标签:tps ash 进入 开启 sea gre rsh 修改 elastic
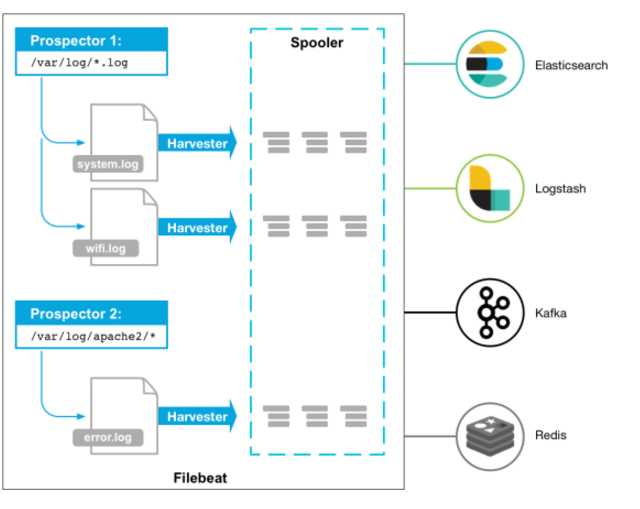
Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh中存放。
当你开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
filebeat的安装配置非常简单
这儿使用的版本是 5.5.2
进入到解压目录下, 然后修改 filebeat.yml
- input_type: log # Paths that should be crawled and fetched. Glob based paths. paths: - /var/log/nginx/*.log #- c:\programdata\elasticsearch\logs\* #exclude_lines: ["^DBG"] #include_lines: ["^ERR", "^WARN"]
这儿可以配置多个路径, 并且使用正则进行日志抽取时的过滤
filebeat的输出可以有多种目的地, es, logstash
elasticsearch:
#-------------------------- Elasticsearch output ------------------------------ #output.elasticsearch: # Array of hosts to connect to. # hosts: ["localhost:9200"] # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme"
logstash:
#----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["www.wenbronk.com:5044"]
nohup ./filebeat -c ./filebeat.yml &
这儿我们以 nginx的日志为例, nginx的安装可见:
http://www.cnblogs.com/wenbronk/p/6557482.html
input { beats { port => "5044" } } output { stdout { codec => rubydebug } }
启动:
./bin/logstash -f ./config/logstash_conf.conf
cat filebeat.yml | grep -v ‘^$‘ | grep -v ‘#‘

参考: http://www.ywnds.com/?p=9776
标签:tps ash 进入 开启 sea gre rsh 修改 elastic
原文地址:http://www.cnblogs.com/wenbronk/p/7411013.html