标签:修改 art uid 结果 不同的 正则 架构 ica over
1.概述
-》flume的三大功能
collecting, aggregating, and moving
收集 聚合 移动
2.框图
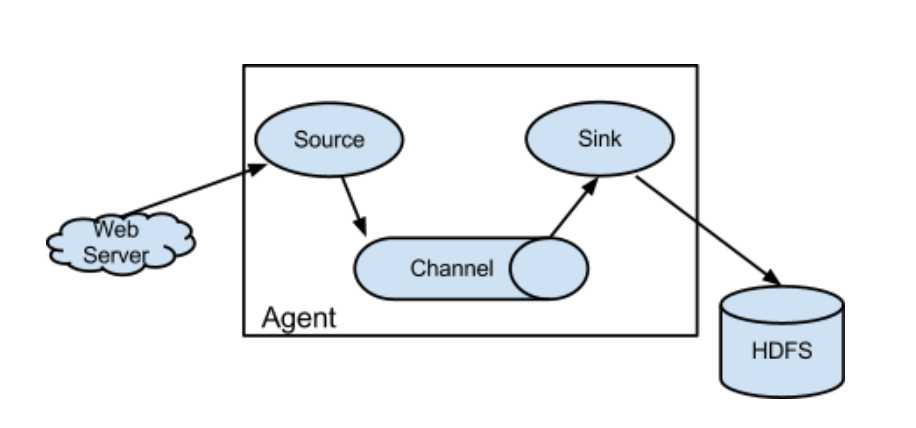
3.架构特点
-》on streaming data flows
基于流式的数据
数据流:job-》不断获取数据
任务流:job1->job2->job3&job4
-》for online analytic application.
-》Flume仅仅运行在linux环境下
如果我的日志服务器是Windows?
-》非常简单
写一个配置文件,运行这个配置文件
source、channel、sink
-》实时架构
flume+kafka spark/storm impala
-》agent三大部分
-》source:采集数据,并发送给channel
-》channel:管道,用于连接source和sink的
-》sink:发送数据,用于采集channel中的数据
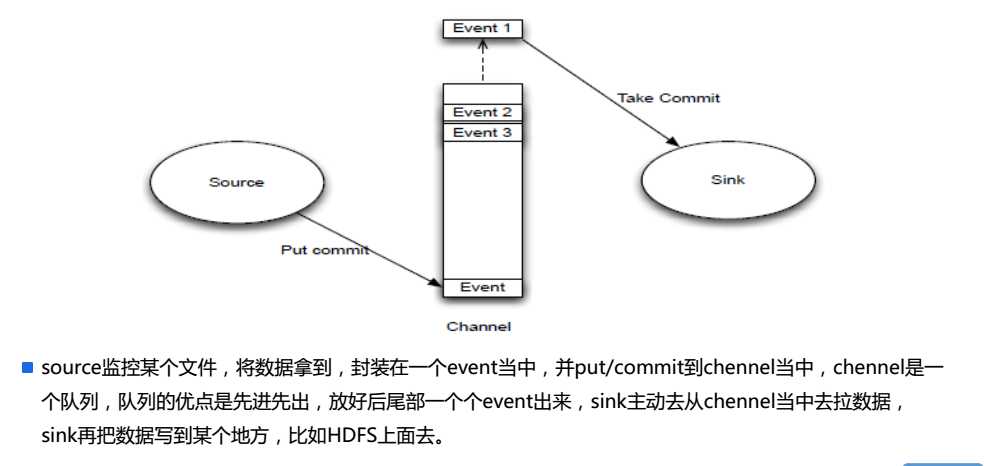
4.Event

5.Source/Channel/Sink
