标签:性能 持久化 后台 md5 mapred content 取数 end return
原文地址:http://lixiangfeng.com/blog/article/content/7869717 转载请标明此处,谢谢!
缓存是什么?为什么要使用缓存?
缓存,通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。
缓存工具有哪些?区别在哪里?
缓存工具:Memecached、redis、MongoDB
区别:
a) memcache数据结构单一
b) redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数,
c) mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富;
a) redis在2.0版本后增加了自己的VM特性,突破物理内存的限制,可以对key value设置过期时间(类似memcache);
b) memcache可以修改最大可用内存,采用LRU算法;
c) mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起;
a) redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响;
b) memcache不支持,通常用在做缓存,提升性能;
c) MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性
a) Memcache 在并发场景下,用cas保证一致性;
b) redis事务支持比较弱,只能保证事务中的每个操作连续执行
c) mongoDB不支持事务
Memecached详解
Memecached、memecached和memecache的区别:
Memecached重点启动设置参数
e.g. /usr/bin/memcached -m 64 -p 11212 -u nobody -c 2048 -f 1.1 -I 1024 -d -l 10.211.55.9
Memecached内存分配策略
当第一次往memcached存储数据时, memcached会去申请1MB的内存(这1M的内存成为page) , 然后把该块内存分割为多个slab,如果可以存储这个数据的最佳的chunk大小为128B,那么memcached会把刚申请的slab以128B为单位进行分割成8192块. 当这页slab的所有chunk都被用完时,并且继续有数据需要存储在128B的chunk里面时,如果已经申请的内存小于最大可申请内存10MB 时,memcached继续去申请1M内存,继续以128B为单位进行分割再进行存储;如果已经无法继续申请内存,那么mamcached会先根据LRU 算法把队列里面最久没有被使用到的chunk进行释放后,再将该chunk用于存储.
Page为内存分配的最小单位
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配
Slabs划分数据空间
Memecached存储数据时不是直接将数据存储到page中,而是预先划分为一系列的slab,每个slab至负责存储大于上一个slab同时又小于或等于其本身大小的数据,如slab2只负责存储105~136 byte之间大小的数据,每个slab大小是不一样的,默认下一个slab的最大值为前一个的1.25倍(-f)
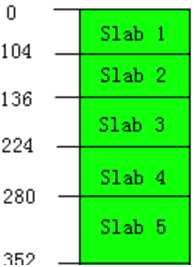
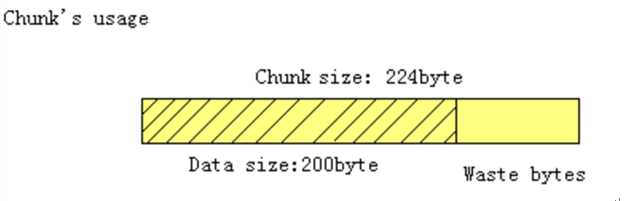
Chunk才是存放缓存数据的单位
Memecached将每个slab划分为一系列相等大小的存储空间,这个空间就叫做chuck。Chunk是Memecached的最小存储单元。同时,如果存储数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。例如下图,chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。
综合上面的介绍,memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。
这里有几个特点要注意:Memcached分配出去的page不会被回收或者重新分配Memcached申请的内存不会被释放slab空闲的chunk不会借给任何其他slab使用
Memecached的static命令详解
使用Telnet客户端连接Memecached后可以使用static命令
|
命令 |
含义说明 |
|
stats slabs |
显示各个slab的信息,包括chunk的大小、数目、使用情况等 |
|
stats items |
显示各个slab中item的数目和最老item的年龄(最后一次访问距离现在的秒数) |
|
stats detail [on|off|dump] |
设置或者显示详细操作记录; 参数为on,打开详细操作记录; 参数为off,关闭详细操作记录; 参数为dump,显示详细操作记录(每一个键值get、set、hit、del的次数) |
|
stats malloc |
打印内存分配信息 |
|
stats sizes |
打印缓存使用信息 |
|
stats reset |
重置统计信息 |
Memecached的分布式算法
当一台Memecached无法满足我们的需求时,我们需要配置多台Memecached服务器,这种用法就叫做Memecached的分布式,但是随之而来的问题是,假设我们有三台服务器A、B、C,需要存一个用户姓名,然后存在了服务器A上,那么当我们要取得时候如何得知我们之前存在哪里了呢?如何解决这个问题就成了Memecached分布式的重点。
通常而言我们有两种方式来实现:
a) 简介:假设我们有3台服务器,我们将存入Memecached中的key通过哈希算法得到一个整数,然后将这个整数与3取摸,那么不管这个整数是多少,结果必然是0,1,2中的一个,那么这样一来就可以解决这个问题。
b) 缺点:当我们服务器的数量发生变化时,依靠上述算法结果将会与未变化之前不同,导致原先我们存入的数据丢失无法获取到。
c) 代码示例:
<?php /** * 普通Hash分布 */ //Hash函数 functionmHash($key){ $md5 = substr(md5($key),0,8); $seed = 31; $hash = 0; for($i = 0;$i<8;$i++){ $hash = $hash * $seed + ord($md5{$i}); $i++; } return$hash&0x7FFFFFFF; } //假设有2台Memcached服务器 $servers = array( array(‘host‘ =>‘192.168.1.1‘,‘port‘ =>11211), array(‘host‘ =>‘192.168.1.1‘,‘port‘ =>11211) ); $key = ‘MyBlog‘; $value = ‘http://blog.phpha.com‘; $sc = $servers[mHash($key) % 2]; $memcached = newMemcached($sc); $memcached->set($key,$value); ?>
a) 将一个32位整数[0 ~ (2^32-1)]想象成一个环,0 作为开头,(2^32-1) 作为结尾,当然这只是想象。
b) 通过Hash函数把KEY处理成整数。这样就可以在环上找到一个位置与之对应。
c) 把Memcached服务器群映射到环上,使用Hash函数处理服务器对应的IP地址即可。
d) 把数据映射到Memcached服务器上。查找一个KEY对应的Memcached服务器位置的方法如下:从当前KEY的位置,沿着圆环顺时针方向出发,查找位置离得最近的一台Memcached服务器,并将KEY对应的数据保存在此服务器上。
e) 代码示例:
<?php /** * 一致性Hash分布 */ classFlexiHash{ //服务器列表 private$serverList = array(); //记录是否已经排序 private$isSorted = FALSE; //添加一台服务器 publicfunctionaddServer($server){ $hash = $this->mHash($server); if(!isset($this->serverList[$hash])){ $this->serverList[$hash] = $server; } //需要重新排序 $this->isSorted = FALSE; returnTRUE; } //移除一台服务器 publicfunctionremoveServer($server){ $hash = $this->mHash($server); if(isset($this->serverList[$hash])){ unset($this->serverList[$hash]); } //需要重新排序 $this->isSorted = FALSE; returnTRUE; } //在当前服务器列表查找合适的服务器 publicfunctionlookup($key){ $hash = $this->mHash($key); //先进行倒序排序操作 if(!$this->isSorted){ krsort($this->serverList,SORT_NUMERIC); $this->isSorted = TRUE; } //圆环上顺时针方向查找当前KEY紧邻的一台服务器 foreach($this->serverList as$pos =>$server){ if($hash>= $pos) return$server; } //没有找到则返回顺时针方向最后一台服务器 return$this->serverList[count($this->serverList) - 1]; } //Hash函数 privatefunctionmHash($key){ $md5 = substr(md5($key),0,8); $seed = 31; $hash = 0; for($i = 0;$i<8;$i++){ $hash = $hash * $seed + ord($md5{$i}); $i++; } return$hash&0x7FFFFFFF; } } ?>
说明:这样一来,当添加或移除某一台服务器时,受影响的数据范围变的更小了。
Memecached的用法
a) add用于添加一个要缓存的数据;
b) set用于设置一个指定key的内容,是add和replace的集合;
c) replace用户替换一个指定key的内容,如果key不存在则返回false;
|
方法 |
当key存在 |
当key不存在 |
|
add |
false |
true |
|
replace |
替换(true) |
false |
|
set |
替换(true) |
true |
a) increment,将元素的值+1,如果元素的值不是数字则按0处理;
b) decrement,将元素的值-1,如果元素的值不是数组则按0处理;
c) 可以通过increment和decrement实现Memecached的队列;
a) append 向元素后面追加内容;
b) prepend 向元素前面追加内容;
Memecached缓存原理及基本操作、分布式(一致性hash)
标签:性能 持久化 后台 md5 mapred content 取数 end return
原文地址:http://www.cnblogs.com/DxinSir/p/7436667.html