标签:property strong tomcat page 获得 tomcat5.0 bytes 设置 asc
0 web.xml中注册的CharacterEncodingFilter
<!-- 配置字符集过滤器 --> <filter> <filter-name>encodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> </filter>
上面的配置相当于servlet中的 request.setCharacterEncoding("UTF-8")。
1 post请求
通过jquery.ajax的post请求,不进行request.setCharacterEncoding("UTF-8");也可以收到中文,我发现收到请求后直接request.getCharacterEncoding得到的已经是UTF-8了。查看Request头部发现含有charset=UTF-8。可能因为请求头里指定了编码方式,所以将按照这种方式编码。
而对于form表单的post请求,request.getCharacterEncoding得到的是null,所以需要进行request.setCharacterEncoding。
所以最好都设置上request.setCharacterEncoding("UTF-8");以应付不同的请求。
2 get请求
但是上面的设置方法是针对POST请求的,tomacat对GET和POST请求处理方式是不同的。在Tomcat5.0中,默认情况下使用ISO- 8859-1对URL提交的数据和表单中GET方式提交的数据进行重新编码(解码),而不使用request.getCharacterEncoding里的参数对URL提交的数据和表单中GET方式提交的数据进行重新编码(解码)。
要解决该问题(也可以在java后台中用getBytes转换),应该在Tomcat的配置文件server.xml的Connector标签中设置useBodyEncodingForURI或者 URIEncoding属性,其中useBodyEncodingForURI参数表示是否用request.setCharacterEncoding 参数对URL提交的数据和表单中GET方式提交的数据进行重新编码,在默认情况下,该参数为false(Tomcat4.0中该参数默认为true)。URIEncoding参数指定对所有GET方式请求(包括URL提交的数据和表单中GET方式提交的数据)进行统一的重新编码(解码)的编码。
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443" useBodyEncodingForURI="true"/>
URIEncoding和useBodyEncodingForURI区别是,URIEncoding是对所有GET方式的请求的数据进行统一的重新编码(解码),而useBodyEncodingForURI则是根据响应该请求的页面的request.setCharacterEncoding参数对数据进行的重新编码(解码),不同的页面可以有不同的重新编码(解码)的编码。所以对于URL提交的数据和表单中GET方式提交的数据,可以修改 URIEncoding参数为浏览器编码或者修改useBodyEncodingForURI为true(这个时候request.setCharacterEncoding为null),并且在获得数据的JSP页面中 request.setCharacterEncoding参数设置成浏览器编码。
3 编码顺序
对于发送数据,服务器按照response.setCharacterEncoding—contentType—pageEncoding的优先顺序,对要发送的数据进行编码。
1、pageEncoding="UTF-8"的作用是设置JSP编译成Servlet时使用的编码。
2、contentType="text/html;charset=UTF-8"的作用是指定对服务器响应进行重新编码的编码。
3、request.setCharacterEncoding("UTF-8")的作用是设置对客户端请求进行重新编码的编码。
4、response.setCharacterEncoding("UTF-8")的作用是指定对服务器响应进行重新编码的编码。同时,浏览器也是根据这个参数(附在http响应头中的charset)来对其接收到的数据进行重新编码(或者称为解码)。Html中meta也有个charset,这个是保存本地离线网页时起作用,因为这时没有方法头。
值得注意的是,jsp文件的编码方式:在JSP标准的语法中,如果 pageEncoding属性存在,那么JSP页面的字符编码方式就由pageEncoding决定,否则就由contentType属性中的 charset决定,如果charset也不存在,JSP页面的字符编码方式就采用默认的ISO-8859-1(在eclipse中可以自行配置文件的默认编码方式)。
4 其它
Java编译时,jvm按照系统默认(我们常用的运行环境一般为eclipse或者操作系统,eclipse的默认编码格式可以自己调整;中文操作系统默认使用GBK格式)或者按照指定的字符集(javac –encoding xxx)将源文件转化为unicode格式存储在内存中编译(Java内存中采用unicode编码,一个字符占两字节)。编译后字符数据会以UNICODE格式存入字节码文件中,生成class文件。
在运行过程中,JAVA也是采用UNICODE编码的,并且默认输入和输出的都是操作系统的默认编码。System.getProperty("file.encoding");查看系统默认编码。
在前端,我们可以用JS脚本来对参数编码:encodeURIComponent(),在JAVA端,可以用java.net.URLDecoder.decode来解码。不过这里要注意一个问题,就是TOMCAT会自动先对URL 做一次decode,我们可以在TOMCAT的UDecoder类中看到这一点。不过TOMCAT并非使用了URLDecoder.decode,而是自己编写了一个decode函数。网上有些文章上介绍过一种处理乱码的方法便是在JS中对参数做两次encodeURIComponent,在JAVA中做 一次decode,可以解决一些没有设置URIEncoding时发生的乱码问题。(解释如下图)

5 unicode和utf8
(1) ASCII码,8位,0到127(包括英文字母、标点等),128到255为扩展ASCII
(2) GBK:16位,一个汉字两个字节,一个英文一个字节
(3) Unicode(统一码),编码方案,为全世界每个字符设定唯一的编码。Unicode目前普遍采用的是UCS-2,它用两个字节来编码一个字符。Unicode也有UCS-4规范,就是用 4个字节来编码字符。
(4) utf8:UTF-8是一种unicode的实现方式,它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。,注意的是unicode一个中文字符占2个字节,而UTF-8一个中 文字符占3个字节)。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。如下图所示。
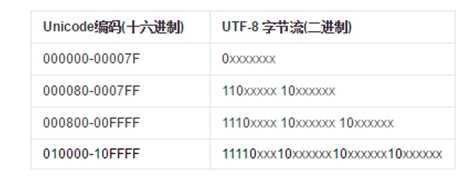
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89
标签:property strong tomcat page 获得 tomcat5.0 bytes 设置 asc
原文地址:http://www.cnblogs.com/liaohuiqiang/p/7440448.html