二:配置
1.下载解压
下载的是Flume版本1.5.0
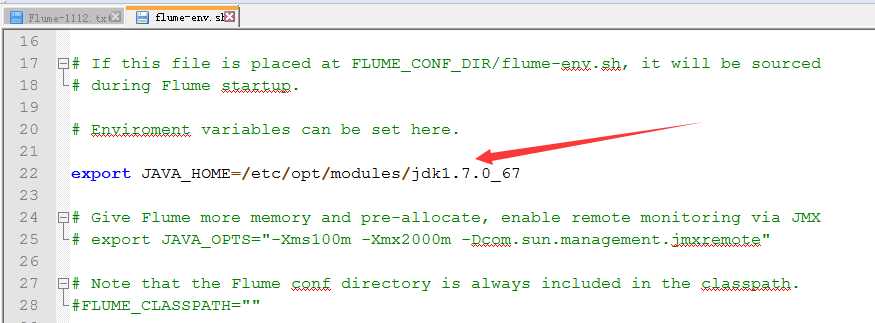
2.启用flume-env.sh

3.修改flume-env.sh
4.增加HADOOP_HOME
因为在env.sh中没有配置,选择的方式是将hdfs的配置放到conf目录下。

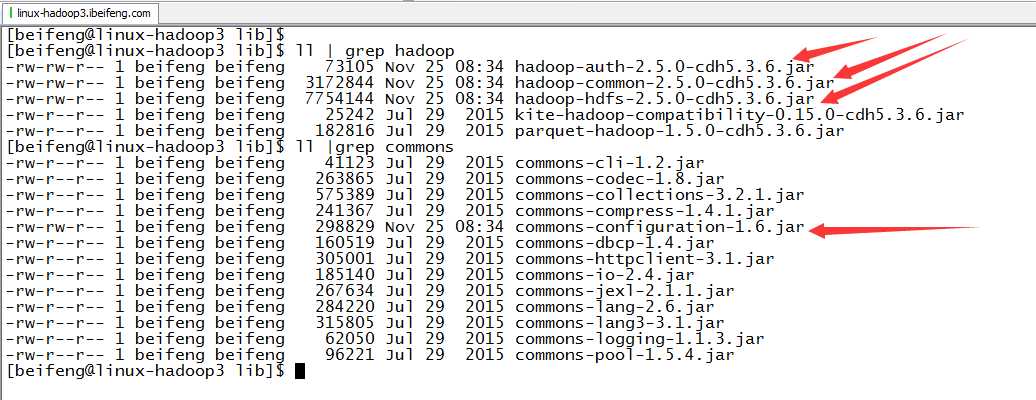
5.放入jar包
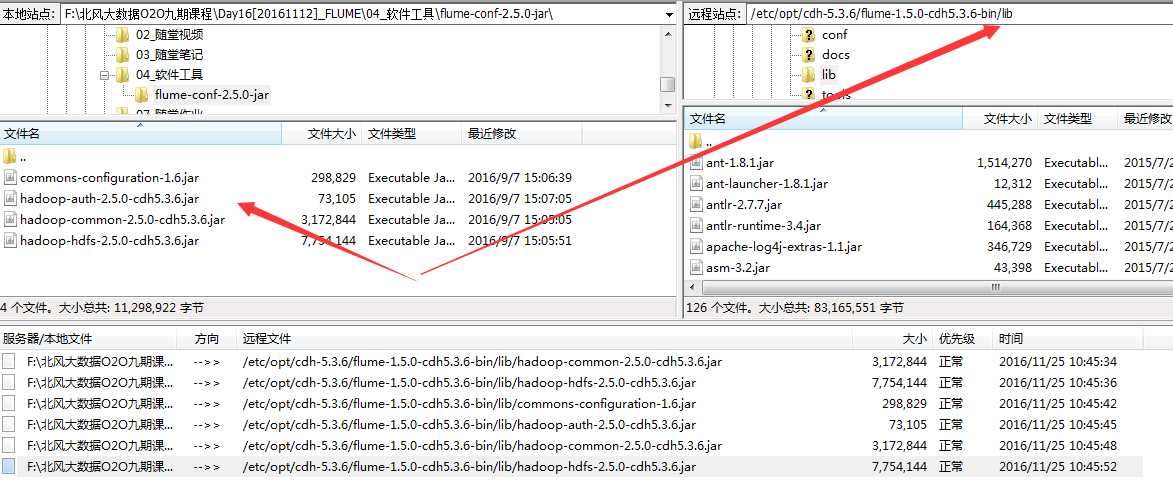
6.验证
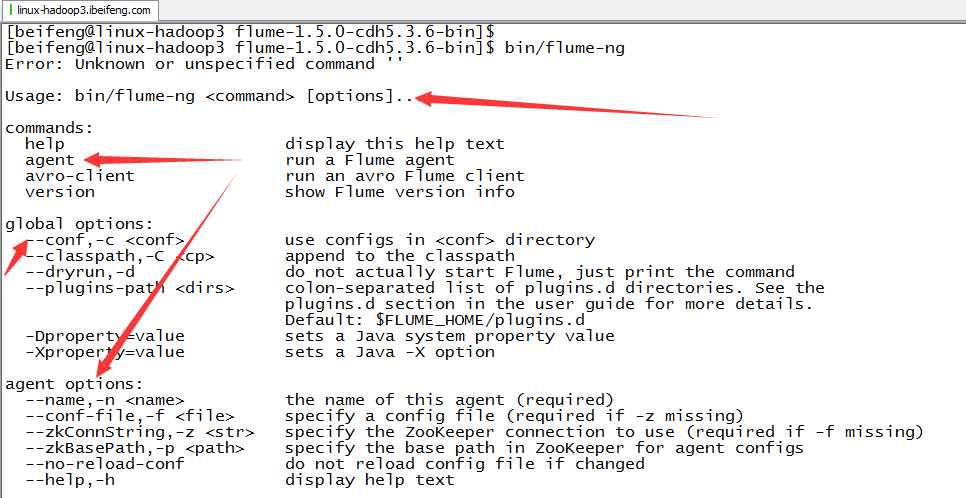
7.用法
三:Flume的使用

1.案例1
source:hive.log channel:mem sink:logger
2.配置
cp flume-conf.properties.template hive-mem-log.properties
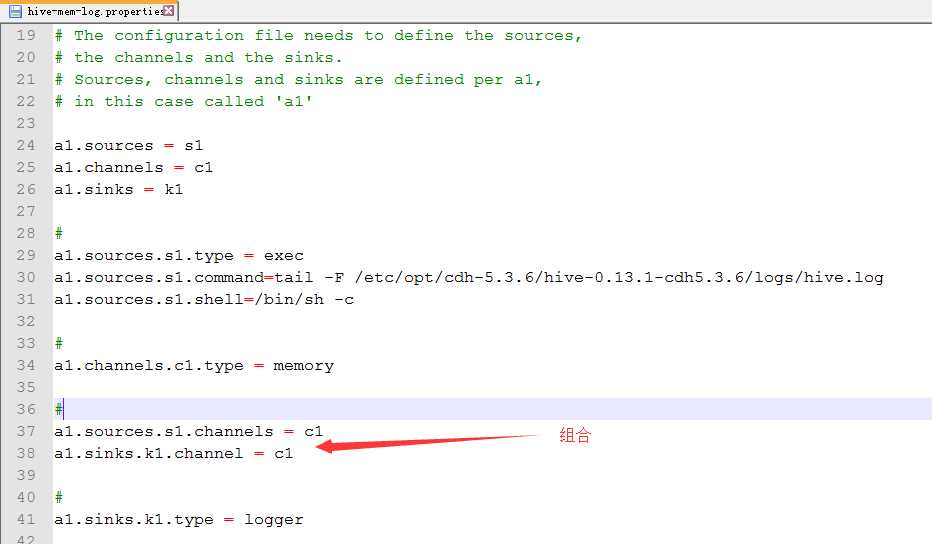
3.配置hive-mem-log.properties
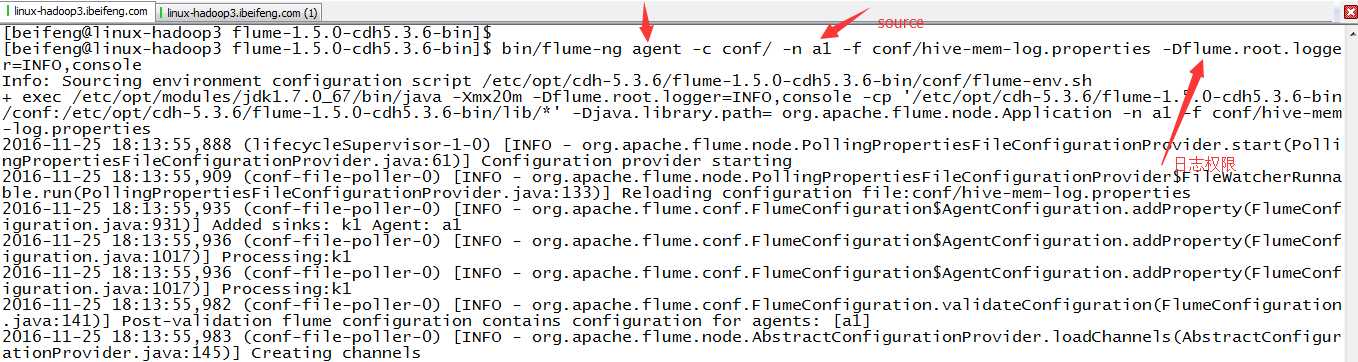
4.运行
