标签:分享 判断 是什么 odi 编号 操作 yesterday amp tin
集合操作
集合是一个无序的,不重复的数据组合,它的主要作用如下:
去重,把一个列表变成集合,就自动去重
关系测试,测试两组数据之前的交集,差集,并集等关系# Author:Zhiyu Su
list_1 = [1,4,5,7,3,6,7,9] list_1 = set(list_1) #转换为集合 list_2 = set([2,6,0,66,22,8,4,]) print(list_1,list_2) ‘‘‘ #交集 intersection print(list_1.intersection(list_2)) #并集 union print(list_1.union(list_2)) #差集 difference
print(list_1.difference(list_2)) print(list_2.difference(list_1)) #子集 list_3 = set([1,3,7]) print(list_3.issubset(list_1)) #判断是否是子集 list3是否是list1的子集 print(list_1.issuperset(list_3)) #判断是否是父集 list1是否是list3的父集 #对称差集 print(list_1.symmetric_difference(list_2)) #把俩个集合里面互相都没有的取出来 print(‘---------------------‘) list_4 = set([5,6,7,8]) print(list_3.isdisjoint(list_4)) #判断是否有交集 #交集 print(list_1 & list_2) #并集 print(list_2 | list_1) #差集 print(list_1 -list_2) #in list1 but not in list #对称差集 print(list_1 ^ list_2) print(‘------------------‘) #增 list_1.add(999) list_1.update([888,777,555])
#使用remove()可以删除一项
t.remove(‘h‘)
#set的长度
len(s)
print(list_1.pop())#s随机删
x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制
文件操作
打开文件
#data = open(‘yesterday‘,encoding=‘utf-8‘).read()
f = open(‘yesterday2‘,‘a‘,encoding=‘utf-8‘) #文件句柄:文件的内存对象 文件名 字符集硬盘上的起始位置 #a = append 追加 f.write(‘when i was young i listen to the radio\n‘)#写入 data = f.read() #read的读第二遍无法获取内容因为第一次读取之后光标到尾端 print(‘----read,‘,data) f.close() #关闭模式
文件打开模式
py3.0传输只能用二进制模式 (文件是以二进制编码不是二进制)
f = open(‘yesterday2‘,‘r‘,encoding=‘utf-8‘) #文件句柄 读
f = open(‘yesterday2‘,‘w‘,encoding=‘utf-8‘) #文件句柄 写
f = open(‘yesterday2‘,‘a‘,encoding=‘utf-8‘) #文件句柄 追加
f = open(‘yesterday2‘,‘r+‘,encoding=‘utf-8‘) #文件句柄 读写 读取一个文件然后在追加 f = open(‘yesterday2‘,‘w+‘,encoding=‘utf-8‘) #文件句柄 写读 创建一个文件再写入 f = open(‘yesterday2‘,‘w+‘,encoding=‘utf-8‘) #文件句柄 追加写 f = open(‘yesterday2‘,‘wb‘) #文件句柄 二进制读 f.write(‘hello binary\n‘.encode()) #二进制写入 f.close()
读取文件
print(f.readline()) #readline读取一行 for i in range(5): #读取五行
print(f.readline())
print(f.readlines()) #文件里所有内容一列表形式打印出来
for line in f.readlines():#循环打印文件
print(line.strip())#打印时会出现空行 是读取文件时把每行的换行符打印
#循环不打印文件第10行
for index,line in enumerate(f.readlines()): #文件全部获取到内存里 适合小文件读取
if index== 9:
print(‘----------‘)
continue
print(line.strip())
#高效版及时读写 迭代器
count = 0
for line in f:
count += 1
if count == 9:
print(‘----------‘)
continue
print(line)
文件光标操作以及其他操作
f.seek(10) f.truncate(15) #如果不写值就是清空,写值就是截断 print(f.tell()) #文件句柄指针 print(f.readline()) print(f.readline()) print(f.readline()) print(f.tell()) #读取指针,按字节算 f.seek(0) #移动光标 print(f.readline()) print(f.encoding) #打印文件的编码 print(f.flush()) #实时更新到硬盘里
print(f.fileno())#返回文件句柄的编号 当前打开的io接口
有关于flush 实时刷新的进度条
# Author:Zhiyu Su import sys,time for i in range(50): sys.stdout.write(‘/‘) sys.stdout.flush() time.sleep(0.1)
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文with在py2.7以后同时打开多个文件
with open(‘log‘,‘r‘)as f: print(f.readline())
with open(‘log1‘)as obj1,open(‘log2‘)as obj2:
.....
字符编码和转码
1.在python2默认编码是ASCII, python3里默认是unicode
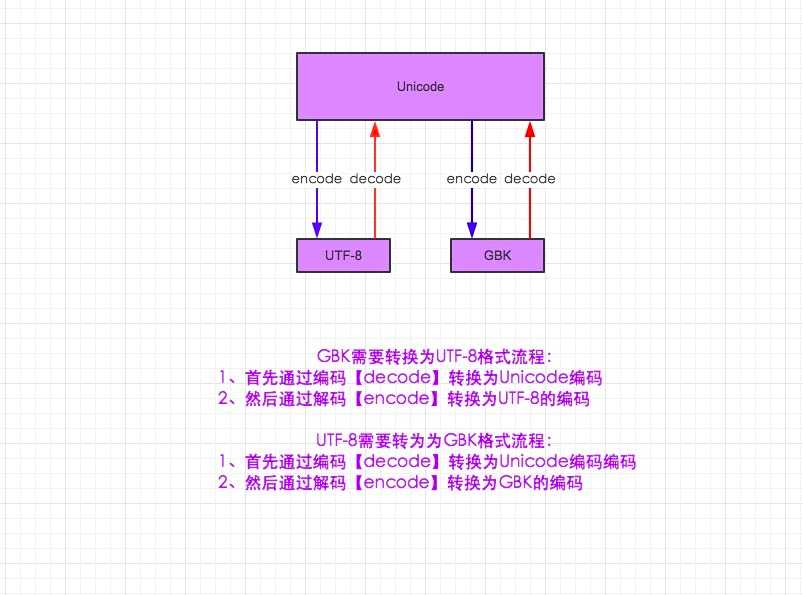
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间udf-8英文连个字节中文三个字节
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
函数
函数是什么
特性:
标签:分享 判断 是什么 odi 编号 操作 yesterday amp tin
原文地址:http://www.cnblogs.com/szy413227820/p/7424437.html