,’a’);
1 row created.
SQL> commit;
Commit complete.
SQL> select rowid from test;
AAAGbEAAHAAAAB8AAA
SQL> select dbms_rowid.rowid_object(rowid) obj#,
2 dbms_rowid.rowid_relative_fno(rowid) rfile#,
3 dbms_rowid.rowid_block_number(rowid) block#,
4 dbms_rowid.rowid_row_number(rowid) row#,
5 dbms_rowid.rowid_to_absolute_fno(rowid,’SYS’,’TEST’) file#
6 from test;
OBJ# RFILE# BLOCK# ROW# FILE#
26308 7 124 0 7
2. 如何从rowid计算得到obj#,rfile#,block#,row#
rowid是base64编码的,用A~Z a~z 0~9 + /共64个字符表示。A表示0,B表示1,……,a表示26,……,0表示52,……,+表示62,/表示63可以将其看做一个64进制的数。
所以,
obj#=AAAGbE=6*64^2+27*64+4=26308
rfile#=AAH=7
block#=AAAAB8=64+60=124
row#=AAA=0
3. 如何从obj#,rfile#,block#,row#计算得到rowid
实际上就是将十进制数转化成64进制数,当然,从二进制转化的规则比较简单点。
将二进制数从右到左,6个bit一组,然后将这6个bit组转成10进制数,就是A~Z a~z 0~9 + /这64个字符的位置(从0开始),替换成base64的字符即可。
obj#=26308=110 011011 000100=6 27 4=G b E,补足成6位base64编码,左边填0,也就是A,结果为AAAGbE
rfile#=7=111=7=H,补足成3位,得到AAH
block#=124=1 111100=1 60=B 8,补足成6位,得到AAAAB8
row#=0,3位AAA
合起来就是AAAGbEAAHAAAAB8AAA
4. Rowid的内部存储格式
虽然我们从rowid伪列中select出来的rowid是以base64字符显示的,但在oracie内部存储的时候还是以原值的二进制表示的。一个扩展rowid采用10个byte来存储,共80bit,其中obj#32bit,rfile#10bit,block#22bit,row#16bit。所以相对文件号不能超过1023,也就是一个表空间的数据文件不能超过1023个(不存在文件号为0的文件),一个datafile只能有2^22=4M个block,,一个block中不能超过2^16=64K行数据。而一个数据库内不能有超过2^32=4G个object。
SQL> select dump(rowid,16) from test;
DUMP(ROWID,16)
Base64编码说明
Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。 如果剩下的字符不足3个字节,则用0填充,输出字符使用’=’,因此编码后输出的文本末尾可能会出现1或2个’=’。
为了保证所输出的编码位可读字符,Base64制定了一个编码表,以便进行统一转换。编码表的大小为2^6=64,这也是Base64名称的由来。
概念:
所谓组查询即将数据按照某列或者某些列相同的值进行分组,然后对该组的数据进行组函数运用,针对每一组返回一个结果。
note:
1.组函数可以出现的位置: select子句和having 子句
2.使用group by 将将行划分成若干小组。
3.having子句用来限制组结果的返回,只能出现在Group by语句中。
语法:
select ...
from ...
where ...
group by col_name,col_name
having ...
order by...
group by col_name:即将数据按照col_name相同值进行分组
组函数
常见有5个:
avg:求平均值
count:求总数
max:最大值
min:最小值
sum:求和
stddev:求标准差
ariance:求方差
avg([distinct] column )/sum([distinct] column) :可以作用在存储数字数据的列上。
max(),min():可以作用在任意类型的数据之上。
对字符型数据的最大值,是按照首字母由A~Z的顺序排列,越往后,其值越大。当然,对于汉字则是按照其全拼拼音排列的,若首字符相同,则比较下一个字符,以此类推。
count([distinct] column | *) :
count(*) : 统计表中所有的行数
count(column) : 返回所有非空行的行数
练习:
查看各个部门的最高工资 
查看各个部门的员工数 
查看各个部门的平均工资 
查看各个部门的最低工资
group by 子句:(注意:如果select查询语句中有组函数出现,并且还查询了其他的列,则此列必须出现在group by子句中!!)
1.用来将表中的行划分成若干更小的组
2.出现在select子句中,但是没有出现在组函数中的列必须出现在group by子句中
3.出现在group by中的列不一定出现在select子句中。
4.group by子句中的列出现在select结果中,表意性比较强。
5.当group by子句中出现多列的时候,表示按照从左至右的顺序进行分组,即先按照第一列分组, 然后再第一列分好的组里面 按照第二列进行分组,以此类推。
6.限制组结果的返回一定使用having不能使用where。
需求:
1.查看各部门,职称相同的人的平均工资。 
2.查找部门平均工资>1000的所有部门的id和平均工资
目标: 部门id , avg(salary)
from : s_emp
分组: 部门平均工资
group by dept_id
组结果的返回:
部门平均工资>1000
组合: 
需求:查看所有部门的部门工资总和,按照部门工资的降序排序
having: 限制组结果的返回。
1.如果希望限制组结果的返回,那么直接使用having子句跟在group by 子句之后。
需求:查看部门平均工资大于1000的部门id 
需求:
1、查看职称不以VP开头的所有员工,
2.并且将他们以职称分组,
3.求各职称的工资总和,
4.将工资总合>5000的职称和工资总合显示出来。
1、排序Order By(注意:order by后面的元素可以给每一个指定升序和降序)
Order by语句始终位于select语句的最后面
2、order by后可以跟什么:
列名,列的别名,表达式,
排序不指明的会按照select后面的列名,按顺序排序
3、order by后面可以跟多列
表示先按第一列排序,
如第一列有相同值再按
第二列进行排序,如前二列
均有相同值,则按第三列进行排序…
4、默认是asc升序
指明desc是降序的
5、空值排序是最大的
升序排序的时候,空值放在最后
降序排序的时候,空值放在最前面的
6、出现在order by后面的列,不一定出现在select查询的列里面
所谓子查询,就是一个select语句中嵌套了另外一个或者多个select语句
应用场景:
1、一条查询语句的查询条件依赖另外一条查询语句的查询结果
2、一条查询的结果作为另外一个查询语句的查询表(查询依据,也就是和1是反过来)
3、在DML操作中使用查询(后期介绍)
子查询的基本原则:
1、在查询中可以有单行查询和多行子查询。
2、在子查询中可以出现操作符的左边或者右边
3、子查询在很多的sql命令中都可以使用。
4、嵌套查询(子查询)先执行,然后将结果递给主查询。
一、比较值不确定,需要另外一个select语句执行后才能得到,使用子查询
语法:
select ...
from ...
where col_name 比较操作符 (
select ...
from ...
where ...
group by ...
having...
)
group by ...
having...
order by ...
1、单值子查询:子查询的结果为1个
需求:
1.查询和Simith职称相同的所有员工的last_name和职称
分析步骤:
1.确定最终查询结果(目标/主查询):查询员工的last_name和title
from : s_emp
条件 : title = Smith的职称
select last_name,title
from s_emp
where title = ?
2.确定条件(子查询):Smith的职称
from : s_emp
条件 :last_name = ‘Smith‘;
select title
from s_emp
where last_name = ‘Smith‘;
3.组合
2.查看工资大于Chang员工工资的所有员工的id和名字。
3.查看员工工资小于平均工资的所有员工的id和名字
例如:查找和Smith同一个部门的员工的id和last_name
1.最终查询目标 : 员工的id,last_name
from : s_emp
查询条件: s_emp.dept_id = Smith所在部门id
select id,last_name
from s_emp
where s_emp.dept_id = ?;
2.子查询的目标:部门id
from s_emp
where last_name = ‘Smith‘;
select dept_id
from s_emp
where last_name = ‘Smith‘;
3. 组合:
2、多值子查询:子查询的结果为多个
需求:
1.查询所在区域为2号区域的所有部门的员工的id和last_name
1.确定最终查询结果: 员工的id, last_name
from : s_emp
条件 :s_emp.dept_id in (?);
select id,last_name
from s_emp
where dept_id in ?
2.确定条件:所在区域为2号部门
子查询:部门id
from : s_dept
条件: region_id = 2;
select id
from s_dept
where region_id = 2;
3.组合:

问题:比如上面的题这样写,就会出现问题,他把所有dept_id不为空的全部打印出来了 
如果子查询的列写成了主查询的条件,不会报错!会把这个列不为空的查询出来
子查询出现情况二:
查询的内容作为一个表存在
语法:
select ....
from (select .... from ....) b
where ......
练习:查询各部门的id,name 和部门员工的平均工资
1、查询目标:
需要部门的id,部门的name ------ 从 s_dept表中
部门员工的平均工资 avg(salary) --------- salary只有s_emp表中有
条件 : 部门id,name和部门 员工,因此要求部门的id跟员工所在部门的id相等才 连接
select id,name, 平均工资
from s_dept , ?
where s_dept.id = ?.dept_id;
2、查询条件
select(dept_id,avg(salary) sal)
from s_emp
group by dept_id;
3、组合
3、子查询返回多行单列
如果说子查询返回的是多行单列数据,实际上就相当于提供了一个数据的查询范围。那么如果要想针对于范围查询, 则要使用三个判断符号:IN、ANY、ALL。
1、IN操作:
指的是在指定范围内。也可以使用 NOT IN 不在范围之内
2、ANY操作(不看)
=ANY:此功能和IN的操作完全相同
>ANY:比查询的最小值要大
<ANY:比查询的最大值要小
3、ALL操作(不看)
>ALL:此功能比子查询返回的最大值还要大
<ALL:此功能比子查询返回的最小值还要小
1、定义:运行的时变量可以让我们和sql语言之间有个交互,容许我们动态传递参数
2、语法 &var
3、运行时变量可以出现在任意位置
例如:
select &colName1,&colName2
from &tbName
where &colname = &colValue;
例如:
select id,last_name
from s_emp
where id = &id;
运行时,服务器会提示:
输入 id 的值:
当输入完成按下回车:
原值 3: where id = &id
新值 3: where id = 2
例如:
select id,last_name
from s_emp
where last_name = &name;
(直接这样写是不需要转义的) 
note:
1.&代表取值。&varName,代表取varName这个变量的值,如果这个变量值,之前不存在,那么系统会提示输入这个变量的值。如果存在,直接取值。
2.set verify on ,打开交互提示,如果打开,会显示old和new value。现在默认都是打开的。使用set verify off,关闭
4.定义变量:
define[def] varName = value; 
查看定义的变量:
define[def] [varName];
例如:
1. define name=zhangsan
定义一个变量名字为name,值为zhangsan
运行select语句时,如果语句中遇到&name会自动替换为zhangsan
例如:
select id,last_name
from s_emp
where last_name=‘&name‘;
只要变量存在的值,会被自动替换 
2.def/define : 查看当前环境中定义的所有变量 
3.def/define name : 查看变量name的值。
如果不想在select语句中&name的外边使用”,则可以在定义变量name时写成definename=”’zhangsan”’;‘可以用来转义’(其实写一个双引号,里面写一个单引号也是可以的”‘zhangsan’”)
存在def里面的值是这样的显示
5.使用accept用来定义带数据类型和提示符的变量
accept varName : 代表定义一个变量名字为varName,当按下回车时需要用户输入值。
accept varName dataType : 代表定义一个带数据类型的变量
例如:accept varNum number :代表定义一个变量名字为varNum,类型为Number,当输入类型不是数字类型是报错,提示继续输入。(类型要和你输入的类型保持一致,如果不设置类型默认的是字符) 
prompt:当输入变量时,给用户的提示信息。
accept myNum number prompt 区域id:
定义一个Number类型的变量myNum,当按下回车时提示区域id:
accept nyName char prompt 名字:(注意日期传的是当前系统的格式dd-mon-rr mon是简写的月份)
如果希望插入的值是隐藏的,可以在后边写上HIDE:
accept num number prompt 密码: HIDE
6.取消变量的定义(和define的取消是一样的)
undefine varName;
7.向脚本文件传递参数(也就是读取文件的时候,在后赋值)
在文件中参数使用&n(n代表数字)来表示取第几个参数值,然后再调用文件执行的时候使用
@file val….(多个参数值使用空格分开。)
文件内容 
SQL
当然比较方便的一种就是把,accept写到文件的开始,先提示用户赋值,然后在通过赋的值,找。
软件开发的步骤可大致分为:
1.需求分析
2.系统设计
3.编码实现
4.系统测试
5.运行维护
student 老师,辅导员class 多对一
sno name age gender id clsname 辅导老师,。。
1 1 jd1613 xxx
2 1 jd1613 xxx
系统设计中一个重要的环节就是数据库设计
数据库设计的时候需要先进行数据建模(实体关系图 E-R图)
数据建模的依据就是前期所做的需求分析
数据建模
1.Model of system in client’s mind
2.Entity model of client’s model
3.Table model of entity model
4.Tables on disk
实体-关系图
实体-关系图(Entity Relationship Diagram),也称为E-R图,提供了表示实体类型、属性和关系的方法,用来描述现实世界的概念模型。
构成E-R图的基本要素是实体、属性和关系
实体(Entity):实体用来表示具有相同特征和性质的事物(类似于java的类(域对象)),实体由实体名和实体属性来表示。
属性(Attribute):实体所具有的某一特性,一个实体可以有若干个属性
关系(Relationship):实体彼此之间相互连接的方式称为关系。一般可分为以下
3 种类型:
一对一关系 (1 ∶ 1)
这种关系比较少见
维护关系:随意选择一方构建外键
例如:Wife and Husband
w1 h1
wife husband
id name h_id id name
一对多关系 (1 ∶ N)
比较常见:
维护关系:在多的一方维护一方的标示列作为外键
比如:
student class
sno sname age c_id id name 老师
1 1
2 1
多对多关系 (M ∶ N)
维护关系:构建桥表
student(学生) course(课程)
sno sname c_id id name
student_course_brige
sno c_id
1 1
1 2
1 3
may-be 和 must-be
在实体与实体之间的关系中,都会存在着may-be和must-be这俩种情况,例如:系统中有订单和顾客俩个实体(N:1关系),一个顾客对应多个订单,一个订单对应一个顾客,而且一个顾客可(以may be)没有订单和他对应,一个订单一定(must be)会有顾客和它对应.
ER图中符号的表示
1) #:主要标识
(#):次要标识
2) * : 非空
#*:表示主键。
3) o : 可有可无
4) 虚线: may be 顾客这边虚线,顾客可能没有订单
5) 实线: must be 订单这边实线,订单一定是属于某个客户。
6) 竖杠(|): UID Bar代表要强制在(|)一方建立一个联合主键,将对方ID拿过来做联合主键
简单点说就是外键同时做了当前表的主键,也就是说|的这一方有两个主键。
7) 伞状图标代表多的一方,不是伞状图标则代表一的一方
自己和自己关联,比如经理自己 
数据库设计
数据建模完成之后,可以把ER图转换成数据中的表
1.实体的名字转换为表的名字
2.实体的属性转换为表中的列
3.具有唯一特点的属性设置为表中的主键
4.根据实体之间的关系设置为表中某列为外键列(主外键关联)
设计关系数据库时,遵从不同的规范要求,才能设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:
第一范式(1NF)
第二范式(2NF)
第三范式(3NF)
巴斯-科德范式(BCNF)
第四范式(4NF)
第五范式(5NF,又称完美范式)
注:满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了
第一范式:
一个表中,每个列里面的值是不能再分割的.
例如:我们设计的表中有一个列是:爱好
这个列的值可能会是这样:足球篮球乒乓球
但是这值是可以再分割的:足球、篮球、乒乓球
所以这种设计是不满足第一范式
第二范式:
第二范式是在满足第一范式的基础上
表中的非主键列都必须依赖于主键列
例如:
订单表: 订单编号 是主键
订单编号 订单名称 订单日期 订单中产品的生产地
这几个非主键列中,产品生产地是不依赖于订单编号的,所以这种设计是不满足第二范式
第三范式:
第三范式是在满足第二范式的基础上
表中的非主键列都必须直接依赖于主键列,而不能间接的依赖.
(不能产生依赖传递)
例如:
订单表: 订单编号 是主键
订单编号 订单名称 顾客编号 顾客姓名
顾客编号依赖于订单编号,顾客姓名依赖于顾客编号,从而顾客姓名间接的依赖于订单编号,那么这里产生了依赖传递,所以这个设计是不满足第三范式的
总之要保证每个表属于一个范畴,表里面的列要完全依赖主键,和主键有间接依赖关系的设置为外键而存在
联合主键联合外键只能是表级约束
主键:
1.能做主键的列必要满足非空唯一的特点
2.只要满足非空唯一的列都可以做主键
3.可以让表中一个有意义的列做主键,比如说学号,它既表示学生学号又作为表中的主键,因为这个列满足非空唯一的条件
4.也可以找一个没有意义的列做主键,就是用来唯一标识一行记录的
5.我们可以让多个列联合在一起做表中的主键,那么它就是联合主键,要求这几个列的值联合在一起是非空唯一的
外键:
1.表中的某一个列声明为外键列,一般这个外键列的值都会引用于另外一张表的主键列的值(有唯一约束的列就可以,不一定非要引用主键列)
2.另外一张表的主键列中出现过的值都可以在外键列中使用
3.外键列值也可以为空的,提前是这个外键列在表中不做主键,因为我们也可以把表中的外键列当做主键来使用(只有满足非空唯一的要求就可以)
4.如果把B表中的联合主键的值引用到A表中做外键,因为是俩个列在B表中做联合主键,那么A表引用过来的时候也要把俩个列的值都引用过来,那么它们在A表中就会作为一个联合外键出现
完整性约束:
实体完整性:主键非空且唯一
引用完整性:或者匹配主键的值或者为空
列级完整性:当前所定义列的类型,和长度是必须要遵守的
用户自定义:自定义规则,例如只能写男和女
Nn:代表not null
U:代表unique
Pk:代表primary key
Fk:代表foreign key 
建表:
1.映射实体—-表
2.映射属性—-列
3.添加约束
4.描述关系信息(外键)
1.oracle数据库中的多种数据结构:
1.表结构 存储数据
2.视图 一张表或多张表中数据的字节
3.sequence 主要用来生成主键值
4.index 提高检索性能
我们需要学会创建数据结构
2.表结构:
1.表结构可以随意创建
2.表结构不需要预先申请空间
3.可以在线修改。
3.创建语法:
创建表的释放有两种:基本操作 子查询
3.1基本操作
3.1.1 语法:
create table [schema.]tb_name(
col_name datatype [default value] [colum_constraints],
...,
[table_constraint],
...
);
note :
1.create table 关键字,固定写法,
schema,在oracle数据库中代表用户名
2.tb_name代表表名,可以自定义:但是需要遵循命名规则(详见3.1.2命名规则):
3.列名一般也要求遵循命名规则(详见3.1.2命名规则)
4.dataType,列所属的数据类型,详见(3.1.3 oracle支持的数据类型)
3.1.2 命名规则
1.字母开头
2.长度为1-30
3.只能有大小写英文,数字和_ $ #
4.同一个用户下的对象名不能重复
5.不能使用关键词作为表名(如:select group等等)
3.1.3 oracle支持的数据类型:
类型名 描述
VARCHAR2(size) 可变长字符串,
CHAR(size) 定长字符串
NUMBER 数字类型
NUMBER(p,s) 数字类型
DATE 日期类型
CLOB 字符大数据对象
BLOB 二进制大数据对象
note:
1.char,varchar2,varchar
用法:
char(size),varchar2(size) varchar(size)
size用来指明所能保存字符值的上限。
区别:char:定长字符
即一旦确定了()中的字符个数,在保存数据的时候,不论你保存的字符个数为多少个,所占空间大小为固定的()中的字符个数。
如char(2) 保存 a ab都占用2个字符空间
varchar , varchar2:不定长字符
即在保存数据的时候,会先判断字符个数,然后再分配对应的空间进行保存。
如varchar(2)
保存a 占用1字符空间
保存ab 占用两2字符空间
在oracle数据库中,指定变长字符串首选varchar2.
2.number(p,s):
p确定数字的有效位数
s确定数字的小数点位数
number(4,2)最大值和最小值为多少?
-99.99~99.99
3.date: 日期类型
系统默认日期类型:‘DD-MON-YY‘
操作字符类型和日期类型数据的时候,一定要放到‘‘中间
3.1.4 default:设置默认值
1.作用:设置在往表中插入数据时,如果没有指定该列的值,默认插入的值。
2.默认值可以是合法的字面值(根据定义的列的数据类型来赋值),表达式,或者是sysdate和user等合法的sql函数。
create table test(
start_date date default sysdate);
3.默认值不能使用其他表的列或者不存在的列/伪列
3.1.5 约束
定义:所谓约束就是强制表中的数据列必须遵循的一些规则。
而且如果表中存在依赖约束,可以阻止一些不合理的删除操作。
分类:
表级约束:定义在表级别的约束(即在列的完整定义完成后,才定义的约束)
column dataType ,
unique(column)
列级约束:直接跟在列完整性定义后边的约束
column dataType unique,
种类:
约束名 描述 分类
NOT NULL :非空 列级
UNIQUE :唯一 列级/表级
PRIMARY KEY :主键 列级/表级
FOREIGN KEY :外键 列级/表级
CHECK :自定义 列级/表级
创建时间:
1.创建表的同时定义约束
2.表创建完成之后,通过修改表结构(后期章节描述)
创建语法:
列级:
column [CONSTRAINT constraint_name] constraint_type,
表级:
column,...(列完整定义结束)
[CONSTRAINT constraint_name] constraint_type (column, ...),....
详细介绍:
1.not Null:值不允许为null,阻止null值输入
note:只能是列级约束
例如:
create table test( id number constraint test_nn_id not null);
create table test( id number not null);
2.unique:唯一值约束,要求值必须唯一,不能重复。
note:
1.可以设置单列唯一,或者组合列唯一
2.如果unique约束单列,此列可以为null
3.可以是列级,也可以是表级约束
4.对于unique列,oracle会自动创建唯一值索引。
例如:
create table test(id number constraint test_un_id unique);
也可以这样写
create table test(
id number,
constraint test_un_id unique(id)
);
create table test(id number unique);//代表不能同时相同,联合唯一!
create table test(
id number,
name varchar2(10),
constraint test_un_id_name unique(id,name)
);
create table test(
id number,
name varchar2(10),
unique(id,name)
);
3.1.6 Primary key:主键
note:
1.主键用来给表中的每一行数据设置唯一标识符。主键只能有一个。
2.主键可以是单列,也可以是组合列。
3.强制非空且唯一,如果由多列组成,组合唯一且列的每一部分都不能为null。
4.可以表级,可以列级。
5.自动创建唯一值索引。
例如:
create table test(id number constraint test_pk_id primary key);
create table test(
id number,
constraint test_pk_id primary key(id)
);
//列级定义
create table test(id number primary key);
//表级定义
//可以联合主键
create table test(
id number,
name varchar2(10),
constraint test_pk_id_name primary key(id,name)
);
create table test(
id number,
name varchar2(10),
primary key(id,name)
);
3.1.7 .foreign key:外键
一般在设计表与表之间的关系时,为了减少数据冗余,一般做的操作是在其中一张表中设置 一列(组合列),这一列(组合列)的值可以唯一的确定另外一种表中和当前表相关联的一行数据。那么这个列成为外键。
note:
1.可以是单列,也可以是组合列
2.引用当前表或者其他表中(只要想和当前表建立关系的表) 的主键列或者unique列
3.可以是表级别/列级别
4.值必须是引用的列的值或者为null
5.有外键约束时,如果想要删除的父表(被引用的表)中的某一条数据时,必须保证在子表(引用表)中没有和这条数据相关联的数据存在。
6.ON DELETE CASCADE ,指明在删除父表中数据时可以级联删除子表中数据
例如:
create table emp(id number primary key);---->父表
1:m/m:1
create table test(
id number constraint test_fk_emp_id references emp(id));
1:1
create table test(id number references emp(id) unique);
create table test(
id number,
constraint test_fk_emp_id foreign key(id) references emp(id)
);
create table test(id number references emp(id));
create table emp(
id number,
name varchar2(10),
primary key(id,name)
);
//这里需要注意的是,如果是联合主键,要引用的表只需要引用其中一个作为 //主键或者unique的列,但是他作为两个存在!,这时在引用的时候就必须, //引用两个。
create table test(
id number,
name varchar2(10),
constraint test_fk_emp_id_name foreign key(id,name)
references emp(id,name)
);
create table test(
id number,
name varchar2(10),
foreign key(id,name) references emp(id,name) on delete cascade
);
3.1.8 check : 自定义约束,定义每一行必须遵循的规则
note:
1.可以是表级/列级约束
例如:
create table test(
gender varchar2(2) constraint test_check_gender check(gender in (‘F‘,‘M‘)),
age number check (age>=15 and age<=20)
);
create table test(
gender varchar2(2),
constraint test_check_gender check(gender in (‘F‘,‘M‘))
);
create table test(
gender varchar2(2),
check(gender in (‘F‘,‘M‘))
);
子查询建表
一般使用子查询建表,要将另外一张表中的某些数据存放到一张新的表格中。(相当于将原来打印在控制台上的信息,现在直接定义成一张新的表格。)
语法:
create table tb_name[(column,...)]
as
select ...
复制一个表的指定列数,或者全部 
note:
1.在用子查询建表时,只有not Null约束会被复制。
2.创建表时可以指定列名,也可以不指定,但是一定不指定列的数据类型
3.创建表的列跟子查询表的列数要保持一致
5、常见数据类型
数据表的组成就是行和列的 集合,而且每一列 都有其对应的类型 ,所以在进行数据 表创建之前,首先 需要来了解一 下在系统之中常用的数据类型。
虽然 BLOB 字段可以保存电影数据,但是一般正常人没人这么做。而且在一般的开发之中,99%选用的数据类型:
VARCHAR2(VARCHAR)、NUM BER、DATE、CLOB(像 VARCHAR 一样的方式操作)。
6、闪回操作(理解)
从 Oracle 10 g 起为了方便用户进行数据表的恢复。为 Oracle 增加了一个类似 于 windows 的回收站功能,等于是所有 删除是数据表,首先保存在回收站之中,如果用户有需要也可以进行恢复。
范例: 查看回收站
show recyclebin ;
在回收站里面可以发现所有被删除的数据表。
从 Oracle 11g 开始为了方便用户查看数据,提供了一个 SQL Develop er 工具,但是此工具需要配置 java 环境。
JDK 目录:D:\ap p \Teacher\p roduct\11.2.0\dbhome_1\jdk\bin\java.exe 
进入到工具之后首先需要配置一个 scott/tiger 用户的数据库连接。
范例: 通过回收站恢复 emp 10 数据表
FLASHBACK TABLE emp 10 TO BEFORE DROP ;
范例: 彻底删除数据表,不让删除的数据表经过回收站,在删除语句之后增加一个 PURGE DROP TABLE emp 10 PURGE ;
范例: 删除回收站之中的一个表
PURGE TABLE emp null ;
范例: 清空回收站
PURGE RECYCLEBIN ;
对于闪回技术,只需要有一定的了解即可,而且也只有 oracle 有此特性。
7、表空间 
1、创建表空间
/分为四步 /
/第1步:创建临时表空间 /
create temporary tablespace user_temp
tempfile ‘D:\oracle\oradata\Oracle9i\user_temp.dbf‘
size 50m
autoextend on
next 50m maxsize 20480m
extent management local;
/第2步:创建数据表空间 /
create tablespace user_data
logging
datafile ‘D:\oracle\oradata\Oracle9i\user_data.dbf‘
size 50m
autoextend on
next 50m maxsize 20480m
extent management local;
/第3步:创建用户并指定表空间 /
create user username identified by password
default tablespace user_data
temporary tablespace user_temp;
/第4步:给用户授予权限 /
grant connect,resource,dba to username;
2、表数据库实例表空间联系
1、数据库
数据库顾名思义是数据的集合,而Oracle则是管理这些数据集合的软件系统,它是一个对象关系型的数据库管理系统。
2、表空间
表空间是Oracle对物理数据库上相关数据的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构。每个数据库至少有一个表空间(称之为system表空间)。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。
3、实例
每一个运行中的数据库都对应着一个Oracle实例。当服务器上的Oracle数据库启动时,Oracle首先会在内存中分配一片区域-称之为System Global Area(SGA),然后启动一个或多个的Oracle进程。
SGA和这些进程合起来就称为一个Oracle的实例。实例中的内存和进程管理器用来高效地访问数据库的数据,同时为单个或多个的用户提供服务。
一个数据库可以由多个实例打开,但任何时刻一个实例只能打开一个数据库。多个实例可以同时运行在同一个机器上,它们彼此访问各自独立的物理数据库。
1、字典,就是用来帮助人们查看一些信息,查看一些内容
2、数据字典的概述:
a)数据字典在数据库被创建的时候被创建。
b)被数据库服务器自动更新和维护
c) Oracle的数据字典就是oracle存放有关数据信息的地方,用途就是用来描述数据的
d) 比如一个表的创建者信息,创建时间信息,所属空间的信息,用户权限信息等。
e) 数据库字典是一组表和视图结构,他们存放在system表的空间里面
f) 当用户对数据库中的数据进行操作的时候遇到困难就可以访问数据字典来查看详细的信息
3、用户可以通过sql语句访问
Select table_name from dictionary
根据查询结果的不同按照前缀分为四类!
1、以user开头的数据字典:
包含用户拥有的相关的对象信息。能够查到对象的所有者是当前的所有对象
user_tables;
user_views;
user_sequences;
user_constraints;
2、以all开头的数据字典:
能够查询当前能所有有访问权限的对象信息
3、当dba开头的数据字典:
只能有dba权限的用户查询,能查到数据库中所有的对象。
4、以v$开头的是动态服务性能视图。
4、数据字典内容包括:
1,数据库中所有模式对象的信息,如表、视图、簇、及索引等。
当前的用户对象的信息存放在user_objects表中
2,分配多少空间,当前使用了多少空间等。
3,列的缺省值。
4,约束信息的完整性。
5,Oracle用户的名字。
6,用户及角色被授予的权限。
7,用户访问或使用的审计信息。
8,其它产生的数据库信息。
例如:
1.查看当前用户的拥有的对象名和对象类型
Select Object_name ,Object_type from user_objects;

