标签:image anaconda tar chrome referer nal start 代码 解析
深圳公租房轮候库已经朝着几十万人的规模前进了,这是截至16年10月之前的数据了,贴上来大家体会下
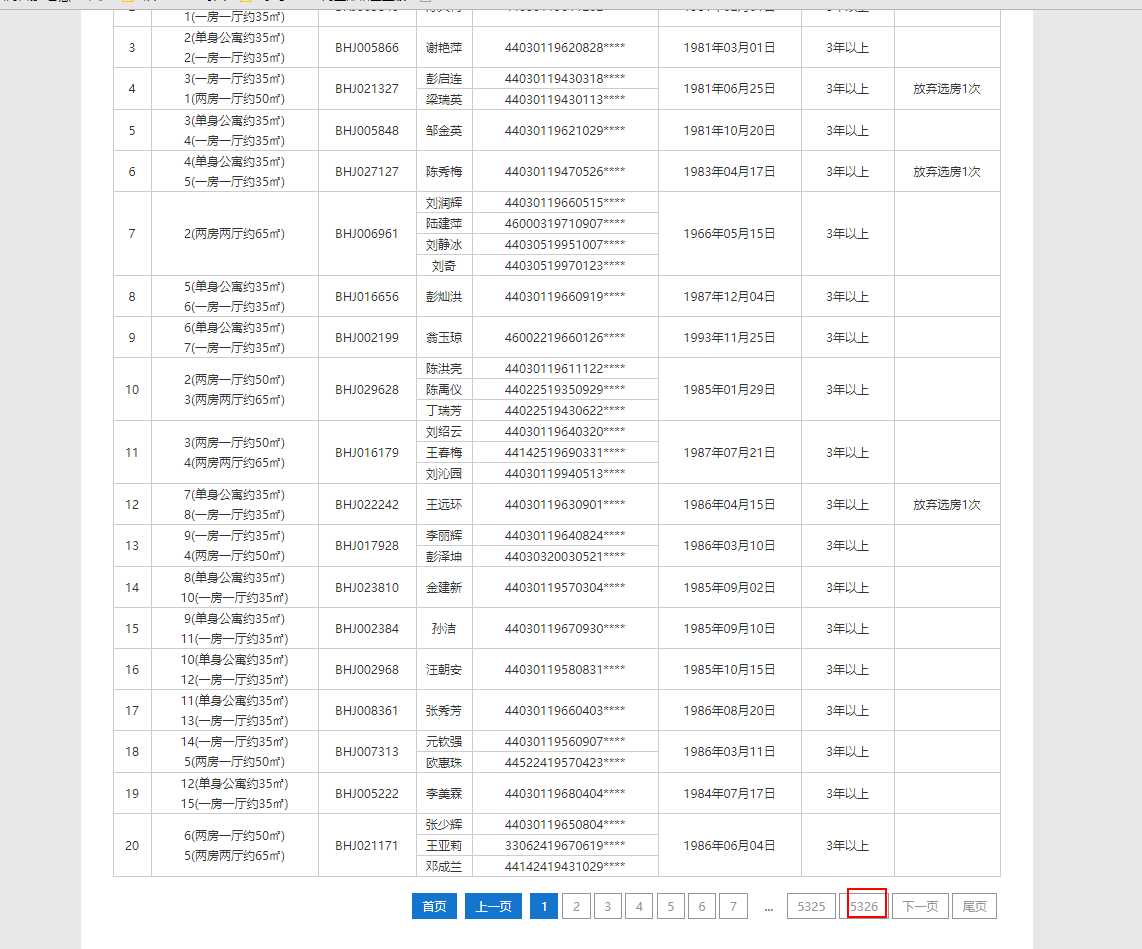
所以17年已更新妥妥的10W+
今天就拿这个作为爬虫的练手项目
1、环境准备:
操作系统:win10
python版本:python3.5.3
开发工具:sublime 3
python需要安装的库:
anaconda 没安装的可以去https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/这里下载,国内镜像比较快;
Requests urllib的升级版本打包了全部功能并简化了使用方法(点我查看官方文档)
beautifulsoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(点我查看官方文档)
LXML 一个HTML解析包 用于辅助beautifulsoup解析网页
Requests ,beautifulsoup ,LXML 模块安装方式:windows的命令提示符窗口输入以下代码即可
pip install requests pip install beautifulsoup4 pip install lxml
直接贴代码吧
import requests from bs4 import BeautifulSoup import os class Gongzufang(): #获取页面数据 def all_url(self,url): html = self.request(url) all_a = BeautifulSoup(html.text, ‘lxml‘).find(‘table‘, class_=‘sort-tab‘).find_all(‘tr‘) for a in all_a: title = a.get_text("|", strip=True) print(title) #self.save_data(url) #获取分页面地址 def html(self, url): html = self.request(url) max_span = BeautifulSoup(html.text, ‘lxml‘).find(‘div‘, class_=‘fix pagebox‘).find_all(‘a‘)[-3].get_text() for page in range(1, int(max_span) + 1): page_url = url + ‘/‘ + ‘0-‘+str(page)+‘-0-0-1‘ self.all_url(page_url) def save_data(self,data_url):#下载数据 pass #获取网页的response 然后返回 def request(self, url): headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240‘,‘Connection‘: ‘Keep-Alive‘,‘Referer‘:‘http://www.mzitu.com/tag/baoru/‘} content = requests.get(url, headers=headers) return content #实例化 Gongzufang = Gongzufang() #给函数all_url、html传入参数 你可以当作启动爬虫(就是入口) Gongzufang.html(‘http://anju.szhome.com/gzfpm‘) Gongzufang.all_url(‘http://anju.szhome.com/gzfpm‘)
结果如下:
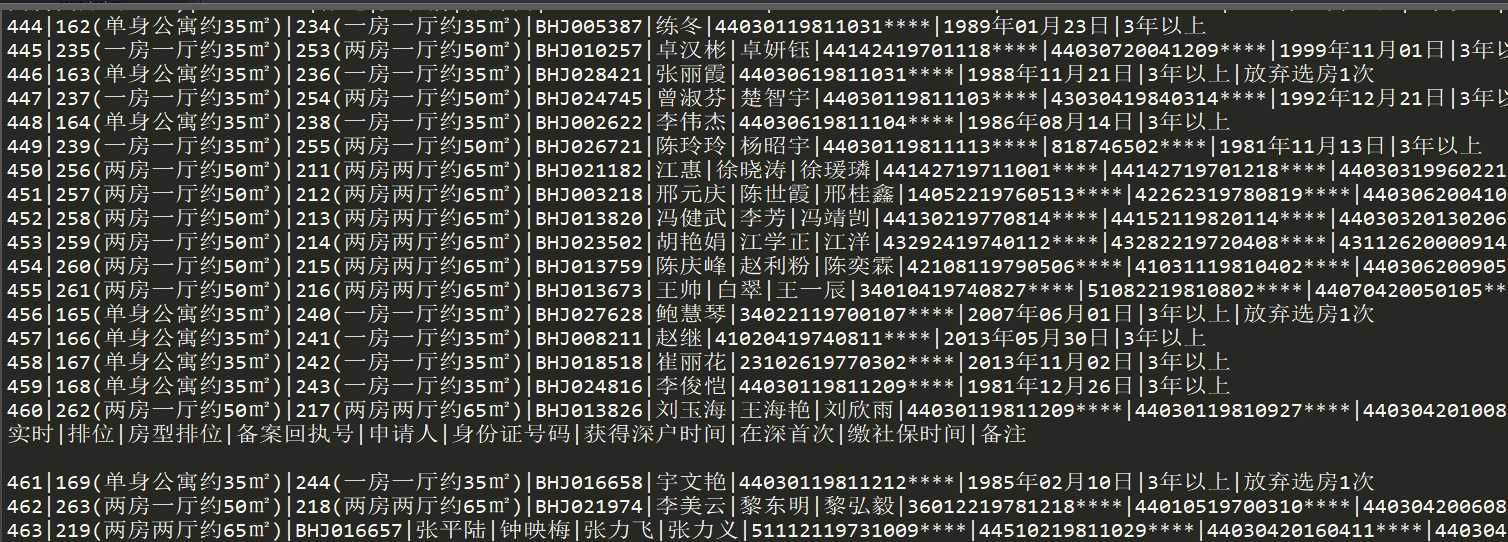
标签:image anaconda tar chrome referer nal start 代码 解析
原文地址:http://www.cnblogs.com/lza945/p/7434657.html