标签:成功 com 发送 吞吐量 直接 基于 时间 如何 dash
上次 提到的Nagle算法特性有可能是dubbo调用”网络耗时高“的始作俑者,后来又仔细看了下dubbo的代码,发现dubbo在consumer端已经将tcp设置成非延迟(即关闭Nagle特性)了,代码片段如下: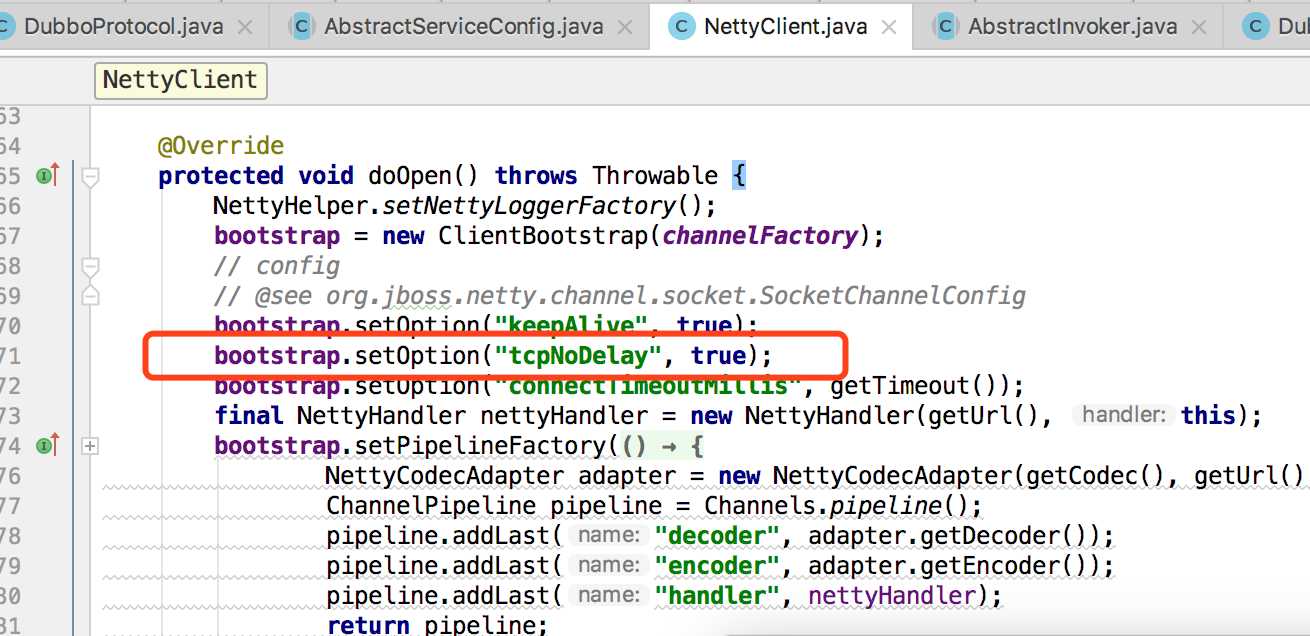
order模块中调用量最高的接口是查询未完成订单,调用量达到每10秒18000,如下: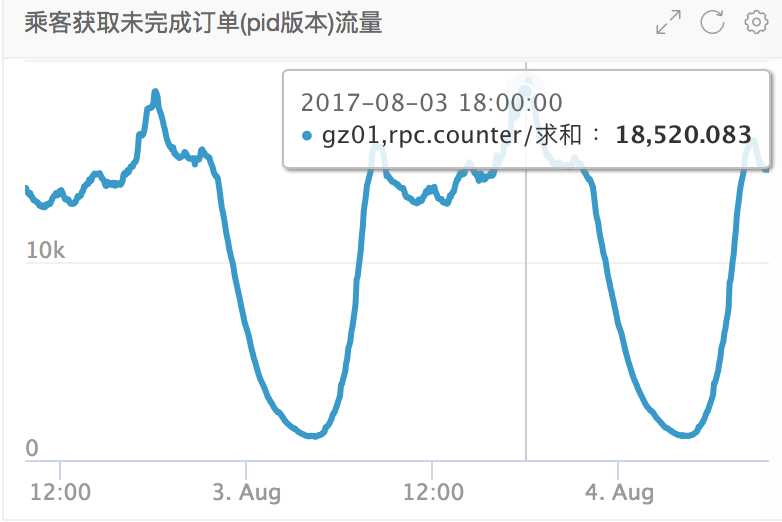