那边是日志级别
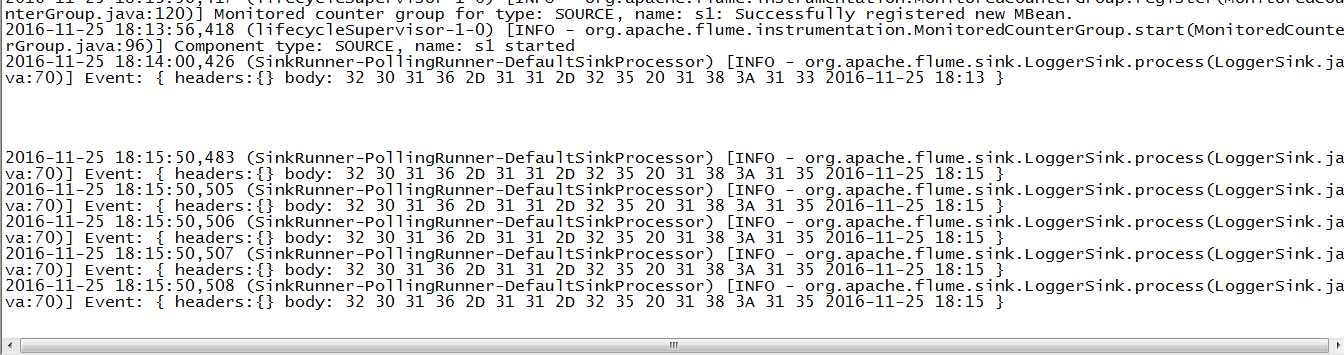
5.注意点
这边的属于实时采集,所以在控制台上的信息随着hive.log的变化在变化
6.案例二
source:hive.log channel:file sink:logger
7.配置
cp hive-mem-log.properties hive-file-log.properties
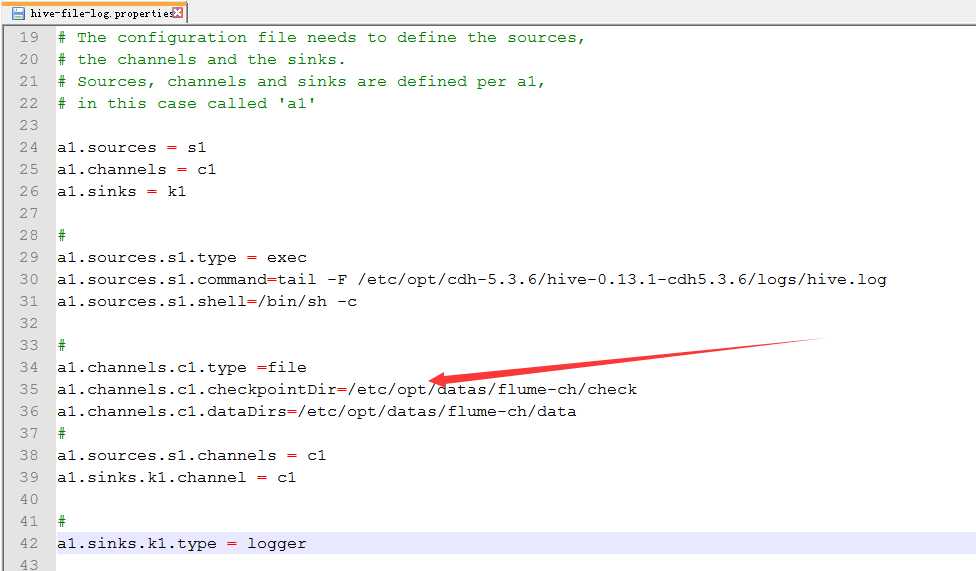
8.配置hive-file-log.properties
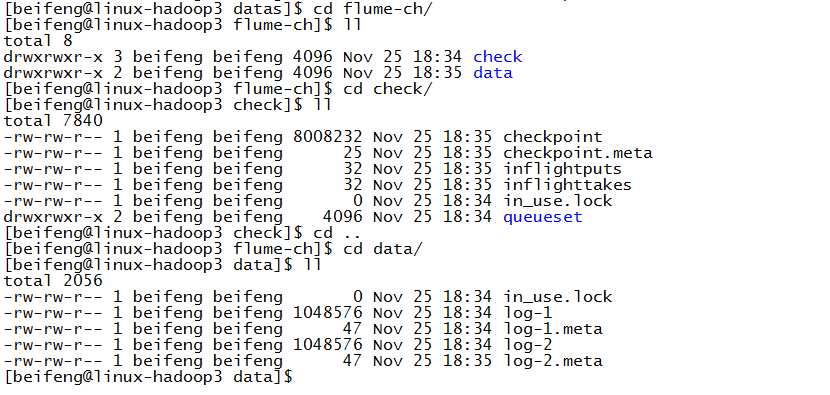
新建file的目录
配置
9.运行
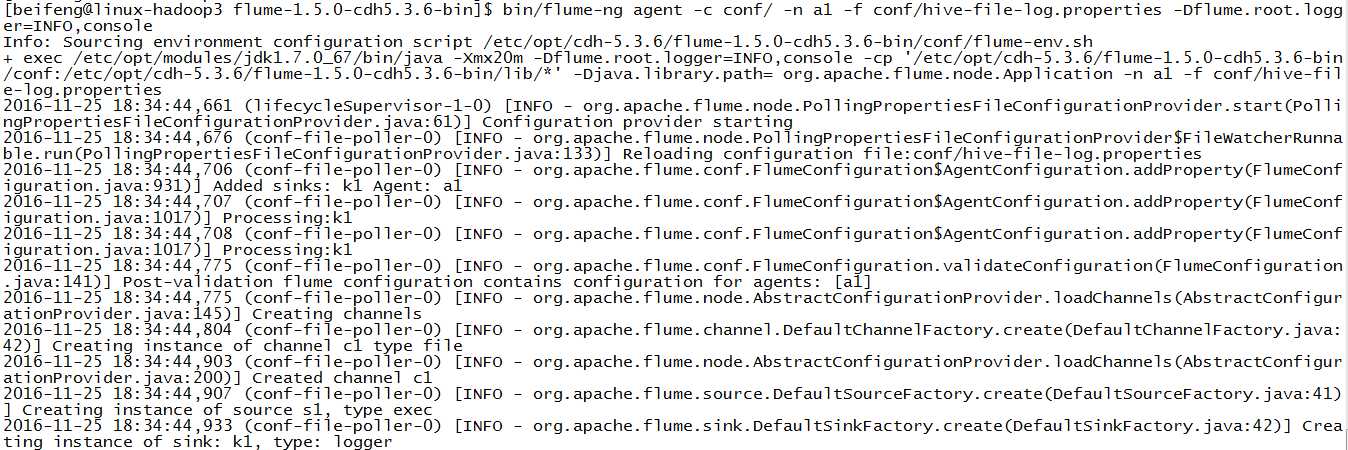
10.结果
11.案例三
source:hive.log channel:mem sink:hdfs
12.配置
cp hive-mem-log.properties hive-mem-hdfs.properties
13.配置hive-mem-hdfs.properties
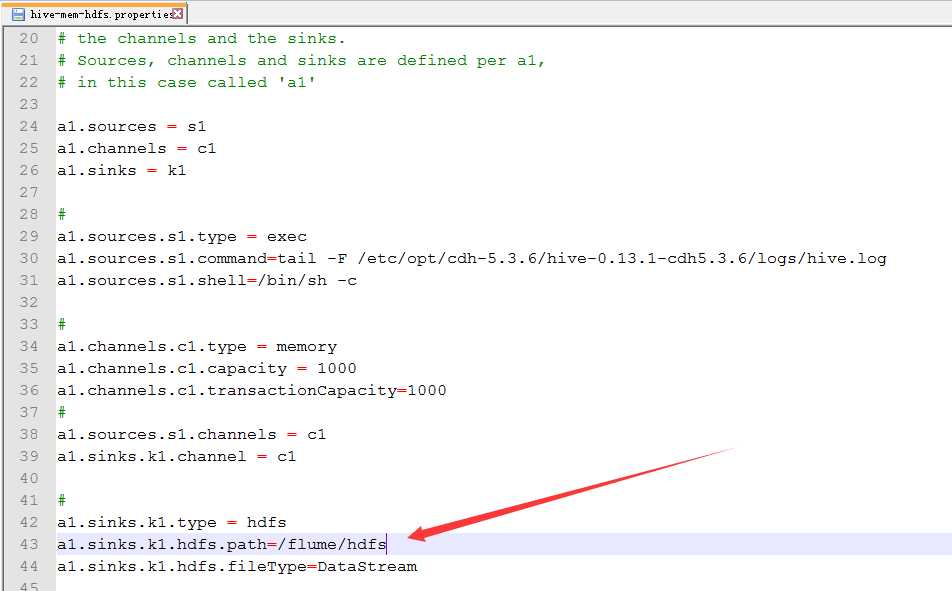