2、查看当前用户下的所有表
Select table_name from user_tables;
3、查看当前用户所定义的所有的约束的姓名和类型
Select constraint_name,constraint_type table_name,R_OWNER
From user_constraints
Where table_name = ‘S_EMP’;
查询是e_emp表的所有约束
4、查找约束姓名和关联列的名字
Select constraint_name,column_name
From user_cons_columns
Where table_name =’S_EMP’;
数据操作语言:
insert update delete
事务控制语言:
commit :提交事务
rollback :回滚事务
Savepoint:设置回滚点
1.insert语句
两种格式:
直接插入
子查询插入
直接插入基本语法:
insert into tb_name[(col_name,...)]
values(val1,....);
note:
1.如果给每个列都插入数据,可以省略table后边的列,并且插入值的顺序和定义表的顺序一致
2.如果插入的顺序和表定义的顺序不同,或者只插入某几列的值table_name后边必须跟上列名
3.字符串和日期类型的值必须使用‘’引起来
4.insert语句一次只插入一条数据
5.插入的值可以使用系统函数,例如---user,sysdate
6.插入的值可以使用运行时参数。
例如:
create table test(
id number primary key,
name varchar2(10),
gender varchar2(2) check (gender in (‘F‘,‘M‘)),
birthday date);
插入:
1.insert into test(id,name) values (3,‘zs‘); //传统的指明了赋值,但非空值必须赋值
2.insert into test(id,name,birthday) values
(1,‘lisi‘,‘09-9月-10‘);
3. insert into test(id,name,birthday) values //可以使用预定义参数
(2,user,sysdate);
4. insert into test(id,name,birthday) values //可以进行参数传值
(&id,‘ss‘,sysdate);
2.使用子查询插入,
和子查询创建不同的是,这里不需要as 关键字,并且不需要出现values
insert into table_name[(col_name,....)]
select .......
note:
1.不出现values关键字
2.插入的列的名字和子查询返回结果的列相匹配。
例如:
1. insert into test2
select * from test;
2. insert into test2(id,gender,name,birthday)
select id,gender,name,birthday from test;
2.delete语句:
语法:delete [from] tbl_name [where option…]
note:在加外键约束的时候,如果想在删除主表的记录的同时对外键表中已经存在的关联关系记录进行操作可以使用下面两个关键词:
on delete cascade:级联删除,删除主表记录,外键表的关联记录一块儿删除
on delete set null:删除主表记录,外键表的关联记录该列的值变成null
例如:
1.从test2表中删除id = 1
delete from test2 where id = 1;
2.create table test3( //设置级联删除主表记录,外键表关联记录一块删除
id number references test2(id) on delete cascade);
create table test3(
id number references test2(id) on delete set null);
如果关联的外键被删除,本表外键的位置会被弄成空,而不会被删除
3.update 语句:
语法:update table_name set column=value,[column=value]
[where condition…];
note:
1.如果不加条件,默认修改表中所有的行。
例如:
1. update test set name = ‘wangwu‘,gender=‘M‘
where id = 3; 只更改id=3的行。
2.update test set gender = ‘F‘;所有行都改。
1、事务的基本
当一个sql命令执行一个事务就开始了,当遇到一下情况,事务自动完成
1.commit或者rollback
2.DDL(数据库定义语言)或者DCL命令执行
3.错误,退出,或者系统崩溃
note:
commit:提交事务,提交事务是指让这个事务里面的所有操作都生效到数据库中
rollback:回滚事务,回滚事务是指让这个事务里面的所有操作都撤销
测试: 使用两个终端窗口,同一个账号登录到数据库中,观察事务是否提交对用户查看数据的影响
注:一个用户对A表某一列做了DML操作,但是没有提交事务,这时候别的用户是不能对A表这一列再做其他的DML操作。(为了保证数据的安全和一致性)
例如1:
insert ....产生事务A
update ... 这个操作是事务A中的操作
insert .. 这个操作是事务A中的操作
commit; 让事务A里面的三个操作生效、事务A结束
delete ... 产生新的事务B
insert .. 这个操作是事务B中的操作
insert .. 这个操作是事务B中的操作
insert .. 这个操作是事务B中的操作
rollback; 让事务B中的四个操作都撤销,事务B结束
例如2:
insert ....产生事务A
update ... 这个操作是事务A中的操作
insert .. 这个操作是事务A中的操作
DDL语句; 事务A会被提交
rollback; 这时候回滚已经对事务A不起作用,因为事务A以及被提交了
注:create语句 drop语句 alter语句等属于DDL语句
事务控制使用:commit,savepoint,rollback;
2、事务的ACID原则:
1、原子性:要不全成功,要不全失败
2、一致性:从一个一致性状态到达另外一个一致性状态
3、隔离性:事务之间互不影响
第一类丢失更新:
事务A撤销事务时,将事务B已经提交的事务覆盖了。
第二类丢失更新:
事务A和事务B同时修改某行的值,
1.事务A将数值改为1并提交
2.事务B将数值改为2并提交。
这时数据的值为2,事务A所做的更新将会丢失。
不可重复读:(例如修改)
在同一事务中,两次读取同一数据,得到内容不同
事务1:查询一条记录
-------------->事务2:更新事务1查询的记录
-------------->事务2:调用commit进行提交
事务1:再次查询上次的记录
此时事务1对同一数据查询了两次,可得到的内容不同,称为不可重复读
幻想读:(例如插入)
同一事务中,用同样的操作读取两次,得到的记录数不相同
事务1:查询表中所有记录
-------------->事务2:插入一条记录
-------------->事务2:调用commit进行提交
事务1:再次查询表中所有记录
此时事务1两次查询到的记录是不一样的,称为幻读
脏读:事务A读到事务B未提交的数据。
4、事务隔离级别
为了处理这些问题,SQL标准定义了以下几种事务隔离级别
READ UNCOMMITTED 幻想读、不可重复读和脏读都允许。
READ COMMITTED 允许幻想读、不可重复读,不允许脏读
REPEATABLE READ 允许幻想读,不允许不可重复读和脏读
SERIALIZABLE 幻想读、不可重复读和脏读都不允许
Oracle数据库支持READ COMMITTED 和 SERIALIZABLE这两种事务隔离级别。所以 Oracle不支持脏读
5、持久性:事务提交后,能够持久性影响数据库。
6、隐式事务提交:
1.DDL语句(create..),执行commit
2.DCL语句(gant….),执行commit
3.正常退出终端。
note:如果系统崩溃,或者sqlplus不正常退出,事务回滚。
7.事务提交或者回滚之前的状态
1.因为数据库缓存区的存在,数据前一次的状态可以被回复
2.当前用户可以会看使用DML操作的数据的结果,但是其他用户不能看到当前用户的DML操作结果
3.所有受影响的行会被锁定,其他用户不能修改。
8.显示结束事务
commit:之前所做的所有会影响数据库的操作,都会对数据库产生持久的影响。
rollback:取消之前所做的所有操作
note:事务一旦提交,不能rollback
savepoint: 保存回滚点
savepoint point_name;
rollback to point_name;回滚到指定的标记点。标记点之后所做的所有操作都会被取消,但是之前的不受影响。
添加列不需要关键字column,删除列需要关键字column,修改列用的modify
重命名列的时候rename也需要加关键字column
涉及到的约束添加,删除,约束生效,无效,都需要constraint
目标:
1.添加和修改列
2.添加,enable,disable,或者remove约束
3.删除表
4.删除表中所有数据并回到表定义的初始状态(截断表)
5.修改对象的名字
6.给对象添加注释,从数据字典中查看注释
用到的命令:
1.Alter table :
1.添加和修改列
2.添加和删除约束
3.enable,disable约束
2.drop table命令移除表中所有行和表结构
3.rename,truncate,comment
4.当执行以上DDL语句时,事务自动提交
功能:
1.增加列
语法:
alter table tb_name
add column datatype [default val] constraint .....
note:
1.如果添加not null(primary key约束要求值也不能为null)约束,需要保证当前表中没有数据存在。
2.新添加的列,相当于表定义中最后一个定义的列。
例如:
//添加新的一列
alter table test add name varchar2(10) default ‘test‘ not null ;
//添加新的多列
alter table s_stu add (sname varchar2(20),sage number);
//添加带有约束的列
alter table husband add sage number constraint husband_sage_check check(sage<=100);

2.删除列:
语法:alter table tableName drop column column_name;
例如:alter table test drop column name;
3.修改列属性:(数据类型和约束使用modify)
语法:ALTER TABLE table
MODIFY (column datatype [DEFAULT expr][NOT NULL]
[, column datatype]...);
note:
修改列的规则:(反正就是只能往大了改不能往小了改(没有数据除外))
1.可以增加字段的宽度或者精度
2.如果列的值为null或者表中没有数据,可以降低宽度和精度
3.给当前列,后续添加的数据指定默认值。Default
4.当且仅当当前列中没有null值时,可以定义当前列为not null.
5.当前列中的值为null时,可以修改列的数据类型
6.如果需要给某个字段添加not null约束,只能使用modify。
例如:
alter table test modify id number constraint test_pk_id primary key;
可以间接性的设置约束,前提是约束必须是不违背当前表里面已有的值
alter table test modify id char(20);
4.增加约束
语法:alter table tb_name add 约束的完整定义
note:
1.只能增加能够使用表级约束的约束
2.不能修改约束
例如:
alter table test add constraint test_pk_id primary key(id);
alter table test add check(gender in (‘F‘,‘M‘));
5.删除约束:只能通过约束名字删
语法:alter table tb_name drop 约束名。
例如:
alter table test drop constraint test_pk_id;(截图是TEST1,有值,但是刚才的约束已经没)

删除主键约束时,同时删除和他依赖的外键约束
alter table test drop constraint test_pk_id cascade;

6.使一个约束失效:
语法:alter table tb_name disable constraint constraint_name [cascade];
note:添加cascade表明要让所有的依赖约束都失效。
7.是一个约束生效:
语法:alter table tb_name enable constraint constraint_name;
note:
1.当启用unique和primary key约束时,会自动创建索引。
例如:alter table test enable constraint test_id_pk;
//但需要注意的是,数据必须不能违反主键要求!否则不能启用 
//只有让原来的数据满足约束条件,才可以开启
8.删除表:
drop table tb_name [cascade constraint];
note:
1.删除表中所有数据
2.所有的索引被删除
3.使用cascade constraint,级联删除所有的依赖完整性约束
例如:
//先为一个表添加父类的外键,然后删除,外键约束直接被删掉了
drop table test cascade constraint;
删除之后,可以通过:
select column_name,constraint_name
from user_cons_columns;
查看是否约束还在。
9.重命名:rename
重命名表:
rename old_tb_name to new_tb_name;

重命名列:
alter table tb_name rename column old_col_name to new_col_name;
note:
1.重命名可以用来修改table,view,sequence,synonym
2.只有是这个对象的拥有者,才能重命名。
例如:
rename emp to emp2; 将表名重命名为emp2
alter table emp rename column id to eid;
10.截断表:truncate
语法:truncate table tb_name 语法和drop一样,作用却和delete一样
note:
1.清空表记录
2.释放当前表所占用的表空间。返回建表初始状态
3.是一个DDL命令。
4.一旦删除,事务不能回滚。
例如:truncate table emp;
delete和truncate的比较:
delete:可以指定删除某些列,也可以清空表,但是不释放表空间,在事务没有提交之前可以回滚。
truncate:只能清空表,释放表空间,不能回滚。
11.给表加注释:comments
语法:
comments on 表名 is ’内容’
Comments on column表明.列名 is ‘内容’
给表添加注释
comment on table talbe_name is ‘注释内容‘

给列添加注释
comment on column table_name.column_name is ‘注释内容‘;

note:
1.添加的注释可以在如下数据字典中查看
ALL_COL_COMMENTS
所有列的注解 
USER_COL_COMMENTS
当前用户列的注解
ALL_TAB_COMMENTS
当前所有的表的注释 
USER_TAB_COMMENTS
当前用户表的注释 
例如:
comment on table emp is ‘测试‘;
comment on column emp.eid is ‘haha‘;
19)、创建序列(自动增长)
概念:
所谓序列,在oracle中就是一个对象,这个对象用来提供一个有序的数据列,这个有序的数据列的值都不重复。
1.序列可以自动生成唯一值
2.是一个可以被共享的对象
3.典型的用来生成主键值的一个对象
4.可以替代应用程序代码
5.当sequence的值存放在缓存中时可以提高访问效率。
查看当前用户的sequence表 
创建序列语法:
CREATE SEQUENCE name
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n | NOCACHE}]
note:
1.increment by n:表明值每次增长n(步长)
2.start with n: 从n开始
3.{MAXVALUE n | NOMAXVALUE}: 设置最大值
4.{MINVALUE n | NOMINVALUE}: 设置最小值,start with不能小于最小值。
5.CYCLE | NOCYCLE : 是否循环,建议不使用
6.CACHE n | NOCACHE : 是否启用缓存。

代表当前的初始值为1,每次增长为1,缓存三个
例如:
create sequence emp_id_seq
start with 1
increment by 1
nomaxvalue
nominvalue
nocycle
nocache;
note:可以通过数据字典user_sequences查看当前用户所拥有的序列信息。
例如:
select sequence_name,min_value,max_value,last_number
from user_sequences
where sequence_name = ‘EMP_ID_SEQ‘;
序列的属性(伪列):
1.nextval : 返回下一个可用的序列值。
通过序列名.nextval获得
就算是被不同的用户调用,每次也返回一个唯一的值。每次调用都会返回下一个值
2.currval :获取序列当前的值。
在currval调用之前,必须保证nextval已经获取过一次值。没有获取就会报错
通过数据字典查定义的序列
select last_number,min_value from user_sequences where sequence_name=‘AOTO_ID1‘ ;
默认缓存是这么大的,默认缓存大小是20
当使用缓存的时候,每次调用序列的nextval就可以让当前值加一,直到当前值等于缓存值的时候,缓存在加上定义缓存的值
使用sequence:
例如:
1.向表中插入数据
insert into emp values(emp_id_seq.nextval);

2.查看序列的当前值
select emp_id_seq.currval from dual;
3.获取序列的下一个值。
select emp_id_seq.nextval from dual;
缓存:
使用缓存可以提高sequence的访问效率
修改sequence:
ALTER SEQUENCE name
[INCREMENT BY n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n | NOCACHE}]
只要从新修改了序列,缓存大小,就又开始从1开始自增加了
note:
1.必须是序列的拥有者,或者具有alter权限
2.修改后的序列,只对之后的值起作用。
3.不能修改start with,如果想改,只能删除,重新创建,启动。
删除sequence:
drop sequence seq_name;
例如:
drop sequence emp_id_seq;

20)、创建视图View
概念:
视图:所谓视图就是提取一张或者多张表的数据生成一个映射,管理视图可以同样达到操作原表 的效果,方便数据的管理以及安全操作。
视图其实就是一条查询sql语句,用于显示一个或多个表或其他视图中的相关数据。视图将 一个查询的结果作为一个表来使用,因此视图可以被看作是存储查询结果的一个虚拟表。视图来 源于表,所有对视图数据的修改最终都会被反映到视图的基表中,这些修改必须服从基表的完整 性约束。
视图的存储:
与表不同,视图不会要求分配存储空间,视图中也不会包含实际的数据。视图只是定义了一个查询,视图中的数据是从基表中获取,这些数据在视图被引用时动态的生成。由于视图基于数据库中的其他对象,因此一个视图只需要占用数据字典中保存其定义的空间,而无需额外的存储空间。
视图的优势:
1.信息隐藏
比如s_emp表中有工资,可以创建视图,隐藏工资信息。(可以配合权限,让某个用户只能查看视图,不能查看表。)
2.使复杂查询变得简单。
3.数据独立
4.相同数据的不同展示形式。
视图的分类:
1.简单视图
2.复杂视图
比较:
简单视图 复杂视图
涉及到的表个数 1 1个或多个
包含函数 不包含 包含
包含组数据 不包含 包含
通过视图使用DML 可以 不可以
视图的创建:(说到这里,在as关键字出来在别名的时候用,在子查询建表的时候也会用到)
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW view_name
[(alias[, alias]...)]
AS
select 。。。。
[WITH CHECK OPTION [CONSTRAINT constraint]]
[WITH READ ONLY]

note:
要想创建view不需要有权限,创建权限需要是dba身份下
grant create view to jd1613;
1.or replace:代表修改view
2.force| noforce: 即使基表不存在也要建立该视图 | 基表不存在就不建立此视图,默认值。
代表不存在也要创建
3.alias: 视图中的列的名字(相当于给子查询的结果列起别名)
4.子查询中可以包含复杂的查询语法,这些细节都对用户隐藏。
5.子查询中不能包含order by子句。
6.WITH CHECK OPTION 插入或修改的数据行必须满足视图定义的约束;
换句话说,加上该关键词表示对view进行dml操作的时候,只能操作select语句 中where条件限制的内容
7.WITH READ ONLY :该视图只读,不能在这个视图上进行任何DML操作。
8.查看视图结构: desc view_name;
例如:
create or replace view myView
as
select id,last_name,start_date
from s_emp
where id <= 4;

感觉类似于子查询创建表一样,只不过把table 变成了or replace view
此时可以使用:
1.查看视图中所有数据信息
select * from myView;
2.执行插入:(创建的时候不加with check option,是可以操作除视图查询条件以外的值)
insert into myView values(111,‘haha‘,‘03-5月-16‘); 插入成功!
3.再次查看,找不到刚插入的数据,因为这条数据不满足id<=4,但是查看原始表s_emp,有这条数据。
如果:
create or replace view myView
(id,name,s_date)
as
select id,last_name,start_date
from s_emp
where id <= 4
with check option;

注意可以取别名,但是要注意,uid也属于关键字!
此时可以使用:
1.查看视图中所有数据信息
select * from myView;
2.执行插入:
insert into myView values(121,‘haha‘,‘03-5月-16‘); 插入失败!,因为视图的约束时id<=4,现在插入的id值为121,所以失败!
create or replace view myView
(id,name,s_date)
as
select id,last_name,start_date
from s_emp;
or
create or replace view myView
as
select id,last_name,start_date s_date
from s_emp;
myView中列的名字都为id,name,s_Date.
创建复杂视图:
子查询不许包含order by,而且复杂视图不能做DML操作
复杂视图可能包含分组,组函数,多表连接等。
例如:
CREATE or replace VIEW myView
(name, minsal, maxsal, avgsal)
AS SELECT d.name, MIN(e.salary),
MAX(e.salary), AVG(e.salary)
FROM s_emp e, s_dept d
WHERE e.dept_id = d.id
GROUP BY d.name;

查看视图信息
可以使用数据字典user_views;
Select view_name from user_views;
删除视图对象:
drop VIEW view_name;
21)、索引Index
概念:
oracle常常是用B树来存储索引
1. 类似书的目录结构
2、 Oracle 的“索引”对象,与表关联的可选对象,提高SQL查询语句的速度
3、 索引直接指向包含所查询值的行的位置,减少磁盘I/O
4、 与所索引的表是相互独立的物理结构
5、 Oracle 自动使用并自动维护索引,插入、删除、更新表后,自动更新索引
创建:
1.自动创建
当在表中指定了primary Key或者unique约束时会自动创建唯一值索引。 
2.用户创建。
用户可以创建非唯一值所在以提高在访问行时的效率。
语法:
CREATE INDEX index_name
ON table_name (column[, column]...);
例如:
create index myIndex on emp (eid);
创建成功后可以通过如下语句查看:
select index_name,index_type from user_indexes;
select * from user_ind_columns;
创建索引的原则:
1.列经常作为where子句的限定条件或者作为连接条件
2.列包含的数据量很大,并且很多非空的值。
3.两个或者更多列频繁的组合在一起作为where的限定条件或者连接条件
4.列总是作为收索条件
5.索引查出的数据量占2%~4%
6.索引不是越多越好,不是索引越多越能加速查找。
7.要索引的表不经常进行修改操作
删除索引:
语法:DROP INDEX index_name;
例如:drop index myIndex;
强制唯一的主键无法删除索引,注意是唯一!!
22)、系统权限
权限允许用户访问属于其它用户的对象或执行程序,
ORACLE系统提供权限:Object 对象级、System 系统级
查看权限的数据字典:
字典名 含义
ROLE_SYS_PRIVS System privileges granted to roles(角色拥有系统权利)
ROLE_TAB_PRIVS Table privileges granted to roles(角色拥有表权限)
USER_ROLE_PRIVS Roles accessible by the user(被赋予用户的角色权限)
USER_TAB_PRIVS_MADE Object privileges granted on the user‘s objects
把这个对象的权限授权给用户的对象
USER_TAB_PRIVS_RECD Object privileges granted to the user
对象权限授权给这个用户
USER_COL_PRIVS_MADE Object privileges granted on the columns of the user‘s Object
对象权限授权给这个用户对象的列
USER_COL_PRIVS_RECD Object privileges granted to the user on specific columns
对象权限授权给这个用户的指定列
1.系统权限(系统权限是对用户而言):
DBA拥有最高的系统权限:system用户
1,可以创建用户
语法:create user username identified by password;
例如:create user briup identified by briup;
当用户创建成功之后,此用户什么权限都没有,甚至不能登录数据库。
2. 赋予权限:
一个用户应该具有的基本权限包含:
CREATE SESSION
CREATE TABLE
CREATE SEQUENCE
CREATE VIEW
CREATE PROCEDURE //程序,手续; 工序,过程,步骤; 诉讼程序
如果有多个用户他们都具有相同的权限(create session,create table,create sequence),赋予权限的动作过于麻烦,要给每个用户分别制定这些权限,因此oracle提出角色的概念,可以 将权限赋值给角色,然后再将角色赋值给用户。
例如,我们当初在进行操作时写的:
grant resource,connect to briup;
此时resource,connect就是角色。
查询resource,connect 具有哪些权限可以使用:
select privilege,role
from role_sys_privs
where role = ‘CONNECT‘ or role =‘RESOURCE‘;
语法:(可以赋值角色权限也可以赋值单独的权限)
grant xxxx to user_name ;
例如:
grant create view to briup;
更多权限赋值
– Create the user
create user www identified by www
default tablespace SDH_DATA
temporary tablespace TEMP
profile DEFAULT
password expire;
– Grant/Revoke role privileges
grant connect to www;
grant exp_full_database to www;
grant imp_full_database to www;
grant resource to www;
– Grant/Revoke system privileges
grant alter any index to www;
grant alter any indextype to www;
grant alter any procedure to www;
grant alter any sequence to www;
grant alter any table to www;
grant alter any trigger to www;
grant alter rollback segment to www;
grant alter session to www ;
grant create any directory to www;
grant create any index to www;
grant create any indextype to www;
grant create any trigger to www;
grant create any view to www;
grant create database link to www;--创建dblink的权限
grant create procedure to www ;
grant create rollback segment to www;
grant create sequence to www ;
grant create session to www ;
grant create synonym to www ;
grant create table to www ;
grant create type to www ;
grant create view to www ;
grant debug any procedure to www ;
grant debug connect session to www;--会话权限 创建dblink时必须要有这个权限
grant drop any index to www;
grant drop any indextype to www;
grant execute any procedure to www;
grant insert any table to www;
grant select any dictionary to www ;
grant select any sequence to www;
grant select any table to www;
grant unlimited tablespace to www ;
grant update any table to www;
grant create job to www;
3.回收权限(可以回收用户赋值的角色的权限,或者单独某一个权限)
语法:revoke xxx from user_name;
例如:
revoke create view from briup;

4.修改密码:
语法:alter user xxx identified by xxxx;
例如:
alter user briup identified by briup;
5.删除用户:
语法:drop user username [cascade];
note: cascade:当用户下有表的时候,必须使用cascade级联删除。
例如: drop user test cascade;
6.对象权限(针对对象,类似表对象等):
对象权限:select, update, insert, alter, index, delete, all //all包括所有权限
对象的拥有者拥有所有的权限。
1.给用户赋予操作对象的权限:这个是一个用户想查询另一个用户的信息,需要在另一个用户设置权限,融需要访问的用户进入
GRANT object_priv [(columns)]
ON object
TO {user|role|PUBLIC}
[WITH GRANT OPTION]; //允许分配到权限的用户继续将权限分配给其它用户
例如:
grant select on s_emp to jd1613;
给jd1613用户赋予在s_emp表上进行查询的权利。
容许另一个同意后,就可以查询,另一个表的数据了
设置的权限具体到列上
grant update(id) on s_emp to jd1613;
给jd1613赋予能够更新s_emp表上id列的权限。
2.回收权限:同系统权限。
语法:revoke xxx on obj from user;
note: 通过with grant option赋予额权限也会被回收。
例如:
revoke select , update on s_emp from jd1613;
7.创建同义词: 相当于给对象起别名
语法:
create[public] synonym sy_name for obje_name;
note:只有dba才有权利创建public的同义词
例如:
create synonym emp for s_emp;
8.删除同义词:
语法: drop synonym syn_name;
例如:
drop synonym emp;
9.导出数据库
exp,imp不属于sqlplus的命令,所以不是在sqlplus终端执行的。
系统终端:exp userid=briup/briup full=y file=briup.dmp
一路回车
导入:imp userid=briup/briup full=y file=briup.dmp;
导入的前提是必须要有用户呀!是在window终端下执行的
23)、添加表和列注解
Oracle添加注释的语法为:
comment on column 字段名 is ‘注释名’;
举例:
创建表:
CREATE TABLE t1(
id varchar2(32) primary key,
name VARCHAR2(8) NOT NULL,
age number,
);
添加表注释:
COMMENT ON table t1 IS ‘个人信息‘;
添加字段注释:
comment on column t1.id is ‘id‘;
comment on column t1.name is ‘姓名‘;
comment on column t1.age is ‘年龄‘;
终于做完了了!!2016-9.9 23点
Oracle 数据库如果要想安装请准备出 5G 空间,同时也要清楚一些常见的 Oracle 版本:
· Oracle 8、Oracle 8i:其中“i”表示的是 internet,表示 Oracle 开始向网络发展,1CD;
· Oracle 9i:是 Oracle 8i 的稳定版,也是现在见到最多的版本、3CD;
· Oracle 10g:表示 Oracle 开始基于网格计算推出的数据库,1CD;
· Oracle 11g:是 Oracle 10g 稳定版,现在也算是最主流推广的版本,2G 左右;
· Oracle 12C:“C”表示的是云计算的概念,是现在的最新版本。
在本次之中采用的是 Oracle 11 g 版本,而不是 Oracle 12C 版,因为 12C 在进行初期学习的时候非常的麻烦。而 且最方便的是,oracle 数据库可以直接从网上下载,使用的时候是免费的,即使你在项目之中没有花钱购买 Oracle 也不会 算你使用盗版,但是千万别出错,一出错,没人管你。
在进行 Oracle 安装之前,必须注意一点:请 将你本机的病毒防火墙关闭,同时将那个什 么垃圾的 360 也关了。
对于 Oracle 而言,本身的软件提供的只是一个平台,而在这个平台之上才会进行数据库的管理,那么此时选择的是“创建和配置数据库”就表示在软件安装完成之后会自动的进入到一个新的数据库的创建和配置过程。 
在进行 Oracle 安装的时候会询问用户安装的类型,默认的单机数据库选择的是“单实例数据库”,而对于 RAC 属于Oracle 之中比较高级的数据库管理话题,有兴趣的话可以继续再花费 2W 块钱自己学习。
选择“高级安装”可以进入到一些数据库的基础配置界面。
本数据库之中所使用的语言提供有两种“简体中文”,英语。
本次选择安装的版本为企业版
本次将 Oracle 数据库安装在了“D:\app\Teacher”
由于在一开始选择了“创建数 据库”,所以此时会 询问用户要创建的数据 库名称,将名称修改 为“mldn ”,同时可以
发现有一个 Oracle 服务标识符( SID)跟数据库名称完全一样,其中 SID 为日后程序开发之中使用的服务编号,如果没有 此编号,那么程序将无法进行数据库的连接,一般 SID 都和数据库名称保持一致。
在日后的实际开发之中,所使用的编码一定是“UTF-8”编码,在进行 Oracle 安装的时候一定要选择好此编码,否 则日后就可能出现程序的乱码问题。
同时在“示例方案”上选择“创建具有示例方案的数据库”,这样就会出现相应的测试数据,供学习使用,如果没有
选中,则没有相应数据出现。
在Oracle 之中有两个主要的管理员用户:SYS(超级管理员)、SYSTEM(普通管理员),此时就需要配置这些管理员
帐号的密码,但是现在为了方便起见,将所有的管理员密码都统一配置为“oracleadmin”。(但是在新版本的数据库之中, 这样的密码是不符合要求的)。
随后进入到安装前的系统检查,如果此时有错误了,请选择“忽略”。
随后开始进入到 Oracle 的安装程序界面。
当安装完成之后(实际上,此时 mldn数据库也已经配置完成了),但是数据库配置完成之后必须进行一些用户名和 密码的设置。
首先进入到“口令管理”界面,进行以下四个用户名和密码的修改:
· 超级管理员:sys / change_on_install,实际工作之中不能使这个密码;
· 普通管理员:system / manager,实际工作之中不能使这个密码;
· 普通用户:scott / tiger,需要解锁,此用户是一个非常经典的用户;
· 大数据用户(示例方案数据库):sh / sh,需要解锁。
此时选择“确定”才表示安装已经完成。在 Oracle 安装完成之后会回到 Oracle 安装的主界面,选择“关闭”。
当Oracle 安装完成之后会自动的在 windows 服务里面进行 Oracle 相关的服务注册,有如下的几个:
但是这些服务默认情况下大 部分都是采用了“ 自动”启动的方式 ,如果你电脑快的 话,电脑启动时没 有影响,但是 建议都将其修改为手工方式,在需要的时候再进行启动。而对于开发者而言,如果要使用 Oracle 进行开发,只需要两个:
· Oracle 监听服务(OracleOraDb11g_ho me1TNS Listener):当需要通过程序连接数据库进行开发的时候,此服
务必须打开,如果是在学习 oracle 的时候,并且是在本机使用的时候可以不启动此服务;
· Oracle 实例服务(OracleServ ice MLDN):在一个 oracle 软件平台下可以创建多个数据库,每创建一个数据库, 都会自动的建立一个数据库的服务,命名“OracleServiceSID”(SID 一般和数据库相同)
PS:虽然此时已经成功的安装完成数据库了,但是对于数据库而言还有一个卸载操作。
· 情 况 一 :正常安装 的情况下进行数据库卸载:
|- 停止掉所有的 oracle 数据库服务;
|- 启动oracle的卸载程序
卸载完成之后有可能数据库会出现一些残留的系统文件和注册表文件, 但是这些文件在正常运行操作系统的 时候是无法被删除的,所以必须重新启动电脑,进入到安全模式(开机 F8);
|- 清理掉所有的 oracle 残留文件,同时运行“reged it.exe”进入到注册表之中,手工搜索所有与 oracle 有关的项, 并且进行删除;
· 情 况 二 :安装半截 OVER 了。
|- 此时卸载程序已经无法被使用了,那么只能够直接进行文件的删除;
|- 重新启动电脑,进入到安全模式(开机 F8);
|- 清理掉所有的 oracle 残留文件,同时运行“reged it.exe”进入到注册表之中,手工搜索所有与 oracle 有关的项, 并且进行删除;
还 有 一 招最终极的卸载 Oracle 系统方式:重 新做一个操作系统。
当 Oracle 安装完成之后,用户可以直接在运行窗口处输入“sqlp lus.exe”命令,启动 Oracle 数据库的操作窗口。 
输入了正确的用户名和密码就可以直接进入到 Oracle。但是进入到了 sqlp lus 里面还需要使用一些基本的操作命令。
1、显示格式化操作
· 在数据库之中最重要的组成就是数据表(表的结构就是行列的集合),那么下面可以查询一个 emp 的数据表:
SELECT * FROM emp ;
现在发现以上的显示效果不好,所以使用两个命令操作:
· 设 置 每 行显示的数据长 度:SET LINES IZE 300;
· 设 置 每 页显示的数据行 数:SET PAGES IZE 30;
2、调用记事本命令
有些时候在进行 SQL 程序编写的时候,往往需要编写很多行,那么如果只在命令行下就无法处理了。这个时候往往 会调用本机的记事本程序,用户直接按照“ed文件名称”(ed mldn)。
询问用户现在是否要创建一个“mldn.sql”文件,选择“是”表示创建新的。随后用户可以直接执行此文件之中的程 序代码“@文件名称”(@mldn,如果后缀是“*.sql”可以不写)。但是这种方式一般都比较适合于没有显示界面的操作系 统。但是如果是有界面的操作系统,可以直接在一个文本编辑器之中编写,而后进行复制即可。
如果说现在在磁盘上有一个文件,要想执行,则必须输入完整路径,例如:“d:\my.txt”文件(@d:\my.txt)。
一般后缀名称为*.sql 的都称为数据库脚本文件。
3、切换用户
在 Oracle 里面之前一共提供有四个用户,这四个用户之间的切换可以使用如下的语法完成:
CONN 用户名/密码 [AS SYSDBA]
如果现在使用的是 SYS 帐号登录,那么必须要写上“AS SYSDBA”,而登录之后可以通过“SHOW USER”来查看 当前的登录用户是那一位。
范例: 使用 sys 登录
CONN sy s/change_on_install AS SYSDBA ;
范例: 使用 scott 登录
CONN scott/tiger ;
4、调用本机命令
COPY 源文件路径 目标文件路径
cop y d:\my.txt d:\hello.txt
如果要想在本机调用的话:前面要加上一个 HOST。 范例: 调用本机的 cop y 命令
host cop y d:\my.txt d:\hello.txt ;
以上只是一些最基础的操作命令,日后还会接触到其它命令。
5、总结
1、 数据库的安装;
2、 记下数据库之中四个主要的用户信息:
· 超级管理员:sys / change_on_install,实际工作之中不能使这个密码;
· 普通管理员:system / manager,实际工作之中不能使这个密码;
· 普通用户:scott / tiger,需要解锁,此用户是一个非常经典的用户;
· 大数据用户(示例方案数据库):sh / sh,需要解锁。
3、 sqlplus 的基本命令要熟悉;
1、在面试的时候碰到一个 问题,就是让写一张表中有id和name 两个字段,查询出name重复的所有数据,现在列下:
select * from xi a where (a.username) in (select username from xi group by username having count(*) > 1)
2、查询出所有数据进行分组之后,和重复数据的重复次数的查询数据,先列下:
select count(username) as ‘重复次数‘,username from xi group by username having count(*)>1 order by username desc
3、一下为 查看别人的 结果,现列下:查询及删除重复记录的方法大全
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
四、例子
1、比方说
在A表中存在一个字段“name”,
而且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;
Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同大则如下:
Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1
方法一declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count() from 表名 group by 主字段 having count() >; 1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名 where 主字段 = @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0
方法二"重复记录"有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
1、对于第一种重复,比较容易解决,使用select distinct * from tableName 就可以得到无重复记录的结果集。 如果该表需要删除重复的记录(重复记录保留1条),可以按以下方法删除select distinct * into #Tmp from tableNamedrop table tableNameselect * into tableName from #Tmpdrop table #Tmp 发生这种重复的原因是表设计不周产生的,增加唯一索引列即可解决。
2、这类重复问题通常要求保留重复记录中的第一条记录,操作方法如下 假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集select identity(int,1,1) as autoID, * into #Tmp from tableNameselect min(autoID) as autoID into #Tmp2 from #Tmp group by Name,autoIDselect * from #Tmp where autoID in(select autoID from #tmp2) 最后一个select即得到了Name,Address不重复的结果集(但多了一个autoID字段,实际写时可以写在select子句中省去此列)
查询重复
select * from tablename where id in (select id from tablename group by idhaving count(id) > 1)
PL/SQL
一 简介
PL/SQL表示SQL的过程式语言扩展(Procedural Language Extension to SQL)。是对SQL的扩充,它吸收了高级语言的许多最高设计特点:如数据封装性、信息隐蔽性、重载等。它允许SQL的数据操纵语言和查询语句包含在块结构
(block_structured)和代码过程语言中,使PL/SQL成为一个功能强大的事务处理语言。
1、为什么使用PL/SQL?
传统SQL只负责做什么,不管怎么做。缺少过程与控制语句;无任何算法描述能力。
PL/SQL 拥有变量、控制结构、函数、异常处理等高级语言的要素。
2、优点:
1.提升系统的性能
在没有PL/SQL时,Oracle每次只处理一个SQL语句,而在具有PL/SQL时,一个
完整的语句块一次发送到Oracle,可明显减少和Oracle之间的通信和调用。
2.良好的可维护性和可移植性
保存于数据库内部,可以运行于Oracle所运行的任何环境。在不同的环境下,
由于PL/SQL不会改变,任何工具可以使用一个PL/SQL脚本。
3.流程控制
条件语句、循环语句和分支可用来控制程序的过程流,以决定是否或何时执
行SQL或其他行动。
4.安全性高
安全性高,减少程序对底层数据库的直接操作。
3、缺点:
不能移植到异构数据库系统
4、开发环境:
任何纯文本编辑器 如vi
ORACLE客户端SQLPLUS
二 PL/SQL程序结构
PLSQL可执行块:
DECLARE
声明部分
BEGIN
代码执行部分,这部分是必要的
EXCEPTION
异常处理部分
END;
例如:
DECLARE --声明部分
v_StudentID NUMBER(5) := 1000;
--以分号分隔每一行代码,与Java相同
v_FirstName VARCHAR(20);
BEGIN --执行部分
SELECT first_name
INTO v_FirstName
FROM students
WHERE id = v_StudentID;
EXCEPTION --异常处理
WHEN NO_DATA_FOUND THEN
INSERT INTO log_table
VALUES(‘Student 1000 does not exist!’);
END;
1、第一个PLSQL语句
打开输出:set serverout on;或者set serveroutput on–这个语句是用来管理输出的,没有这句话不会把HelloWorld打印到控制台
begin
dbms_output.put_line(‘Hello,World‘);
end;
/
Declare—申明变量的部分
v_hello varchar2(20):=‘Hello,World‘;
begin
dbms_output.put_line(v_hello);
end;
/
2、plsql基本语法
declare
--这是变量声明部分
v_title varchar2(20);
begin
/*
--这是执行部分
--这是执行部分
*/
end
3、PLSQL的注释:
单行注释: --两个减号
多行注释: /* XXXXX
*/
4、标识符命名规则:
.以字母开头
.后跟任意非空格字符,数字,货币符号,下划线和#
.最大长度为30个字符
.不能是oracle中的关键字
注:PLSQL对大小写不敏感
5、PLSQL的变量声明
变量名 [CONSTANT] 变量类型 [NOT NULL] [:=初始值]
变量定义:以v_开头
常量定义:以c_开头
游标定义:以_cursor结尾
异常定义:以e_开头
变量定义:
declare
v_resultA number :=100;--此处只是申明变量
v_resultB number;
begin
v_resultb:=30;--不区分大小写
dbms_output.put_line(‘v_resultA+B的内容为:‘||(v_resultA+V_resultb));
end;
/