但该接口在order这边的平均耗时特别低(尖刺是由发布引起的,这里忽略),才1毫秒: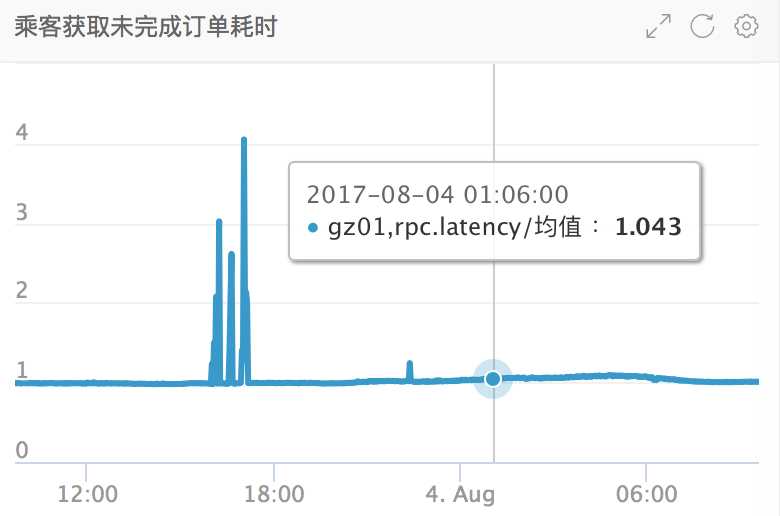
该接口直接由kop来调用,我们看kop这边的平均耗时: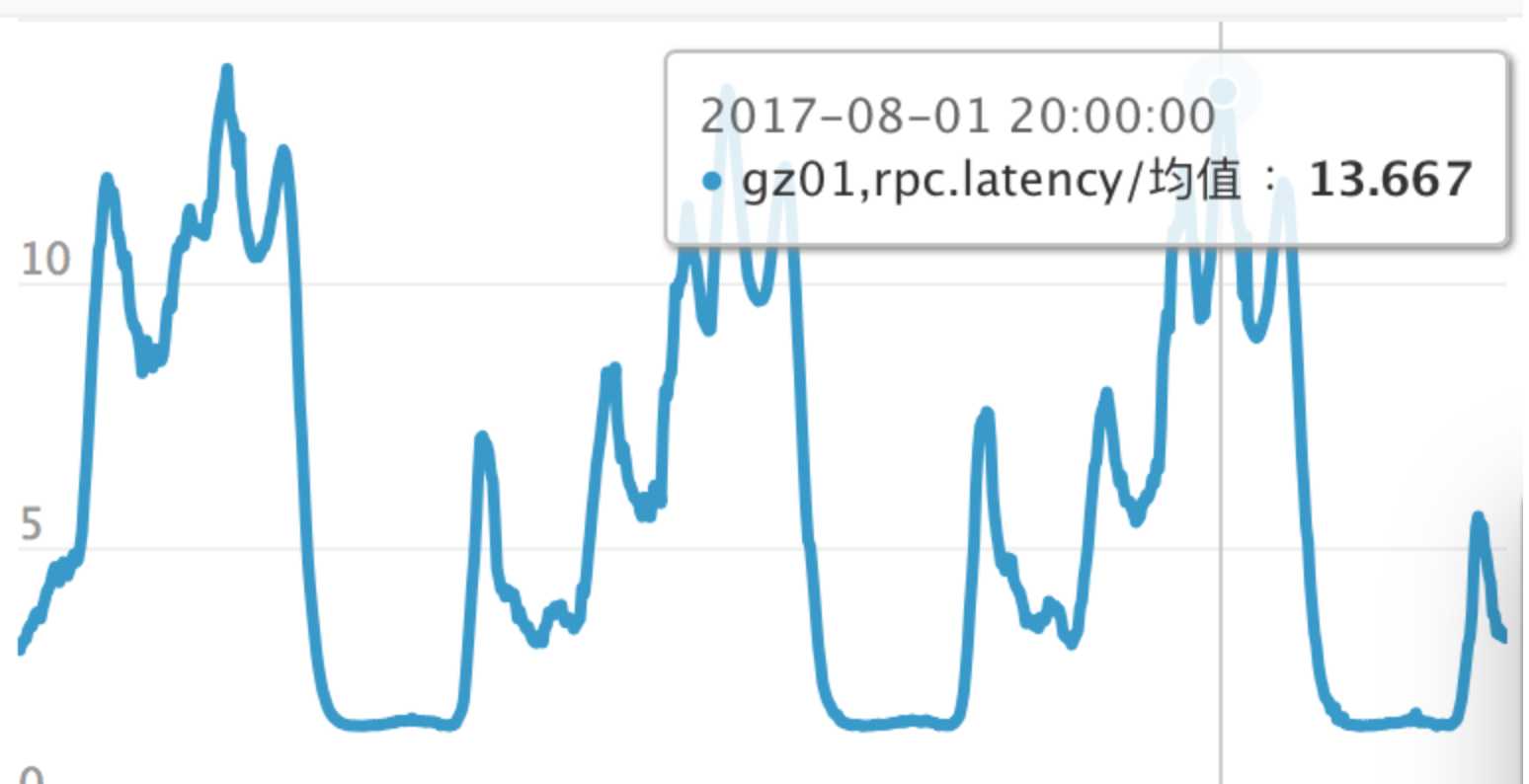
可以看出,在低峰期,kop这边的耗时和order的耗时是匹配的,1-2毫秒,但在高峰期,kop这边的平均耗时高达13毫秒!
