标签:https pat erro 相对 技术分享 思路 提取 .com tor
版权声明:本文为博主原创文章,转载请附带原文网址http://www.cnblogs.com/wbchanblog/p/7411750.html ,谢谢!
提示:本文主要是讲解零宽断言,所以阅读本文需要有一定的正则表达式基础。
我们知道元字符“\b”、“^”、“$”匹配的是一个位置,而且这个位置需要满足一定的条件(比如“\b”表示单词的边界),我们把这个条件称为断言或零宽度断言。这里有很重要的两个信息:一是断言实际上是某种条件;二是它不占字符宽度,只是一个位置,并不匹配任何字符。
零宽断言一共分为正向和反向两类,每类又分为预测先行和回顾后发两种:
§零宽度正预测先行断言,简称正向先行断言,语法是(?=exp),它断言此位置的后面能匹配表达式exp。
§零宽度正回顾后发断言,简称正向后发断言,语法是(?<=exp),它断言此位置的前面能匹配表达式exp。
§零宽度负预测先行断言,简称反向先行断言,语法是(?!exp),它断言此位置的后面不能匹配表达式exp。
§零宽度负回顾后发断言,简称反向后发断言,语法是(?<!exp),它断言此位置的前面不能匹配表达式exp。
好了,说到这里你一定感觉云里雾里,讲道理我刚看到这官方定义也是一脸懵逼,下面就结合例子来帮助理解一下什么是断言。做过python爬虫的朋友一定做过提取html标签内容的工作吧,比如有<div>hello world</div>,我们要把div标签里面的‘hello world’提取出来,用断言就是如下这样:
正则表达式:(?<=<div>).*(?=</div>)
匹配字符串:<div>hello world</div>
匹配结果: hello world
我们结合这段表达式来看,我们前后用了(?<=<div>)和(?=</div>)两个断言。
先来看第一个断言(?<=<div>),看形式,是不是跟断言语法中的(?<=exp)一样,没错,这个就是正向后发断言,这里的exp就是<div>,它断言此位置的前面能匹配表达式<div>,这样说其实很不好理解,关键在于此位置这三个字不知道代表什么,实际上,这个此位置可以替换成目标字符串,也就是我们需要提取出来的内容,替换之后就变成了:它断言目标字符串的前面能匹配表达式<div>,换个更形象的说法:我断言,我所要提取的目标字符串,它前面的内容一定要匹配表达式<div>。单靠这个条件,去匹配<div>hello world</div>,可以得到结果hello world</div>;
再来看第二个断言(?=</div>),看形式,跟断言语法中的(?=exp)一样,那么这个就是正向先行断言,这里的exp就是</div>,它就代表:我断言,我所要提取的目标字符串,它后面的内容一定要匹配表达式</div>。根据这个条件,结合上一段得到的hello world</div>,我们可以得到匹配结果hello world。
这里安利一个叫Regex Match Tracer的软件,可以帮助我们学习正则表达式:
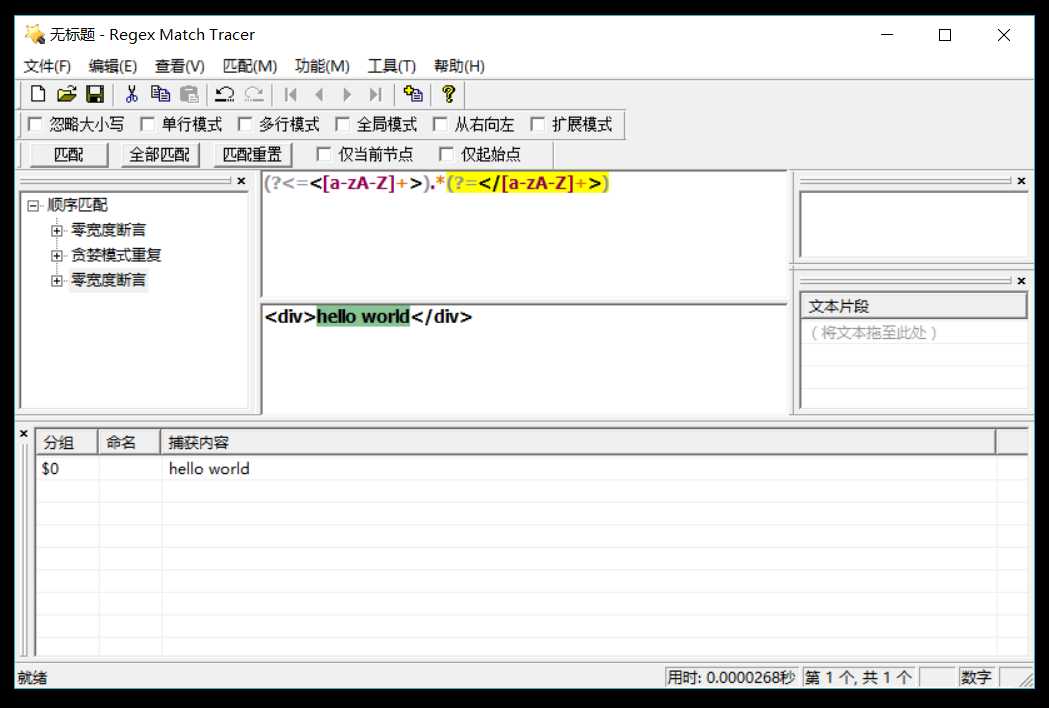
根据以上所说,当我们需要提取字符串的时候,可以用断言,就比如上述字符串<div>hello world</div>,想得到div标签里面的内容时,我们可以按照以下思路写正则表达式:
首先,目标字符串是hello world,那么它可以归纳为 .* ;
其次,目标字符串前面有<div>,既然是前面有,那么根据四种断言的含义,容易得出用正向后发断言(?<=exp),将它放在目标字符串前面,得到(?<=<div>).*,进一步可以将div归纳为[a-zA-Z]+,从而得到(?<=<[a-zA-Z]+>).*;
最后,目标字符串后面有</div>,既然是后面有,那么根据四种断言的含义,容易得出用正向先行断言(?=exp),将它放在目标字符串后面,从而得到(?<=<[a-zA-Z]+>).*(?=</[a-zA-Z]+>);
