标签:table pre code mysq -- xxx 需求 exp and
索引对提升SELECT/UPDATE语句查询速度有着立竿见影的效果,有索引和无索引,查询速度往往差几个数量级。
本次讨论一下index(每列作为一个索引,单列索引)和Multiple-Column Indexes(多列作为一个索引,最多16列,复合索引)使用场景。
方式一,建表时新建
CREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), -- 单列索引 INDEX name (last_name) -- 复合索引 -- INDEX name (last_name,first_name) );
方式二,给即存表添加索引:
/*单列索引*/ ALTER TABLE test ADD INDEX name (last_name); /*复合索引*/ ALTER TABLE test ADD INDEX name (last_name,first_name);
这里要注意索引的顺序很重要,关系到能否命中索引,后面详细讨论。
mysql官方文档是这么描述复合索引的:mysql能使用复合索引来查询索引中的所有列,或者查询复合索引中的第一列、前两列、前三列等等。
如果指定列顺序正确相对于索引中的定义顺序,那么一个简单的复合作引可以加快一个表中几种类型的查询。官网地址
以上这段话包可解读如下:
简单的说加入复合索引的顺序是(col1, col2, col3)那么WHERE语句中的(col1)、(ol1, col2)、(col1, col2, col3)都能命中索引,但是(col2)、(col3)、(ol2, col3)是不能命中索引规则的,因为不满足最左前缀规则。
举个栗子,假设新建复合索引如下:
CREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name,first_name) );
根据最左前缀原则,以下查询语句能命中索引:
SELECT * FROM test WHERE last_name=‘Widenius‘; SELECT * FROM test WHERE last_name=‘Widenius‘ AND first_name=‘Michael‘; SELECT * FROM test WHERE last_name=‘Widenius‘ AND (first_name=‘Michael‘ OR first_name=‘Monty‘); SELECT * FROM test WHERE last_name=‘Widenius‘ AND first_name >=‘M‘ AND first_name < ‘N‘;
以下查询语句不能命中复合索引:
SELECT * FROM test WHERE first_name=‘Michael‘; SELECT * FROM test WHERE last_name=‘Widenius‘ OR first_name=‘Michael‘;
如果不清楚是否命中索引,EXPLAIN是个好工具,要充分利用起来。比如下语句,查看结果中的key就能知道是否命中,为空就是木有命中:
EXPLAIN SELECT * FROM test WHERE first_name=‘Michael‘;