是否因为单TCP吞吐达到瓶颈?
和@董磊讨论了下,在order这边将该接口的TCP连接数设置成3(这里需要注意,connections不能设置成1,设置成1还将继续共用1条tcp连接,至少需要2或2以上),如下:
<dubbo:service interface="PassService"
ref="passService" connections="3"version="1.0.0" />
上线后的效果如下: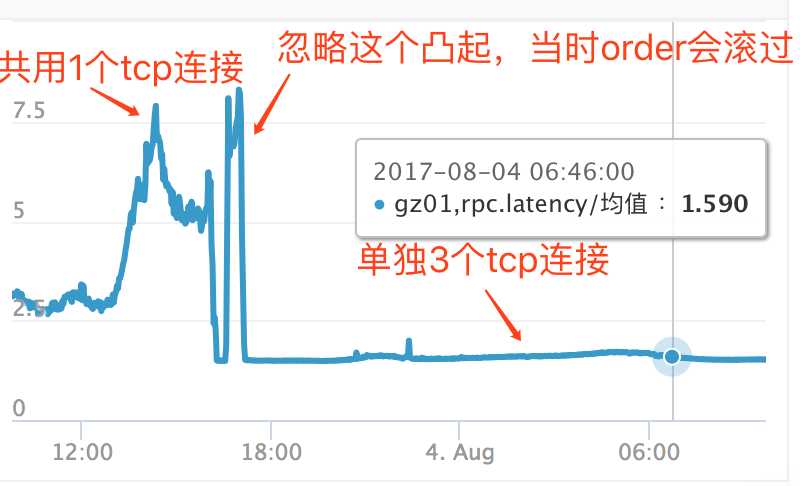
可以看出,在设置成3个单独tcp连接后,网络耗时再也不受高峰期影响,一直很平稳!!
如果不是Nagle算法导致的问题,那么还有可能是其他什么原因呢?
为了达到当前网络条件下的最大吞吐量,TCP协议设计成自适应的(可以参看:https://segmentfault.com/a/1190000008803687),就是说如果网络质量高的情况下,理论上单条TCP连接都能“占满”整个带宽。但tcp是基于可靠到达+顺序保证的,所以每个发生着在发送tcp数据段后都需要收到接收者的ack后才认为数据已经发送成功,否则将定时重发一定次数。而为了增加吞吐量,tcp这边提出了窗口的概念,窗口内的tcp数据段会一次性发送,而不需要等前一个段ack再发送另一个段,而tcp会根据网络质量来逐渐增大窗口。
所以tcp发送数据的吞吐量可能如下几个因素都有关(这里只是分析,欢迎大伙一起纠正和补充):