常量定义:
declare
c_resultA constant number not null :=100;--此处用来申明常量
v_resultB number;
begin
c_resulta:=30;--不能改变常量的值,这样写会报错的
dbms_output.put_line(‘v_resultA+B的内容为:‘||(v_resultA+V_resultb));
end;
/
6、PL/SQl中变量的作用域和可见性
作用域:指的是可以访问变量的程序部分,作用域从变量声明开始到该语句块结束。
可见性:外部过程变量在内嵌的过程中可见,
内部过程变量在外部过程不可见
7、PLSQL转义字符: ’ (单引号)
4个单引号是1个,6个是两个8个是三个,10个单引号是四个
练习:输出连续的三个单引号
begin
dbms_output.put_line(‘‘‘‘‘‘‘‘‘‘);
end;
/
8、字段类型RowType和type
给单个值赋值类型Type
declare
v_ename s_emp.last_name%type;
v_eid s_emp.id%type;
begin
dbms_output.put_line(‘请输入订单编号:‘);
v_eid:=&empno;
select last_name into v_ename from s_emp where id = v_eid;
dbms_output.put_line(‘编号为:‘|| v_eid||‘名字为:‘||v_ename);
end;
/
给多个值赋值类型RowType
declare
v_emp s_emp%rowtype;
begin
dbms_output.put_line(‘请输入订单编号:‘);
v_emp.id:=&empno;
select last_name into v_emp.last_name from s_emp where id = v_emp.id;
dbms_output.put_line(‘编号为:‘|| v_emp.id||‘名字为:‘||v_emp.last_name);
end;
/
两个结果都是一样的
三 PLSQL数据类型
PLSQL的数据类型分为:
标量型:数字型、字符型、布尔型、日期型
组合型(复合型):RECORD、TABLE
引用型(参考型):CURSOR
LOB型:BLOB、CLOB等

1、第一个练习:
declare
v_name varchar2(20):=‘zhang‘;
v_age number(7):=20;
v_date date:=to_date
(‘1988-08-08‘,‘yyyy-mm-dd‘);
c_chang constant varchar2(20):=‘briup‘;
begin
dbms_output.put_line
(v_name||v_age||v_date||c_chang);
end;
/
如果报错,请注意语言设置为英文

2、第二个练习:手动输入要查询的值
declare
v_name varchar2(10);
v_eid number;
v_num number;
begin
v_eid := &empno; -- 由键盘输入数据
select first_name into v_name from s_emp where id = v_eid;
v_num :=30; --为变量赋值
dbms_output.put_line(‘Hello World v_num的值为:‘|| v_num|| ‘雇员的名字:‘||v_name||‘编号为:‘||v_eid);
end;
/
(1)标量类型:
数字型:
1.NUMBER
定点数或浮点数,同SQL中NUMBER
declare
v_x number(3);--最多为3位数字
v_y number(5,2);--3位整数,2位小数
begin
v_x :=500;
v_y :=50.90;
dbms_output.put_line(v_x+v_y);
end;
/
2.BINARY_INTEGER
-2**31至2**31间的整数,占用空间比NUMBER
--binary_float
declare
v_x binary_float:=89.51F;--最多为3位数字
v_y binary_double:=23;--3位整数,2位小数
begin
v_x :=500;
v_y :=50.90;
dbms_output.put_line(v_x+v_y);
end;
/
3.binary_float和binary_double定义的常量
begin
dbms_output.put_line(‘1,binary_double_min_normay‘||
binary_float_min_normal);
end;
/
字符型:
常用:CHAR VARCHAR VARCHAR2(STRING) 
1、long和longraw
--UTL_RAW.cast_to_raw转化位二进制
--UTL_RAW.cast_to_raw转化为unclide编码
declare
v_info_long long;
v_info_longraw long raw;
begin
v_info_long := ‘有一个姑娘她灰常的美丽!‘;
v_info_longraw := UTL_RAW.cast_to_raw(‘董小姐!‘);
dbms_output.put_line(
‘v_info_long:‘||v_info_long||
‘v_info_longraw:‘||UTL_RAW.cast_to_varchar2(v_info_longraw));
end;
/
2、rowid和urowid
declare
v_emp_rowid rowid;
v_emp_urowid urowid;
begin
select rowid into v_emp_rowid from s_emp where id=21;
select rowid into v_emp_urowid from s_emp where id=23;
dbms_output.put_line(‘雇员21的rowid为:‘||v_emp_rowid);
dbms_output.put_line(‘雇员23的urowid为:‘||v_emp_urowid);
end;
/
--雇员21的rowid为:AAADVHAABAAAKUaAAU
--雇员23的urowid为:AAADVHAABAAAKUaAAW
时间类型
1、date
--date
declare
v_date1 date :=sysdate;
v_date2 date :=systimestamp;
v_date3 date :=‘19-9月-2016‘;
begin
dbms_output.put_line(‘日期数据‘||to_char(v_date1,‘yyyy-mm-dd hh24:mi:ss‘));
dbms_output.put_line(‘日期数据‘||to_char(v_date1,‘yyyy-mm-dd hh24:mi:ss‘));
dbms_output.put_line(‘日期数据‘||to_char(v_date1,‘yyyy-mm-dd hh24:mi:ss‘));
end;
/
2、timestamp
--使用timestamp
declare
v_timestamp1 timestamp :=sysdate;
v_timestamp2 timestamp :=systimestamp;
v_timestamp3 timestamp :=‘19-9月-2016‘;
begin
dbms_output.put_line(‘日期数据‘||v_timestamp1);
dbms_output.put_line(‘日期数据‘||v_timestamp2);
dbms_output.put_line(‘日期数据‘||v_timestamp3);
end;
/
--使用timestamp2 8小时时差
declare
v_timestamp timestamp with time zone :=systimestamp;
begin
dbms_output.put_line(‘日期数据‘||v_timestamp);
end;
/
--使用timestamp3 当前数据库时间
declare
v_timestamp timestamp with local time zone :=systimestamp;
begin
dbms_output.put_line(‘日期数据‘||v_timestamp);
end;
/


Oracle中TIMESTAMP时间的显示格式
Oracle中的TIMESTAMP数据类型很多人用的都很少,所以即使最简单的一个查询返回的结果也会搞不清楚到底这个时间是什么时间点。
例如:
27-1月 -08 12.04.35.877000 上午
这个时间到底是几点呢?中午12:04分,那就错了,其实使用to_char函数转换后得到如下结果:
2008-01-27 00:04:35:877000
说明这个时间是凌晨的00:04分,而不是中午的12:04分。
发生此问题的原因如下:
示例:
SELECT TO_CHAR(TO_DATE(‘2008-01-29 00:05:10‘, ‘yyyy-mm-dd hh24:mi:ss‘),‘yyyy-mm-dd hh:mi:ss am‘) FROM DUAL
首先把一个00:05分的时间进行转换,按照’yyyy-mm-dd hh:mi:ss am’格式进行转换,得到的结果是:
2008-01-29 12:05:10 上午
这说明Oracle在进行日期转换成字符串的过程中,如果小时转换使用的是12进制的格式,则凌晨00点会被认为是上午12点,然后才是上午1点、 2点、3点。。。oracle中12进制的计时不是从0-11,而是从1-12的,所以如果是夜里零点,你不能记成1点,那只能记成12点了。(不知道这 是不是跟洋人的习惯有关?)
现在我们来看一下Oracle中对TIMESTAMP的处理:
SELECT VALUE FROM NLS_SESSION_PARAMETERS WHERE PARAMETER = ‘NLS_TIMESTAMP_FORMAT‘
返回结果DD-MON-RR HH.MI.SSXFF AM,可以看到,这里默认情况下,使用的TIMESTAMP的格式是12进制的小时。
问题到这里已经找到根源了。
解决方法:
pl/sql developer中读取的是注册表中设置的NLS_TIMESTAMP_FORMAT格式,那么只要在注册表中设置Oracle环境变量的地方(也就是 设置ORACLE_HOME的地方)设置NLS_TIMESTAMP_FORMAT的格式(也就是创建这样一个字符串项,然后设置它的值为你转换需要的掩 码,我一般设置为YYYY-MM-DD HH24:MI:SS:FF6),然后关掉PL/SQL DEVELOPER,再继续登陆,以后我们看到的TIMESTAMP时间就会自动转换成大家需要的格式了。
3、interval
declare
v_interval interval year(3) to month :=interval ‘16-11‘ year to month;
begin
dbms_output.put_line(‘时间间隔‘||v_interval);
dbms_output.put_line(‘当前时间戳+时间间隔:‘||(systimestamp+v_interval));
dbms_output.put_line(‘时间日期+时间间隔‘||(sysdate+v_interval));
end;
/
–时间间隔+016-11
–当前时间戳+时间间隔:21-11月-33 03.47.42.836000000 下午 +08:00
–时间日期+时间间隔21-11月-33
(2)组合类型
1.RECORD记录类型,包含多个标量类型
使用前,首先进行定义
TYPE record_name IS RECORD (
field1 type1 [NOT NULL] [:=expr1],
field2 type2 [NOT NULL] [:=expr2],
…
fieldn typen [NOT NULL] [:=exprn]
);
声明RECORD变量
v_record record_name;
RECORD属性访问
v_record.field1:=...;
v_record.field2:=...;
两个类型相同的RECORD变量可以相互赋值
当RECORD中属性名与select的类型相同,可以直接进行into赋值
--记录类型
declare
type myrec is record(
v_id number(7),
v_name varchar2(20),
v_date date
);
myrec2 myrec;
begin
select id,last_name,start_date
into myrec2
from s_Emp
where id=1;
dbms_output.put_line
(myrec2.v_id||myrec2.v_name||myrec2.v_date);
end;
/
2.%ROWTYPE 返回一个基于数据库表定义的类型
declare
v_s s_emp%rowtype;
begin
select * into v_s
from s_emp
where id=1;
dbms_output.put_line
(‘雇员名是‘||v_s.last_name);
end;
/
注:%rowtype和record的区别
%rowtype是 自定义与表同类型record的便捷方式
3.PL/SQL表(TABLE类型)
类似数组功能的变量类型,包含一组数据,通过下标的方式访问数据。
定义一个TABLE类型:
TYPE table_type_name IS TABLE OF member_type INDEX BY BINARY_INTEGER;
TABLE中元素的类型(member_type)可以是复合类型
如果元素i还没有创建就被引用,会抛出异常(ORA-1403: No data found)
declare
type mytab is table
of varchar2(20) index
by binary_integer;
mytab2 mytab;
begin
select last_name,title
into mytab2(-2),mytab2(2)
from s_Emp
where id=1;
dbms_output.put_line(mytab2(-2)||
mytab2(2));
end;
/
(3)运算符
1、赋值运算符
declare
v_info varchar2(50) :=‘蓝蓝的天空,,,‘;
v_url varchar2(50);--没有设置内容
begin
v_url :=‘www.shinedrn.com‘;--赋值
dbms_output.put_line(v_info);
dbms_output.put_line(v_url);
end;
/
4、连接运算符
--连接运算符
declare
v_info varchar2(50) :=‘蓝蓝的天空,,,‘;
v_url varchar2(50);--没有设置内容
begin
v_url :=‘www.shinedrn.com‘;--赋值
dbms_output.put_line(v_info||v_url);
end;
/

3、关系运算符
--关系运算符
declare
v_info varchar2(50) :=‘蓝蓝的天空,,,‘;
v_num1 number:=80;
v_num2 number:=50;
begin
if v_num1 >v_num2 then
dbms_output.put_line(‘第一个数字比第二个数字大!‘);
end if;
if v_info like ‘%天%‘ then
dbms_output.put_line(‘文本中包含天这个字!‘);
end if;
end;
/

4、逻辑运算符
–逻辑运算符
--and,or not
declare
v_flog1 boolean :=true;
v_flog2 boolean :=false;
v_flog3 boolean ;
begin
if v_flog1 and v_flog2 then
dbms_output.put_line(‘v_flog1 and v_flog2为true‘);
end if;
if v_flog1 or v_flog3 then
dbms_output.put_line(‘v_flog1 or v_flog3结果为true‘);
end if;
if v_flog3 is null then
dbms_output.put_line(‘v_flog3结果为null‘);
end if;
end;
/
控制语句:条件语句 循环语 句 GOTO语句(不建议使用) 
1、条件语句 if case ..
IF boolean_expression1 THEN
...
ELSIF boolean_expression2 THEN
...
ELSE
...
END IF;
–程序控制 if
declare
v_countResult number;
begin
select count(*) into v_countResult from s_emp;
if v_countResult >100 then
dbms_output.put_line(‘数量大于十00条!!‘);
elsif v_countResult >10 then
dbms_output.put_line(‘数量大于十条!!‘);
else
dbms_output.put_line(‘数量大于一条!!‘);
end if;
end;
/
–数量大于十条!!
练习一:
判断一个表中记录条数是奇数还是偶数。
declare
v_num number(7);
begin
select count(*) into v_num
from s_emp;
if mod(v_num,2)=0 then
dbms_output.put_line(‘记录数是偶数‘);
else
dbms_output.put_line(‘记录数是奇数‘);
end if;
end;
/
练习二:
–练习if,提示用户输入编号判断当前用户工资情况
declare
v_sal s_emp.salary%type;
v_id s_emp.id%type;
begin
dbms_output.put_line(‘亲,请输入你要查看的工资等级!!‘);
v_id := &empno;
select id,salary into v_id,v_sal from s_emp where id=v_id;
if v_sal>3000 then
dbms_output.put_line(‘中等工资!‘);
elsif v_sal>6000 then
dbms_output.put_line(‘高工资!‘);
else
dbms_output.put_line(‘低工资!!‘);
end if;
end;
/
/*
输入 empno 的值: 1
原值 6: v_id := &empno;
新值 6: v_id := 1;
亲,请输入你要查看的工资等级!!
低工资!!
*/
练习三:
–根据雇员的id查到所在部门,根据所在的部门上涨工资
–要求最高不超过5000,超过5000就按5000算
declare
v_say s_emp.salary%type;
v_id s_emp.id%type;
v_deptid s_emp.dept_id%type;
begin
v_id :=&empno;
select salary,dept_id into v_say ,v_deptid from s_emp where id = v_id;
if v_deptid = 41 then
if v_say * 1.1 >5000 then
update s_emp set salary=5000 where id=v_id;
else
update s_emp set salary = salary*1.1 where id=v_id;
end if;
elsif v_deptid = 42 then
if v_say * 1.2 >5000 then
update s_emp set salary=5000 where id=v_id;
else
update s_emp set salary = salary*1.2 where id=v_id;
end if;
end if;
end;
/
2、between and
declare
begin
if to_date(‘1995-08-12‘,‘yyyy-mm-dd‘) between to_date(‘1990-08-01‘,‘yyyy-mm-dd‘)
and to_date(‘1999-08-01‘,‘yyyy-mm-dd‘) then
dbms_output.put_line(‘你的生日在这个范围之内!!‘);
end if;
end;
/
3、in
declare
begin
if 10 in(12,23,10) then
dbms_output.put_line(‘数据已经被查找到!‘);
end if;
end;
/
4、like
declare
begin
if ‘DRN‘ like ‘%R%‘ then
dbms_output.put_line(‘可以找到!‘);
end if;
end;
/
5、case
declare
v_choose number :=1;
begin
case v_choose
when 0 then
dbms_output.put_line(‘你选的是0‘);
when 1 then
dbms_output.put_line(‘你选的是1‘);
when 2 then
dbms_output.put_line(‘你选的是2‘);
end case;
end;
/

6、内部程序块
–内部程序块
declare
v_x number :=30; --全局变量
begin
declare
v_x varchar2(40) := ‘我是局部变量‘;
v_y number := 20;
begin
dbms_output.put_line(‘内部程序块输出:v_x=‘||v_x);
dbms_output.put_line(‘内部程序块输出:v_y=‘||v_y);
end;
dbms_output.put_line(‘外部程序块输出:v_x=‘||v_x);
end;
/
7、异常处理
异常处理流程 
1).编译时异常
---exception 编译时异常
declare
v_result number :=1;
begin
if result = 1--缺少THEN
dbms_output.put_line(‘条件满足!‘);
end if;
end;
/
2).运行时异常
declare
v_result number :=1;
begin
v_result := v_result/0;--除数为0
end;
/
3). 异常处理,需要使用exception
declare
v_result number :=1;
begin
v_result := v_result/0;--除数为0
dbms_output.put_line(‘异常之后程序不会在执行!‘);
exception
when zero_divide then
--这样可以捕获异常
dbms_output.put_line(‘除数不能为零。‘);
dbms_output.put_line(‘sqlcode:‘||sqlcode);
end;
/
4). 处理赋值异常
--处理赋值异常1
declare
v_varA varchar2(1);
v_varB varchar2(4) := ‘jack‘;
begin
v_varA := v_varB;--错误的赋值
dbms_output.put_line(‘数据赋值错误!‘);
dbms_output.put_line(‘异常之后的代码不会在执行!‘);
exception
when value_error THEN
dbms_output.put_line(‘数据赋值错误!!‘);
dbms_output.put_line(‘sqlcode:‘||sqlcode);
end;
/
–处理赋值异常2 no_data_found 当找不到的数据的时候
declare
v_id s_emp.id%type;
v_name s_emp.last_name%type;
begin
dbms_output.put_line(‘请输入你要查询的‘);
v_id :=&empno;
select last_name into v_name from s_emp where id=v_id;
dbms_output.put_line(‘根据id查到的名字为:‘||v_name);
exception
when no_data_found THEN
dbms_output.put_line(‘你输入的id没有数据哦!!‘);
dbms_output.put_line(‘sqlcode:‘||sqlcode);
end;
/
5).返回数据过多异常
–处理异常3 返回数据过多!
declare
v_x number(1) := 9;
v_y number(2) := 20;
begin
v_x := v_y;
exception
when others THEN
dbms_output.put_line(‘其他的错误!!‘);
dbms_output.put_line(‘sqlcode:‘||sqlcode);
end;
/
6).用户自定义异常 
–用户自定义异常
declare
v_data number;
v_myexp exception;
begin
v_data :=&inputData;--输入数据
if v_data >10 and v_data <1000 then
raise v_myexp;--抛出异常
end if;
exception
when v_myexp then --出现指定异常
dbms_output.put_line(‘输入数据有问题!!‘);
dbms_output.put_line(‘sqlcode:‘||sqlcode);
dbms_output.put_line(‘sqlerrm:‘||sqlerrm);
end;
/
/*输入 inputdata 的值: 21
原值 5: v_data :=&inputData;–输入数据
新值 5: v_data :=21;–输入数据
输入数据有问题!!
sqlcode:1
sqlerrm:User-Defined Exception
*/
–用户自定义异常2,设置sqlcode ,抛出异常,保证sqlcode编码要一致才可以抛出
declare
v_data number;
v_myexp exception;--定义一个异常变量
pragma exception_init(v_myexp,-20789);
begin
v_data :=&inputData;--输入数据
if v_data >10 and v_data <100 then
raise_application_error(-20789,‘输入的数字不能在10~100之间!‘);--抛出异常
end if;
exception
when v_myexp then --出现指定异常
dbms_output.put_line(‘输入数据有问题!!‘);
dbms_output.put_line(‘sqlcode:‘||sqlcode);
dbms_output.put_line(‘sqlerrm:‘||sqlerrm);
end;
/
/*
输入 inputdata 的值: 21
原值 6: v_data :=&inputData;–输入数据
新值 6: v_data :=21;–输入数据
输入数据有问题!!
sqlcode:-20789
sqlerrm:ORA-20789:
*/
7).构建动态异常
–构建动态异常
declare
v_myexp exception;
v_input_rowid varchar2(18);
pragma exception_init(v_myexp,-01213);
begin
v_input_rowid := ‘&inputRowid‘; --输入一个rowid的数据
if length(v_input_rowid) <> 18 then
raise v_myexp;
end if;
exception
when v_myexp then
dbms_output.put_line(‘sqlcode:‘||sqlcode);
dbms_output.put_line(‘sqlerrm:‘||sqlerrm);
end;
/
–练习,利用pl/sql动态的为部门表添加信息,如果id存在,则抛出异常提示,id存在
declare
v_did s_dept.id%type;--部门编号
v_dname s_dept.name%type;--部门名称
v_dregid s_dept.region_id%type;--部门位置
v_deptCount number;--保存count函数的结果
begin
v_did := &inputdid; --输入部门编号
v_dname := &inputdname; -- 输入部门名称
v_dregid := &inputdregid;--输入部门位置
--统计要增加的部门编号在dept表中的信息数量,如果返回0,表示没有次部门
select count(id) into v_deptCount from s_dept where id = v_did;
if v_deptCount > 0 then --部门存在
raise_application_error(-20888,‘此部门存在,请从新再来!!‘);
else
insert into s_dept values(v_did,v_dname,v_dregid);
dbms_output.put_line(‘新部门增加成功!!‘);
commit;
end if;
exception
when others then
dbms_output.put_line(sqlerrm);
rollback;
end;
/
8).预定义异常
CURSOR_ALREADY_OPEN ORA-6511 试图打开一个已打开的游标
DUP_VAL_ON_INDEX ORA-0001 试图破坏一个唯一性限制
INVALID_CURSOR ORA-1001 试图使用一个无效的游标
INVALID_NUMBER ORA-1722 试图对非数字值进行数字操作
LOGIN_DENIED ORA-1017 无效的用户名或者口令
NO_DATA_FOUND ORA-1403 查询未找到数据
NOT_LOGGED_ON ORA-1012 还未连接就试图数据库操作
PROGRAM_ERROR ORA-6501 内部错误
ROWTYPE_MISMATCH ORA-6504 主变量和光标的类型不兼容
STORAGE_ERROR ORA-6500 内部错误
TIMEOUT_ON_RESOURCE ORA-0051 发生超时
TOO_MANY_ROWS ORA-1422 SELECT INTD命令返回的多行
TRANSACTION_BACKED_OUT ORA-006 由于死锁提交被退回
VALUE_ERROR ORA-6502 转换或者裁剪错误
ZERO_DIVIDE ORA-1476 试图被零除
1. LOOP简单循环
格式如下:
LOOP
…
–使用IF与EXIT配合进行退出
IF boolean_expr THEN
EXIT;
END IF;
--使用EXIT与WHEN进行退出
EXIT WHEN boolean_expr2;
END LOOP;
1、练习1
–循环语句
declare
v_num number(7):=1;
begin
loop
dbms_output.put_line(v_num);
exit when v_num=10;
v_num:=v_num+1;
end loop;
end;
/
2、练习2
declare
v_num number(7):=1;
v_sum number(7):=0;
begin
loop
v_sum:=v_sum+v_num;
exit when v_num = 100;
v_num:=v_num+1;
end loop;
dbms_output.put_line(‘和为‘||v_sum);
end;
/
2. WHILE循环
WHILE boolean_expression LOOP
…
END LOOP;
也可以使用EXIT或EXIT WHEN语句终止循环处理。
—while循环
declare
v_num number(7):=1;
begin
while v_num<=10 loop
dbms_output.put_line(v_num);
v_num := v_num+1;
end loop;
end;
/
declare
v_num number(7):=1;
v_sum number(7):=0;
begin
while v_num<=100 loop
v_sum:=v_sum+v_num;
v_num :=v_num+1;
end loop;
dbms_output.put_line(v_sum);
end;
/
3. FOR循环
FOR loop_counter IN [REVERSE] low_bound..high_bound LOOP
…
END LOOP;
begin
for i in 1..10 loop
dbms_output.put_line(i);
end loop;
end;
/
4、循环的选择:
FOR循环:用于明确循环次数的使用
WHILE循环:用于条件判断的循环
LOOP循环:类似JAVA中的do while循环,首先进行一次操作
NULL语句:表示不执行任何操作
begin
null;
end;
/
1、什么是记录(Record)?
由单行多列的标量构成的复合结构。可以看做是一种用户自定义数据类型。组成类似于多维数组。将一个或多个标量封装成一个对象进行操作。是一种临时复合对象类型。
记录可以直接赋值。RECORD1 :=RECORD2;
记录不可以整体比较.
记录不可以整体判断为空。
2、%ROWTYPE和记录(Record)?
请区别%ROWTYPE和记录(Record)类型。%ROWTYPE可以说是Record的升级简化版。
区别在与前者结构为表结构,后者为自定义结构。二者在使用上没有很大区别。前者方便,后者灵活。在实际中根据情况来具体决定使用。
Record + PL/SQL表可以进行数据的多行多列存储。
3、如何创建和使用记录?
①创建记录类型
语法:
TYPE 记录名 IS RECORD
(
filed1 type1 [NOT NULL] [:=eXPr1],
....... ,
filedN typen [NOT NULL] [:=exprn]
)
其中,filed1是标量的名字。
②声明记录类型变量:
记录类型变量名 记录类型
③填充记录。
④访问记录成员
记录类型变量名.filed1
.........
记录类型变量名.filedN
注意:
表字段类型修改后,还需要修改记录字段类型,有时候可能会忘记,从而出现错误。
对于记录内每个字段(filed1.。。。),可以指定也可以使用%TYPE和%ROWTYPE动态指定记录字段类型。
好处是表字段发生变化,记录字段自动改变。但是,由于每次执行前,遇到%TYPR或%ROWTYPE,
数据库系统都会去查看对应表字段类型,会造成一定的数据库开销,如果系统中大量使用记录类型,则对性能会有一定影响。
另外如果删除了某一字段,而自定义记录中使用了该字段,也会有可能忘记删除该字段。
对数据库负荷偏低的系统,性能问题一般可以不重点关注,但是对于高负荷数据库服务器,
各个环节都要考虑性能问题,每处节省一点出来,性能整体就有很大提高。
语法:
TYPE 记录名 IS RECORD
(
filed1 table.Filed%Type [NOT NULL] [:=eXPr1] ,
filed2 table.Filed%Type [NOT NULL] [:=eXPr1] ,
....... ,
filedn table.Filed%Type [NOT NULL] [:=exprn]
);
例子:记录可以整体赋值
Create Table empa As Select * From emp;
Declare
Type EmpType is Record(
EMPNO number(4),
ENAME varchar2(10),
JOB varchar2(15),
SAL number(7,2),
DEPTNO number(2)
);
EmpRec1 EmpType;
EmpRec2 EmpType;
Begin
EmpRec1.Empno:=7369;
EmpRec1.Ename:=‘SMITH‘;
EmpRec1.Job:=‘CLERK‘;
EmpRec1.Sal:=800;
EmpRec1.Deptno:=10;
EmpRec2 := EmpRec1;
DBMS_output.put_line(EmpRec2.empno);
End;
例子:记录不可以整体比较,只可以比较记录字段
Declare
Type EmpType is Record(
EMPNO number(4),
ENAME varchar2(10),
JOB varchar2(15),
SAL number(7,2),
DEPTNO number(2)
);
EmpRec1 EmpType;
EmpRec2 EmpType;
Begin
EmpRec1.Empno:=7369;
EmpRec1.Ename:=‘SMITH‘;
EmpRec1.Job:=‘CLERK‘;
EmpRec1.Sal:=800;
EmpRec1.Deptno:=10;
if EmpRec1.sal < EmpRec2.sal then
DBMS_output.put_line(‘Xiao Xiao Xiao‘);
end if;
End;
例子:记录不可以整体判断为空,只可以判断记录字段。
Declare
Type EmpType is Record(
EMPNO number(4),
ENAME varchar2(10),
JOB varchar2(15),
SAL number(7,2),
DEPTNO number(2)
);
EmpRec EmpType;
Begin
if EmpRec.ename is null then
DBMS_output.put_line(‘Kong Kong Kong‘);
end if;
End;
例子:使用%TYPE和%ROWTYPE动态指定记录字段。
Create Table empa As Select * From emp;
DECLARE
Type MyRecType Is Record
(
RENO EMPA.EMPNO%Type,
RENAME EMPA.ENAME%Type,
RJOB EMPA.JOB%Type
);
EmpRec MyRecType;
Begin
Select EMPNO, ENAME, JOB InTo EmpRec From empa Where empa.EMPNO = ‘7369‘;
If EmpRec.RJOB = ‘CLERK‘ Then
DBMS_OUTPUT.PUT_LINE(‘Name: ‘||EmpRec.RENAME);
End If;
End;
例子:数据集中的记录和记录类型中的数据关系。
DECLARE
Type MyRecType Is Record
(
RENO EMPA.EMPNO%Type,
RENAME EMPA.ENAME%Type,
RJOB EMPA.JOB%Type
);
EmpRec MyRecType;
vJob EMPA.JOB%Type;
Begin
Select EMPNO, ENAME, JOB InTo EmpRec From empa Where empa.EMPNO = ‘7369‘;
DBMS_OUTPUT.PUT_LINE(‘MyRecType.RJOB: ‘||EmpRec.RJOB);
EmpRec.RJOB := ‘修改值后‘ ;
DBMS_OUTPUT.PUT_LINE(‘MyRecType.RJOB: ‘||EmpRec.RJOB);
Select JOB InTo vJob from empa Where empa.EMPNO = EmpRec.RENO;
DBMS_OUTPUT.PUT_LINE(‘EMPA.JOB: ‘||vJob);
End;
/
4、使用记录向表中插入数据?
根据表结构合理安排记录字段。比如主外键。
如果用记录(RECORD)插入数据,那么只能使用记录成员;
如果用%ROWTYPE插入数据,可以直接使用%ROWTYPE。
例子:使用记录成员向表中插入数据
DECLARE
Type MyRecType Is Record
(
RENO EMPA.EMPNO%Type,
RENAME VARCHAR2(10),
RJOB EMPA.JOB%Type
);
EmpRec MyRecType;
Begin
Select EMPNO, ENAME, JOB InTo EmpRec From empa Where empa.EMPNO = ‘7369‘;
DBMS_OUTPUT.PUT_LINE(EmpRec.RENO||‘ ‘||EmpRec.RENAME||‘ ‘||EmpRec.RJOB);
EmpRec.RENO := 1001;
EmpRec.RENAME := ‘杰克‘;
EmpRec.RJOB := ‘办事员‘;
Insert InTo empa(EMPNO,ENAME,JOB) Values(EmpRec.RENO, EmpRec.RENAME,EmpRec.RJOB);
Select EMPNO, ENAME, JOB InTo EmpRec From empa Where empa.EMPNO = ‘1001‘;
DBMS_OUTPUT.PUT_LINE(EmpRec.RENO||‘ ‘||EmpRec.RENAME||‘ ‘||EmpRec.RJOB);
End;
5、使用记录更新数据?
如果用记录(RECORD)更新数据,那么只能使用记录成员;
如果用%ROWTYPE更新数据,可以直接使用%ROWTYPE。
例子:使用%ROWTYPE向表中插入数据
DECLARE
vEmp empa%RowType;
Begin
Select * InTo vEmp From empa Where empa.EMPNO = ‘7369‘;
UpDate empa Set ROW = vEmp Where EMPNO = 1001;
End;
6,使用记录删除数据?
删除记录时,只能在delete语句的where子句中使用记录成员。
索引表
declare
type info_index is table of varchar2(20) index by pls_integer;
v_info info_index;
begin
v_info(1) := ‘我是张三1号!‘;
v_info(10) := ‘我是张三10号!‘;
v_info := v_info/0;
if v_info.exists(10) then
dbms_output.put_line(v_info(10));
elsif v_info.exists(30) then
dbms_output.put_line(v_info(30));
else
dbms_output.put_line(‘索引号30的数据不存在!!‘);
end if;
exception
when others then
dbms_output.put_line(‘索引号30的数据不存在!!,报错!!‘);
end;
/
–索引表用rowtype
declare
type dept_index is table of s_dept%rowtype index by pls_integer;
v_dept dept_index;
begin
v_dept(0).name := ‘我是张三1号!‘;
v_dept(0).id := 1234;
if v_dept.exists(0) then
dbms_output.put_line(v_dept(0).name);
dbms_output.put_line(v_dept(0).id);
elsif v_dept.exists(0) then
dbms_output.put_line(v_dept(0).id);
else
dbms_output.put_line(‘索引号0的数据不存在!!‘);
end if;
exception
when others then
dbms_output.put_line(‘索引号0的数据不存在!!,报错!!‘);
end;
/
–索引表用record
declare
type dept_type is record(
name s_dept.name%type,
id s_dept.id%type
);
type dept_index is table of dept_type index by pls_integer;
v_dept dept_index;
begin
v_dept(0).name := ‘我是张三1号!‘;
v_dept(0).id := 1234;
if v_dept.exists(0) then
dbms_output.put_line(v_dept(0).name);
dbms_output.put_line(v_dept(0).id);
elsif v_dept.exists(0) then
dbms_output.put_line(v_dept(0).id);
else
dbms_output.put_line(‘索引号0的数据不存在!!‘);
end if;
exception
when others then
dbms_output.put_line(‘索引号0的数据不存在!!,报错!!‘);
end;
/
创建嵌套表类型
create or replace type project_nested is table of varchar2(50) not null;
drop table department purge;--删除表结构!
–新建表内嵌表类型
create table department(
did number,
deptname varchar2(30),
projects project_nested
)nested table projects store as projects_nested_table;
insert into department(did,deptname,projects) values(
10,‘Jack‘,project_nested(‘Java实战!‘,‘安卓实战!!‘)
);
insert into department(did,deptname,projects) values(
11,‘DRN‘,project_nested(‘Java实战1!‘,‘安卓实战!!1‘)
);
可变数组
–定义简单类型的可变数组
create or replace type project_varry as varray(3) of varchar2(50);
–oracle10g drop表后并没有彻底的删除表,而是把表放入回收站,可以用purge完全删除
drop table department purge;
create table department(
did number,
deptname varchar2(30) not null,
projects project_varry not null,
constraint pk_did primary key (did)
);
insert into department (did,deptname,projects) values
(1008611,‘中国移动‘,project_varry(‘1‘,‘2‘,‘3‘));
insert into department (did,deptname,projects) values
(10010,‘中国联通‘,project_varry(‘11‘,‘22‘,‘33‘));

