标签:style 报错 字符 span 2.7 版本 code gbk nic
HtmlTestRunner的乱码问题
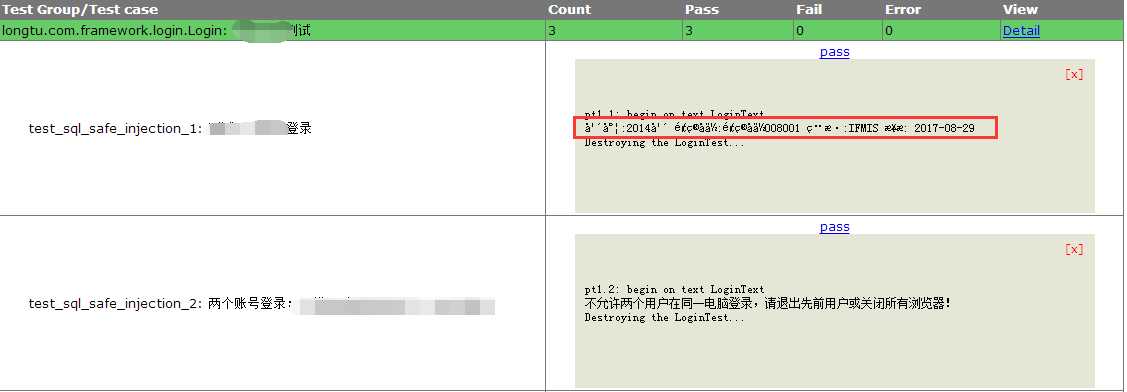
1生成的报告中,对print打印的数据都记录下来,但是数据有些会存在乱码。如下面。有些又没有乱码。
这到底是怎么回事呢?
str=t.encode(‘utf-8‘)
print str
第一个test我以utf-8编码,看来htmlTestRunner不是utf-8 编码。
为何第二个正确了呢?
第二个是unicode编码方式。
也就是说,可以被其他任何encode了。
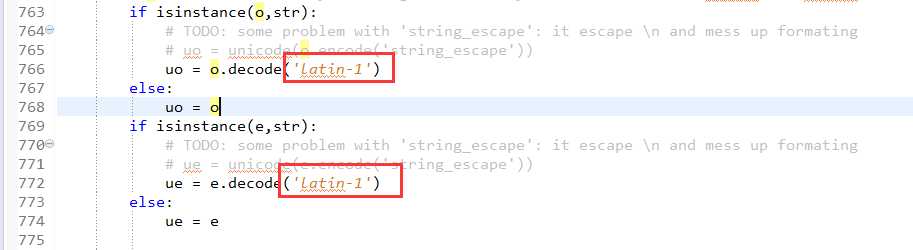
原码中已这个进行编码,也就是说他设置为latin-1这种编码方式了。估计是作者自己国家的一种编码方式。
修改为如下后,问题解决
说明,python2.7以下以上修改就可以,python3以上版本还需修改其他地方。我是从虫师书里进行修改再来研究这个问题的。
引申出来一个问题。string和unicode
string类型是字符串。会形成不同的编码集。
输入时为utf-8编码,输出时设置的编码集为utf-8。他就解码正常,会正确打印输入的内容。
如果输入时为utf-8。输出为gbk呢?就会乱码。
如何进行编码
#代码中设置编码格式
#coding:utf-8
# -*-coding=utf-8 -*-
如何解码
如果是后台日志,他会自动解码,如果是前台页面。或者数据库呢?
他们都设置了类似的编码格式。
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
所有不需要我们做什么,双方定义好了规则,他们自动的编码和解码了。
输入:print(‘你好‘)
前台就打印了你好。
如何解决乱码
如果定错了,就会出现乱码。这就是乱码的由来。就像上方所说:如果输入时为utf-8。输出为gbk呢?就会乱码。
这时候就是看问题出在哪方,把规则定义好。
上面只讲述了输入输出双方的自动编码和解码。可在python中提供一套编码和解码的方法(其他语言肯定也提供一套方法)。
这时候需要说说unicode。unicode是国际统一码,就如同标准时间一样。是唯一的。包含UTF-8/UTF-16/UTF-32.
utf-8属于unicode的一个小子集。不多扩展了,说多了自己也乱了。
# -*- coding=GB2312 -*-
print ‘string类型,默认为gbk编码‘,repr(‘你好‘)
print ‘unicode编码 ‘,repr(u‘你好‘)
string类型,默认为gbk编码 ‘\xc4\xe3\xba\xc3‘
unicode编码 u‘\u4f60\u597d‘
改变默认编码方式后。
# -*- coding=UTF-8 -*-
print ‘string类型,默认为UTF-8编码‘,repr(‘你好‘)
print ‘unicode编码 ‘,repr(u‘你好‘)
string类型,默认为UTF-8编码 ‘\xe4\xbd\xa0\xe5\xa5\xbd‘
unicode编码 u‘\u4f60\u597d‘
默认编码方法下,改变个别编码方式
#coding=utf-8
#print repr(‘你好‘.encode(‘gbk‘).decode())#以gbk解码【错误方法】报错
print repr(‘你好‘.decode()),‘ ||string类型变成unicode类型‘# 转换成了unicode方法
print repr(u‘你好‘.encode(‘gbk‘)),‘ ||unicode编码方式,再设置编码方式为gbk(gb2312)的string类型‘
print repr(‘你好‘.decode().encode(‘gbk‘)),‘ ||string类型变成unicode类型后 ,再设置编码方式为gbk(gb2312)的string类型‘#转化成gbk编码
u‘\u4f60\u597d‘ ||string类型变成unicode类型
‘\xc4\xe3\xba\xc3‘ ||unicode编码方式,再设置编码方式为gbk(gb2312)的string类型
‘\xc4\xe3\xba\xc3‘ ||string类型变成unicode类型后 ,再设置编码方式为gbk(gb2312)的string类型
乱码问题引申 python 中string和unicode
标签:style 报错 字符 span 2.7 版本 code gbk nic
原文地址:http://www.cnblogs.com/q2z2012/p/7449284.html