标签:双向链表 删除 关注 子页面 http 表示 简单 nod 组成
我们已经知道B+树的组织结构及不同层之间是如何关联的了。
现在我们模拟一个B+树是如何从小到大,从无到有,从简到繁的过程。
首先我们来做一些假设:
1,每个页面包括内节点和叶子节点最多可以插入三条记录,插入第四条的时候,就会导致分裂。
2,插入的数据是键值对,但是我们只关注键,值可以不用关注,就简单的以data表示。
3,插入数据序列为:10,20,5,8,23,22,50,21,53,40,9
4,为了简明一些,key就是一些简单的int类型的数字
5,假设根节点的页面号是100
第一次插入过程。此时,索引中没有数据,所以B+树是一个空的根节点。
因为页面只能存储三个Key,首先将10,20,5插入进去,然后在页面内做数据库排序,索引三个key插入以后,B+树应该是下图的样子。

根据假设,跟页面已经插入满了,但是还有更多的数据需要插入,如果继续插入,则需要跟面叶分裂,分类过程如下:
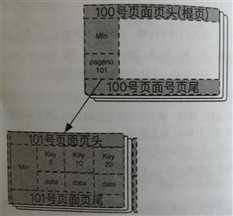
1,首先创建一个新的叶子节点,假设申请出来的额页面是101号。在分裂过程中,根节点始终是不会变得,不管变成多大的树,根节点的页面始终如一。
2,然后将根节点的全部记录复制到新的页面中,原根页面的最小记录指向新的叶子节点,同时将根页面的记录全部删除。
3,最后将根页面的min指针指向新的叶子节点101号页面。
这样变换以后,新的B+树结构入下图所示
此时,根节点的分类完成了,但是我们要插入的key--8还没有插入进去,所以还需要继续插入。
插入8 的时候,可以想到,通过定位直接回找到101号页面,在这个页面内插入时,发现还是没有空间,此时这样页面属于叶子节点,所以有涉及到了一次叶子节点的分裂。
步骤如下:
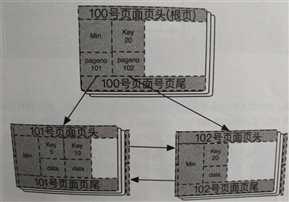
1,首先创建一个叶子节点,假设页面号未102
2,将101号上的一半的数据迁移到102号页面,这里可以假设每次迁移过去1条
3,101号页面和102号页面都是叶子节点,一般称为兄弟关系,他们需要组成双向链表。
4,将一半的数据迁移到102号页面之后,102号页面只有key为20的这1条记录。注意102号页面也是叶子节点,那么这个页面也需要和根节点挂上关系。需要做的就是将20这条记录的key取出来,
然后再加上一个指针信息,就是这里的102号页面,组成一条新的记录插入到根页面中,那么这条记录就算指向对应的儿子节点102号页面了。