集合运算符
–验证cardinality函数
declare
type list_nested is table of varchar2(50) not null;--嵌套类型
v_all list_nested := list_nested(‘a‘,‘b‘,‘c‘,‘d‘,‘e‘,‘f‘);
begin
dbms_output.put_line(‘集合的长度!为:‘||cardinality(v_all));
end;
/
–验证set取消重复
declare
type list_nested is table of varchar2(50) not null;--嵌套类型
v_all list_nested := list_nested(‘a‘,‘b‘,‘b‘,‘d‘,‘d‘,‘f‘);
begin
dbms_output.put_line(‘集合的长度!为:‘||cardinality(set(v_all)));
end;
/
–验证entry(是否为空)运算符
declare
type list_nested is table of varchar2(50) not null;--嵌套类型
v_allA list_nested := list_nested(‘mldn‘,‘beijing‘,‘java‘);
v_allB list_nested := list_nested();
begin
if v_allA is not empty then
dbms_output.put_line(‘集合A不为空集合‘);
end if;
if v_allB is empty then
dbms_output.put_line(‘集合B为空集合‘);
end if;
end;
/
–验证member of 运算符,判断字符串是否存在
declare
type list_nested is table of varchar2(50) not null;
v_all list_nested := list_nested(‘DRN‘,‘我们‘,‘还会在见吗?‘);
v_str varchar(20) :=‘DRN‘;
begin
if v_str member of v_all then
dbms_output.put_line(‘v_str在v_all中是存在的!!‘);
end if;
end;
/
–验证multiset except –找到两个集合中不同的数据
declare
type list_nested is table of varchar2(50) not null;
v_allA list_nested := list_nested(‘DRN‘,‘我们‘,‘还会在见吗?‘);
v_allB list_nested := list_nested(‘我们‘,‘还会在见吗?‘);
v_newlist list_nested;
begin
v_newlist:=v_allA multiset except v_allB;--‘DRN’
for x in 1..v_newlist.count loop
dbms_output.put_line(v_newlist(x));
end loop;
end;
/
–验证multiset intersect –找到两个集合中相同的数据
declare
type list_nested is table of varchar2(50) not null;
v_allA list_nested := list_nested(‘DRN‘,‘我们‘,‘还会在见吗?‘);
v_allB list_nested := list_nested(‘我们‘,‘还会在见吗?‘);
v_newlist list_nested;
begin
v_newlist:=v_allA multiset intersect v_allB;--‘DRN’
for x in 1..v_newlist.count loop
dbms_output.put_line(v_newlist(x));
end loop;
end;
/
–验证multiset union –合并两个集合的数据
declare
type list_nested is table of varchar2(50) not null;
v_allA list_nested := list_nested(‘DRN‘,‘我们‘,‘还会在见吗?‘);
v_allB list_nested := list_nested(‘我们‘,‘还会在见吗?‘);
v_newlist list_nested;
begin
v_newlist:=v_allA multiset union v_allB;--‘DRN’
v_newlist:=set(v_newlist);--加这个是去除重复
for x in 1..v_newlist.count loop
dbms_output.put_line(v_newlist(x));
end loop;
end;
/
–验证是不是子集合
declare
type list_nested is table of varchar2(50) not null;
v_allA list_nested := list_nested(‘DRN‘,‘我们‘,‘还会在见吗?‘);
v_allB list_nested := list_nested(‘我们‘,‘还会在见吗?‘);
v_newlist list_nested;
begin
if v_allB submultiset v_allA then
dbms_output.put_line(‘v_allB是v_allA的一个子集合。‘);
end if;
end;
/
declare
type list_nested is table of varchar2(50) not null;
v_allA list_nested := list_nested(‘cat‘,‘我们‘,‘还会在见吗?‘);
v_allB list_nested := list_nested(‘我们‘,‘还会在见吗?‘);
v_newlist list_nested;
begin
if v_allB submultiset v_allA then
dbms_output.put_line(‘v_allB是v_allA的一个子集合。‘);
end if;
end;
/
–使用delete函数删除一个数据
declare
type list_nested is table of varchar2(50) not null;
v_all list_nested := list_nested(‘cat‘,‘我们‘,‘还会在见吗?‘,‘时间都去哪了?‘,‘一岁以光荣!‘);
begin
v_all.delete(1);--清楚指定索引的数据。
for x in v_all.first..v_all.last loop
dbms_output.put_line(v_all(x));
end loop;
end;
/
–使用delete函数删除一个范围数据
declare
type list_nested is table of varchar2(50) not null;
v_all list_nested := list_nested(‘cat‘,‘我们‘,‘还会在见吗?‘,‘时间都去哪了?‘,‘一岁以光荣!‘);
begin
v_all.delete(1,3);--清楚指定索引的数据。
for x in v_all.first..v_all.last loop
dbms_output.put_line(v_all(x));
end loop;
end;
/
–判读数据是否存在EXISTS
declare
type list_nested is table of varchar2(50) not null;
v_all list_nested := list_nested(‘cat‘,‘我们‘,‘还会在见吗?‘,‘时间都去哪了?‘,‘一岁以光荣!‘);
begin
if v_all.exists(1) then
dbms_output.put_line(‘索引为1得数据不存在!!‘);
end if;
end;
/
–扩充集合长度(x打印的是数字也就是次数)
declare
type list_nested is table of varchar2(50) not null;
v_all list_nested := list_nested(‘cat‘,‘我们‘,‘还会在见吗?‘,‘时间都去哪了?‘,‘一岁以光荣!‘);
begin
dbms_output.put_line(‘原始长度:‘||v_all.count());
v_all.extend(2);--扩充两个长度
v_all(6):=‘最美的夏天!‘;
v_all(7):=‘最美的冬天!‘;
for x in v_all.first .. v_all.last loop
dbms_output.put_line(v_all(x));
dbms_output.put_line(‘x是:‘||x);
end loop;
end;
/
–获取索引表长度
declare
type list_nested is varray(8) of varchar2(50) not null;
v_all list_nested := list_nested(‘cat‘,‘我们‘,‘还会在见吗?‘,‘时间都去哪了?‘,‘一岁以光荣!‘);
begin
dbms_output.put_line(‘最大长度:‘||v_all.limit);
dbms_output.put_line(‘原始长度:‘||v_all.count);
end;
/
–索引表数据不是连续的,first获取第一个索引
declare
type list_index is table of varchar2(50)index by pls_integer;
v_info list_index;
v_foot number;
begin
v_info(1) :=‘MSDN1‘;
v_info(10) :=‘MSDN2‘;
v_info(-1) :=‘MSDN3‘;
v_info(-21) :=‘MSDN4‘;
v_info(30) :=‘MSDN5‘;
v_foot := v_info.first;--找到第一个索引值(按照大小排序的)
while (v_info.exists(v_foot)) loop --置顶索引值存在
dbms_output.put_line(‘|| (‘||v_foot||‘) = ‘||
v_info(v_foot));
v_foot:=v_info.next(v_foot);--取得下一个索引值
end loop;
end;
/
–验证索引表数据不是连续的
--|| (-21) = MSDN4
--|| (-1) = MSDN3
--|| (1) = MSDN1
--|| (10) = MSDN2
--|| (30) = MSDN5
–集合函数trim删除最后一个数据
declare
type list_varray is varray(8) of varchar2(50);
v_info list_varray := list_varray(‘cat‘,‘我们‘,‘还会在见吗?‘,‘时间都去哪了?‘,‘一岁以光荣!‘);
begin
dbms_output.put_line(‘原始长度:‘||v_info.count);
v_info.trim; --删除一个数据
dbms_output.put_line(‘山之后的长度:‘||v_info.count);
for x in v_info.first.. v_info.last loop
dbms_output.put_line(v_info(x));
end loop;
end;
/
两个表通常使用外键建立数据之间的关联,相对于这样的方式访问数据库,存储在集合中的数据可以更快的被访问。常用的集合类型:
index-by表(索引表)
嵌套表
可变数组
1、index-by表(索引表)
index-by表类似C语言中的数组,但是元素顺序并没有按照特定的顺序排列。元素的个数只受到BINARY_INTEGER的下标大小限制。
type tabletype IS table of INDEX BY binaru_interger;
–typetable:定义的新类型类型名
–type:定义index-by表的类型
type Country_Name IS table of COUNTRIES.COUNTRIES_NAME%TYPE
–声明使用类型
INDEX by binary_integer;
–声明变量
v_Name Country_Name;
–赋值操作
begin
v_Name(1):=‘China‘;
v_Name(2):=‘AnHui‘;
v_Name(3):=‘HeFei‘;
v_Name(-2):=‘SuZhou‘;
v_Name(6):=‘SiXian‘;
end;
调用没有赋值的元素
declare
type StudyTab IS table of varchar(20) index by binary_integer;
v_StudyTab StudyTab;
begin
--使用循环赋值
for v_Count IN 1..5 Loop
v_StudyTab(v_Count):=v_Count*100;
end loop;
--使用循环取值
for v_Count in 1..6 loop
DBMS_OUTPUT.put_line(v_StudyTab(v_Count));
end loop;
end;
–上面赋值的时候只赋了5个值,但是取值的时候取了6个值,报错
–:未找到数据
2、嵌套表
嵌套表和index-by表相比少了index by binary_integer子句。这也是区分两种表的区别。
–嵌套表声明语法
type table_name IS table of table_type[not null];
–嵌套表的初始化
declare
type StudyTab IS table of varchar(20);
v_StudyTab StudyTab:=StudyTab(‘Tom‘,‘Jack‘,‘Rose‘);
begin
for v_Count IN 1..3 loop
DBMS_OUTPUT.put_line(v_StudyTab(v_Count));
end loop;
end;
3 index-by表:
如果声明类型之后,再声明一个index-by表变量类型,如果没有给该表赋值,那么这个表就是空的,后面可以继续添加
4 嵌套表:
声明嵌套表变量类型时,如果表中没有任何元素,会初始化为null,并且是只读的,如果再添加元素就会出现错误
ERROR
初始化为null后添加元素:引用未初始化的收集
初始化赋值后添加元素:下标超出数量
元素的序列
嵌套表和index-by表很相似,但是嵌套表在结构上是有序的,index-by表是无序的,给嵌套表赋值,下标从1开始,而且依次递增。
declare
type NumTab is Table of Numer(4);
v_Num NumTab:=NumTab(1,2,4,5,7,9);
begin
for v_Count IN 1..6 loop
DBMS_OUTPUT.put_line(‘v_Num(‘||v_Count||‘)=‘||v_Num(v_Count));
END LOOP
END;
上面赋值后的下标依次是:1,2,3,4,5,6
3、可变数组
可变数组声明
—数组声明语法—
type type_name IS {varray|varying array}(maxinum_size)
OF element_type[not null];
–type_name:可变数组的类型名
–maxinum_size:可变数组元素个数的最大值
–element_type:数组元素的类型
—创建一个数组—
declare
–包含星期数组
type Dates IS varray(7) OF varchar2(10);
–包含月份数组
type Months IS varray(12) OF varchar2(10);
—数组的初始化—
declare
type Dates IS varray(7) OF varchar2(10);
v_Dates Dates:=Dates(‘Monday‘,‘Tuesday‘,‘Wednesday‘);
begin
DBMS_OUTPUT.put_line(v_Dates(1));
DBMS_OUTPUT.put_line(v_Dates(2));
DBMS_OUTPUT.put_line(v_Dates(3));
end;
4、集合的属性和方法
index-by表,嵌套表,可变数组是对象类型,本身具有属性和方法。
count:返回集合中数组元素的个数
delete:删除集合中一个或多个元素
delete—删除所有元素
delete(x)—删除第x位置的元素
delete(x,y)—删除两个位置之间的元素
extist:判断集合中元素是否存在
extists(x)—判断x位置的元素是否存在
extend把元素添加到集合末端
extend把一个null元素添加到集合中
extend(x)—将x个null元素添加到集合的末端
extend(x,y)—将x个位于y的元素添加到集合的末端
first和last:first返回集合的第一个元素位置,last返回集合的最后一个元素位置
limit:返回集合中最大元素的个数,嵌套表没有上限,返回null
next(x),prior(x):返回x处元素的前后的元素
trim:删除几个末端的元素
trim—从几个末端删除一个元素
trim(x)—从几个末端删除x个元素,x小于集合的count总数
declare
type Dates IS varray(7) OF varchar2(10);
v_Dates Dates:=Dates(‘Monday‘,‘Tuesday‘,‘Wednesday‘);
begin
DBMS_OUTPUT.put_line(v_Dates.Count);
DBMS_OUTPUT.put_line(V_Dates.last);
end;
1、匿名语句块:
不能存储于数据库之中
每次执行都需要重新编译
不能被其他模块调用
2、命名语句块:
编译并存储于数据库中
可以在其他地方调用
可以输入输出参数
3、命名语句块包括:
(1)存储过程 PROCEDURE
(2)函数 FUNCTION
(3)触发器 TRIGGER
(4)包 PACKAGE
4、存储过程创建语法:
CREATE OR REPLACE PROCEDURE procedure_name
[(
arg_name1 [{IN,OUT,IN OUT}] TYPE,
...
arg_namen [{IN,OUT,IN OUT}] TYPE
)]
IS/AS
--声明部分
BEGIN
...
EXCEPTION
...
END;
参数类型:
IN:只读
OUT:只写
IN OUT:可读可写
存储过程的使用:
注意:存储过程传参数时不能指定形参的长度,只有类型。
形参类型有三种:in. out. in out.默认为in
注:IN OUT或OUT参数对应的实际参数必须是变量,
不能是常量或表达式。
5、调用方式:
1.直接执行:
exec/execute my_procedure_name(..);
2.在其他地方调用
begin
my_procedure(...);
end;
/
3.call my_procedure();
4.利用jdbc调用存储过程:
通过id显示雇员名
6、传参方式:
位置标示法
调用时添入所有参数,实参与形参按顺序一一对应
名字标示法
调用时给出形参名字,并给出实参
ModeTest(12,
p_OutParm => v_var1,
p_InOut => 10);
两种方法可以混用
名字标示法对于参数很多时,可提高程序的可读性
7、删除过程:
drop procedure pro_name;
8、查看过程、函数内容:
select text from all_source where name=upper(‘&plsql_name‘);
9、存储过程计算区域的例子
/*
praent_id是父区域id
1.新建一张表,字段:区域id、区域名称、上级区域名称、上级区域id、区域级别;
2.循环遍历rm_area表的所有记录,取id、名称、上级区域id、上级区域名称,计算当前区域的级别,插入上述表。
*/
–最终版!!!递归解决
create or replace procedure f_area1(c_area_supid in number,
c_area_supname in varchar2,
c_i in number) is
v_area_sup_id number(24); --父区域的id
/* v_area_name varchar2(255); --当前区域的名字
v_area_id number(24); --当前区域的id
v_area_sup_id number(24); --父区域的id
v_area_sup_name varchar2(255); --父区域名字
v_i number := 0; --区域级别*/
begin
/* v_area_sup_id := c_area_supid; --父区域的id
v_area_sup_name := c_area_supname; --父区域名字
v_i := c_i; --区域级别
*/
FOR c_rm_area IN (SELECT id, name
FROM rm_area
where parent_id is null
) LOOP
v_area_sup_id := c_rm_area.id;
insert into area_01
(area_id, area_name, area_sup_id, area_sup_name, area_level)
values
(c_rm_area.id, c_rm_area.name, c_area_supid, c_area_supname, c_i);
f_area2(c_rm_area.id,c_rm_area.name,c_i+1);
/* --获取总的便利出的长度
select count(1)
into v_count
from rm_area
where parent_id = c_rm_area.id;
--判断一下当前区域的id作为父id是否有区域,有区域在遍历
if v_count > 0 then
--说明存在,存在就继续遍历当前id,name赋值
f_area1(c_rm_area.id, c_rm_area.name, c_i + 1);
elsif v_count = 0 then
\* EXIT WHEN c_rm_area%notfound; --如果没有找到就推出当前for循环* null;
end if;*/
end loop;
commit;
end;
create or replace procedure f_area2(c_area_supid in number,
c_area_supname in varchar2,
c_i in number)
is
v_count number(24); --总的数量
begin
FOR c_rm_area IN (SELECT id, name
FROM rm_area
where parent_id = c_area_supid) LOOP
insert into area_01
(area_id, area_name, area_sup_id, area_sup_name, area_level)
values
(c_rm_area.id, c_rm_area.name, c_area_supid, c_area_supname, c_i);
--获取总的便利出的长度
select count(1)
into v_count
from rm_area
where parent_id = c_rm_area.id;
--判断一下当前区域的id作为父id是否有区域,有区域在遍历
if v_count > 0 then
--说明存在,存在就继续遍历当前id,name赋值
f_area2(c_rm_area.id, c_rm_area.name, c_i + 1);
elsif v_count = 0 then
/* EXIT WHEN c_rm_area%notfound; --如果没有找到就推出当前for循环*/
null;
end if;
end loop;
end;
1、函数与存储过程相同点:
都有名字
都有统一的形式:
都可以存储在数据库中声明,执行与异常处理
2、差别:
存储过程调用 本身是一个PL/SQL语句
函数调用 则是PLSQL语句的一部分
v_count:=my_function(table_name);
函数有返回值而存储过程没有
函数可以在SQL语句中调用
v_name:=myfun(1);
CREATE [OR REPLACE] FUNCTION func_name
[(
arg_name1 [{IN,OUT,IN OUT}] TYPE,
...
arg_namen [{IN,OUT,IN OUT}] TYPE
)]
RETURN TYPE --返回类型
IS/AS
--声明部分
BEGIN
...
EXCEPTION
...
END;
1、标识符不同。函数的标识符为FUNCTION,过程为:PROCEDURE。
2、函数中一般不用变量形参,用函数名直接返回函数值;而过程如有返回值,则必须用变量形参返回。
3、过程无类型,不能给过程名赋值;函数有类型,最终要将函数值传送给函数名。
4、函数在定义时一定要进行函数的类型说明,过程则不进行过程的类型说明。
5、调用方式不同。函数的调用出现在表达式中,过程调用,由独立的过程调用语句来完成。
6、过程一般会被设计成求若干个运算结果,完成一系列的数据处理,或与计算无关的各种操作;而函数往往只为了求得一个函数值
function 可以使用在表达式中 x := func();procedure不能
function 可以做为表达式 select func() from dual;procedure 不能
function 不能BEGIN func();END;;procedure 可以
3、RETURN的使用:
与其他语言的RETURN相同
PLSQL的FUNCTION要求必须拥有一个要执行到的RETURN
当有异常处理部分的时候,必须在每种异常处理部分(when .. then ..)有一个return
函数的plsql块中调用:
declare
v_name varchar2(20);
begin
v_name:=myfun(1);
dbms_output.put_line(v_name);
end;
/
4、函数的sql语句中的调用
select myfun(1) from dual;
函数的删除:
drop function function_name;
如果要在oracle中定义包,那么需要定义两个组成部分
包规范:相当于java中的接口。
包体:相当于java接口的实现类
包是可以将逻辑上相关的对象存储在一起的PL/SQL结构
包中可以包括:
变量、游标、RECORD、TABLE、存储过程、函数等,
声明部分出现的任何东西都能出现在包中。
包中的内容可以在其他地方使用或调用,是全局的内容。
PACKAGE内容包括:包头、包体
包头:包含了包的所有信息,但不包括任何过程代码。
包体:包含了包头声明的procedure、function的过程代码。
使用:
包名.函数名
包名.过程名
例如:
dbms_output.put_line(‘hello‘);
注:包头与包体分开创建,只有包头创建成功才可以创建包体。
1、创建包头:
CREATE [OR REPLACE] PACKAGE pack_name { IS | AS }
procedure_specification |
function_ specification |
variable_declaration |
type_definition |
exception_declaration |
cursor_declaration
procedure package_procedure;
function package_function
return varchar2;
END pack_name;
create or replace package myp
is
procedure mypro;
function myfun return varchar2;
end myp;
/
2、创建包体:
CREATE OR REPLACE PACKAGE BODY pak_test AS
PROCEDURE AddStudent(p_StuID IN students.id%TYPE,
p_Dep IN classes.department%TYPE,
p_Course IN classes.course%TYPE) IS
BEGIN
…
END AddStudent;
PROCEDURE RemoveStudent(p_StuID IN students.id%TYPE) IS
BEGIN
…
END RemoveStudent;
END pak_test;
3、包中内容的使用:
包中的内容在包内可以直接使用
包中的内容在包外,需使用加上"包名."前缀进行使用
每一个会话在第一次使用包时,初始化并拥有一个包中所有变量的副本。
4、包的第一个例子
–定义包
create or replace package mldn_pkg
function get_emp_fun(p_dno s_dept.id%type) return SYS_REFCURSOR;--返回游标变量
end;
/
–此时返回的是多条记录,所以使用了强类型的游标变量进行的操作,但是只有包规范还是无法使用包体,包体的名字一定要和包规范统一的。
–范例:定义包体
create or replace package body mldn_pkg
as
function get_emp_fun(p_dno s_dept.id%type) return SYS_REFCURSOR
as
cur_var sys_refcursor;
begin
open cur_var for select * from s_dept where id = p_dno.id --打开游标
return cur_var;
end;
end;
/
–列object_type是包类型,有PACKAGE和PACKAGE BODY
select * user_object;--查询所有对象
–条件就是上一部对象名字
select * from user_source ;--查看源代码
– Created on 2017/1/5 by SHINE
declare
-- Local variables here
v_receive sys_refcursor;
v_deptRow s_dept%rowtype;
begin
-- Test statements here
v_receive := mldn_pkg.get_emp_fun(10);--调用包中的操作
loop--循环遍历
fetch v_receive into v_deptRow;
exit when v_receive%notfound;
dbms_output.put_line(v_deptRow.id||‘-‘||v_deptRow.name);
end loop;
end;
drop package mldn_pkg;
alter package mldn_pkg compile body;
5、包的第二个例子,包的作用域
–包的作用域
–在包规范中定义一个变量
create or replace package pkg_1
as
v_dept s_dept.id%type :=10;
function get_emp_fun(p_eno s_emp.id%type) return s_emp%rowtype;
end;
/
create or replace package body pkg_1
as
function get_emp_fun(p_eno s_emp.id%type) return s_emp%rowtype
as
v_empRow s_emp%rowtype;
begin
select * into v_empRow from s_emp
where id = p_eno and dept_id = v_dept;
return v_empRow;
end;
/
–给从新赋值,下面两个一起执行才能有结果,要不找不到
begin
pkg_1.v_dept :=50;
end;
/
declare
v_empResult s_emp%rowtype;
begin
v_empResult := pkg_1.get_emp_fun(1);
dbms_output.put_line(pkg_1.v_dept);
dbms_output.put_line(v_empResult.last_name||‘-‘||v_empResult.id);
end;
/

