标签:tin lca ash 覆写 instance cal odi 设置 重写
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些过期的数据删除掉,比如我们缓存10000条数据,当数据小于10000时可以随意添加,当超 过10000时就需要把新的数据添加进来,同时要把过期数据删除,以确保我们最大缓存10000条,那怎么确定删除哪条过期数据呢,采用LRU算法实现的 话就是将最老的数据删掉
1.2. 实现
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
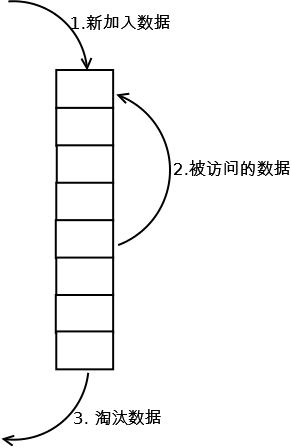
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
java中最简单的LRU算法实现,就是利用jdk的LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可
LRU Cache的LinkedHashMap实现
LinkedHashMap自身已经实现了顺序存储,默认情况下是按照元素的添加顺序存储,也可以启用按照访问顺序存储,即最近读取的数据放在最前面,最 早读取的数据放在最后面,然后它还有一个判断是否删除最老数据的方法,默认是返回false,即不删除数据,我们使用LinkedHashMap实现 LRU缓存的方法就是对LinkedHashMap实现简单的扩展,扩展方式有两种,一种是inheritance,一种是delegation,具体使 用什么方式看个人喜好
/**
* LinkedHashMap的一个构造函数,当参数accessOrder为true时,即会按照访问顺序排序,
* 最近访问的放在最前,最早访问的放在后面
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* LinkedHashMap自带的判断是否删除最老的元素方法,默认返回false,即不删除老数据
* 我们要做的就是重写这个方法,当满足一定条件时删除老数据
* Returns <tt>true</tt> if this map should remove its eldest entry.
* This method is invoked by <tt>put</tt> and <tt>putAll</tt> after
* inserting a new entry into the map. It provides the implementor
* with the opportunity to remove the eldest entry each time a new one
* is added. This is useful if the map represents a cache: it allows
* the map to reduce memory consumption by deleting stale entries.
*
* <p>Sample use: this override will allow the map to grow up to 100
* entries and then delete the eldest entry each time a new entry is
* added, maintaining a steady state of 100 entries.
* <pre>
* private static final int MAX_ENTRIES = 100;
*
* protected boolean removeEldestEntry(Map.Entry eldest) {
* return size() > MAX_ENTRIES;
* }
* </pre>
*
* <p>This method typically does not modify the map in any way,
* instead allowing the map to modify itself as directed by its
* return value. It <i>is</i> permitted for this method to modify
* the map directly, but if it does so, it <i>must</i> return
* <tt>false</tt> (indicating that the map should not attempt any
* further modification). The effects of returning <tt>true</tt>
* after modifying the map from within this method are unspecified.
*
* <p>This implementation merely returns <tt>false</tt> (so that this
* map acts like a normal map - the eldest element is never removed).
*
* @param eldest The least recently inserted entry in the map, or if
* this is an access-ordered map, the least recently accessed
* entry. This is the entry that will be removed it this
* method returns <tt>true</tt>. If the map was empty prior
* to the <tt>put</tt> or <tt>putAll</tt> invocation resulting
* in this invocation, this will be the entry that was just
* inserted; in other words, if the map contains a single
* entry, the eldest entry is also the newest.
* @return <tt>true</tt> if the eldest entry should be removed
* from the map; <tt>false</tt> if it should be retained.