在做报表集计一般会使用ETL工具抽取业务数据插入到事实表中,就比如使用kettle update/insert,其内部原理都是先查询不存在就如插入数据,存在数据就更新。
因此如果数据很多的话就会有很多的查询动作,并且是多条件查询。这种情况复合索引效率是最高的,但是往往实际的业务中还会以单列作为查询的场合这是就需要普通索引来满足这个需求。
这种场合就会出现同一列同时出现在了复合索引和单列索引中,这也是很正常的。给一个实际的例子如下:
CREATE TABLE `st_stock` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT ‘自增ID‘, `id_company` int(11) NOT NULL COMMENT ‘组织维度‘, `id_date` int(11) NOT NULL COMMENT ‘日期维度‘, `id_part` int(11) NOT NULL COMMENT ‘材料维度‘, `number` decimal(18,2) DEFAULT NULL COMMENT ‘出库数量‘, `subtotal` decimal(21,6) DEFAULT NULL COMMENT ‘出库金额‘, PRIMARY KEY (`id`), KEY `IDX_ORG` (`id_company`), KEY `IDX_PART` (`id_part`), KEY `IDX_DATE_ORG_PART` (`id_date`,`id_company`,`id_part`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT=‘xxxxxx‘;
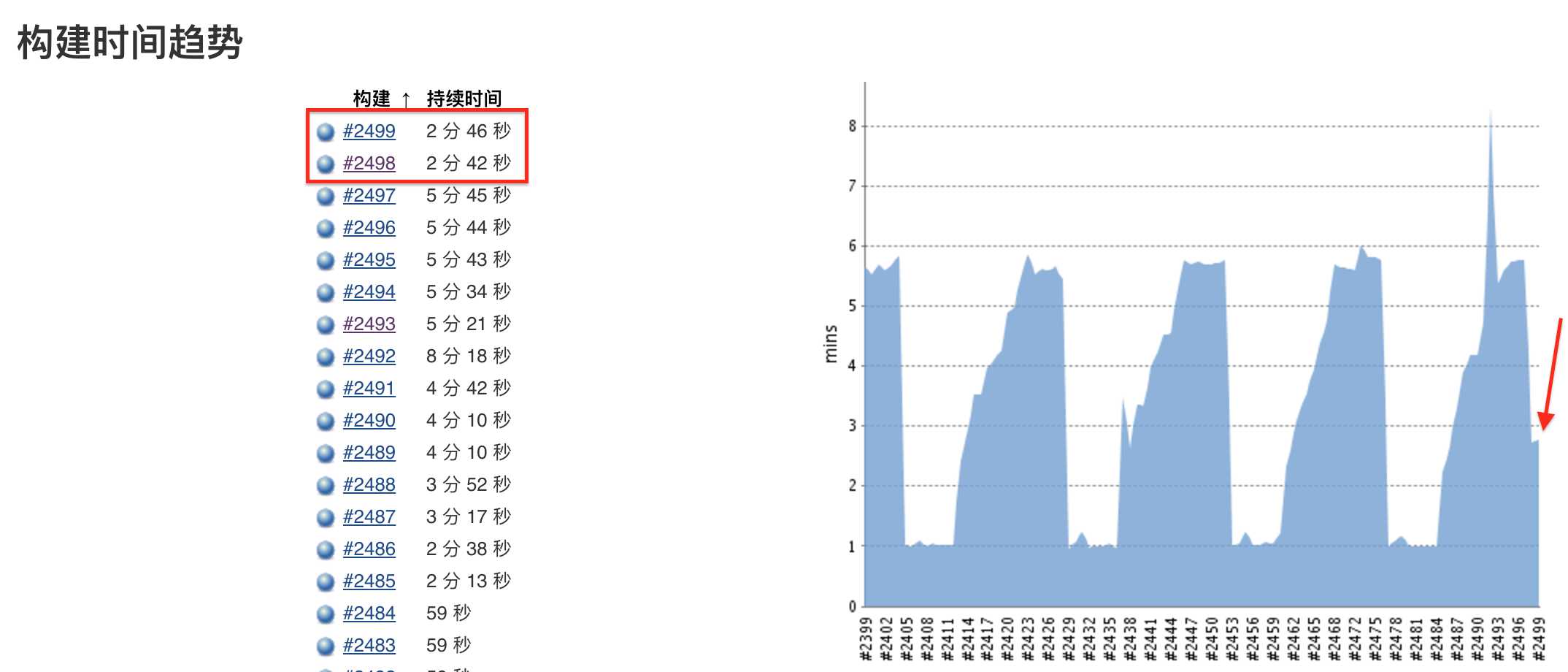
#2498和#2499数据量大于等于#2496、#2497,但集计时间将近缩短了一半,效果还是很明显。
优化效果没有达到一个数量或更高级是因为优化的只是JOB中一个转换,只是优化的众多因素之一。
即便如此也达到了预期的效果。
最后还要注意一点,索引的维护是有代价的,并不是越多越好。其他参考资料如下:
https://www.percona.com/blog/2009/09/19/multi-column-indexes-vs-index-merge/
https://www.percona.com/blog/2014/01/03/multiple-column-index-vs-multiple-indexes-with-mysql-56/
https://dev.mysql.com/doc/refman/5.7/en/drop-index.html
https://dev.mysql.com/doc/refman/5.6/en/multiple-column-indexes.html
https://dev.mysql.com/doc/refman/5.7/en/create-index.html
mysql中index与Multiple-Column Indexes区别与联系
标签:table pre code mysq -- xxx 需求 exp and
原文地址:http://www.cnblogs.com/maxiaofang/p/7420656.html