5、Oracle的第三个例子,存储过程重载
–重载包中的子程序
create or replace package emp_delete_pkg
as
--根据雇员信息删除雇员信息
procedure delete_emp_proc(p_empno s_emp.id%type);
--根据雇员姓名删除雇员信息
procedure delete_emp_proc(p_empname s_emp.last_name%type);
--根据员工所在部门及职位删除雇员信息
procedure delete_emp_proc(p_depton s_emp.dept_id%type);
end;
create or replace package body emp_delete_pkg
as
emp_delete_exception exception;
--根据雇员信息删除雇员信息
procedure delete_emp_proc(p_empno s_emp.id%type)
as
begin
delete from s_emp where id=p_empno;
if sql%notfound then
raise emp_delete_exception;
end if;
commit;
exception
when emp_delete_exception then
null;
end delete_emp_proc;
--根据雇员姓名删除雇员信息
procedure delete_emp_proc(p_empname s_emp.last_name%type)
as
begin
delete from s_emp where last_name=p_empname;
if sql%notfound then
raise emp_delete_exception;
end if;
end delete_emp_proc;
--根据员工所在部门及职位删除雇员信息
procedure delete_emp_proc(p_depton s_emp.dept_id%type)
as
begin
delete from s_emp where dept_id=p_depton;
if sql%notfound then
raise emp_delete_exception;
end if;
end delete_emp_proc;
end emp_delete_pkg;
exec emp_delete_pkg.delete_emp_proc(‘Velasquez‘);
注意:当重载的存储过程参数类型或者参数数目不一致时,就会报错哦!
正确结果:
后续补充
1、在Oracle中执行动态SQL的几种方法
在一般的sql操作中,sql语句基本上都是固定的,如:
SELECT t.empno,t.ename FROM scott.emp t WHERE t.deptno = 20;
但有的时候,从应用的需要或程序的编写出发,都可能需要用到动态SQl,如:
当 from 后的表 不确定时,或者where 后的条件不确定时,都需要用到动态SQL。
一、使用动态游标实现
1、声明动态游标
TYPE i_cursor_type IS REF CURSOR;
2、声明游标变量
my_cursor i_cursor_type;
3、使用游标
n_deptno:=20;
dyn_select := ‘select empno,ename from emp where deptno=‘||n_deptno;
OPEN my_cursor FOR dyn_select;
LOOP
FETCH my_cursor INTO n_empno,v_ename;
EXIT WHEN my_cursor%NOTFOUND;
--用n_empno,v_ename做其它处理
--....
END LOOP;
CLOSE dl_cursor;
4、小结:
动态游标可以胜任大多数动态SQL的需求了,使用简洁方便居家旅行之必备杀人放火之法宝。
二、使用 EXECUTE IMMEDIATE
最早大家都使用DBMS_SQL包,但是太太麻烦了,最终都放弃了。但是自从有了EXECUTE IMMEDIATE之后,但要注意以下几点:
EXECUTE IMMEDIATE代替了以前Oracle8i中DBMS_SQL package包.它解析并马上执行动态的SQL语句或非运行时创建的PL/SQL块.动态创建和执行SQL语句性能超前,EXECUTE IMMEDIATE的目标在于减小企业费用并获得较高的性能,较之以前它相当容易编码.尽管DBMS_SQL仍然可用,但是推荐使用EXECUTE IMMEDIATE,因为它获的收益在包之上。
使用技巧
1. EXECUTE IMMEDIATE将不会提交一个DML事务执行,应该显式提交
如果通过EXECUTE IMMEDIATE处理DML命令,那么在完成以前需要显式提交或者作为EXECUTE IMMEDIATE自己的一部分. 如果通过EXECUTE IMMEDIATE处理DDL命令,它提交所有以前改变的数据
2. 不支持返回多行的查询,这种交互将用临时表来存储记录(参照例子如下)或者用REF cursors.
3. 当执行SQL语句时,不要用分号,当执行PL/SQL块时,在其尾部用分号.
4. 在Oracle手册中,未详细覆盖这些功能。下面的例子展示了所有用到Execute immediate的可能方面.希望能给你带来方便.
5. 对于Forms开发者,当在PL/SQL 8.0.6.3.版本中,Forms 6i不能使用此功能.
EXECUTE IMMEDIATE用法例子
1. 在PL/SQL运行DDL语句
begin
execute immediate ‘set role all‘;
end;
2. 给动态语句传值(USING 子句)
declare
l_depnam varchar2(20) := ‘testing‘;
l_loc varchar2(10) := ‘Dubai‘;
begin
execute immediate ‘insert into dept values (:1, :2, :3)‘
using 50, l_depnam, l_loc;
commit;
3. 从动态语句检索值(INTO子句)
declare
l_cnt varchar2(20);
begin
execute immediate ‘select count(1) from emp‘
into l_cnt;
dbms_output.put_line(l_cnt);
end;
4. 动态调用例程.
例程中用到的绑定变量参数必须指定参数类型.黓认为IN类型,其它类型必须显式指定
declare
l_routin varchar2(100) := ‘gen2161.get_rowcnt‘;
l_tblnam varchar2(20) := ‘emp‘;
l_cnt number;
l_status varchar2(200);
begin
execute immediate ‘begin ‘ || l_routin || ‘(:2, :3, :4); end;‘
using in l_tblnam, out l_cnt, in out l_status;
if l_status != ‘OK‘ then
dbms_output.put_line(‘error‘);
end if;
end;
5. 将返回值传递到PL/SQL记录类型;
同样也可用%rowtype变量
declare
type empdtlrec is record (empno number(4),ename varchar2(20),deptno number(2));
empdtl empdtlrec;
begin
execute immediate ‘select empno, ename, deptno ‘||‘from emp where empno = 7934‘
into empdtl;
end;
6. 传递并检索值.INTO子句用在USING子句前
declare
l_dept pls_integer := 20;
l_nam varchar2(20);
l_loc varchar2(20);
begin
execute immediate ‘select dname, loc from dept where deptno = :1‘
into l_nam, l_loc
using l_dept ;
end;
7.多行查询选项.
对此选项用insert语句填充临时表,用临时表进行进一步的处理,也可以用REF cursors纠正此缺憾.
declare
l_sal pls_integer := 2000;
begin
execute immediate ‘insert into temp(empno, ename) ‘ ||
‘ select empno, ename from emp ‘ ||
‘ where sal > :1‘
using l_sal;
commit;
end;
对于处理动态语句,EXECUTE IMMEDIATE比以前可能用到的更容易并且更高效.当意图执行动态语句时,适当地处理异常更加重要.应该关注于捕获所有可能的异常.
8.实例一
Oracle 动态SQL
Oracle 动态SQL有两种写法:用 DBMS_SQL 或 execute immediate,建议使用后者。试验步骤如下:
1. DDL 和 DML
1./*** DDL ***/
2.begin
3. EXECUTE IMMEDIATE ‘drop table temp_1‘;
4. EXECUTE IMMEDIATE ‘create table temp_1(name varchar2(8))‘;
5.end;
6.
7./*** DML ***/
8.declare
9. v_1 varchar2(8);
10. v_2 varchar2(10);
11. str varchar2(50);
12.begin
13. v_1:=‘测试人员‘;
14. v_2:=‘北京‘;
15. str := ‘INSERT INTO test (name ,address) VALUES (:1, :2)‘;
16. EXECUTE IMMEDIATE str USING v_1, v_2;
17. commit;
18.end;
2. 返回单条结果
1.declare
2. str varchar2(500);
3. c_1 varchar2(10);
4. r_1 test%rowtype;
5.begin
6. c_1:=‘测试人员‘;
7. str:=‘select * from test where name=:c WHERE ROWNUM=1‘;
8. execute immediate str into r_1 using c_1;
9. DBMS_OUTPUT.PUT_LINE(R_1.NAME||R_1.ADDRESS);
10.end ;
3. 返回结果集
1.CREATE OR REPLACE package pkg_test as
2. /* 定义ref cursor类型
3. 不加return类型,为弱类型,允许动态sql查询,
4. 否则为强类型,无法使用动态sql查询;
5. */
6. type myrctype is ref cursor;
7.
8. --函数申明
9. function get(intID number) return myrctype;
10.end pkg_test;
11./
12.
13.CREATE OR REPLACE package body pkg_test as
14.--函数体
15. function get(intID number) return myrctype is
16. rc myrctype; --定义ref cursor变量
17. sqlstr varchar2(500);
18. begin
19. if intID=0 then
20. --静态测试,直接用select语句直接返回结果
21. open rc for select id,name,sex,address,postcode,birthday from
22.student;
23. else
24. --动态sql赋值,用:w_id来申明该变量从外部获得
25. sqlstr := ‘select id,name,sex,address,postcode,birthday from student
26.where id=:w_id‘;
27. --动态测试,用sqlstr字符串返回结果,用using关键词传递参数
28. open rc for sqlstr using intid;
29. end if;
30.
31. return rc;
32. end get;
33.
34.end pkg_test;
35./
sql server 自定义函数的使用
自定义函数
用户定义自定义函数像内置函数一样返回标量值,也可以将结果集用表格变量返回
用户自定义函数的类型:
标量函数:返回一个标量值
表格值函数{内联表格值函数、多表格值函数}:返回行集(即返回多个值)
1、标量函数
Create function 函数名(参数)
Returns 返回值数据类型
[with {Encryption | Schemabinding }]
[as]
begin
SQL语句(必须有return 变量或值)
End
Schemabinding :将函数绑定到它引用的对象上(注:函数一旦绑定,则不能删除、修改,除非删除绑定)
Create function AvgResult(@scode varchar(10))
Returns real
As
Begin
Declare @avg real
Declare @code varchar(11)
Set @code=@scode + ‘%’
Select @avg=avg(result) from LearnResult_baijiali
Where scode like @code
Return @avg
End
执行用户自定义函数
select 用户名。函数名 as 字段别名
select dbo.AvgResult(‘s0002’) as result
用户自定义函数返回值可放到局部变量中,用set ,select,exec赋值
declare @avg1 real ,@avg2 real ,@avg3 real
select @avg1= dbo.AvgResult(‘s0002’)
set @avg2= dbo.AvgResult(‘s0002’)
exec @avg3= dbo.AvgResult ‘s0002’
select @avg1 as avg1 ,@avg2 as avg2 ,@avg3 as avg3
函数引用
create function code(@scode varchar(10))
returns varchar(10)
as
begin
declare @ccode varchar(10)
set @scode = @scode + ‘%’
select @ccode=ccode from cmessage
where ccode like @scode
return @ccode
end
select name from class where ccode = dbo.code(‘c001’)
2、表格值函数
a、 内联表格值函数
格式:
create function 函数名(参数)
returns table
[with {Encryption | Schemabinding }]
as
return(一条SQL语句)
create function tabcmess(@code varchar(10))
returns table
as
return(select ccode,scode from cmessage where ccode like @ccode)
b、 多句表格值函数
create function 函数名(参数)
returns 表格变量名table (表格变量定义)
[with {Encryption | Schemabinding }]
as
begin
SQL语句
end
多句表格值函数包含多条SQL语句,至少有一条在表格变量中填上数据值
表格变量格式
returns @变量名 table (column 定义| 约束定义 [,…])
对表格变量中的行可执行select,insert,update,delete , 但select into 和 insert 语句的结果集是从存储过程插入。
Create function tabcmessalot (@code varchar(10))
Returns @ctable table(code varchar(10) null,cname varchar(100) null)
As
Begin
Insert @ctable
Select ccode,explain from cmessage
Where scode like @code
return
End
Select * from tabcmessalot(‘s0003’)
9.实例二
–1、存储过程不能直接写ddl语句
create or replace function get_table_count_fun(p_table_name varchar2)
return number
as
begin
create table p_table_name(
id number,
name varchar2,
constraint pk_d primary key(id)
);
return 0;
end;
/
–2、使用动态sql写ddl语句
create or replace function get_table_count_fun(p_table_name varchar2)
return number
as
sql_1 varchar2(1000);
v_count number;
begin
--首先判断一下表是否存在
select count(*) into v_count from user_tables where table_name = upper(p_table_name);
if v_count<=0 then
--等于0表不存在
sql_1 := ‘create table ‘|| p_table_name ||‘(
id number,
name varchar2(255),
constraint ‘||p_table_name||‘_pk_id‘||‘ primary key(id)
)‘;
dbms_output.put_line(sql_1);
execute immediate sql_1;
else
dbms_output.put_line(p_table_name||‘: 这个表已经存在!‘);
end if;
return 0;
end;
/
begin
dbms_output.put_line(get_table_count_fun(‘jack_DRN‘));
end;
/
–EXECUTE IMMEDIATE 语句
在动态sql中execute immediate 是最重要的执行命令,使用此语句可以方便在pl/SQL程序之中执行
DML(insert update select delete),DDL(create alter drop),DCL(GRANT ,REVOKE )语句,execute 语法如下所示:
execute immediate 动态sql字符串[[BULK COLLECT ] INTO 自定义变量,....|记录类型]
[USING[IN|OUT|IN OUT]绑定参数,...]
[[RETURNING|RETURN][BULK COLLECT]INTO 绑定参数,....];
在EXECUTE IMMEDIATE 由以下三个主要语句组成:
INTO:保存动态sql执行的结果,如果返回多行记录可以通过bulk collect 设置批量保存:
USING:用来为动态SQL设置占位符设置内容
RETURNING|RETURN :两者使用效果一样,是取得更新表记录影响的数据,通过BULK COLLECT 来批量绑定
declare
v_sql_statement varchar2(200);
v_count number;
begin
select count(*) into v_count from user_tables where table_name = ‘MLDN_TABLE‘;
if v_count = 0 then
v_sql_statement := ‘create table mldn_table(
id number primary key,
url varchar2(50) NOT NULL)‘;
EXECUTE IMMEDIATE v_sql_statement;
else --数据表存在
v_sql_statement :=‘truncate table mldn_table‘;
execute immediate v_sql_statement;
END IF;
v_sql_statement := ‘BEGIN
FOR X IN 1..10 LOOP
INSERT INTO mldn_table(ID,URL) VALUES(X,‘‘WWW.BAIDU.COM‘‘||X);
END LOOP;
END;‘;
EXECUTE IMMEDIATE v_sql_statement;
commit;
end;
/
select count(*) from user_tables
–设置绑定变量使用占位符
–练习一
declare
v_sql_statement varchar2(200);
v_deptno number := 60;
v_dname varchar2(25):=‘张三‘;
v_loc varchar2(50):=‘beijing‘;
begin
/*execute immediate ‘create table dept(
id number primary key ,
name varchar2(25),
loc varchar2(50)
)‘;
*/
v_sql_statement := ‘insert into dept(id,name,loc) values(:id,:name,:loc)‘;
execute immediate v_sql_statement using v_deptno,v_dname,v_loc;
end;
/
–练习二
declare
v_sql_statement varchar2(200);
type deptno_dested is table of dept.id%type not null;
type dname_nested is table of dept.name%type not null;
v_deptno deptno_dested := deptno_dested(10,20,30,40);
v_deptname dname_nested := dname_nested(‘销售部‘,‘事业部‘,‘交付2部‘,‘研发部‘);
begin
v_sql_statement := ‘insert into dept(id,name,loc) values(:id,:name,:loc)‘;
for x in 1..v_deptno.count loop
execute immediate v_sql_statement using v_deptno(x),v_deptname(x),v_deptname(x);
end loop;
end;
/
–练习三
declare
v_sql_statement varchar2(200);
v_deptno dept.id%type := 10;
v_deptRow dept%rowtype;
begin
v_sql_statement :=‘select * from dept where id = :eno‘;
execute immediate v_sql_statement into v_deptRow using v_deptno;
dbms_output.put_line(‘雇员编号:‘||v_deptRow.id ||‘部门名称:‘||v_deptRow.name);
end;
/
–练习四(这个时候只能用拼接sql语句完成不能用占位符)
declare
v_sql_statement varchar2(200);
v_table_name varchar2(200) := ‘mldn‘;
v_id_column varchar2(200):= ‘id‘;
begin --创建表的操作上使用的占位符
v_sql_statement := ‘create table :tn(:ic number primary key )‘;
execute immediate v_sql_statement using v_table_name,v_id_column;
end;
/
–练习四_2(这个是可以的)
declare
v_sql_statement varchar2(200);
v_table_name varchar2(200) := ‘mldn‘;
v_id_column varchar2(200):= ‘id‘;
begin --创建表的操作上使用的占位符
v_sql_statement := ‘create table ‘||v_table_name||‘(‘||v_id_column||‘ number primary key )‘;
execute immediate v_sql_statement;
end;
/
–练习五returning用法
declare
v_sql_statement varchar2(200);
v_deptno dept.id%type := 10;
v_deptname dept.name%type:=‘DRN123‘;
v_count number;
v_deptloc dept.loc%type;
v_deptname1 dept.name%type;
begin
v_sql_statement := ‘update dept set name = :name where id = :id return name,loc into :deptname1,:v_deptloc‘;
execute immediate v_sql_statement using v_deptname,v_deptno return into v_deptname1,v_deptloc;
dbms_output.put_line(‘调整后:名字叫做‘||v_deptname||‘个更新了:‘||v_count||‘条数据‘);
end;
/
–练习六returning用法
–对于using和returning语句也可以设置参数模式,in,out,in out,默认的模式是in模式,而对于returning采用的是out模式
declare
v_sql_statement varchar2(200);
v_deptno dept.id%type := 10;
v_count number;
v_name dept.name%type;
v_loc dept.loc%type;
begin
v_sql_statement := ‘delete from dept where id = :id returning name,loc into :v_name,:v_loc‘;
execute immediate v_sql_statement using v_deptno returning into v_name,v_loc;
dbms_output.put_line(v_count||‘条数据被删除!‘||‘删除数据为:‘||v_name||‘ ‘||v_loc);
end;
/
–希望动态执行的时候可以把p_deptno内容带回来
create or replace procedure dept_insert_proc(
p_deptno in out dept.id%type,
p_dname dept.name%type,
p_loc dept.loc%type
)as
begin
select max(id) into p_deptno from dept;
p_deptno := p_deptno + 1;
insert into dept(id,name,loc) values(p_deptno,p_dname,p_loc);
end;
/
----------
declare
v_sql_statement varchar2(200);
v_deptno dept.id%type;
v_name dept.name%type :=‘电信交付2部‘;
v_loc dept.loc%type := ‘北京‘;
begin
v_sql_statement := ‘begin dept_insert_proc(:id,:name,:loc); end;‘;
execute immediate v_sql_statement using in out v_deptno, in out v_name,in out v_loc;
dbms_output.put_line(‘新增的数据为:id ‘||v_deptno||‘名字:‘||v_name||‘loc为:‘||v_loc);
end;
10.关于returning的几个问题:
ORACLE的DML语句中可以指定RETURNING语句。RETURNING语句的使用在很多情况下可以简化PL/SQL编程。
这里不打算说明RETURNING语句的使用(其实使用起来也很简单,和SELECT INTO语句没有多大区别。),主要打算说明RETURNING语句的几个特点。
其实这篇文章源于同事问我的一个问题:
使用UPDATE语句的时候,RETURNING得到的结果是UPDATE之前的结果还是UPDATE之后的结果?
这个问题把我问住了。考虑DELETE的情况,RETURNING返回的肯定是DELETE之前的结果,而考虑INSERT的情况,RETURNING返回的一定是INSERT之后的结果。但是UPDATE到底返回那种情况,就无法推断出来了。而且,由于一般在使用UPDATE的RETURNING语句时,都会返回主键列,而主键列一般都是不会修改的,因此确实不清楚Oracle返回的是UPDATE之前的结果还是之后的结果。
当然,一个简单的例子就可以测试出来:
SQL> CREATE TABLE T (ID NUMBER, NAME VARCHAR2(30));
表已创建。
SQL> SET SERVEROUT ON
SQL> DECLARE
2 V_NAME VARCHAR2(30);
3 BEGIN
4 INSERT INTO T VALUES (1, ‘YANGTK‘) RETURNING NAME INTO V_NAME;
5 DBMS_OUTPUT.PUT_LINE(‘INSERT: ‘ || V_NAME);
6 V_NAME := NULL;
7 UPDATE T SET NAME = ‘YTK‘ RETURNING NAME INTO V_NAME;
8 DBMS_OUTPUT.PUT_LINE(‘UPDATE: ‘ || V_NAME);
9 V_NAME := NULL;
10 DELETE T RETURNING NAME INTO V_NAME;
11 DBMS_OUTPUT.PUT_LINE(‘DELETE: ‘ || V_NAME);
12 END;
13 /
INSERT: YANGTK
UPDATE: YTK
DELETE: YTK
PL/SQL 过程已成功完成。
显然,UPDATE操作的RETURNING语句是返回UPDATE操作之后的结果。
顺便总结几个RETURNING操作相关的问题:
1.RETURNING语句似乎和RETURN通用。
SQL> SET SERVEROUT ON
SQL> DECLARE
2 V_NAME VARCHAR2(30);
3 BEGIN
4 INSERT INTO T VALUES (1, ‘YANGTK‘) RETURN NAME INTO V_NAME;
5 DBMS_OUTPUT.PUT_LINE(‘INSERT: ‘ || V_NAME);
6 V_NAME := NULL;
7 UPDATE T SET NAME = ‘YTK‘ RETURN NAME INTO V_NAME;
8 DBMS_OUTPUT.PUT_LINE(‘UPDATE: ‘ || V_NAME);
9 V_NAME := NULL;
10 DELETE T RETURN NAME INTO V_NAME;
11 DBMS_OUTPUT.PUT_LINE(‘DELETE: ‘ || V_NAME);
IXDBA.NET技术社区
12 END;
13 /
INSERT: YANGTK
UPDATE: YTK
DELETE: YTK
PL/SQL 过程已成功完成。
2.RETURNING语句也可以使用SQLPLUS的变量,这样,RETURNING语句不一定非要用在PL/SQL语句中。
SQL> VAR V_NAME VARCHAR2(30)
SQL> INSERT INTO T VALUES (1, ‘YANGTK‘) RETURNING NAME INTO :V_NAME;
已创建 1 行。
SQL> PRINT V_NAME
V_NAME
YANGTK
SQL> UPDATE T SET NAME = ‘YTK‘ RETURNING NAME INTO :V_NAME;
已更新 1 行。
SQL> PRINT V_NAME
V_NAME
YTK
SQL> DELETE T RETURNING NAME INTO :V_NAME;
已删除 1 行。
SQL> PRINT V_NAME
V_NAME
YTK
3.INSERT INTO VALUES语句支持RETURNING语句,而INSERT INTO SELECT语句不支持。MERGE语句不支持RETURNING语句。
SQL> MERGE INTO T USING (SELECT * FROM T) T1
2 ON (T.ID = T1.ID)
3 WHEN MATCHED THEN UPDATE SET NAME = T1.NAME
4 WHEN NOT MATCHED THEN INSERT VALUES (T1.ID, T1.NAME)
5 RETURNING NAME INTO :V_NAME;
RETURNING NAME INTO :V_NAME
*第 5 行出现错误:
ORA-00933: SQL 命令未正确结束
SQL> INSERT INTO T SELECT * FROM T RETURNING NAME INTO :V_NAME;
INSERT INTO T SELECT * FROM T RETURNING NAME INTO :V_NAME
*第 1 行出现错误:
ORA-00933: SQL 命令未正确结束
这两个限制确实不大方便。不知道Oracle在以后版本中是否会放开。
个人感觉RETURNING语句和BULK COLLECT INTO语句配合使用的机会更多一些。
使用游标,用于提取多行数据集。
1、cursor的使用步骤
1.声明游标(声明游标代表的查询语句)
2.为查询打开游标(执行查询语句)
3.将结果提取出来,存入PL/SQL变量中(遍历查询语句)
4.关闭游标
(1)、游标声明
CURSOR CURSOR_NAME IS select_statement
如果使用了PL/SQL变量在select_statement中,
变量的声明必须放在游标前面。
例如:
DELCARE
v_major students.major%TYPE;
CURSOR c_student IS
SELECT first_name, last_name
FROM students
WHERE major = v_major;
(2)、打开游标
OPEN Cursor_name
注:游标最多只能打开一次
(3)、从游标中取出数据 FETCH
FETCH Cursor_name into v_1,v_2
FETCH Cursor_name into v_rec
游标常用属性:
1、%ISOPEN:确定游标是否打开
2、%ROWCOUNT:当前游标的指针位移量,即当前检索的个数
3、%FOUND:若前面的FETCH语句返回一行数据,
则%FOUND返回TRUE;
如果未fetch就检查%FOUND,则返回NULL
4、%NOTFOUND:与%FOUND行为相反
注:%ROWCOUNT %FOUND %NOTFOUND均需要游标已打开
(4)、关闭
CLOSE CURSOR
游标关闭后不允许FETCH
游标只能关闭一次
(5)、遍历CURSOR
1.简单LOOP
LOOP
FETCH cursor INTO…
EXIT WHEN cursor%NOTFOUND;
END LOOP
2.WHILE
FETCH cursor INTO…
WHILE cursor%FOUND LOOP
FETCH cursor INTO…
END LOOP
3.FOR
FOR var IN cursor LOOP
--var既是提取出的RECORD,可以直接使用
END LOOP
注:使用FOR不需要对游标进行open,fetch与close
loop循环:
declare
v_num number(7):=10;
cursor mycur is
select * from s_emp
where id<v_num;
v_s s_emp%rowtype;
begin
open mycur;
loop
fetch mycur into v_s;
exit when mycur%NOTFOUND;
dbms_output.put_line(v_s.last_name);
end loop;
close mycur;
end;
/
while循环遍历游标:
declare
v_num number(7):=15;
cursor mycur is
select * from s_Emp
where id<v_num;
v_s s_emp%rowtype;
begin
open mycur;
fetch mycur into v_s;
while mycur%FOUND loop
dbms_output.put_line(v_s.title);
fetch mycur into v_s;
end loop;
if mycur%ISOPEN then
dbms_output.put_line(mycur%ROWCOUNT);
end if;
close mycur;
end;
/
for循环遍历游标,显示薪水小于1000的员工的名字
declare
cursor mycur is
select * from s_emp
where salary<1000;
v_s s_emp%rowtype;
begin
for v_s in mycur loop
dbms_output.put_line(v_s.last_name);
end loop;
end;
/
(6)、带参数的CURSOR
声明:
CURSOR cursor_name(v_field field_type)
is select * from mytable where c_column=v_field
使用:
open cursor_name(field_value);
declare
cursor mycur(v_id number)
select * from s_emp
where id<v_id;
v_s s_emp%rowtype;
begin
open mycur(15);
loop
fetch mycur into v_s;
exit when mycur%NOTFOUND;
dbms_output.put_line(v_s.last_name);
end loop;
close mycur;
end;
/
(7)、自定义游标
声明:
type my_cursor is ref cursor;
使用: v_cur my_cursor;
open v_cur for select * from student;
declare
type mycur is ref cursor;
v_cur mycur;
v_s s_Emp%rowtype;
begin
open v_cur for select *
from s_emp where salary>1500;
fetch v_cur into v_s;
while v_cur%FOUND loop
dbms_output.put_line(v_s.last_Name);
fetch v_cur into v_s;
end loop;
close v_cur;
end;
/
2、细分隐式游标例子
–隐式游标1
declare
v_count number;
begin
select count(1) into from v_count from dual;--返回一个记录
dbms_output.put_line(‘sql%rowcount = ‘||sql%rowcount);
end;
/
–隐式游标2
declare
begin
insert into s_dept values(12316,‘康师傅红烧牛肉面‘,12306);--也是返回一个记录
dbms_output.put_line(‘sql%rowcount = ‘||sql%rowcount);
end;
/
–隐式游标3
declare
begin
update s_emp set last_name=‘我爱吃红烧牛肉面‘;
dbms_output.put_line(‘sql%rowcount = ‘||sql%rowcount);--这回显示的就不是一条记录了,而是等于26了
rollback;
end;
/
–隐式游标4
declare
v_empRow s_emp%rowtype; --保存s_emp一行数据
begin
select * into v_empRow from s_emp where id=21;
if sql%found then--如果前面进行dml数据操作在%found返回结果就是true
dbms_output.put_line(‘雇员姓名:‘||v_empRow.last_name);
end if;
end;
/
–隐式游标5多行隐式右表,会返回多行记录
declare
begin
update s_emp set salary=salary*1.2 where salary>10000;
if sql%found then--如果前面进行dml数据操作在%found返回结果就是true
dbms_output.put_line(‘更新的记录行数:‘||sql%rowcount);
else
dbms_output.put_line(‘没有更新记录条数!‘);
end if;
end;
3、细分显示游标例子
–显式游标用while
declare
cursor cur_emp return s_emp%rowtype is select * from s_emp;
v_empRow s_emp%rowtype;--保存一行数据
v_num number;
begin
--游标如果要操作一定要保证其已经打开了
if cur_emp%isopen then
null;--如果打开什么也不做。
else
open cur_emp;--然后打开
end if;
--默认情况下游标在第一行记录上
fetch cur_emp into v_empRow; --取得当前行数据
while cur_emp%found loop
dbms_output.put_line(‘第‘||cur_emp%rowcount||‘行数据为:‘||v_empRow.last_name||‘-‘||v_empRow.dept_id||‘-‘||v_empRow.salary);--这里如果用cur_emp获取数据是不可以的,会报引用超出范围
fetch cur_emp into v_empRow;--从新把新的一行数据赋值给
end loop;
close cur_emp;--关闭游标
exception
when others then
--这里的异常只在
dbms_output.put_line(‘你说你是不是傻!!!‘);
end;
/
–显式游标用loop
declare
cursor cur_emp is select * from s_emp;
v_empRow s_emp%rowtype;–保存一行数据
v_num number;
begin
–游标如果要操作一定要保证其已经打开了
if cur_emp%isopen then
null;–如果打开什么也不做。
else
open cur_emp;–然后打开
end if;
–默认情况下游标在第一行记录上
loop
fetch cur_emp into v_emprow;--取得当前行数据
exit when cur_emp%notfound;--没有数据退出循环
dbms_output.put_line(‘第‘||cur_emp%rowcount||‘行数据为:‘||v_empRow.last_name||‘-‘||v_empRow.dept_id||‘-‘||v_empRow.salary);--这里如果用cur_emp获取数据是不可以的,会报引用超出范围
end loop;
close cur_emp;--关闭游标
exception
when others then
--这里的异常只在
dbms_output.put_line(‘你说你是不是傻!!!‘);
end;
/
–隐式游标用for(注意for循环不能获得当前执行的次数,不能用%rowcount)
declare
v_num number := 0;
begin
for cur_emp in (select * from s_emp) loop
v_num:=v_num+1;
dbms_output.put_line(‘第‘||v_num||‘行数据为:‘||cur_emp.last_name||‘-‘||cur_emp.dept_id||‘-‘||cur_emp.salary);--这里如果用cur_emp获取数据是不可以的,会报引用超出范围
end loop;
exception
when others then
--这里的异常只在
dbms_output.put_line(‘你说你是不是傻!!!‘);
end;
/
–显示游标用for(注意for循环的cur_emp不能获得当前执行的次数,不能用%rowcount只能用定义好的游标)
declare
cursor row_emp is select * from s_emp;
v_num number := 0;
begin
for cur_emp in row_emp loop
v_num:=v_num+1;
dbms_output.put_line(‘第‘||row_emp%rowcount||‘行数据为:‘||cur_emp.last_name||‘-‘||cur_emp.dept_id||‘-‘||cur_emp.salary);--这里如果用cur_emp获取数据是不可以的,会报引用超出范围
end loop;
exception
when others then
--这里的异常只在
dbms_output.put_line(‘你说你是不是傻!!!‘||sqlcode||‘-‘||sqlerrm);
end;
/
–利用索引赋值,在取值
declare
cursor cur_emp is select * from s_emp;
type emp_index is table of s_emp%rowtype index by pls_integer;
v_emp emp_index;
begin
for emp_row in cur_emp loop
v_emp(emp_row.id) := emp_row;
end loop;
dbms_output.put_line(‘ID:‘||v_emp(21).id||v_emp(21).last_name||‘-‘||v_emp(21).dept_id||‘-‘||v_emp(21).salary);
end;
/
一、对比区别:
1 select * from TTable1 for update 锁定表的所有行,只能读不能写
2 select * from TTable1 where pkid = 1 for update 只锁定pkid=1的行
3 select * from Table1 a join Table2 b on a.pkid=b.pkid for update 锁定两个表的所有记录
4 select * from Table1 a join Table2 b on a.pkid=b.pkid where a.pkid = 10 for update 锁定两个表的中满足条件的行
5. select * from Table1 a join Table2 b on a.pkid=b.pkid where a.pkid = 10 for update of a.pkid 只锁定Table1中满足条件的行
for update 是把所有的表都锁点 for update of 根据of 后表的条件锁定相对应的表
———–
关于NOWAIT(如果一定要用FOR UPDATE,我更建议加上NOWAIT)
当有LOCK冲突时会提示错误并结束STATEMENT而不是在那里等待(比如:要查的行已经被其它事务锁了,当前的锁事务与之冲突,加上nowait,当前的事务会结束会提示错误并立即结束 STATEMENT而不再等待).