这样,叶子节点分裂并重新调整之后的B+树,如下图所示:
分裂到现在为止,插入key(8)就非常简单了。
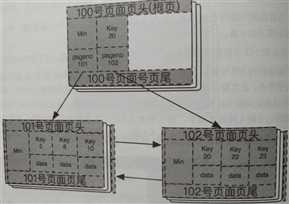
从跟页面开始搜索,因为8比20小,所以还是从min这个记录找对应的叶子节点,就找到了101号页面。然后在这个页面上做插入操作,这次已经满足插入条件了。
同样的方法,从根节点开始搜索,可以简单了插入key(23),key(22)这两行记录。此时的B+如下图所示:
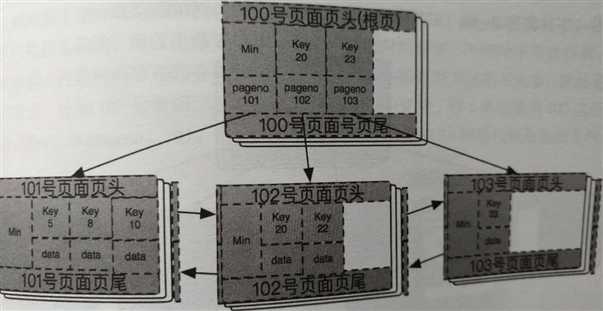
此时继续插入key(50)这行数据,因为它是大于20的,索引查到了102子页面,但是102页面已经满了,那就继续分裂吧。这个分类依然是叶子节点的分裂。
同样先申请一个叶子节点页面,设页面号是103号页面。然后将102号页面上的一半数据key(23)移动到103号页面,再讲103号页面和根页面产生父子关系。
这样就产生了一个新的叶子节点103号页面。103号页面也是102号页面的兄弟节点,需要用双向链表连接起来。
这样变换之后,新的B+树结构入下图:
分裂到此之后,用同样的方法,从根节点开始搜索,可以方便的插入key(50),key(21),key(53)三行数据。
那么继续插入key(40)的时候,因为它比key(23)大,所以应该插入到103号页面,,但103号页面已经满了,所以再次发生叶子节点的分裂。
假设这次申请到的页面是104号页面,分裂并插入key(40)之后的B+树如下图:
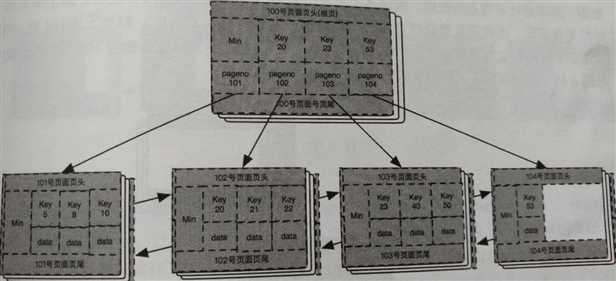
继续插入下一数据key(9)。在根页面中,因为key(9)比key(20)小,所以应该找到101号页面插入数据,但是该页面已经储存满了,需要再次页面分裂。
同样的创建一个新的叶子节点页面,设页面号是105。移动数据,使其成为101号页面的兄弟节点。
都做完之后,将105号页面上唯一的一个key(10)(从101号页面移动过来的一条)与根节点产生父子关系,创建一条新的索引记录(Key:10,Pageno:105),并且插入到根节点页面中。
此时发现跟页面已经满了,很明显需要做根页面的分裂了。
我们首先李看一下目前的B+树(其实不能称之为一个完整的B+树)如下图所示:
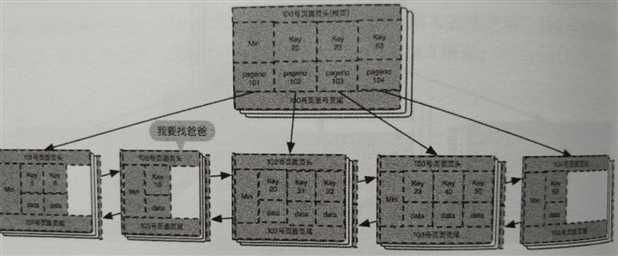
可以看到105号页面是没有父亲的,需要通过分裂为他找到一个父亲。