14.运行
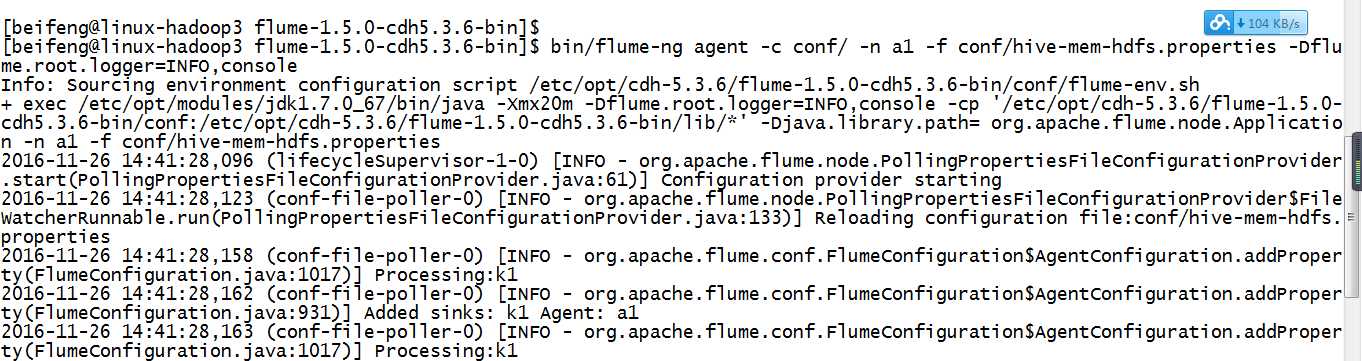
验证了,在配置文件中不需要有这个目录,会自动产生。
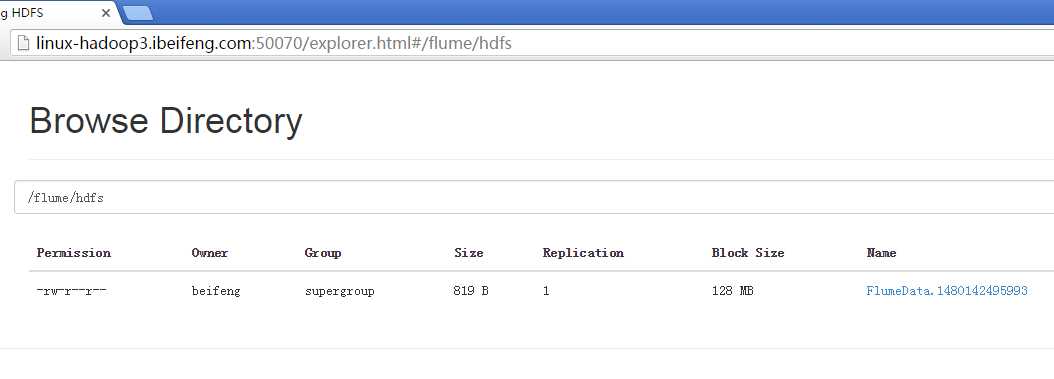
四:企业思考一
15.案例四
因为在hdfs上会生成许多小文件,文件的大小的设置。
16.配置
cp hive-mem-hdfs.properties hive-mem-size.properties
17.配置hive-mem-size.properties
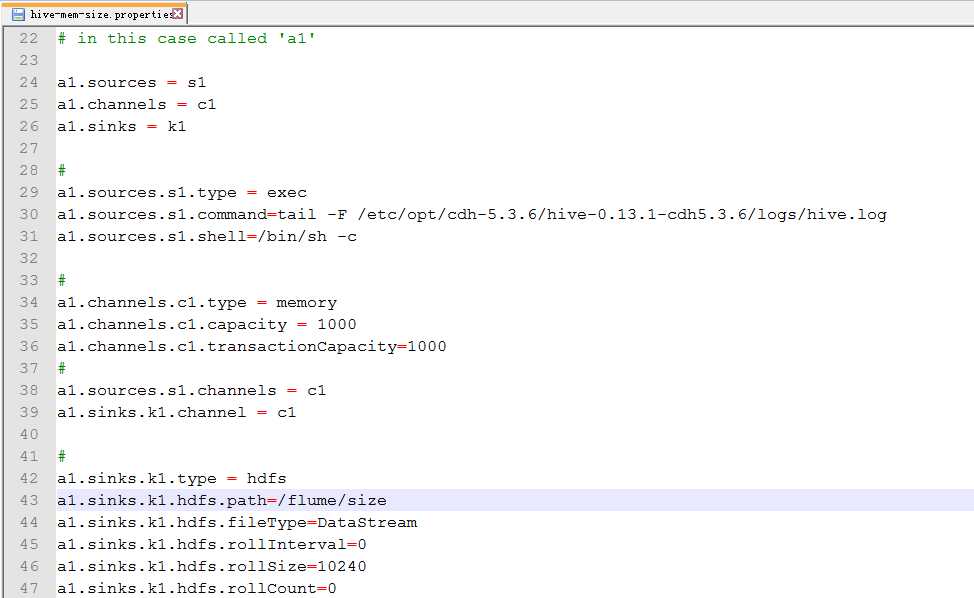
18.运行
19.结果
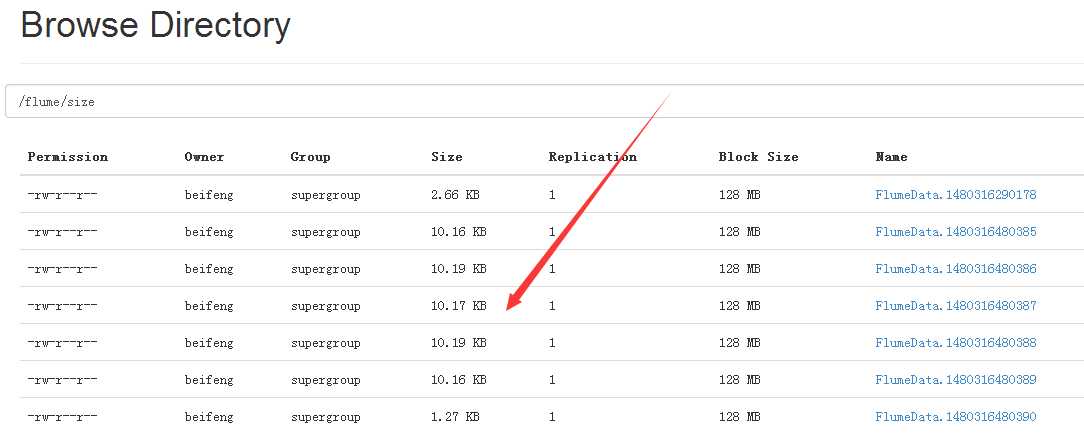
20.案例五
按时间进行分区
21.配置
cp hive-mem-hdfs.properties hive-mem-part.properties
22.配置hive-mem-part.properties
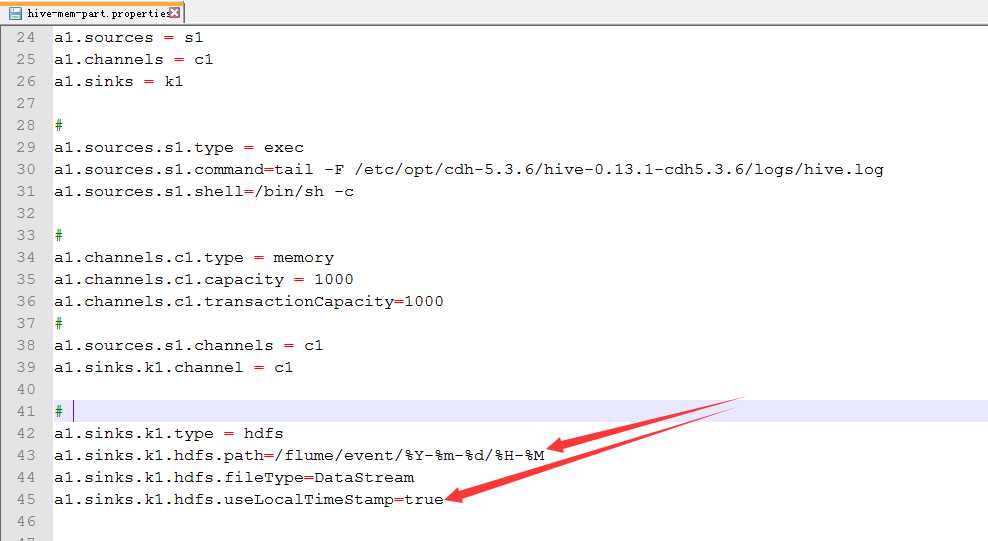
23.运行
bin/flume-ng agent -c conf/ -n a1 -f conf/hive-mem-part.properties -Dflume.root.logger=INFO,console