如果加了for update后 该语句用来锁定特定的行(如果有where子句,就是满足where条件的那些行)。当这些行被锁定后,其他会话可以选择这些行,但不能更改或删除这些行,直到该语句的事务被commit语句或rollback语句结束为止。
因为FOR UPDATE子句获得了锁,所以COMMIT将释放这些锁。当锁释放了,该游标就无效了。
就是这些区别了
二、关于锁定指定列和表效果一样
问题,如下:select * from emp where empno = 7369 for update; 会对表中员工编号为7369的记录进行上锁。其他用户无法对该记录进行操作,只能查询。select * from emp where empno = 7369 for update of sal; 这条语句是不是意味着只对表中的7369 这一行的sal字段的数据进行了上锁,其他数据则可以被其他用户做更新操作呢。学员测试结果为二条语句的效果是一样的。其他用户对整行都无法更新,那么是不是意味着 for update of columns这句没有什么意义呢?
这个问题估计很多玩ORACLE的同学们都没有去思考过【网上相关的帖子不多】。现在将其功能讲解一下。
从单独一张表的操作来看,上面二条语句的效果确实是相同的。但是如果涉及到多表操作的时候 for update of columns就起到了非常大的作用了。现假定有二个用户,scott和mm。
scott执行语句:select * from emp e,dept d where e.deptno = d.deptno for update; --对二张表都进行了整表锁定
mm执行语句:select * from scott.dept for update wait 3; --试图锁定scott用户的dept表
结果是:
ERROR 位于第 1 行:
ORA-30006: 资源已被占用; 执行操作时出现 WAIT 超时
现在,scott用户先进行解锁rollback,再在for update语句后面加上of columns,进行测试
scott执行语句:select * from emp e,dept d where e.deptno = d.deptno for update of sal ;
mm执行语句:select * from scott.dept for update wait 3;
结果是:
成功锁定了dept表的数据.
mm再次执行语句:select * from scott.emp for update wait 3;
结果是:
ERROR 位于第 1 行:
ORA-30006: 资源已被占用; 执行操作时出现 WAIT 超时
通过这段代码案例,我们可以得到结论,for update of columns 用在多表连接锁定时,可以指定要锁定的是哪几张表,而如果表中的列没有在for update of 后面出现的话,就意味着这张表其实并没有被锁定,其他用户是可以对这些表的数据进行update操作的。这种情况经常会出现在用户对带有连接查询的视图进行操作场景下。用户只锁定相关表的数据,其他用户仍然可以对视图中其他原始表的数据来进行操作。
Oracle 的for update行锁
SELECT…FOR UPDATE 语句的语法如下:
SELECT … FOR UPDATE [OF column_list][WAIT n|NOWAIT][SKIP LOCKED];
其中:
OF 子句用于指定即将更新的列,即锁定行上的特定列。
WAIT 子句指定等待其他用户释放锁的秒数,防止无限期的等待。
“使用FOR UPDATE WAIT”子句的优点如下:
1防止无限期地等待被锁定的行;
2允许应用程序中对锁的等待时间进行更多的控制。
3对于交互式应用程序非常有用,因为这些用户不能等待不确定
4 若使用了skip locked,则可以越过锁定的行,不会报告由wait n 引发的‘资源忙’异常报告
示例:
create table t(a varchar2(20),b varchar2(20));
insert into t values(‘1‘,‘1‘);
insert into t values(‘2‘,‘2‘);
insert into t values(‘3‘,‘3‘);
insert into t values(‘4‘,‘4‘);
现在执行如下操作:
在plsql develope中打开两个sql窗口,
在1窗口中运行sql
select * from t where a=‘1‘ for update;
在2窗口中运行sql1
1. select * from t where a=‘1‘; 这一点问题也没有,因为行级锁不会影响纯粹的select语句
再运行sql2
2. select * from t where a=‘1‘ for update; 则这一句sql在执行时,永远处于等待状态,除非窗口1中sql被提交或回滚。
如何才能让sql2不等待或等待指定的时间呢? 我们再运行sql3
3. select * from t where a=‘1‘ for update nowait; 则在执行此sql时,直接报资源忙的异常。
若执行 select * from t where a=‘1‘ for update wait 6; 则在等待6秒后,报 资源忙的异常。
如果我们执行sql4
4. select * from t where a=‘1‘ for update nowait skip Locked; 则执行sql时,即不等待,也不报资源忙异常。
现在我们看看执行如下操作将会发生什么呢?
在窗口1中执行:
select * from t where rownum<=3 nowait skip Locked;
在窗口2中执行:
select * from t where rownum<=6 nowait skip Locked;
select for update 也就如此了吧,insert、update、delete操作默认加行级锁,其原理和操作与select for update并无两样。
select for update of,这个of子句在牵连到多个表时,具有较大作用,如不使用of指定锁定的表的列,则所有表的相关行均被锁定,若在of中指定了需修改的列,则只有与这些列相关的表的行才会被锁定。
三、游标用到修改删除数据
DELCARE
CURSOR c1 IS SELECT empno,salary
FROM emp
WHERE comm IS NULL
FOR UPDATE OF comm
v_comm NUMBER(10,2);
BEGIN
FOR r1 IN c1 LOOP
IF r1.salary<500 THEN
v_comm:=r1.salary*0.25;
ELSEIF r1.salary<1000 THEN
v_comm:=r1.salary*0.20;
ELSEIF r1.salary<3000 THEN
v_comm:=r1.salary*0.15;
ELSE
v_comm:=r1.salary*0.12;
END IF;
UPDATE emp SET comm=v_comm WHERE CURRENT OF c1;
END LOOP;
END
通过从游标工作区中抽取出来的数据,可以对数据库中的数据进行操纵,包括修改与删除操作。
要想通过游标操纵数据库,在定义游标的时候,必须加上FOR UPDATE OF子句;
而且在UPDATE或DELETE时,必须加上WHERE CURRENT OF子句,则游标所在行被更新或者删除。
一个FOR UPDATE子句将使所在行获得一个行级排他锁。
UPDATE或DELETE语句中的WHERE CURRENT OF子串专门处理要执行UPDATE或DELETE操作的表中取出的最近的数据。要使用这个方法,在声明游标时必须使用FOR UPDATE子串,当对话使用FOR UPDATE子串打开一个游标时,所有返回集中的数据行都将处于行级(ROW-LEVEL)独占式锁定,其他对象只能查询这些数据行,不能进行UPDATE、DELETE或SELECT…FOR UPDATE操作。
二十、Oracle系统工具包
No. 子程序名称 描述
1 enable 打开缓冲区,当用户使用“SET SERVEROUTPUT ON”命令时,自动调用此语句
2 disable 关闭缓冲区,当用户使用“SET SERVEROUTPUT OFF”命令时,自动调用此语句
3 put 将内容保存到缓冲区中,不包含换行符,等执行put_line时一起输出
4 put_line 直接输出指定内容,包括换行符
5 new_line 在行尾添加换行符,在使用PUT时必须依靠new_line来添加换行符
6 get_line 获取缓冲区中的单行信息
子程序定义:“procedure get_line(line out varchar2, status out integer);”
参数作用: line:被get_line取回的行;
status:是否取回一行,如果设置为1表示取回一行,如果0表示没有取回数据。
7 get_lines 以数组的形式来获取缓冲区中的所有信息
子程序定义:“procedure get_lines(lines out chararr, numlines in out integer);”
参数作用:
line:被get_line取回的行,是一个CHARARR类型,此类型是一个VARCHAR2(255)的嵌套表,会返回缓冲区的多行信息;
status:是否取回一行,如果设置为1表示取回一行,如果0表示没有取回数据;
numlines:如果作为输入参数表明要返回的行数;作为返回参数表示实际取回的行数。
1、系统自带工具包DBMS_OUTPUT包
–示例一、设置输出打开,enable和关闭disable
begin
dbms_output.enable; --启用缓存
dbms_output.put_line(‘可以显示!‘);
end;
/
begin
dbms_output.disable; --关闭缓存
dbms_output.put_line(‘不显示数据!‘);
end;
/
–示例二、设置缓冲区
begin
dbms_output.enable; --启用缓存
dbms_output.put(‘www‘); --像缓存中增加内容
dbms_output.put(‘163.com‘);--像缓存中增加内容
dbms_output.new_line; --换行,输出之间缓存区的内容
dbms_output.put(‘www.baidu.com‘); --像缓存区增加内容
dbms_output.new_line; --换行,输出之间缓存区的内容
dbms_output.put(‘www.qq.com‘); --这行没有输出是因为没有换行!
end;
/
–示例三、使用get_line()和get_lines()函数取回缓冲区数据
declare
v_line1 varchar2(200);
v_line2 varchar2(200);
v_status number;
begin
dbms_output.enable;
dbms_output.put(‘www‘); --像缓存中增加内容
dbms_output.put(‘163.com‘);--像缓存中增加内容
dbms_output.new_line; --换行,输出之间缓存区的内容
dbms_output.put(‘www.baidu.com‘); --像缓存区增加内容
dbms_output.new_line; --换行,输出之间缓存区的内容
dbms_output.get_line(v_line1,v_status);--读取缓存区一行
dbms_output.get_line(v_line2,v_status);--读取缓存区一行
dbms_output.put_line(v_line1);--读取缓冲区一行
dbms_output.put_line(v_line2);--读取缓冲区一行
end;
/
declare
v_lines dbms_output.chararr; --定义charrarr变量
v_status number;
begin
dbms_output.enable;--启用缓存
dbms_output.put(‘www.baidu.com‘);
dbms_output.new_line;
dbms_output.get_lines(v_lines,v_status);--读取缓存区一行
for x in 1..v_lines.count loop
dbms_output.put_line(v_lines(x));--读取缓存区一行
end loop;
end;
/
2、DBMS_ASSERT包
–示例四、为字符串的前后都加上单引号
select dbms_assert.enquote_literal(‘www.hellojava‘) from dual;
–示例五、为字符串的前后都加上双引号,并且变为大写
select dbms_assert.enquote_name(‘www.hellojava‘) from dual;
–示例六、验证字符串是否为有效模式对象名
select dbms_assert.qualified_sql_name(‘hello_oracle‘) from dual;;
–示例七、输入错误的械对象
select dbms_assert.qualified_sql_name(‘123‘) from dual;--提示对象名不能以数字开头
–示例八、验证字符串是否为有效模式名
select dbms_assert.SCHEMA_NAME(‘SCOTT‘) from dual;
–实例九,输入错误模式名
select dbms_assert.SCHEMA_NAME(‘tests‘) from dual;
3、系统自带工具包DBMS.JOB包
–系统自带工具包DBMS.JOB包
drop sequence job_seq;
drop table job_data purge;
create sequence job_seq;
create table job_data(
jid number,
title varchar2(20),
job_data date,
constraint pk_jid primary key(jid)
);
create or replace procedure insert_demo_proc(p_title job_data.title%type)
as
begin
insert into job_data(jid,title,job_data) values(job_seq.nextval,p_title,sysdate);
end;
/
declare
v_jobno number;
begin
dbms_job.submit(v_jobno,--通过out取得作业号
‘insert_demo_proc(‘‘作业A‘‘);‘, --执行的额调度过程
sysdate, --作业开始日期
‘sysdate+(2/(24*60*60))‘--时间间隔
);
commit;
end;
/
select * from job_data
–查询当前用户所有job
select * from user_jobs;
–查询当前job数据
select * from job_data;
–修改执行间隔,在cmd执行
exec dbms_job.interval(21,‘sysdate+(1/(24*60))‘);--修改一个小时执行一次
–删除当前job,在cmd执行
exec dbms_job.remove(21);
4、系统自带工具包DBMS_LOB包
DBMS_LOB包提供了对大对象的操作支持,用户可以直接利用此包的实现对CLOB(大文本)或者BLOB(二进制数据例如:图片,音乐,文字等)类型的列进行操作
1、conn sys/lhj as sysdba;
2、create or replace directory mldn_files as ‘
3、grant read on directory mldn_files to jack;
grant write on directory mldn_files to jack;
4、conn jack/server
5、drop sequence teacher_seq;
drop table teacher;
---
6、create sequence teacher_seq;
create table teacher(
tid number,
name varchar2(50) not null,
note clob,
photo blob,
constraint pk_tid primary key(tid)
);
7、declare
v_photo teacher.photo%type;
v_srcfile bfile;--文件定位
v_pos_write integer;
begin
insert into teacher(tid,name,note,photo) values
(teacher_seq.nextval,‘Jack‘,‘是一个天才‘,empty_blob())
return photo into v_photo;
v_srcfile := bfilename(‘MLDN_FILES‘,‘myJack.png‘);
v_pos_write := dbms_lob.getlength(v_srcfile);
dbms_lob.fileopen(v_srcfile,dbms_lob.file_readonly);
dbms_lob.loadfromfile(v_photo,v_srcfile,v_pos_write);
dbms_lob.fileclose(v_srcfile);
end;
/
注意问题:
1、复制目录的时候可能在盘符后面有乱码;
2、查询目录是否存在:select * from dba_directories;
3、目录的名字一定要和创建名字大小写相同,这里是区分大小写的!
其实,我前面一篇讲表空间的时候就介绍了数据库的结构,只是那个图只是简单的层次关系,这张图片看上去挺封复杂的,只要关注几个概念就行了。
Database(数据库) :数据库是按照数据结构来组织、存储和管理数据的仓库。
Tablespaces(表空间) :表空间是数据库的逻辑划分,一个表空间只能属于一个数据库。所有的数据库对象都存放在指定的表空间中。但主要存放的对象是表, 所以称作表空间。
Segments (段): 段是表空间的重要组织结构,段是指占用数据文件空间的通称,或数据库对象使用的空间的集合;段可以有表段、索引段、回滚段、临时段和高速缓存段等。
extents (盘区):是数据库存储空间分配的一个逻辑单位,它由连续数据块所组成。第一个段是由一个或多个盘区组成。当一段中间所有空间已完全使用,oracle为该段分配一个新的范围。
Data Block (数据块):是oralce 管理数据文件中存储空间的单位,为数据库使用的I/O的最小单位,其大小可不同于操作系统的标准I/O块大小。
exp,imp的使用
注: 在splplus环境下执行时,在命令前加 ! 号,这样 SQL> !exp … 和 SQL> !imp …
基本语法和实例:
1. EXP
有三种主要的方式(完全、用户、表)
1.1 完全
EXP SYSTEM/MANAGER BUFFER=64000 FILE=C:\FULL.DMP FULL=Y
如果要执行完全导出,必须具有特殊的权限
1.2 用户模式
EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC
这样用户SONIC的所有对象被输出到文件中。
1.3 表模式
EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC TABLES=(SONIC)
这样用户SONIC的表SONIC就被导出
2. IMP
具有三种模式(完全、用户、表)
1.1 完全:
IMP SYSTEM/MANAGER BUFFER=64000 FILE=C:\FULL.DMP FULL=Y
1.2 用户模式:
IMP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP FROMUSER=SONIC TOUSER=SONIC
这样用户SONIC的所有对象被导入到文件中。必须指定FROMUSER、TOUSER参数,这样才能导入数据。
1.3 表模式:
EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC TABLES=(SONIC)
这样用户SONIC的表SONIC就被导入。
/*–示例
–只导出3张表的结构:
exp user/pasword@dbServerName owner=user tables=(tb1,tb2,tb3) rows=n file=c:\1.dmp
–连带数据导出:
exp user/pasword@dbServerName owner=user tables=(tb1,tb2,tb3) rows=y file=c:\2.dmp
–imp导入
imp user2/pasword@dbServerName2 fromuser=user touser=user2 file=c:\1.dmp*/
exp smartanthztest/smartanthztest@134.96.101.7:1521/tatestdb
buffer=64000 file=d:\smartanthztest_model\smartanthztest_model.dmp owner=smartanthztest
imp smartanthztest/smartanthztest@localhost/orcl
buffer=64000 file=d:\smartanthztest_model\smartanthztest_model.dmp fromuser=smartanthztest touser=smartanthztest
**–实践
–只导出表结构**
exp SMARTANTHZ_0823/SMARTANTHZ_0823@134.96.101.7:1521/TATESTDB owner=SMARTANTHZ_0823 rows=n
file=d:\smartanthz_0823.dmp
–导出带数据的表(owner和tables不能同时使用)
exp SMARTANTHZ_0823/SMARTANTHZ_0823@134.96.101.7:1521/TATESTDB tables=
(mm_table,mm_field,mm_entity_spec,mm_relation_spec,mr_table_spec,mm_spec_attribute,mr_dictvalue_attr,mm_dicttype,mm_dictvalue,mr_dicttype_dictvalue,mm_domain,mr_domain_object) rows=y file=d:\smartanthz_0823_tables.dmp
--imp导入
imp test/test@localhost:1521/orcl fromuser=SMARTANTHZ_0823 touser=test file=d:\smartanthz_0823.dmp
imp test/test@localhost:1521/orcl fromuser=SMARTANTHZ_0823 touser=test file=d:\smartanthz_0823_tables.dmp
exp TC/TC#ANTMAT130@134.96.101.7:1521/TATESTDB owner=TC rows=n file=d:\TCMETADATA.dmp
imp tctest/tctest@134.96.101.7:1521/TATESTDB fromuser=TC touser=tctest file=d:\TCMETADATA.dmp
–expdp,impdp的使用
create directory DATA_PUMP_DIR as ‘D:\oracle\admin\orcl\dpdump\‘;--创建导出目录
grant write,read on directory DATA_PUMP_DIR to test;--授予读写权限
数据泵导出的各种模式:
1、 按表模式导出:
expdp zftang/zftang@fgisdb tables=zftang.b$i_exch_info,zftang.b$i_manhole_info dumpfile =expdp_test2.dmp logfile=expdp_test2.log directory=dir_dp job_name=my_job
2、按查询条件导出:
expdp zftang/zftang@fgisdb tables=zftang.b$i_exch_info dumpfile =expdp_test3.dmp logfile=expdp_test3.log directory=dir_dp job_name=my_job query=‘"where rownum<11"‘
3、按表空间导出:
Expdp zftang/zftang@fgisdb dumpfile=expdp_tablespace.dmp tablespaces=GCOMM.DBF logfile=expdp_tablespace.log directory=dir_dp job_name=my_job
4、导出方案
Expdp zftang/zftang DIRECTORY=dir_dp DUMPFILE=schema.dmp SCHEMAS=zftang,gwm
5、导出整个数据库:
expdp zftang/zftang@fgisdb dumpfile =full.dmp full=y logfile=full.log directory=dir_dp job_name=my_job
impdp导入模式:
1、按表导入
p_street_area.dmp文件中的表,此文件是以gwm用户按schemas=gwm导出的:
impdp gwm/gwm@fgisdb dumpfile =p_street_area.dmp logfile=imp_p_street_area.log directory=dir_dp tables=p_street_area job_name=my_job
2、按用户导入(可以将用户信息直接导入,即如果用户信息不存在的情况下也可以直接导入)
impdp gwm/gwm@fgisdb schemas=gwm dumpfile =expdp_test.dmp logfile=expdp_test.log directory=dir_dp job_name=my_job
3、不通过expdp的步骤生成dmp文件而直接导入的方法:
--从源数据库中向目标数据库导入表p_street_area
impdp gwm/gwm directory=dir_dp NETWORK_LINK=igisdb tables=p_street_area logfile=p_street_area.log job_name=my_job
igisdb是目的数据库与源数据的链接名,dir_dp是目的数据库上的目录
4、更换表空间
采用remap_tablespace参数
–导出gwm用户下的所有数据
expdp system/orcl directory=data_pump_dir dumpfile=gwm.dmp SCHEMAS=gwm
注:如果是用sys用户导出的用户数据,包括用户创建、授权部分,用自身用户导出则不含这些内容
–以下是将gwm用户下的数据全部导入到表空间gcomm(原来为gmapdata表空间下)下
impdp system/orcl directory=data_pump_dir dumpfile=gwm.dmp remap_tablespace=gmapdata:gcomm
expdp SMARTANT_0329/SMARTANT_0329 TABLES=RM_AREA,RE_AREA_BRANCHBUREAU_CCS,RE_AREA_MANAGE,RE_AREA_MANAGE_CCS,RE_AREA_REGION_CCS,RE_AREA_SITE_CCS,RE_AREA_SITEDIRECTION_CCS,RE_AREA_SMALLUNIT_CCS,PM_CUSTOMER,PE_CUSTOMER_CCS directory=DATA_PUMP_DIR dumpfile=SMARTANT_0329_TABLES_20160425.dmp logfile=SMARTANT_0329_TABLES_20160425.log
–导入命令:
impdp SMARTANTNB_0329/SMARTANTNB_0329 DIRECTORY=DATA_PUMP_DIR DUMPFILE=SMARTANT_0329_TABLES_20160425.dmp logfile=SMARTANT_SMARTANTNB_0329.log remap_schema=SMARTANT_0329:SMARTANTNB_0329 remap_tablespace=sdh_data:sdh_data TABLE_EXISTS_ACTION=TRUNCATE version=11.2.0.4.0 cluster=N
导入:
impdp SMARTANTNB_0329/SMARTANTNB_0329 DIRECTORY=DATA_PUMP_DIR DUMPFILE=SEED0329.DMP logfile=SEED_SMARTANTNB_0329.log remap_schema=ITSP_SEED:SMARTANTNB_0329 remap_tablespace=sdh_data:sdh_data TABLE_EXISTS_ACTION=TRUNCATE version=11.2.0.4.0 cluster=N
导出:
impdp SMARTANT_0329/SMARTANT_0329 DIRECTORY=DATA_PUMP_DIR DUMPFILE=SEED0329.DMP logfile=SEED_SMARTANT_0329.log remap_schema=ITSP_SEED:SMARTANT_0329 remap_tablespace=sdh_data:sdh_data TABLE_EXISTS_ACTION=TRUNCATE version=11.2.0.4.0 cluster=N
nohup impdp ngrm/ngrm DIRECTORY=dir_nmdata4 network_link=TONGRM INCLUDE=TABLE:\"IN\(\‘XM_ACCESSURL\‘\)\" LOGFILE=impxm.log TABLE_EXISTS_ACTION=TRUNCATE &
nohup impdp ngrm/ngrm DIRECTORY=dir_nmdata4 network_link=TONGRM INCLUDE=TABLE:\"IN\(\‘XM_ACCESSURL\‘\)\" LOGFILE=impxm.log TABLE_EXISTS_ACTION=TRUNCATE &
Create directory TEST as ‘d:\test‘;
Grant read,write on directory dump_scott to scott;
IMPDP ITSP0319/ITSP0319 DIRECTORY =DIR_DUMP DUMPFILE=ITSP_HA_%U.DMP LOGFILE =ITSP0319_IMP.LOG REMAP_SCHEMA=ITSP_POC:ITSP0319 REMAP_TABLESPACE=ITSP_DATA:SDH_DATA,PUB_TMPWORK_DAT:SDH_DATA PARALLEL=8
IMPDP ITSP/ITSP DIRECTORY =TEST DUMPFILE=ITSP07%U.DMP LOGFILE =ITSP0702_IMP.LOG PARALLEL=4
C:\>impdp -help
Import: Release 11.1.0.7.0 - Production on 星期六, 28 9月, 2013 15:37:03
Copyright (c) 2003, 2007, Oracle. All rights reserved.
数据泵导入实用程序提供了一种用于在 Oracle 数据库之间传输
数据对象的机制。该实用程序可以使用以下命令进行调用:
示例:
impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
您可以控制导入的运行方式。具体方法是: 在 ‘impdp’ 命令后输入各种参数。要指定各参数, 请使用关键字:
格式: impdp KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
示例: impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
USERID 必须是命令行中的第一个参数。
关键字 说明 (默认)
ATTACH 连接到现有作业, 例如 ATTACH [=作业名]。
CONTENT 指定要加载的数据, 其中有效关键字为:(ALL),DATA_ONLY和METADATA_ONLY。
DATA_OPTIONS 数据层标记,其中唯一有效的值为:SKIP_CONSTRAINT_ERRORS-约束条件错误不严重。
DIRECTORY 供转储文件,日志文件和sql文件使用的目录对象。
DUMPFILE 要从(expdat.dmp)中导入的转储文件的列表,例如 DUMPFILE=scott1.dmp, scott2.dmp, dmpdir:scott3.dmp。
ENCRYPTION_PASSWORD 用于访问加密列数据的口令关键字。此参数对网络导入作业无效。
ESTIMATE 计算作业估计值, 其中有效关键字为:(BLOCKS)和STATISTICS。
EXCLUDE 排除特定的对象类型, 例如 EXCLUDE=TABLE:EMP。
FLASHBACK_SCN 用于将会话快照设置回以前状态的 SCN。
FLASHBACK_TIME 用于获取最接近指定时间的 SCN 的时间。
FULL 从源导入全部对象(Y)。
HELP 显示帮助消息(N)。
INCLUDE 包括特定的对象类型, 例如 INCLUDE=TABLE_DATA。
JOB_NAME 要创建的导入作业的名称。
LOGFILE 日志文件名(import.log)。
NETWORK_LINK 链接到源系统的远程数据库的名称。
NOLOGFILE 不写入日志文件。
PARALLEL 更改当前作业的活动worker的数目。
PARFILE 指定参数文件。
PARTITION_OPTIONS 指定应如何转换分区,其中有效关键字为:DEPARTITION,MERGE和(NONE)
QUERY 用于导入表的子集的谓词子句。
REMAP_DATA 指定数据转换函数,例如REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO
REMAP_DATAFILE 在所有DDL语句中重新定义数据文件引用。
REMAP_SCHEMA 将一个方案中的对象加载到另一个方案。
REMAP_TABLE 表名重新映射到另一个表,例如 REMAP_TABLE=EMP.EMPNO:REMAPPKG.EMPNO。
REMAP_TABLESPACE 将表空间对象重新映射到另一个表空间。
REUSE_DATAFILES 如果表空间已存在, 则将其初始化 (N)。
SCHEMAS 要导入的方案的列表。
SKIP_UNUSABLE_INDEXES 跳过设置为无用索引状态的索引。
SQLFILE 将所有的 SQL DDL 写入指定的文件。
STATUS 在默认值(0)将显示可用时的新状态的情况下,要监视的频率(以秒计)作业状态。
STREAMS_CONFIGURATION 启用流元数据的加载
TABLE_EXISTS_ACTION 导入对象已存在时执行的操作。有效关键字:(SKIP),APPEND,REPLACE和TRUNCATE。
TABLES 标识要导入的表的列表。
TABLESPACES 标识要导入的表空间的列表。
TRANSFORM 要应用于适用对象的元数据转换。有效转换关键字为:SEGMENT_ATTRIBUTES,STORAGE,OID和PCTSPACE。
TRANSPORTABLE 用于选择可传输数据移动的选项。有效关键字为: ALWAYS 和 (NEVER)。仅在 NETWORK_LINK 模式导入操作中有效。
TRANSPORT_DATAFILES 按可传输模式导入的数据文件的列表。
TRANSPORT_FULL_CHECK 验证所有表的存储段 (N)。
TRANSPORT_TABLESPACES 要从中加载元数据的表空间的列表。仅在 NETWORK_LINK 模式导入操作中有效。
VERSION 要导出的对象的版本, 其中有效关键字为:(COMPATIBLE), LATEST 或任何有效的数据库版本。仅对 NETWORK_LINK 和 SQLFILE 有效。
下列命令在交互模式下有效。
注: 允许使用缩写
命令 说明 (默认)
CONTINUE_CLIENT 返回到记录模式。如果处于空闲状态, 将重新启动作业。
EXIT_CLIENT 退出客户机会话并使作业处于运行状态。
HELP 总结交互命令。
KILL_JOB 分离和删除作业。
PARALLEL 更改当前作业的活动 worker 的数目。PARALLEL=<worker 的数目>。
START_JOB 启动/恢复当前作业。START_JOB=SKIP_CURRENT 在开始作业之前将跳过作业停止时执行的任意操作。
STATUS 在默认值 (0) 将显示可用时的新状态的情况下,要监视的频率 (以秒计) 作业状态。STATUS[=interval]
STOP_JOB 顺序关闭执行的作业并退出客户机。STOP_JOB=IMMEDIATE 将立即关闭数据泵作业。
备注:红色标记的选项是比较常用的,需知晓其用法。
操作实例
1、全库模式导入[full]
impdp orcldev/oracle directory=backup_path dumpfile=orcldev_schema.dmp full=Y table_exists_action=replace –如果表已经存在则进行替换操作。
一般来说,在还原数据库操作的时候,首先要删除这个用户,然后在进行impdp还原操作。
eg:
(1)SQL>DROP USER orcldev CASCADE;
(2)impdp orcldev/oracle directory=backup_path dumpfile=orcldev_2013.dmp full=Y
2、Schema模式导入[schema]
–还原orcldev这个方案(用户)
impdp orcldev/oracle directory=backup_path dumpfile=orcldev_schema.dmp schemas=orcldev table_exists_action=replace
3、表模式导入[table]
–还原某个用户下的具体的表
(1)windows版本:
impdp orcldev/oracle directory=backup_path dumpfile=orcldev_table.dmp tables=’TAB_TEST’ table_exists_action=replace
(2)unix版本:需要将’单引号进行转义操作
impdp orcldev/oracle directory=backup_path dumpfile=orcldev_table.dmp tables=\’ius_tran\’ table_exists_action=replace
4、表空间模式导入[tablespace]
impdp orcldev/oracle directory=backup_path dumpfile=orcldev_tablespace.dmp tablespace=user,orcldev
5、传输表空间模式导入[Transportable Tablespace]
(1)Oracle_Online
You cannot export transportable tablespaces and then import them into a database at a lower release level. The target database must be at the same or higher release level as the source database.
The TRANSPORT_TABLESPACES is valid only when the NETWORK_LINK parameter is also specified.
意思就说,目标库的版本要等于或者高于源数据库的版本,TRANSPORT_TABLESPACES参数选项有效前提条件是NETWORK_LINK参数需被指定。
查询数据库版本号SQL语句:SELECT * FROM v$version;
EG:impdp orcldev/oracle DIRECTORY=dackup_path NETWORK_LINK=db_link_test01 TRANSPORT_TABLESPACES=test0001 TRANSPORT_FULL_CHECK=n TRANSPORT_DATAFILES=‘app/oradata/test0001.dbf‘
(2)创建数据库dbLink方法:
语法:
CREATE [PUBLIC] DATABASE LINK LINK_NAME
CONNECT TO Username IDENTIFIED BY Password
USING ‘ConnectString’;
注释:
1)创建dblink需要有CREATE DATABASE LINK或CREATE PUBLIC DATABASE LINK的系统权限以及用来登录到远程数据库的帐号必须有CREATE SESSION权限。
2)ConnectString指的是在tnsnames.ora文件中配置的监听名称。
3)当GLOBAL_NAME=TRUE时,dblink名必须与远程数据库的全局数据库名GLOBAL_NAME相同;否则,可以任意命名。
(3)查看GLOBAL_NAME参数方法:
SQL> show parameters global_name;
NAME TYPE VALUE
———————————– ———– ——————————
global_names boolean FALSE
6、REMAP_SCHEMA参数
众所周知:IMP工具的FROMUSER和TOUSER参数可以实现将一个用户的的数据迁移到另外一个用户。
(1)impdp数据泵使用REMAP_SCHEMA参数来实现不同用户之间的数据迁移;
语法:
REMAP_SCHEMA=source_schema:target_schema
eg:impdp orcldev/oracle DIRECTORY=backup_path DUMPFILE=oracldev.dmp REMAP_SCHEMA=orcldev:orcltwo
与REMAP_SCHEMA类似的参数选项,如REMAP_TABLESPACE将源表空间的所有对象导入目标表空间。
将源表空间的所有对象导入到目标表空间中:REMAP_TABLESPACE=source_tablespace:target:tablespace
7、REMAP_TABLE参数
将源表数据映射到不同的目标表中
eg:impdp orcldev/oracle DIRECTORY=backup_path dumpfile=oracldev.dmp remap_table=TAB_TEST:TEST_TB
数据导入到TEST_TB表中,但是该表的索引等信息并没有相应的创建,需要手工初始化。
8、REMAP_DATAFILE参数
语法:REMAP_DATAFILE=source_datafile:target_datafile
Oracle_Online:
Remapping datafiles is useful when you move databases between platforms that have different file naming conventions. The source_datafile and target_datafile names should be exactly as you want them to appear in the SQL statements where they are referenced. Oracle recommends that you enclose datafile names in quotation marks to eliminate ambiguity on platforms for which a colon is a valid file specification character.
9、PARALLEL参数
使用PARALLEL参数可以提高数据泵还原的效率,前提是必须有多个expdp的文件,如expdp01.dmp,expdp02.dmp,expdp03dmp等等,不然会有问题。运行impdp命令时,会先启动一个WOrKER进程将METADATA导入,然后再启动多个WORKER进程将数据以及其他对象导入,所以在前期只会看到一个WOrKER在导入METADATA,而且IMPDP也需要DUMP文件是多个,也可以使用%U来进行导入。
eg: impdp orcldev/oracle directory=backup_path dumpfile=orcldev_schema_%U.dmp schemas=orcldev parallel=4
备注:
而在11GR2后EXPDP和IMDP的WORKER进程会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘上,如果没有设置共享磁盘还是指定cluster=no来防止报错。
10、CONTENT参数
CONTENT参数选项有ALL,DATA_ONLY和METADATA_ONLY,默认情况是ALL。可以选择只导入元数据或者是只导入数据。
EG:impdp orcldev/oracle directory=backup_path dumpfile=orcldev_schema.dmp schemas=orcldev CONTENT=DATA_ONLY
11、include、exclude、parfile、query和version参数选项与EXPDP命令的参数选项一致。
–数据泵备份(EXPDP命令)
(1)http://www.cnblogs.com/oracle-dba/p/3344230.html
(2)http://docs.oracle.com/cd/B19306_01/server.102/b14215/dp_export.htm#i1007829
六、常识
1、ANSI码(American National Standards Institute)
美国国家标准学会的标准码
ASCII码(America Standard Code for Information Interchange)美国信息交换标准码
可以认为是不同的东西!
ANSI码仅在前126个与ASCII码相同。
2、Oracle的表分析是做什么的?
analyze table tablename compute statistics;
分析的结果被Oracle用于基于成本的优化生成更好的查询计划。
那么,问题在于:Oracle的表分析需要经常进行吗?还是只要跑一回就可以一直有效了?
答:遇到当前表的查询或其他性能不好时,就可以对相应的表进行一次分析。1。如果你的表经常由几千万变成几百万,又变成几千万那么需要制定分析计划定期表分析,同时可以一并分析索引,计算索引中数据的分布情况,这样CBO会选择更加准确的执行计划。2。如果表结构变化了也要做下,也就是经常对表做dml就需要分析,现在推荐使用dbms_stats包。
1、这个比较简单,用||或concat函数可以实现
select concat(id,username) str from app_user
select id||username str from app_user
字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式
字符串转多行
使用union all函数等方式
2、wm_concat函数
首先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以”,”号分隔起来,并显示成一行,接下来上例子,看看这个神奇的函数如何应用准备测试数据
create table test(id number,name varchar2(20));
insert into test values(1,‘a‘);
insert into test values(1,‘b‘);
insert into test values(1,‘c‘);
insert into test values(2,‘d‘);
insert into test values(2,‘e‘);
效果1 : 行转列 ,默认逗号隔开
select wm_concat(name) name from test;