网络带宽。在我们线上机器是万兆网卡,而且我们用dubbo做rpc都是小数据高频传输,所以不存在带宽被打满的情况。
mss大小。每个分段中能发送的最大TCP数据量。
平均窗口大小。一旦网络质量高,tcp的窗口将变得很大,否则窗口将缩小,直至达到当前网络的合理值,当然窗口一直在不断变化。
TCP缓冲区大小。缓冲区满了发送将一定程度的阻塞。
平均重发次数。这也直接和网络质量有关系。
不论是什么原因,可以知道的是带宽不是瓶颈,网络质量也是靠谱的,所以瓶颈应该和TCP本身的设计相关,既然多条TCP连接能解决问题,现在所要做的就是如何发现业务中网络耗时高的调用了。
于是我们对taxi-rpc和taxi-dubbo进行了升级(后面会单独发邮件推广),用来统计网络耗时,计算公式:网络耗时 = consumer处理耗时 – provider处理耗时,这里先忽略服务器时间同步的影响。order和cos已经进行了升级,所以cos调用order的网络耗时如下: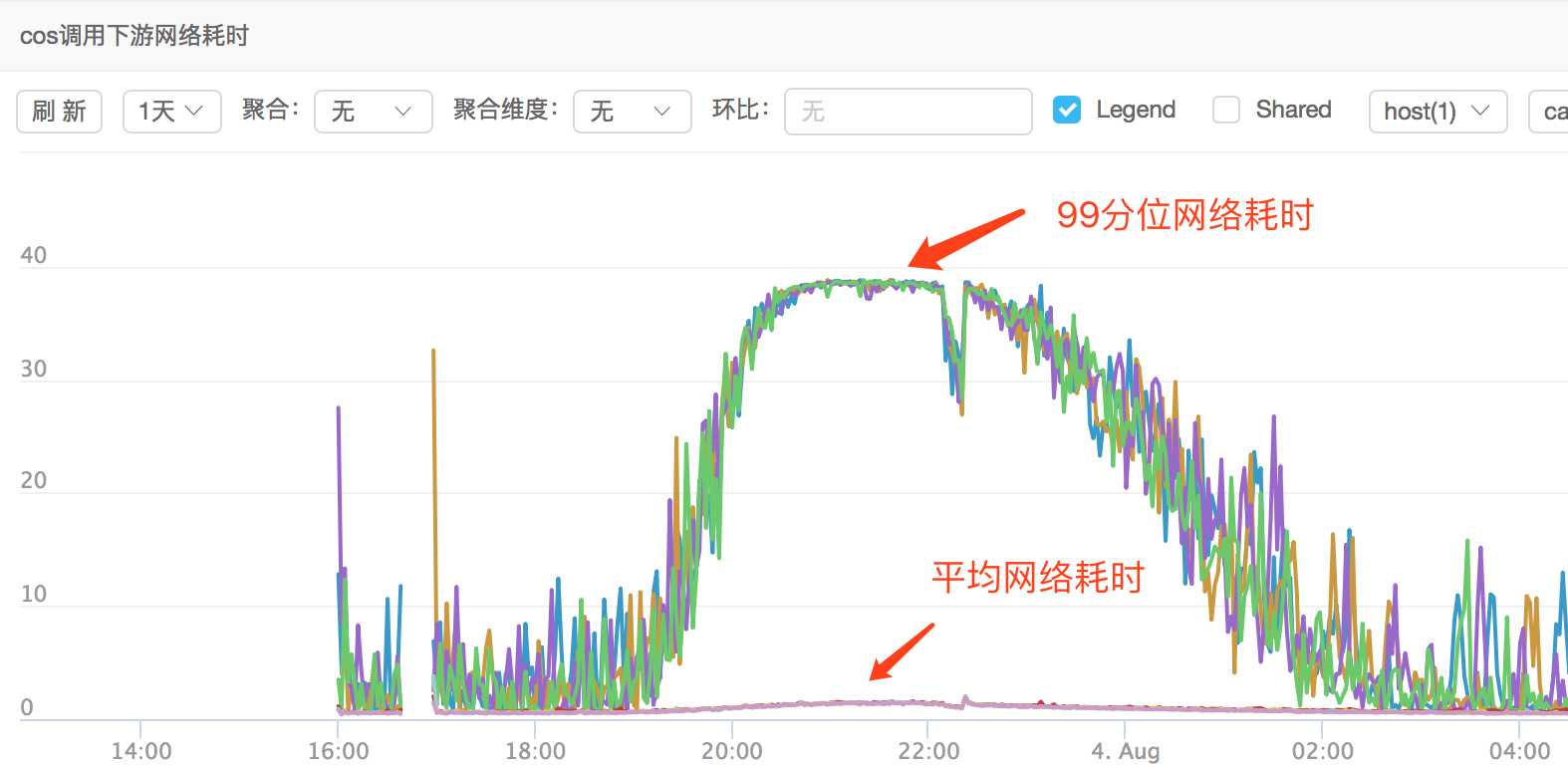
后期如果发现某些接口网络耗时特别高,就很有可能是单个公共的tcp连接不够用了,届时可以对tcp连接的数量进行优化!
稳定性 耗时 监控原因分析-- dubbo rpc 框架 的线程池,io 连接模型. 客户端,服务端
标签:成功 com 发送 吞吐量 直接 基于 时间 如何 dash
原文地址:http://www.cnblogs.com/fei33423/p/7403529.html