进一步的,我们发现前后两个断言中都有[a-zA-Z]+,可以使用分组来避免书写重复的内容:(?<=<([a-zA-Z]+)>).*(?=</\1>),当然也可以使用命名分组,这里就不展开了。
说到这里,我归纳出了几句书写断言的口诀:
前面有,正向后发(?<=exp),放前面;
后面有,正向先行(?=exp),放后面;
前面无,反向后发(?<!exp),放前面;
后面无,反向先行(?!exp),放后面。
请记住,这个前面和后面是针对目标字符串,也就是你要提取出来的字符串而言的。
前面说了这么多, 都是就正则表达式本身而言的,我们知道不同编程语言都有自己对正则表达式的扩展,python也不例外。来看下面一段代码:
import re pattern = re.compile(r‘(?<=<([a-zA-Z]+>)).*(?=</\1>)‘) s = ‘<html>hello world</html>‘ ret = re.search(pattern, s) print(ret.group()) #得到结果: #Traceback (most recent call last): # raise error("look-behind requires fixed-width pattern") #sre_constants.error: look-behind requires fixed-width pattern
我们看到python解释器报错了,怎么回事?别急,接着看:
import re pattern = re.compile(r‘(?<=<([a-zA-Z]+>)).*‘) s = ‘<html>hello world</html>‘ ret = re.search(pattern, s) print(ret.group()) #得到结果: #Traceback (most recent call last): # raise error("look-behind requires fixed-width pattern") #sre_constants.error: look-behind requires fixed-width pattern
import re pattern = re.compile(r‘.*(?=</[a-zA-Z]+>)‘) s = ‘<html>hello world</html>‘ ret = re.search(pattern, s) print(ret.group()) #得到结果: #<html>hello world
看明白了吗?将上面第二第三段分别跟第一段代码对比,我们看到第二段相对于第一段的正则表达式去掉了正向先行断言,仍然报错;第三段相对于第一段的正则表达式去掉了正向后发断言(当然用到分组的地方已经手动补全了),却匹配到了结果。再结合错误信息“sre_constants.error: look-behind requires fixed-width pattern”,我们可以得出python的re模块并不支持变长的后发断言,只支持定长的后发断言。
那咋办?难不成就不能提取html标签里的内容了?别急,请看下面代码:
import re pattern = re.compile(r‘<([a-zA-Z]+)>(.*)</\1>‘) s = ‘<html>hello world</html>‘ ret = re.search(pattern, s) print(‘re.group()→‘, ret.group()) print(‘re.group(2)→‘, ret.group(2)) #运行结果 #re.group()→ <html>hello world</html> #re.group(2)→ hello world
我们可以用分组来提取特定的字符串,上面代码给了.*增加了一个分组,按从左到右是第二个分组,这样我们可以在匹配结果中用.group(2)得到目标字符串。
标签:https pat erro 相对 技术分享 思路 提取 .com tor
原文地址:http://www.cnblogs.com/wbchanblog/p/7411750.html