效果2: 把结果里的逗号替换成”|”
select replace(wm_concat(name),‘,‘,‘|‘) from test;

效果3: 按ID分组合并name
select id,wm_concat(name) name from test group by id;

sql语句等同于下面的sql语句
——– 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )
select id, max(decode(rn, 1, name, null)) || max(decode(rn, 2, ‘,‘ || name, null)) || max(decode(rn, 3, ‘,‘ || name, null)) str
from (select id,name,row_number() over(partition by id order by name) as rn from test) t group by id order by 1;
——– 适用范围:8i,9i,10g及以后版本 ( ROW_NUMBER + LEAD )
select id, str from (select id,row_number() over(partition by id order by name) as rn,name || lead(‘,‘ || name, 1) over(partition by id order by name) ||
lead(‘,‘ || name, 2) over(partition by id order by name) || lead(‘,‘ || name, 3) over(partition by id order by name) as str from test) where rn = 1 order by 1;
——– 适用范围:10g及以后版本 ( MODEL )
select id, substr(str, 2) str from test model return updated rows partition by(id) dimension by(row_number() over(partition by id order by name) as rn)
measures (cast(name as varchar2(20)) as str) rules upsert iterate(3) until(presentv(str[iteration_number+2],1,0)=0) (str[0] = str[0] || ‘,’ || str[iteration_number+1]) order by 1;
——– 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )
select t.id id,max(substr(sys_connect_by_path(t.name,‘,‘),2)) str from (select id, name, row_number() over(partition by id order by name) rn from test) t
start with rn = 1 connect by rn = prior rn + 1 and id = prior id group by t.id;</span>
懒人扩展用法:
案例: 我要写一个视图,类似”create or replace view as select 字段1,…字段50 from tablename” ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 当然有了,看我如果应用wm_concat来让这个需求变简单,假设我的APP_USER表中有(id,username,password,age)4个字段。查询结果如下
/* 这里的表名默认区分大小写 /
select ‘create or replace view as select ‘|| wm_concat(column_name) || ‘ from APP_USER‘ sqlStr from user_tab_columns where table_name=‘APP_USER‘;

利用系统表方式查询
select * from user_tab_columns
3、Oracle 11g 行列互换 pivot 和 unpivot 说明
在Oracle 11g中,Oracle 又增加了2个查询:pivot(行转列) 和unpivot(列转行)
参考:http://blog.csdn.net/tianlesoftware/article/details/7060306、http://www.oracle.com/technetwork/cn/articles/11g-pivot-101924-zhs.html
google 一下,网上有一篇比较详细的文档:http://www.oracle-developer.net/display.php?id=506
pivot 列转行
测试数据 (id,类型名称,销售数量),案例:根据水果的类型查询出一条数据显示出每种类型的销售数量。
create table demo(id int,name varchar(20),nums int); ---- 创建表
insert into demo values(1, ‘苹果‘, 1000);
insert into demo values(2, ‘苹果‘, 2000);
insert into demo values(3, ‘苹果‘, 4000);
insert into demo values(4, ‘橘子‘, 5000);
insert into demo values(5, ‘橘子‘, 3000);
insert into demo values(6, ‘葡萄‘, 3500);
insert into demo values(7, ‘芒果‘, 4200);
insert into demo values(8, ‘芒果‘, 5500);

分组查询 (当然这是不符合查询一条数据的要求的)
select name, sum(nums) nums from demo group by name

行转列查询
select * from (select name, nums from demo) pivot (sum(nums) for name in (‘苹果‘ 苹果, ‘橘子‘, ‘葡萄‘, ‘芒果‘));
注意: pivot(聚合函数 for 列名 in(类型)) ,其中 in(‘’) 中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers
当然也可以不使用pivot函数,等同于下列语句,只是代码比较长,容易理解
select * from (select sum(nums) 苹果 from demo where name=‘苹果‘),(select sum(nums) 橘子 from demo where name=‘橘子‘),
(select sum(nums) 葡萄 from demo where name=‘葡萄‘),(select sum(nums) 芒果 from demo where name=‘芒果‘);
unpivot 行转列
顾名思义就是将多列转换成1列中去
案例:现在有一个水果表,记录了4个季度的销售数量,现在要将每种水果的每个季度的销售情况用多行数据展示。
创建表和数据
create table Fruit(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int);
insert into Fruit values(1,‘苹果‘,1000,2000,3300,5000);
insert into Fruit values(2,‘橘子‘,3000,3000,3200,1500);
insert into Fruit values(3,‘香蕉‘,2500,3500,2200,2500);
insert into Fruit values(4,‘葡萄‘,1500,2500,1200,3500);
select * from Fruit

列转行查询
select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
注意: unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量

同样不使用unpivot也可以实现同样的效果,只是sql语句会很长,而且执行速度效率也没有前者高
select id, name ,‘Q1‘ jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,‘Q2‘ jidu, (select q2 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,‘Q3‘ jidu, (select q3 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,‘Q4‘ jidu, (select q4 from fruit where id=f.id) xiaoshou from Fruit f
XML类型
上述pivot列转行示例中,你已经知道了需要查询的类型有哪些,用in()的方式包含,假设如果您不知道都有哪些值,您怎么构建查询呢?
pivot 操作中的另一个子句 XML 可用于解决此问题。该子句允许您以 XML 格式创建执行了 pivot 操作的输出,在此输出中,您可以指定一个特殊的子句 ANY 而非文字值
示例如下:
select * from (
select name, nums as "Purchase Frequency"
from demo t
)
pivot xml (
sum(nums) for name in (any)
)