24.运行结果
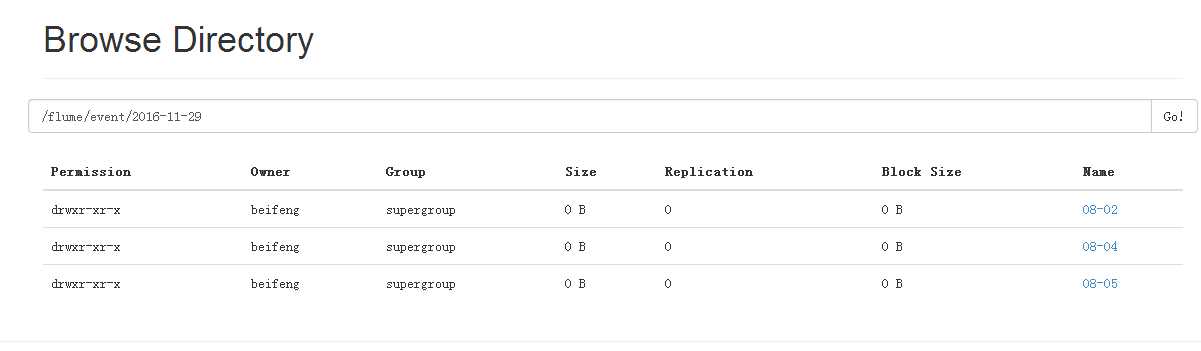
25.案例六
自定义文件开头
26.配置hive-mem-part.properties
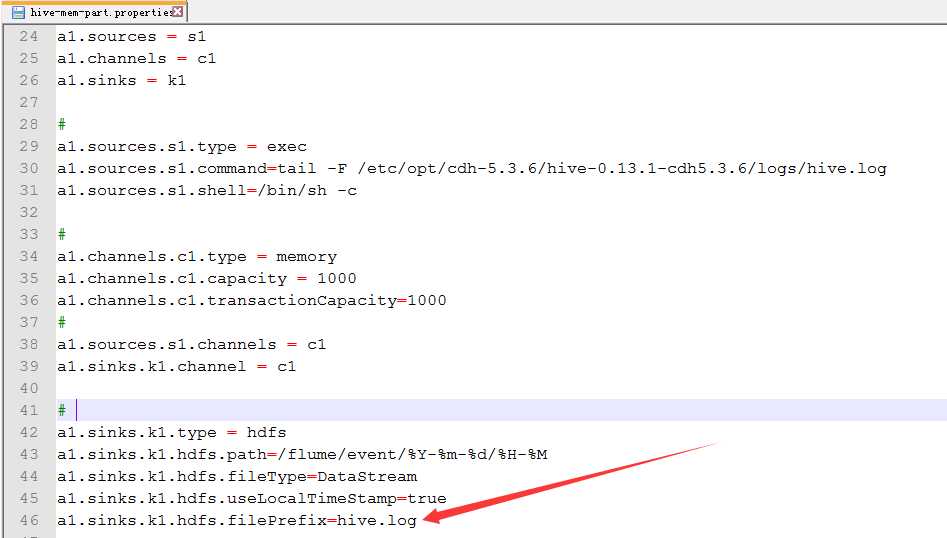
27.运行效果
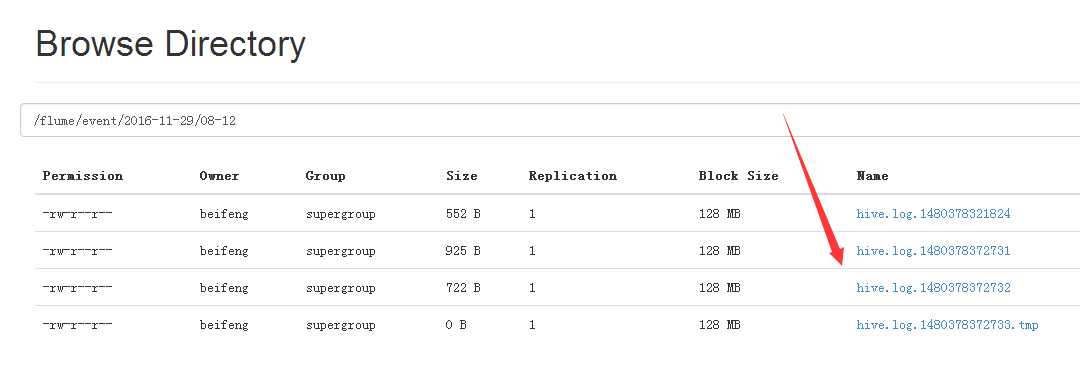
五:企业思考二
1.案例七
source:用来监控文件夹
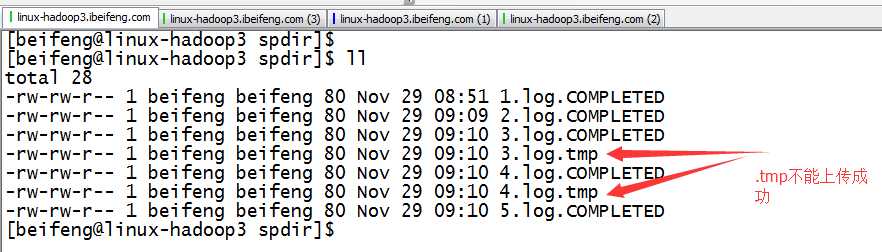
文件中先存在.tmp
到第二日出现新的.tmp文件。前一天的.tmp马上变成log结尾,这时监控文件夹时,马上发现出现一个新的文件,就被上传进HDFS
2.配置
cp hive-mem-hdfs.properties dir-mem-hdfs.properties
3.正则表达式忽略上传的.tmp文件
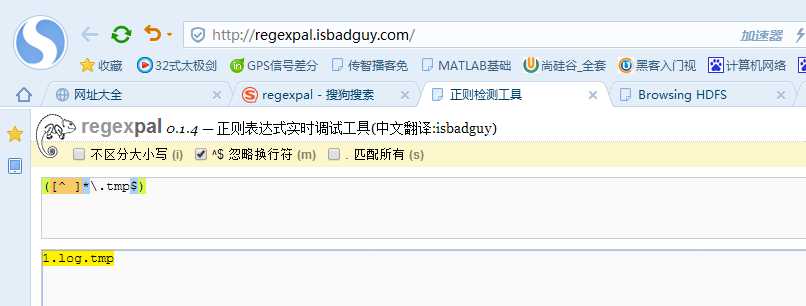
3.配置dir-mem-hdfs.properties
新建文件夹
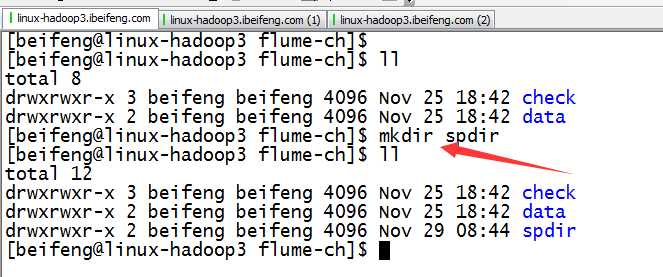