新申请的页面应该是内节点页面,因为要存储的是索引,而不是叶子页面的数据。假设这个页面是106号。
这里需要注意,由于根节点始终是跟节点,因此还是需要将根节点上的所有数据移动到106号页面上,相当于从101到105这5个页面的父节点变成106号了。而100号页面的最小节点也会指向106号页面。
此时的B+树已经是3层结构了,如下图所示:
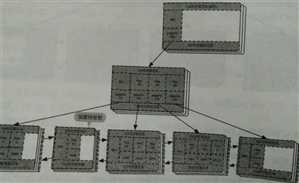
此时的105号节点,依然不能再父节点写入索引信息,因为106号依然是满了。那就继续分裂吧。
指示这次测分裂不是页面节点也不是根节点,而是内节点的分裂。
内节点的分裂和叶子节点的分裂方法差不多,依然是申请一个新节点,假设是107号页面,然后作为106号页面的兄弟页面,移动一条数据到107号页面之后,将索引记录(key:53,pageno:107)插入到根页面中。
此时,新的B+树结构如下图所示:
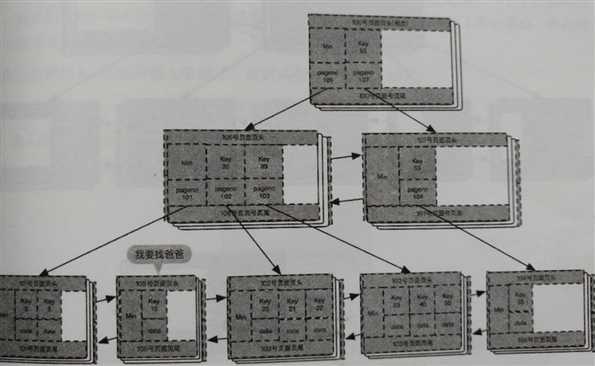
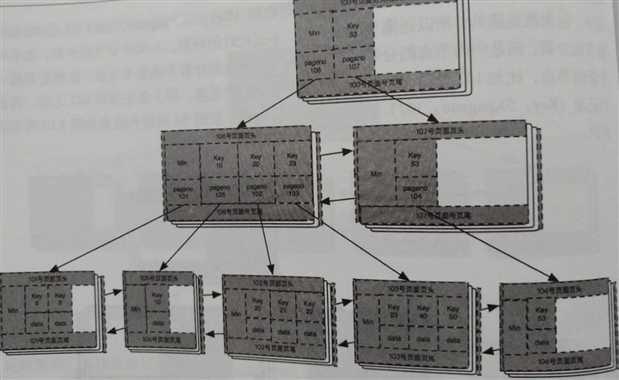
这时,继续在106号页面插入索引数据(key:10,pageno:105)。此时,经过两次分裂,
此时的106号页面包括key(10,20,23)三条记录了,分别指向105,102,103号页面。
终于105号也找到了自己的父节点,此时的B+树入下图所示:
等等,别忘了正事,我们的数据插入的任务还没有完成呢。
插入数据key(9)。从根开始搜索,依然会找到101号页面,此时可以直接把数据写到101号页面了。
将所有数据插入完成之后的完整的B+树入下图所示:
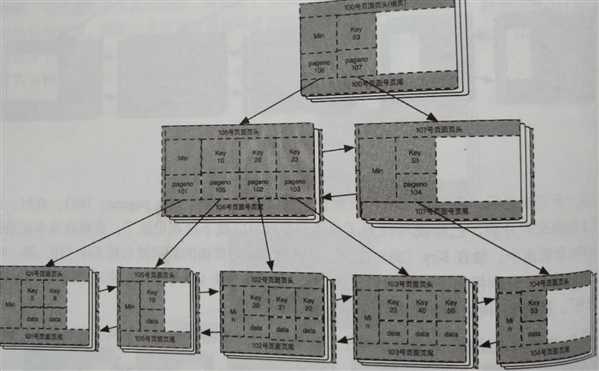
此时,我们回头看一下,要插入的数据的序列是:10,20,5,23,22,50,21,53,40,9。
此时可以看下最后这张图的叶子节点,从左到右把所有的记录都读取出来,序列为:5,8,9,10,20,21,22,23,40,50,53。
很明显的可以看到,相当于给原始序列做了一次排序,并且包含了全部数据。
若想要查询全表的话,在InnoDB内部,会直接定位到最左边的叶子节点上,然后从左到右将所有数据读取出来,而这也正式我们所介绍的B+树的特性。
标签:双向链表 删除 关注 子页面 http 表示 简单 nod 组成
原文地址:http://www.cnblogs.com/shizheyangde/p/7437231.html