如您所见,列 NAME_XML 是 XMLTYPE,其中根元素是 。每个值以名称-值元素对的形式表示。您可以使用任何 XML 分析器中的输出生成更有用的输出。

结论
Pivot 为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用 unpivot 操作转换任何交叉表报表,以常规关系表的形式对其进行存储。Pivot 可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域。
Oracle提供了大量索引选项。知道在给定条件下使用哪个选项对于一个应用程序的性能来说非常重要。一个错误的选择可能会引发死锁,并导致数据库性能急剧下降或进程终止。而如果做出正确的选择,则可以合理使用资源,使那些已经运行了几个小时甚至几天的进程在几分钟得以完成,这样会使您立刻成为一位英雄。这篇文章就将简单的讨论每个索引选项。主要有以下内容:
[1] 基本的索引概念
查询DBA_INDEXES视图可得到表中所有索引的列表,注意只能通过USER_INDEXES的方法来检索模式(schema)的索引。访问USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。
[2] 组合索引
当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。在 Oracle9i引入跳跃式扫描的索引访问方法之前,查询只能在有限条件下使用该索引。比如:表emp有一个组合索引键,该索引包含了empno、 ename和deptno。在Oracle9i之前除非在where之句中对第一列(empno)指定一个值,否则就不能使用这个索引键进行一次范围扫描。
特别注意:在Oracle9i之前,只有在使用到索引的前导索引时才可以使用组合索引!
[3] ORACLE ROWID
通过每个行的ROWID,索引Oracle提供了访问单行数据的能力。ROWID其实就是直接指向单独行的线路图。如果想检查重复值或是其他对ROWID本身的引用,可以在任何表中使用和指定rowid列。
[4] 限制索引
限制索引是一些没有经验的开发人员经常犯的错误之一。在SQL中有很多陷阱会使一些索引无法使用。下面讨论一些常见的问题:
4.1 使用不等于操作符(<>、!=)
下面的查询即使在cust_rating列有一个索引,查询语句仍然执行一次全表扫描。
select cust_Id,cust_name
from customers
where cust_rating <> ‘aa‘;
把上面的语句改成如下的查询语句,这样,在采用基于规则的
优化器而不是基于代价的优化器(更智能)时,将会使用索引。
select cust_Id,cust_name
from customers
where cust_rating < ‘aa‘ or cust_rating > ‘aa‘;
特别注意:通过把不等于操作符改成OR条件,就可以使用索引,以避免全表扫描。
4.2 使用IS NULL 或IS NOT NULL
使用IS NULL 或IS NOT NULL同样会限制索引的使用。因为NULL值并没有被定义。在SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。
4.3 使用函数
如果不使用基于函数的索引,那么在SQL语句的WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。 下面的查询不会使用索引(只要它不是基于函数的索引)
select empno,ename,deptno
from emp
where trunc(hiredate)=‘01-MAY-81‘;
把上面的语句改成下面的语句,这样就可以通过索引进行查找。
select empno,ename,deptno
from emp
where hiredate<(to_date(‘01-MAY-81‘)+0.9999);
4.4 比较不匹配的数据类型
比较不匹配的数据类型也是比较难于发现的性能问题之一。
注意下面查询的例子,account_number是一个VARCHAR2类型,
在account_number字段上有索引。下面的语句将执行全表扫描。
select bank_name,address,city,state,zip
from banks
where account_number = 990354;
Oracle可以自动把where子句变成to_number(account_number)=990354,这样就限制了
索引的使用,改成下面的查询就可以使用索引:
select bank_name,address,city,state,zip
from banks
where account_number =‘990354‘;
特别注意:不匹配的数据类型之间比较会让Oracle自动限制索引的使用,
即便对这个查询执行Explain Plan也不能让您明白为什么做了一次“全表扫描”。
[5] 选择性
使用USER_INDEXES视图,该视图中显示了一个distinct_keys列。比较一下唯一键的数量和表中的行数,就可以判断索引的选择性。选择性越高,索引返回的数据就越少。
[6] 群集因子(Clustering Factor)
Clustering Factor位于USER_INDEXES视图中。该列反映了数据相对于已索引的列是否显得有序。如果Clustering Factor列的值接近于索引中的树叶块(leaf block)的数目,表中的数据就越有序。如果它的值接近于表中的行数,则表中的数据就不是很有序。
[7] 二元高度(Binary height)
索引的二元高度对把ROWID返回给用户进程时所要求的I/O量起到关键作用。在对一个索引进行分析后,可以通过查询DBA_INDEXES的B- level列查看它的二元高度。二元高度主要随着表的大小以及被索引的列中值的范围的狭窄程度而变化。索引上如果有大量被删除的行,它的二元高度也会增加。更新索引列也类似于删除操作,因为它增加了已删除键的数目。重建索引可能会降低二元高度。
[8] 快速全局扫描
在Oracle7.3后就可以使用快速全局扫描(Fast Full Scan)这个选项。这个选项允许Oracle执行一个全局索引扫描操作。快速全局扫描读取B-树索引上所有树叶块。初始化文件中的 DB_FILE_MULTIBLOCK_READ_COUNT参数可以控制同时被读取的块的数目。
[9] 跳跃式扫描
从Oracle9i开始,索引跳跃式扫描特性可以允许优化器使用组合索引,即便索引的前导列没有出现在WHERE子句中。索引跳跃式扫描比全索引扫描要快的多。下面的程序清单显示出性能的差别:
create index skip1 on emp5(job,empno);
index created.
select count(*)
from emp5
where empno=7900;
Elapsed:00:00:03.13
Execution Plan
SELECT STATEMENT Optimizer=CHOOSE(Cost=4 Card=1 Bytes=5)
SORT(AGGREGATE)
INDEX(FAST FULL SCAN) OF ‘SKIP1‘(NON-UNIQUE)
Statistics
6826 consistent gets
6819 physical reads
select /*+ index(emp5 skip1)*/ count(*)
from emp5
where empno=7900;
Elapsed:00:00:00.56
Execution Plan
SELECT STATEMENT Optimizer=CHOOSE(Cost=6 Card=1 Bytes=5)
SORT(AGGREGATE)
INDEX(SKIP SCAN) OF ‘SKIP1‘(NON-UNIQUE)
Statistics
consistent gets
physical reads
[10] 索引的类型
B-树索引
位图索引
HASH索引
索引编排表
反转键索引
基于函数的索引
分区索引
本地和全局索引
逻辑上:
Single column 单行索引
Concatenated 多行索引
Unique 唯一索引
NonUnique 非唯一索引
Function-based函数索引
Domain 域索引
物理上:
Partitioned 分区索引(全局索引和本地索引)
NonPartitioned 非分区索引
B-tree:
Normal 正常型B树
Rever Key 反转型B树
Bitmap 位图索引
索引结构:
B-tree:
适合与大量的增、删、改(OLTP);
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)
典型的树状结构;
每个结点都是数据块;
大多都是物理上一层、两层或三层不定,逻辑上三层;
叶子块数据是排序的,从左向右递增;
在分支块和根块中放的是索引的范围;
Bitmap:
适合与决策支持系统;
做UPDATE代价非常高;
非常适合OR操作符的查询;
基数比较少的时候才能建位图索引;
树型结构:
索引头
开始ROWID,结束ROWID(先列出索引的最大范围)
BITMAP
每一个BIT对应着一个ROWID,它的值是1还是0,如果是1,表示着BIT对应的ROWID有值;
B*tree索引的话通常在访问小数据量的情况下比较适用,比如你访问不超过表中数据的5%,当然这只是个相对的比率,适用于一般的情况。bitmap的话在数据仓库中使用较多,用于低基数列,比如性别之类重复值很多的字段,基数越小越好。
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类:
Range(范围)分区
Hash(哈希)分区
List(列表)分区
以及组合分区:Range-Hash,Range-List。
对于表而言(常规意义上的堆组织表),上述分区形式都可以应用(甚至可以对某个分区指定compress属性),只不过分区依赖列不能是lob,long之类数据类型,每个表的分区或子分区数的总数不能超过1023个。
对于索引组织表,只能够支持普通分区方式,不支持组合分区,常规表的限制对于索引组织表同样有效,除此之外呢,还有一些其实的限制,比如要求索引组织表的分区依赖列必须是主键才可以等。
注:本篇所有示例仅针对常规表,即堆组织表!
对于索引,需要区分创建的是全局索引,或本地索引:
l 全局索引(global index):即可以分区,也可以不分区。即可以建range分区,也可以建hash分区,即可建于分区表,又可创建于非分区表上,就是说,全局索引是完全独立的,因此它也需要我们更多的维护操作。
l 本地索引(local index):其分区形式与表的分区完全相同,依赖列相同,存储属性也相同。对于本地索引,其索引分区的维护自动进行,就是说你add/drop/split/truncate表的分区时,本地索引会自动维护其索引分区。
Oracle建议如果单个表超过2G就最好对其进行分区,对于大表创建分区的好处是显而易见的,这里不多论述why,而将重点放在when以及how。
WHEN
一、When使用Range分区
Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,
将记录存放到列值所在的range分区中,比如按照时间划分,2008年1季度的数据放到a分区,08年2季度的数据放到b分区,因此在创建的时候呢,需要你指定基于的列,以及分区的范围值,如果某些记录暂无法预测范围,可以创建maxvalue分区,所有不在指定范围内的记录都会被存储到maxvalue所在分区中,并且支持指定多列做为依赖列,后面在讲how的时候会详细谈到。
二、When使用Hash分区
通常呢,对于那些无法有效划分范围的表,可以使用hash分区,这样对于提高性能还是会有一定的帮助。hash分区会将表中的数据平均分配到你指定的几个分区中,列所在分区是依据分区列的hash值自动分配,因此你并不能控制也不知道哪条记录会被放到哪个分区中,hash分区也可以支持多个依赖列。
三、When使用List分区
List分区与range分区和hash分区都有类似之处,该分区与range分区类似的是也需要你指定列的值,但这又不同与range分区的范围式列值—其分区值必须明确指定,也不同与hash分区—通过明确指定分区值,你能控制记录存储在哪个分区。它的分区列只能有一个,而不能像range或者hash分区那样同时指定多个列做为分区依赖列,不过呢,它的单个分区对应值可以是多个。
你在分区时必须确定分区列可能存在的值,一旦插入的列值不在分区范围内,则插入/更新就会失败,因此通常建议使用list分区时,要创建一个default分区存储那些不在指定范围内的记录,类似range分区中的maxvalue分区。
四、When使用组合分区
如果某表按照某列分区之后,仍然较大,或者是一些其它的需求,还可以通过分区内再建子分区的方式将分区再分区,即组合分区的方式。
组合分区呢在10g中有两种:range-hash,range-list。注意顺序哟,根分区只能是range分区,子分区可以是hash分区或list分区。
提示:11g在组合分区功能这块有所增强,又推出了range-range,list-range,list-list,list-hash,这就相当于除hash外三种分区方式的笛卡尔形式都有了。为什么会没有hash做为根分区的组合分区形式呢,再仔细回味一下第二点,你一定能够想明白~~。
Oracle数据库中,有两种类型的分区索引,全局索引和本地索引,其中本地索引又可以分为本地前缀索引和本地非前缀索引。下面就分别看看每种类型的索引各自的特点。
全局索引以整个表的数据为对象建立索引,索引分区中的索引条目既可能是基于相同的键值但是来自不同的分区,也可能是多个不同键值的组合。
全局索引既允许索引分区的键值和表分区键值相同,也可以不相同。全局索引和表之间没有直接的联系,这一点和本地索引不同。
SQL> create table orders (
order_no number,
part_no varchar2(40),
ord_date date
)
partition by range (ord_date)
(partition Q1 values less than (TO_DATE(‘01-APR-1999‘,‘DD-MON-YYYY‘)),
partition Q2 values less than (TO_DATE(‘01-JUL-1999‘,‘DD-MON-YYYY‘)),
partition Q3 values less than (TO_DATE(‘01-OCT-1999‘,‘DD-MON-YYYY‘)),
partition Q4 values less than (TO_DATE(‘01-JAN-2000‘,‘DD-MON-YYYY‘))
)
;
Table created.
SQL> create index orders_global_1_idx
on orders(ord_date)
global partition by range (ord_date)
(partition GLOBAL1 values less than (TO_DATE(‘01-APR-1999‘,‘DD-MON-YYYY‘)),
partition GLOBAL2 values less than (TO_DATE(‘01-JUL-1999‘,‘DD-MON-YYYY‘)),
partition GLOBAL3 values less than (TO_DATE(‘01-OCT-1999‘,‘DD-MON-YYYY‘)),
partition GLOBAL4 values less than (MAXVALUE)
)
;
Index created.
SQL> create index orders_global_2_idx
on orders(part_no)
global partition by range (part_no)
(partition IND1 values less than (555555),
partition IND2 values less than (MAXVALUE)
)
;
Index created.
从上面的语句可以看出,全局索引和表没有直接的关联,必须显式的指定maxvalue值。假如表中新加了分区,不会在全局索引中自动增加新的分区,必须手工添加相应的分区。
SQL> alter table orders add partition Q5 values less than (TO_DATE(‘01-APR-2000‘,‘DD-MON-YYYY‘));
Table altered.
SQL> select TABLE_NAME, PARTITION_NAME from dba_tab_partitions where table_name=‘ORDERS‘;
TABLE_NAME PARTITION_NAME
ORDERS Q1
ORDERS Q2
ORDERS Q3
ORDERS Q4
ORDERS Q5
SQL> select INDEX_NAME, PARTITION_NAME from dba_ind_partitions where index_name=upper(‘orders_global_1_idx‘);
INDEX_NAME PARTITION_NAME
ORDERS_GLOBAL_1_IDX GLOBAL1
ORDERS_GLOBAL_1_IDX GLOBAL2
ORDERS_GLOBAL_1_IDX GLOBAL3
ORDERS_GLOBAL_1_IDX GLOBAL4
使用全局索引,索引键值必须和分区键值相同,这就是所谓的前缀索引。Oracle不支持非前缀的全局分区索引,如果需要建立非前缀分区索引,索引必须建成本地索引。
SQL> create index orders_global_2_idx
2 on orders(part_no)
3 global partition by range (order_no)
4 (partition IND1 values less than (555555),
5 partition IND2 values less than (MAXVALUE)
6 )
7 ;
global partition by range (order_no)
*
ERROR at line 3:
ORA-14038: GLOBAL partitioned index must be prefixed
接下来再来看看本地分区。
本地索引的分区和其对应的表分区数量相等,因此每个表分区都对应着相应的索引分区。使用本地索引,不需要指定分区范围因为索引对于表而言是本地的,当本地索引创建时,Oracle会自动为表中的每个分区创建独立的索引分区。
创建本地索引不必显式的指定maxvalue值,因为为表新添加表分区时,会自动添加相应的索引分区。
create index orders_local_1_idx
on orders(ord_date)
local
(partition LOCAL1,
partition LOCAL2,
partition LOCAL3,
partition LOCAL4
)
;
Index created.
SQL> select INDEX_NAME, PARTITION_NAME from dba_ind_partitions where index_name=upper(‘orders_local_1_idx‘);
INDEX_NAME PARTITION_NAME
ORDERS_LOCAL_1_IDX LOCAL1
ORDERS_LOCAL_1_IDX LOCAL2
ORDERS_LOCAL_1_IDX LOCAL3
ORDERS_LOCAL_1_IDX LOCAL4
SQL> alter table orders add partition Q5 values less than (TO_DATE(‘01-APR-2000‘,‘DD-MON-YYYY‘));
Table altered.
SQL> select INDEX_NAME, PARTITION_NAME from dba_ind_partitions where index_name=upper(‘orders_local_1_idx‘);
INDEX_NAME PARTITION_NAME
ORDERS_LOCAL_1_IDX LOCAL1
ORDERS_LOCAL_1_IDX LOCAL2
ORDERS_LOCAL_1_IDX LOCAL3
ORDERS_LOCAL_1_IDX LOCAL4
ORDERS_LOCAL_1_IDX Q5
这里系统已经自动以和表分区相同的名字自动创建了一个索引分区。同理,删除表分区时相对应的索引分区也自动被删除。
本地索引和全局索引还有一个显著的差别,就是上面提到的,本地索引可以创建成本地非前缀型,而全局索引只能是前缀型。
SQL> create index orders_local_2_idx
on orders(part_no)
local
(partition LOCAL1,
partition LOCAL2,
partition LOCAL3,
partition LOCAL4)
;
Index created.
SQL> select INDEX_NAME, PARTITION_NAME, HIGH_VALUE from dba_ind_partitions
where index_name=upper(‘orders_local_2_idx‘);
INDEX_NAME PARTITION_NAME HIGH_VALUE
ORDERS_LOCAL_2_IDX LOCAL1 TO_DATE(‘ 1999-04-01 00:00:00‘, ‘SYYYY-MM-DD HH24:MI:SS‘,
‘NLS_CALENDAR=GREGORIA‘
ORDERS_LOCAL_2_IDX LOCAL2 TO_DATE(‘ 1999-07-01 00:00:00‘, ‘SYYYY-MM-DD HH24:MI:SS‘,
‘NLS_CALENDAR=GREGORIA‘
ORDERS_LOCAL_2_IDX LOCAL3 TO_DATE(‘ 1999-10-01 00:00:00‘, ‘SYYYY-MM-DD HH24:MI:SS‘,
‘NLS_CALENDAR=GREGORIA‘
ORDERS_LOCAL_2_IDX LOCAL4 TO_DATE(‘ 2000-01-01 00:00:00‘, ‘SYYYY-MM-DD HH24:MI:SS‘,
‘NLS_CALENDAR=GREGORIA‘
从上面的输出可以看出,虽然索引的键值是part_no,但索引分区的键值仍然和表的分区键值相同,即ord_date,也即是所谓的非前缀型索引。
最后,再引用一个例子说明前缀索引和非前缀索引的应用。
假设有一个使用DATE列分区的大表。我们经常使用一个VARCHAR2列(VCOL)进行查询,但这个列并不是表的分区键值。
有两种可能的方法来访问VCOL列的数据,一是建立基于VCOL列的本地非前缀索引,
| |
| | (10 more | |
Values: A.. Z.. partitions here) A.. Z..
另一种是建立基于VCOL列的全局索引,
| |
| | (10 more | |
Values: A.. D.. partitions here) T.. Z..
可以看出,如果能够保证VCOL列值的唯一性,全局索引将会是最好的选择。如果VCOL列值不唯一,就需要在本地非前缀索引的并行查询和全局索引顺序查询以及高昂的维护代价之间做出选择。
1.前言:
动态查找树主要有:二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Search Tree),红黑树 (Red-Black Tree ),B-tree/B+-tree/ B*-tree (B~Tree)。前三者是典型的二叉查找树结构,其查找的时间复杂度O(log2N)与树的深度相关,那么降低树的深度自然对查找效率是有所提高的;还有一个实际问题:就是大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下(为什么会出现这种情况,待会在外部存储器-磁盘中有所解释),那么如何减少树的深度(当然是不能减少查询的数据量),一个基本的想法就是:采用多叉树结构(由于树节点元素数量是有限的,自然该节点的子树数量也就是有限的)。
这样我们就提出了一个新的查找树结构——多路查找树。根据平衡二叉树的启发,自然就想到平衡多路查找树结构,也就是这篇文章所要阐述的主题B~tree(B树结构),B-tree这棵神奇的树是在Rudolf Bayer, Edward M. McCreight(1970)写的一篇论文《Organization and Maintenance of Large Ordered Indices》中首次提出。具体介绍可以参考wikipedia中的介绍:http://en.wikipedia.org/wiki/B-tree,其中还阐述了B-tree名字来源以及相关的开源地址。
2.外存储器—磁盘
计算机存储设备一般分为两种:内存储器(main memory)和外存储器(external memory)。内存存取速度快,但容量小,价格昂贵,而且不能长期保存数据(在不通电情况下数据会消失)。
外存储器—磁盘是一种直接存取的存储设备(DASD)。它是以存取时间变化不大为特征的。可以直接存取任何字符组,且容量大、速度较其它外存设备更快。
2.1磁盘的构造
磁盘时一个扁平的圆盘(与电唱机的唱片类似)。盘面上有许多称为磁道的圆圈,数据就记录在这些磁道上。磁盘可以是单片的,也可以是由若干盘片组成的盘组,每一盘片上有两个面。如下图6片盘组为例,除去最顶端和最底端的外侧面不存储数据之外,一共有10个面可以用来保存信息。 
当磁盘驱动器执行读/写功能时。盘片装在一个主轴上,并绕主轴高速旋转,当磁道在读/写头(又叫磁头) 下通过时,就可以进行数据的读 / 写了。
一般磁盘分为固定头盘(磁头固定)和活动头盘。固定头盘的每一个磁道上都有独立的磁头,它是固定不动的,专门负责这一磁道上数据的读/写。
活动头盘 (如上图)的磁头是可移动的。每一个盘面上只有一个磁头(磁头是双向的,因此正反盘面都能读写)。它可以从该面的一个磁道移动到另一个磁道。所有磁头都装在同一个动臂上,因此不同盘面上的所有磁头都是同时移动的(行动整齐划一)。当盘片绕主轴旋转的时候,磁头与旋转的盘片形成一个圆柱体。各个盘面上半径相同的磁道组成了一个圆柱面,我们称为柱面。因此,柱面的个数也就是盘面上的磁道数。
2.2磁盘的读/写原理和效率
磁盘上数据必须用一个三维地址唯一标示:柱面号、盘面号、块号(磁道上的盘块)。
读/写磁盘上某一指定数据需要下面3个步骤:
(1) 首先移动臂根据柱面号使磁头移动到所需要的柱面上,这一过程被称为定位或查找。
(2) 如上图6盘组示意图中,所有磁头都定位到了10个盘面的10条磁道上(磁头都是双向的)。这时根据盘面号来确定指定盘面上的磁道。
(3) 盘面确定以后,盘片开始旋转,将指定块号的磁道段移动至磁头下。
经过上面三个步骤,指定数据的存储位置就被找到。这时就可以开始读/写操作了。
访问某一具体信息,由3部分时间组成:
● 查找时间(seek time) Ts: 完成上述步骤(1)所需要的时间。这部分时间代价最高,最大可达到0.1s左右。
● 等待时间(latency time) Tl: 完成上述步骤(3)所需要的时间。由于盘片绕主轴旋转速度很快,一般为7200转/分(电脑硬盘的性能指标之一, 家用的普通硬盘的转速一般有5400rpm(笔记本)、7200rpm几种)。因此一般旋转一圈大约0.0083s。
● 传输时间(transmission time) Tt: 数据通过系统总线传送到内存的时间,一般传输一个字节(byte)大概0.02us=2*10^(-8)s
磁盘读取数据是以盘块(block)为基本单位的。位于同一盘块中的所有数据都能被一次性全部读取出来。而磁盘IO代价主要花费在查找时间Ts上。因此我们应该尽量将相关信息存放在同一盘块,同一磁道中。或者至少放在同一柱面或相邻柱面上,以求在读/写信息时尽量减少磁头来回移动的次数,避免过多的查找时间Ts。
所以,在大规模数据存储方面,大量数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构,就是下面所要重点阐述的B-tree结构,以及相关的变种结构:B+-tree结构和B*-tree结构。
3.B-tree
B-tree又叫平衡多路查找树。一棵m阶的B-tree (m叉树)的特性如下:
(其中ceil(x)是一个取上限的函数)
1) 树中每个结点至多有m个孩子;
2) 除根结点和叶子结点外,其它每个结点至少有有ceil(m / 2)个孩子;
3) 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
4) 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为null);
5) 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,……,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1。
B-tree中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。
为了简单,这里用少量数据构造一棵3叉树的形式。上面的图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件的内容在硬盘中的存储位置;p1表示指向17左子树的指针。
其结构可以简单定义为:
typedef struct {
/*文件数*/
int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子节点的指针*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盘中的存储位置*/
FILE_HARD_ADDR offset[max_file_num];
假如每个盘块可以正好存放一个B-tree的结点(正好存放2个文件名)。那么一个BTNode结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
模拟查找文件29的过程:
(1) 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
(2) 此时内存中有两个文件名17,35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,因此我们找到指针p2。
(3) 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作2次】
(4) 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现26<29<30,因此我们找到指针p2。
(5) 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作3次】
(6) 此时内存中有两个文件名28,29。根据算法我们查找到文件29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于3次磁盘IO操作时影响整个B-tree查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘IO操作最少4次,最多5次。而且文件越多,B-tree比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
上面仅仅介绍了对于B-tree这种结构的查找过程,还有树节点的插入与删除过程,以及相关的算法和代码的实现,将在以后的深入学习中给出相应的实例。
上面简单介绍了利用B-tree这种结构如何访问外存磁盘中的数据的情况,下面咱们通过另外一个实例来对这棵B-tree的插入(insert),删除(delete)基本操作进行详细的介绍:
下面以一棵5阶B-tree实例进行讲解(如下图所示):
其满足上述条件:除根结点和叶子结点外,其它每个结点至少有ceil(5/2)=3个孩子(至少2个关键字);当然最多5个孩子(最多4个关键字)。下图中关键字为大写字母,顺序为字母升序。
结点定义如下:
typedef struct{
int Count; // 当前节点中关键元素数目
ItemType Key[4]; // 存储关键字元素的数组
long Branch[5]; // 伪指针数组,(记录数目)方便判断合并和分裂的情况
} NodeType;
插入(insert)操作:
插入一个元素时,首先在B-tree中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素,注意:如果叶子结点空间足够,这里需要向右移动该叶子结点中大于新插入关键字的元素,如果空间满了以致没有足够的空间去添加新的元素,则将该结点进行“分裂”,将一半数量的关键字元素分裂到新的其相邻右结点中,中间关键字元素上移到父结点中(当然,如果父结点空间满了,也同样需要“分裂”操作),而且当结点中关键元素向右移动了,相关的指针也需要向右移。如果在根结点插入新元素,空间满了,则进行分裂操作,这样原来的根结点中的中间关键字元素向上移动到新的根结点中,因此导致树的高度增加一层。
咱们通过一个实例来逐步讲解下。插入以下字符字母到空的5阶B-tree中:C N G A H E K Q M F W L T Z D P R X Y S,5序意味着一个结点最多有5个孩子和4个关键字,除根结点外其他结点至少有2个关键字,首先,结点空间足够,4个字母插入相同的结点中,如下图: 
当咱们试着插入H时,结点发现空间不够,以致将其分裂成2个结点,移动中间元素G上移到新的根结点中,在实现过程中,咱们把A和C留在当前结点中,而H和N放置新的其右邻居结点中。如下图: 
当咱们插入E,K,Q时,不需要任何分裂操作 
插入M需要一次分裂,注意M恰好是中间关键字元素,以致向上移到父节点中 
插入F,W,L,T不需要任何分裂操作 
插入Z时,最右的叶子结点空间满了,需要进行分裂操作,中间元素T上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。 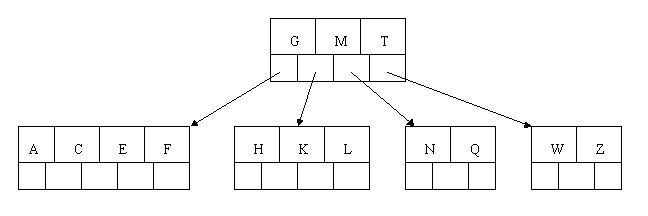
插入D时,导致最左边的叶子结点被分裂,D恰好也是中间元素,上移到父节点中,然后字母P,R,X,Y陆续插入不需要任何分裂操作。 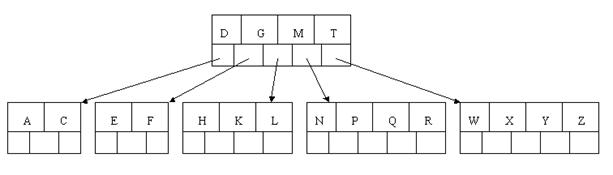
最后,当插入S时,含有N,P,Q,R的结点需要分裂,把中间元素Q上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素M上移到新形成的根结点中,注意以前在父节点中的第三个指针在修改后包括D和G节点中。这样具体插入操作的完成,下面介绍删除操作,删除操作相对于插入操作要考虑的情况多点。 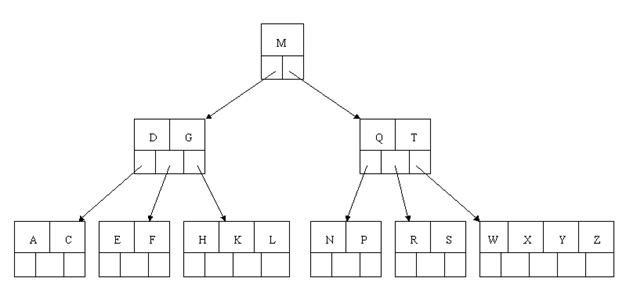
删除(delete)操作:
首先查找B-tree中需删除的元素,如果该元素在B-tree中存在,则将该元素在其结点中进行删除,如果删除该元素后,首先判断该元素是否有左右孩子结点,如果有,则上移孩子结点中的某相近元素到父节点中,然后是移动之后的情况;如果没有,直接删除后,移动之后的情况.。
删除元素,移动相应元素之后,如果某结点中元素数目小于ceil(m/2)-1,则需要看其某相邻兄弟结点是否丰满(结点中元素个数大于ceil(m/2)-1),如果丰满,则向父节点借一个元素来满足条件;如果其相邻兄弟都刚脱贫,即借了之后其结点数目小于ceil(m/2)-1,则该结点与其相邻的某一兄弟结点进行“合并”成一个结点,以此来满足条件。那咱们通过下面实例来详细了解吧。
以上述插入操作构造的一棵5阶B-tree为例,依次删除H,T,R,E。
首先删除元素H,当然首先查找H,H在一个叶子结点中,且该叶子结点元素数目3大于最小元素数目ceil(m/2)-1=2,则操作很简单,咱们只需要移动K至原来H的位置,移动L至K的位置(也就是结点中删除元素后面的元素向前移动) 
下一步,删除T,因为T没有在叶子结点中,而是在中间结点中找到,咱们发现他的继承者W(字母升序的下个元素),将W上移到T的位置,然后将原包含W的孩子结点中的W进行删除,这里恰好删除W后,该孩子结点中元素个数大于2,无需进行合并操作。 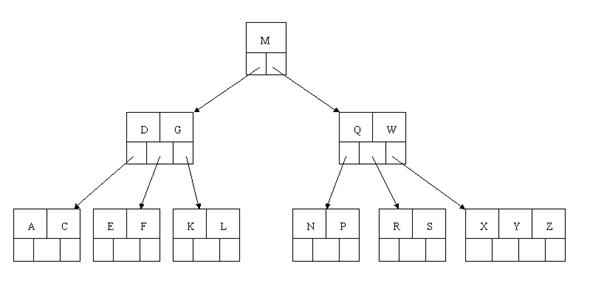
下一步删除R,R在叶子结点中,但是该结点中元素数目为2,删除导致只有1个元素,已经小于最小元素数目ceil(5/2)-1=2,如果其某个相邻兄弟结点中比较丰满(元素个数大于ceil(5/2)-1=2),则可以向父结点借一个元素,然后将最丰满的相邻兄弟结点中上移最后或最前一个元素到父节点中,在这个实例中,右相邻兄弟结点中比较丰满(3个元素大于2),所以先向父节点借一个元素W下移到该叶子结点中,代替原来S的位置,S前移;然后X在相邻右兄弟结点中上移到父结点中,最后在相邻右兄弟结点中删除X,后面元素前移。 
最后一步删除E,删除后会导致很多问题,因为E所在的结点数目刚好达标,刚好满足最小元素个数(ceil(5/2)-1=2),而相邻的兄弟结点也是同样的情况,删除一个元素都不能满足条件,所以需要该节点与某相邻兄弟结点进行合并操作;首先移动父结点中的元素(该元素在两个需要合并的两个结点元素之间)下移到其子结点中,然后将这两个结点进行合并成一个结点。所以在该实例中,咱们首先将父节点中的元素D下移到已经删除E而只有F的结点中,然后将含有D和F的结点和含有A,C的相邻兄弟结点进行合并成一个结点。 
也许你认为这样删除操作已经结束了,其实不然,在看看上图,对于这种特殊情况,你立即会发现父节点只包含一个元素G,没达标,这是不能够接受的。如果这个问题结点的相邻兄弟比较丰满,则可以向父结点借一个元素。假设这时右兄弟结点(含有Q,X)有一个以上的元素(Q右边还有元素),然后咱们将M下移到元素很少的子结点中,将Q上移到M的位置,这时,Q的左子树将变成M的右子树,也就是含有N,P结点被依附在M的右指针上。所以在这个实例中,咱们没有办法去借一个元素,只能与兄弟结点进行合并成一个结点,而根结点中的唯一元素M下移到子结点,这样,树的高度减少一层。 
为了进一步详细讨论删除的情况。再举另外一个实例:
这里是一棵不同的5阶B-tree,那咱们试着删除C 
于是将删除元素C的右子结点中的D元素上移到C的位置,但是出现上移元素后,只有一个元素的结点的情况。 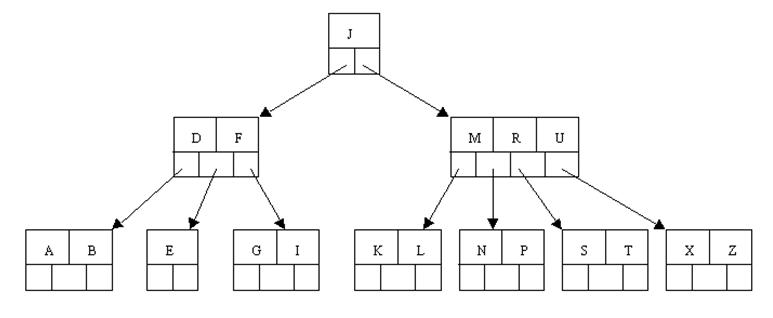
又因为含有E的结点,其相邻兄弟结点才刚脱贫(最少元素个数为2),不可能向父节点借元素,所以只能进行合并操作,于是这里将含有A,B的左兄弟结点和含有E的结点进行合并成一个结点。 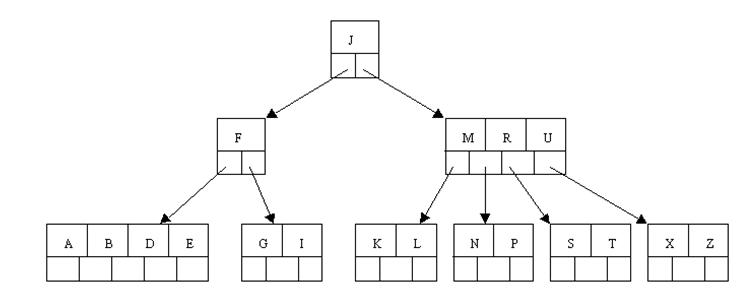
这样又出现只含有一个元素F结点的情况,这时,其相邻的兄弟结点是丰满的(元素个数为3>最小元素个数
2),这样就可以想父结点借元素了,把父结点中的J下移到该结点中,相应的如果结点中J后有元素则前移,然后相邻兄弟结点中的第一个元素(或者最后一个元素)上移到父节点中,后面的元素(或者前面的元素)前移(或者后移);注意含有K,L的结点以前依附在M的左边,现在变为依附在J的右边。这样每个结点都满足B-tree结构性质。 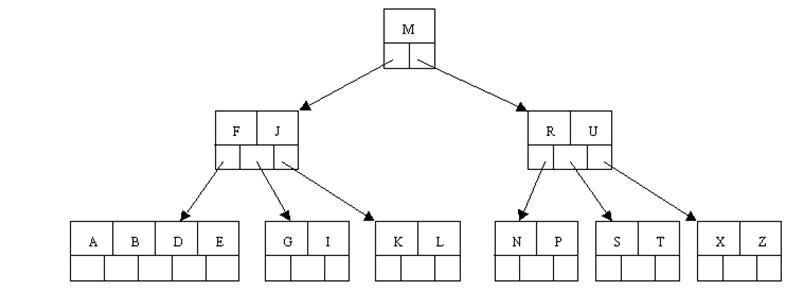
如果想了解相关代码,见最后参考。
4.B+-tree
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+-tree和m阶的B-tree的差异在于:
1.有n棵子树的结点中含有n个关键字; (B-tree是n棵子树有n-1个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (B-tree的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B-tree的非终节点也包含需要查找的有效信息) 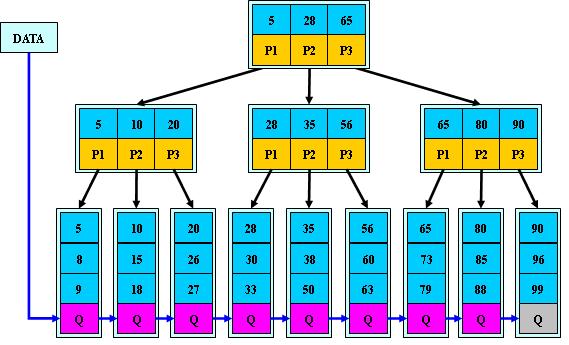
a) 为什么说B+树比B-tree更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B-tree更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+-tree内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B-tree就比B+-tree多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
b) B+-tree的应用:
VSAM(虚拟存储存取法)文件(来源论文the ubiquitous Btree 作者:D COMER - 1979 )
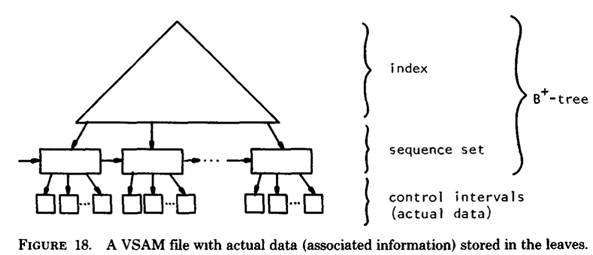
5.B*-tree
B-tree是B+-tree的变体,在B+-tree的非根和非叶子结点再增加指向兄弟的指针;B*-tree定义了非叶子结点关键字个数至少为(2/3)M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示: 
B+-tree的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+-tree的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*-tree的分裂:
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*-tree分配新结点的概率比B+-tree要低,空间使用率更高;
6.总结
B-tree,B+-tree,B*-tree总结如下:
B-tree:有序数组+平衡多叉树;
B+-tree:有序数组链表+平衡多叉树;
B*-tree:一棵丰满的B+-tree。
在大规模数据存储的文件系统中,B~tree系列数据结构,起着很重要的作用,对于存储不同的数据,节点相关的信息也是有所不同,这里根据自己的理解,画的一个查找以职工号为关键字,职工号为38的记录的简单示意图。(这里假设每个物理块容纳3个索引,磁盘的I/O操作的基本单位是块(block),磁盘访问很费时,采用B+-tree有效的减少了访问磁盘的次数。)
对于像MySQL,DB2,Oracle等数据库中的索引结构有待深入的了解才行,不过网上可以找到很多B-tree相关的开源代码可以用来研究。
VSESSION是APPS用户下面对于SYS.V_SESSION 视图的同义词。
在本视图中,每一个连接到数据库实例中的session都拥有一条记录。包括用户session及后台进程如DBWR,LGWR,arcchiver等等。
1、V$SESSION中的常用列
V$SESSION是基础信息视图,用于找寻用户SID或SADDR。不过,它也有一些列会动态的变化,可用于检查用户。如例:
SQL_HASH_VALUE,SQL_ADDRESS:这两列用于鉴别默认被session执行的SQL语句。如果为null或0,那就说明这个session没有执行任何SQL语句。PREV_HASH_VALUE和PREV_ADDRESS两列用来鉴别被session执行的上一条语句。
注意:当使用SQL*Plus进行选择时,确认你重定义的列宽不小于11以便看到完整的数值。
STATUS:这列用来判断session状态是:
l Achtive:正执行SQL语句(waiting for/using a resource)
l Inactive:等待操作(即等待需要执行的SQL语句)
l Killed:被标注为删除
下列各列提供session的信息,可被用于当一个或多个combination未知时找到session。
2、Session信息
l SID:SESSION标识,常用于连接其它列
l SERIAL#:如果某个SID又被其它的session使用的话则此数值自增加(当一个 SESSION结束,另一个SESSION开始并使用了同一个SID)。
l AUDSID:审查session ID唯一性,确认它通常也用于当寻找并行查询模式
l USERNAME:当前session在oracle中的用户名。
3、Client信息
数据库session被一个运行在数据库服务器上或从中间服务器甚至桌面通过SQL*Net连接到数据库的客户端进程启动,下列各列提供这个客户端的信息
l OSUSER: 客户端操作系统用户名
l MACHINE:客户端执行的机器
l TERMINAL:客户端运行的终端
l PROCESS:客户端进程的ID
l PROGRAM:客户端执行的客户端程序
要显示用户所连接PC的TERMINAL、OSUSER,需在该PC的ORACLE.INI或Windows中设置关键字TERMINAL,USERNAME。
4、Application信息
调用DBMS_APPLICATION_INFO包以设置一些信息区分用户。这将显示下列各列。
l CLIENT_INFO:DBMS_APPLICATION_INFO中设置
l ACTION:DBMS_APPLICATION_INFO中设置
l MODULE:DBMS_APPLICATION_INFO中设置
下列V$SESSION列同样可能会被用到:
l ROW_WAIT_OBJ#
l ROW_WAIT_FILE#
l ROW_WAIT_BLOCK#
l ROW_WAIT_ROW#
5、V$SESSION中的连接列
1.Column View Joined Column(s)
2.SID V$SESSION_WAIT,V$SESSTAT,V$LOCK,V$SESSION_EVENT,V$OPEN_CURSOR SID
3.(SQL_HASH_VALUE, SQL_ADDRESS) V$SQLTEXT, V$SQLAREA, V$SQL (HASH_VALUE, ADDRESS)
4.(PREV_HASH_VALUE, PREV_SQL_ADDRESS) V$SQLTEXT, V$SQLAREA, V$SQL (HASH_VALUE, ADDRESS)
5.TADDR V$TRANSACTION ADDR
16.PADDR V$PROCESS ADDR
示例:
1.查找你的session信息
SELECTSID, OSUSER, USERNAME, MACHINE, PROCESS
FROMV$SESSIONWHEREaudsid = userenv(‘SESSIONID‘);
2.当machine已知的情况下查找session
SELECTSID, OSUSER, USERNAME, MACHINE, TERMINAL
FROMV$SESSION
WHEREterminal =‘pts/tl‘ANDmachine =‘rgmdbs1‘;
3.查找当前被某个指定session正在运行的sql语句。假设sessionID为100
1.selectb.sql_text
2.fromv$session a,v$sqlarea b
3.wherea.sql_hash_value=b.hash_valueanda.sid=100
寻找被指定session执行的SQL语句是一个公共需求,如果session是瓶颈的主要原因,那根据其当前在执行的语句可以查看session在做些什么。
视图应用:
6、V$session 表的妙用
v$session 表中比较常用的几个字段说明:
1. sid,serial#
通过sid我们可以查询与这个session相关的各种统计信息,处理信息.
1.select * from v$sesstat where sid = :sid;
查询用户相关的各种统计信息.
1.SELECT a.sid, a.statistic#, b.name, a.value
2. FROM v$sesstat a, v$statname b
3. WHERE a.statistic# = b.statistic#
4. AND a.sid = :sid;
b. 查询用户相关的各种io统计信息
1.select * from v$sess_io where sid = :sid;
c. 查询用户想在正在打开着的游标变量.
1.select * from v$open_cursor where sid = :sid;
d. 查询用户当前的等待信息. 以查看当前的语句为什么这么慢/在等待什么资源.
1.select * from v$session_wait where sid = :sid ;
e. 查询用户在一段时间内所等待的各种事件的信息. 以了解这个session所遇到的瓶颈
1.select * from v$session_event where sid = :sid;
f. 还有, 就是当我们想kill当前session的时候可以通过sid,serial#来处理.
1.alter system kill session ‘:sid,:serail#‘;
2. paddr.字段, process addr, 通过这个字段我们可以查看当前进程的相关信息, 系统进程id,操作系统用户信息等等.
1.SELECT a.pid,
2. a.spid,
3. b.name,
4. b.description,
5. a.latchwait,
6. a.latchspin,
7. a.pga_used_mem,
8. a.pga_alloc_mem,
9. a.pga_freeable_mem,
10. a.pga_max_mem
11. FROM v$process a, v$bgprocess b
12. WHERE a.addr = b.paddr(+)
13. AND a.addr = :paddr
command 字段, 表明当前session正在执行的语句的类型.请参考reference.
taddr 当前事务的地址,可以通过这个字段查看当前session正在执行的事务信息, 使用的回滚段信息等
SELECT b.name rollname, a.*
FROM v$transaction a, v$rollname b
WHERE a.xidusn = b.usn
AND a.addr = ‘585EC18C‘;
lockwait字段, 可以通过这个字段查询出当前正在等待的锁的相关信息.
SELECT *
FROM v$lock
WHERE (id1, id2) = (SELECT id1, id2 FROM v$lock WHERE kaddr = ‘57C68C48‘)
(sql_address,sql_hash_value) (prev_sql_addr,prev_hash_value) 根据这两组字段, 我们可以查询到当前session正在执行的sql语句的详细信息.
[c-sharp] view plaincopy
1.SELECT *
2.FROM v$sqltext
WHERE address = :sql_address
AND hash_value = :sql_hash_value;
7.ROW_WAIT_OBJ#,ROW_WAIT_FILE#,ROW_WAIT_BLOCK#,ROW_WAIT_ROW#可以通过这几个字段查询现在正在被锁的表的相关信息.^_^
a. 首先得到被锁的的信息
1.SELECT * FROM dba_objects WHERE object_id = :row_wait_obj#;
b. 根据row_wait_file#可以找出对应的文件的信息.
1.SELECT * FROM v$datafile WHERE file# = :row_wait_file#.
c. 在根据以上四个字段构造出被锁的字段的rowid信息.
1.SELECT dbms_rowid.ROWID_CREATE(1,
:row_wait_obj#,
:row_wait_file#,
:row_wait_block#,
:row_wait_row#)
FROM dual;
logon_time 当前session的登录时间.
last_call_et 该session idle的时间, 每3秒中更新一次.
十、Oracle:DBMS_STATS.GATHER_TABLE_STATS的语法
作用:DBMS_STATS.GATHER_TABLE_STATS统计表,列,索引的统计信息.
DBMS_STATS.GATHER_TABLE_STATS的语法如下:
DBMS_STATS.GATHER_TABLE_STATS (ownname VARCHAR2, tabname VARCHAR2, partname VARCHAR2, estimate_percent NUMBER, block_sample BOOLEAN, method_opt VARCHAR2, degree NUMBER, granularity VARCHAR2, cascade BOOLEAN, stattab VARCHAR2, statid VARCHAR2, statown VARCHAR2, no_invalidate BOOLEAN, force BOOLEAN);
参数说明:
ownname:要分析表的拥有者
tabname:要分析的表名.
partname:分区的名字,只对分区表或分区索引有用.
estimate_percent:采样行的百分比,取值范围[0.000001,100],null为全部分析,不采样. 常量:DBMS_STATS.AUTO_SAMPLE_SIZE是默认值,由oracle决定最佳取采样值.
block_sapmple:是否用块采样代替行采样.
method_opt:决定histograms信息是怎样被统计的.method_opt的取值如下:
for all columns:统计所有列的histograms.
for all indexed columns:统计所有indexed列的histograms.
for all hidden columns:统计你看不到列的histograms
for columns SIZE | REPEAT | AUTO | SKEWONLY:统计指定列的histograms.N的取值范围[1,254]; REPEAT上次统计过的histograms;AUTO由oracle决定N的大小;SKEWONLY multiple end-points
with the same value which is what we define by “there is skew in the data
degree:决定并行度.默认值为null.
granularity:Granularity of statistics to collect ,only pertinent if the table is partitioned.
cascace:是收集索引的信息.默认为falase.
stattab指定要存储统计信息的表,statid如果多个表的统计信息存储在同一个stattab中用于进行区分.statown存储统计信息表的拥有者.以上三个参数若不指定,统计信息会直接更新到数据字典.
no_invalidate: Does not invalidate the dependent cursors if set to TRUE. The procedure invalidates the dependent cursors immediately if set to FALSE.
force:即使表锁住了也收集统计信息.
例子:
execute dbms_stats.gather_table_stats(ownname => ‘owner‘,tabname => ‘table_name‘ ,estimate_percent => null ,method_opt => ‘for all indexed columns‘ ,cascade => true);
例如:
在使用DBMS_STATS分析表的时候,我们经常要保存之前的分析,以防分析后导致系统性能低下然后进行快速恢复。
1、首先创建一个分析表,该表是用来保存之前的分析值:
SQL> begin
2 dbms_stats.create_stat_table(ownname=>‘TEST‘,stattab=>‘STAT_TABLE‘);
3 end;
4 /
PL/SQL 过程已成功完成。
SQL> begin
2 dbms_stats.gather_table_stats(ownname=>‘TEST‘,tabname=>‘T1‘);
3 end;
4 /
PL/SQL 过程已成功完成。
2、导出表分析信息到stat_table中
SQL> begin
2 dbms_stats.export_table_stats(ownname=>‘TEST‘,tabname=>‘T1‘,stattab=>‘STAT_TABLE‘);
3 end;
4 /
PL/SQL 过程已成功完成。
SQL> select count(*) from TEST.STAT_TABLE;
COUNT(*)
4
EXPORT_COLUMN_STATS:导出列的分析信息
EXPORT_INDEX_STATS:导出索引分析信息
EXPORT_SYSTEM_STATS:导出系统分析信息
EXPORT_TABLE_STATS:导出表分析信息
EXPORT_SCHEMA_STATS:导出方案分析信息
EXPORT_DATABASE_STATS:导出数据库分析信息
IMPORT_COLUMN_STATS:导入列分析信息
IMPORT_INDEX_STATS:导入索引分析信息
IMPORT_SYSTEM_STATS:导入系统分析信息
IMPORT_TABLE_STATS:导入表分析信息
IMPORT_SCHEMA_STATS:导入方案分析信息
IMPORT_DATABASE_STATS:导入数据库分析信息
GATHER_INDEX_STATS:分析索引信息
GATHER_TABLE_STATS:分析表信息,当cascade为true时,分析表、列(索引)信息
GATHER_SCHEMA_STATS:分析方案信息
GATHER_DATABASE_STATS:分析数据库信息
GATHER_SYSTEM_STATS:分析系统信息
4、删除分析信息
SQL> begin
2 dbms_stats.delete_table_stats(ownname=>‘TEST‘,tabname=>‘T1‘);
3 end;
4 /
PL/SQL 过程已成功完成。
SQL> SELECT num_rows,blocks,empty_blocks as empty, avg_space, chain_cnt, avg_row_len FROM dba_tables WHERE owner = ‘TEST‘
AND table_name = ‘T1‘;
NUM_ROWS BLOCKS EMPTY AVG_SPACE CHAIN_CNT AVG_ROW_LEN
没有查到分析数据
5、导入分析信息
SQL> begin 2 dbms_stats.import_table_stats(ownname=>‘TEST‘,tabname=>‘T1‘,stattab=>‘STAT_TABLE‘); 3 end; 4 / PL/SQL 过程已成功完成。 SQL> SELECT num_rows,blocks,empty_blocks as empty, avg_space, chain_cnt, avg_row_len FROM dba_tables WHERE owner = ‘TEST‘ AND table_name = ‘T1‘; NUM_ROWS BLOCKS EMPTY AVG_SPACE CHAIN_CNT AVG_ROW_LEN ---------- ---------- ---------- ---------- ---------- ----------- 1000 5 0 0 0 16
转自
作为一个新手的Oracle(DBA)学习笔记 - JackChiang的博客 - CSDN博客
http://blog.csdn.net/jack__chiang/article/details/70045806
标签:星期六 env count 传递 中国移动 天空 开发者 b树 base
原文地址:http://www.cnblogs.com/paul8339/p/7397862.html











































































































