配置
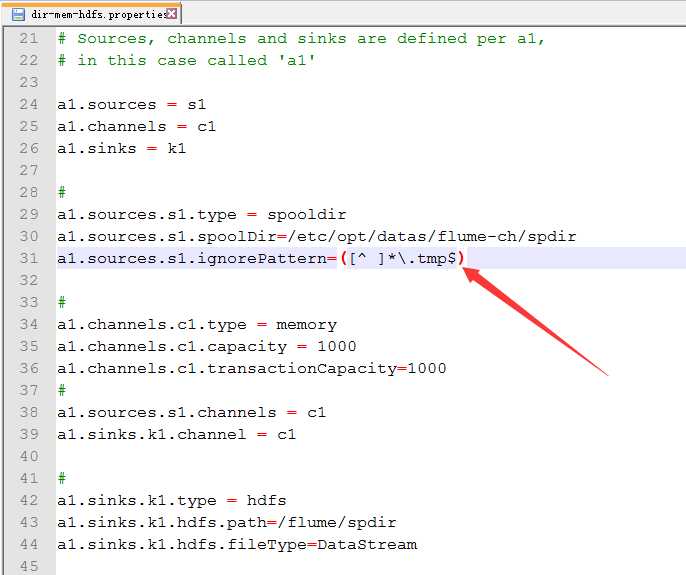
4.观察结果
5.案例二
source:监控文件夹下文件的不断动态追加
但是现在不是监控新出现的文件下,
这个配置将在下面讲解
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
六:企业实际架构
1.flume多sink
同一份数据采集到不同的框架
采集source:一份数据
管道channel:案例中使用两个管道
目标sink:多个针对于多个channel
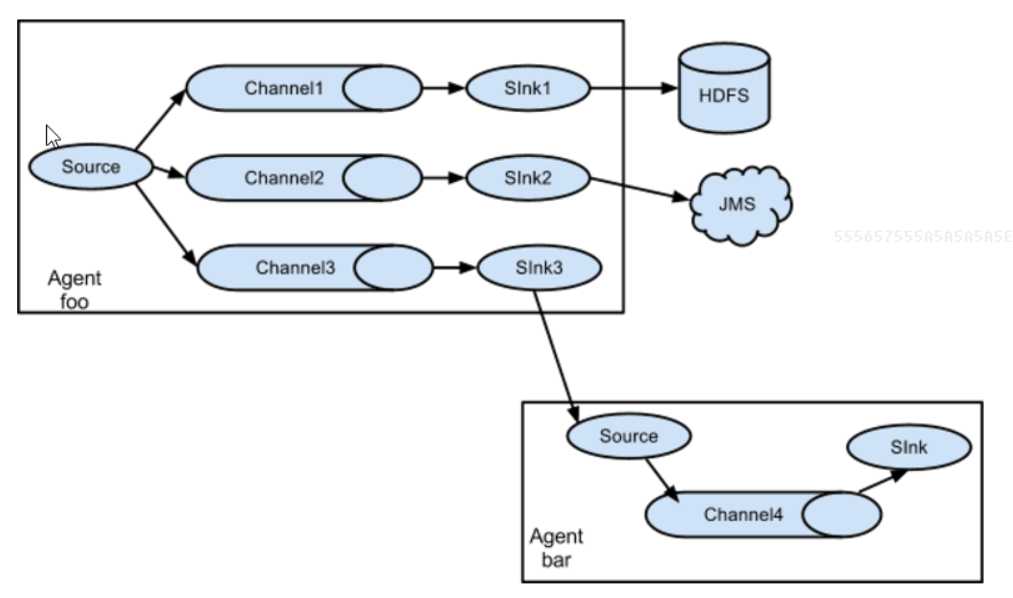
2.案例
source:hive.log channel:file sink:hdfs
3.配置
cp hive-mem-hdfs.properties sinks.properties
4.配置sink.properties
新建存储的文件

配置
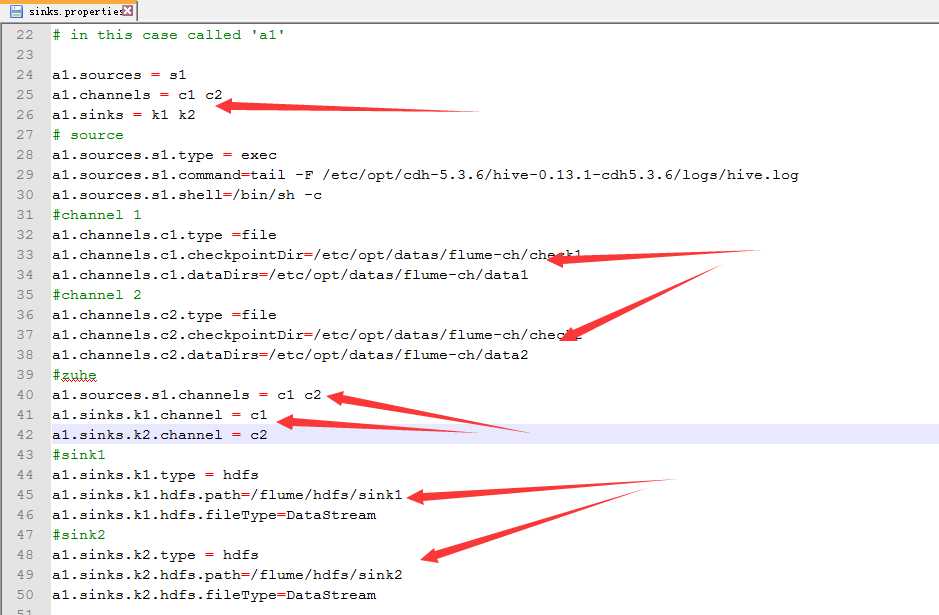
5.效果
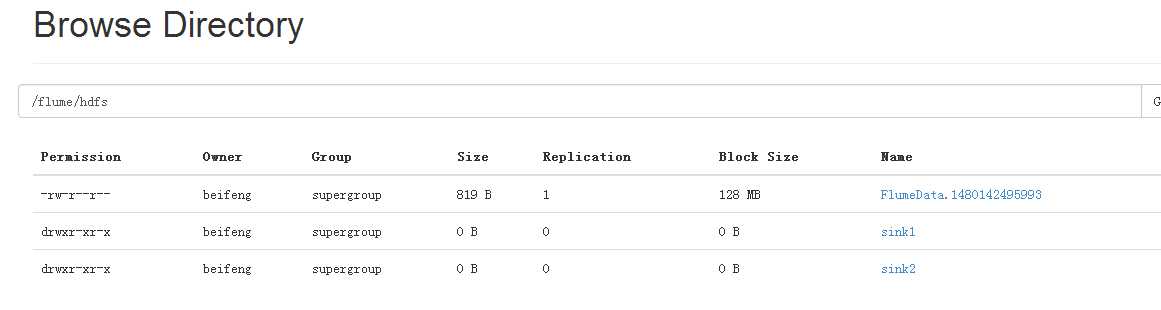
6.flume的collect
