标签:不同的 数据挖掘 能力 pts 聚类算法 本质 clu 一个 分享
一。基于密度的聚类算法简介
DBSCAN是数据挖掘中最经典基于密度的聚类算法。
基于密度的聚类算法的核心是,通过某个点r邻域内样本点的数量来衡量该点所在空间的密度。和k-means算法的不同的是:
1.可以不需要事先指定cluster的个数。
2.可以找出不规则形状的cluster。
二。DBSCAN算法思想
该算法的参数是:r 和minPts
r:表示某点领域的阈值。
minPts:表示某点r邻域范围内样本点的数量。
核心点:若某点r邻域内样本点的数量不小于minPts,则该点就是核心点。
圆圈代表 r 邻域,红色点为核心点,B、C为边界点,而N为噪声点。
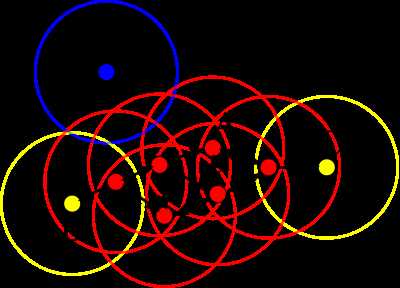
算法的本质是一个发现类簇并不断扩展类簇的过程。
对于任意一点q,若它是核心点,则在该点为中心,r为半径可以形成一个类簇c.
而扩展的方法就是,遍历类簇c内所有点,判断每个点是否是核心点,若是,则将该点的r邻域也划入类簇c.递归执行,直到不能太扩展类簇c.
假设 minPts 为3,r 为图中圆圈的半径,算法从A开始,经计算其为核心点,则将点A及其邻域内的所有点(共4个)归为类Q,接着尝试扩展类Q。查询可知类Q内所有的点均为核心点(红点),故皆具有扩展能力,点C也被划入类Q。在递归拓展的过程中,查询得知C不是核心点,类Q不能从点C处扩充,称C为边界点。边界点被定义为属于某一个类的非核心点。在若干次扩展以后类Q不能再扩张,此时形成的类为图中除N外的所有的点,点N则成为噪声点,即不属于任何一个类簇的点,等价的可以定义为从任何一个核心点出发都是密度不可达的。在上图中数据点只能聚成一个类,在实际使用中往往会有多个类,即在某一类扩展完成后另外选择一个未被归类的核心点形成一个新的类簇并扩展,算法结束的标志是所有的点都已被划入某一类或噪声,且所有的类都不可再扩展。
标签:不同的 数据挖掘 能力 pts 聚类算法 本质 clu 一个 分享
原文地址:http://www.cnblogs.com/lyr2015/p/7439586.html