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 缓存是需要自己实现同步的
* @param <K>
* @param <V>
*/
public class LRUCache<K, V> {
private int cacheSize;
private float loadFactor = 0.75f;
private Map<K, V> cache;
private final Lock lock = new ReentrantLock();
public LRUCache(int maxCapacity) {
cacheSize = maxCapacity;
//根据cacheSize和加载因子计算HashMap的capactiy,+1确保当达到cacheSize上限时不会触发HashMap的扩容
int capacity = (int) Math.ceil(cacheSize / loadFactor) + 1;
this.cache = new LinkedHashMap<K, V>(capacity, loadFactor, true) {
// 定义put后的移除规则,大于容量就删除eldest
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > cacheSize;
}
};
}
public boolean containsKey(Object key) {
try {
lock.lock();
return cache.containsKey(key);
} finally {
lock.unlock();
}
}
public V get(Object key) {
try {
lock.lock();
return cache.get(key);
} finally {
lock.unlock();
}
}
public V put(K key, V value) {
try {
lock.lock();
return cache.put(key, value);
} finally {
lock.unlock();
}
}
public int size() {
try {
lock.lock();
return cache.size();
} finally {
lock.unlock();
}
}
}
基于双链表 的LRU实现:
传统意义的LRU算法是为每一个Cache对象设置一个计数器,每次Cache命中则给计数器+1,而Cache用完,需要淘汰旧内容,放置新内容时,就查看所有的计数器,并将最少使用的内容替换掉。
它的弊端很明显,如果Cache的数量少,问题不会很大, 但是如果Cache的空间过大,达到10W或者100W以上,一旦需要淘汰,则需要遍历所有计算器,其性能与资源消耗是巨大的。效率也就非常的慢了。
它的原理: 将Cache的所有位置都用双连表连接起来,当一个位置被命中之后,就将通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。
这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。
当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。
上面说了这么多的理论, 下面用代码来实现一个LRU策略的缓存。
我们用一个对象来表示Cache,并实现双链表,
import java.util.HashMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LRUCache<K, V> {
private final int MAX_CACHE_SIZE;
private CacheNode first;
private CacheNode last;
private final Lock lock = new ReentrantLock();
private HashMap<K, CacheNode<K, V>> hashMap;
public LRUCache(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
hashMap = new HashMap<K, CacheNode<K, V>>();
}
public void put(K key, V value) {
try {
lock.lock();
CacheNode CacheNode = getEntry(key);
if (CacheNode == null) {
if (hashMap.size() >= MAX_CACHE_SIZE) {
hashMap.remove(last.key);
removeLast();
}
CacheNode = new CacheNode();
CacheNode.key = key;
}
CacheNode.value = value;
moveToFirst(CacheNode);
hashMap.put(key, CacheNode);
} finally {
lock.unlock();
}
}
public V get(K key) {
try {
lock.lock();
CacheNode<K, V> CacheNode = getEntry(key);
if (CacheNode == null) return null;
moveToFirst(CacheNode);
return CacheNode.value;
} finally {
lock.unlock();
}
}
public void remove(K key) {
try {
lock.lock();
CacheNode CacheNode = getEntry(key);
if (CacheNode != null) {
if (CacheNode.pre != null) CacheNode.pre.next = CacheNode.next;
if (CacheNode.next != null) CacheNode.next.pre = CacheNode.pre;
if (CacheNode == first) first = CacheNode.next;
if (CacheNode == last) last = CacheNode.pre;
}
hashMap.remove(key);
} finally {
lock.unlock();
}
}
private void moveToFirst(CacheNode CacheNode) {
if (CacheNode == first) {
return;
}
if (CacheNode.pre != null) {
CacheNode.pre.next = CacheNode.next;
}
if (CacheNode.next != null) {
CacheNode.next.pre = CacheNode.pre;
}
if (CacheNode == last) {
last = last.pre;
}
if (first == null || last == null) {
first = last = CacheNode;
return;
}
CacheNode.next = first;
first.pre = CacheNode;
first = CacheNode;
CacheNode.pre = null;
}
private void removeLast() {
try {
lock.lock();
if (last != null) {
last = last.pre;
if (last == null) {
first = null;
} else {
last.next = null;
}
}
} finally {
lock.unlock();
}
}
private CacheNode<K, V> getEntry(K key) {
try {
lock.lock();
return hashMap.get(key);
} finally {
lock.unlock();
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
CacheNode CacheNode = first;
while (CacheNode != null) {
sb.append(String.format("%s:%s ", CacheNode.key, CacheNode.value));
CacheNode = CacheNode.next;
}
return sb.toString();
}
class CacheNode<K, V> {
CacheNode pre;
CacheNode next;
K key;
V value;
CacheNode() {
}
}
}
测试:
public class Test {
public static void main(String[] args) {
lruCache();
}
static void lruCache() {
//最多缓存5条数据
LRUCache<Integer, String> lru = new LRUCache(5);
lru.put(1, "11");
lru.put(2, "11");
lru.put(3, "11");
lru.put(4, "11");
lru.put(5, "11");
System.out.println(lru.toString());
lru.put(6, "66");
lru.get(2);
lru.put(7, "77");
lru.get(4);
System.out.println(lru.toString());
System.out.println();
}
}
运行结果;
5:11 4:11 3:11 2:11 1:11
4:11 7:77 2:11 6:66 5:11
标签:tin lca ash 覆写 instance cal odi 设置 重写
原文地址:http://www.cnblogs.com/winner-0715/p/7417830.html