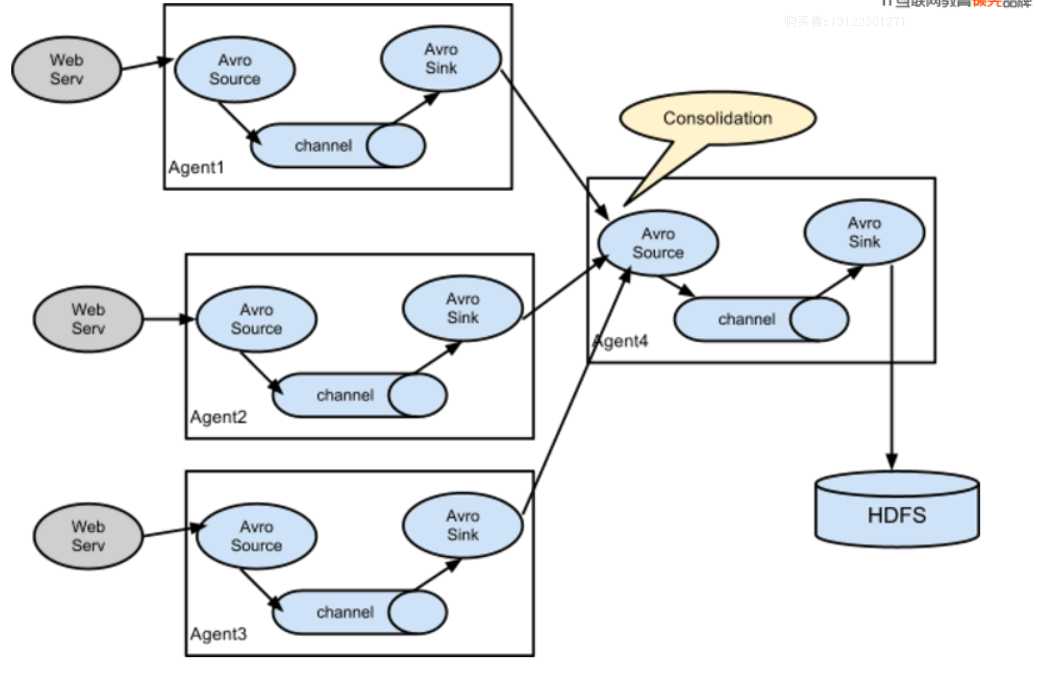
7.案例
启动三台机器,其中两台为agent,一台collect。
192.168.134.241:collect
192.168.134.242:agent
192.168.134.243:agent
8.情况
因为没有搭建cdh集群,暂时不粘贴
9.运行
运行:collect
bin/flume-ng agent -c conf/ -n a1 -f conf/avro-collect.properties -Dflume.root.logger=INFO,console
运行:agent
bin/flume-ng agent -c conf/ -n a1 -f conf/avro-agent.properties -Dflume.root.logger=INFO,console
七:关于文件夹中文件处于追加的监控
1.安装git
2.新建一个文件下
3.在git bash 中进入目录
4.在此目录下下载源码
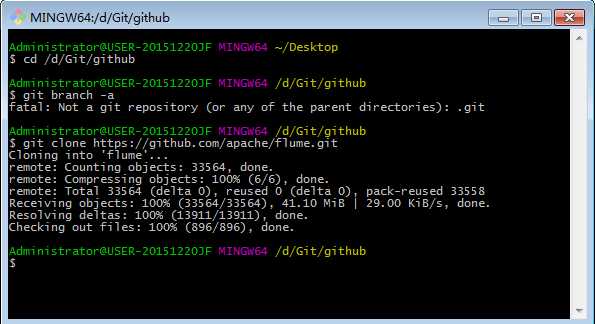
5.进入flume目录
6.查看源码有哪些分支
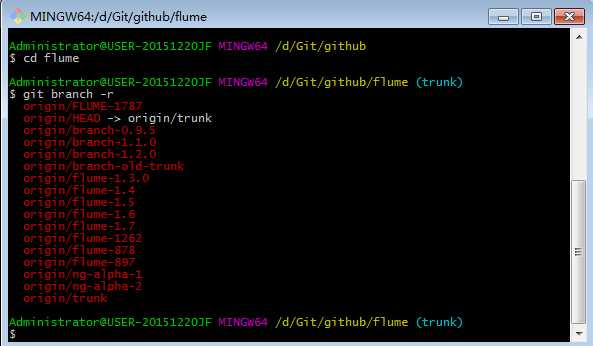
7.切换分支
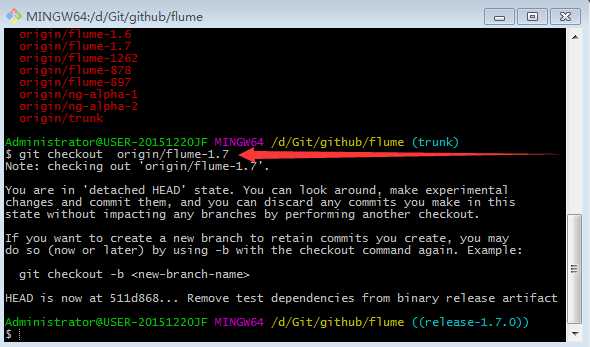
8.复制出flume-taildir-source
九。编译
1.pom文件
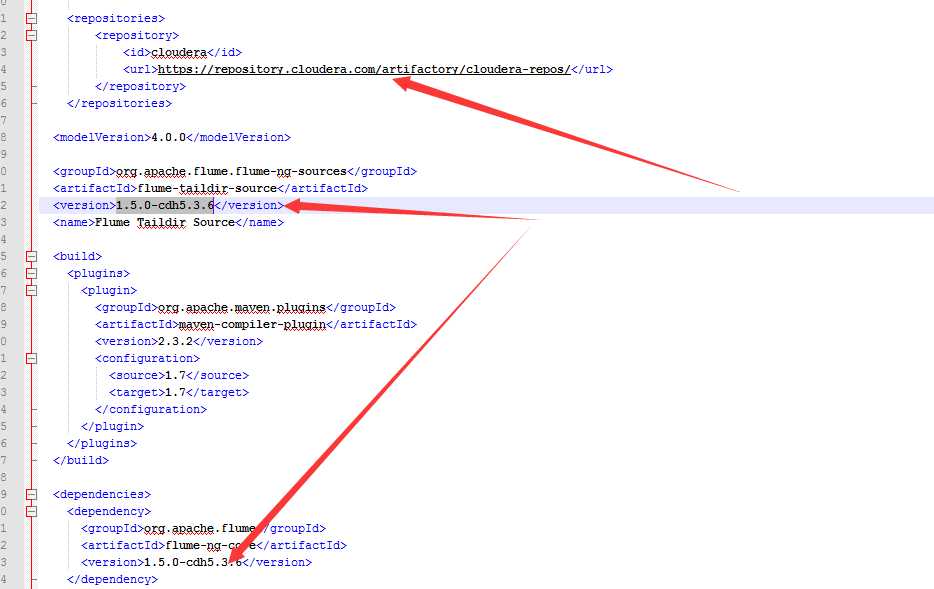
2.在1.5.0中添加一个1.7.0中的类
PollableSourceConstants
3.删除override
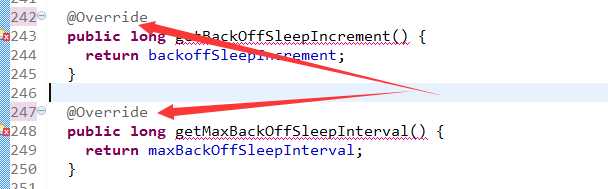
4.编译
run as -> maven build
goals -> skip testf
5.将jar包放在lib目录下
6.使用
因为这是1.7.0的源码,所以在1.5的文档中没有。
所以:可以看源码
或者看1.7.0的参考文档关于Tail的介绍案例
\flume\flume-ng-doc\sphinx\FlumeUserGuide
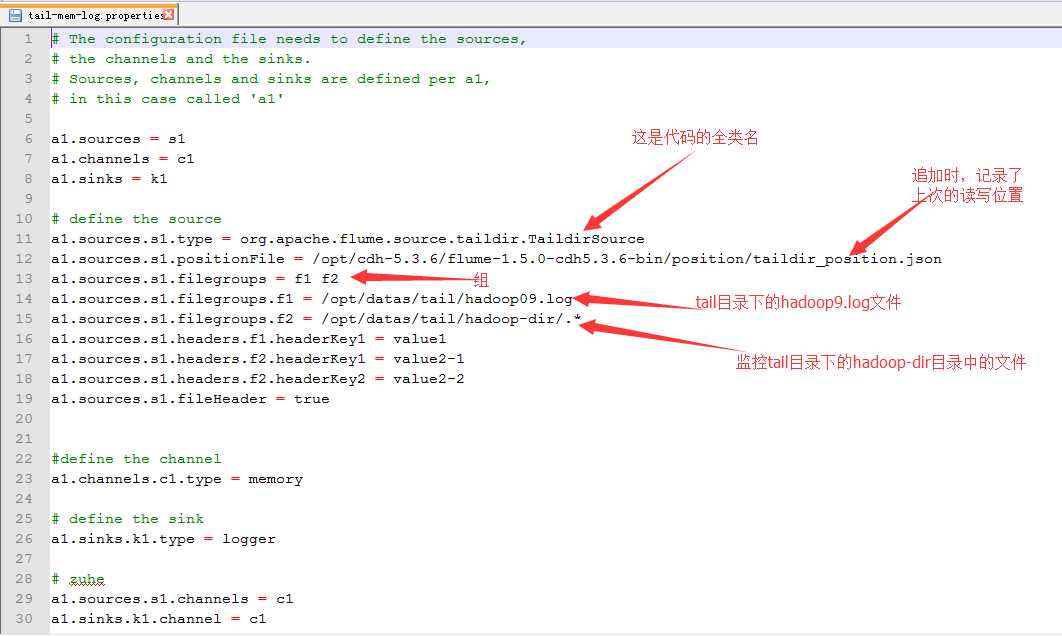
7.配置
标签:修改 art uid 结果 不同的 正则 架构 ica over
原文地址:http://www.cnblogs.com/RHadoop-Hive/p/7414013.html