标签:nis nal 整理 分析 打开 操作模式 es2017 直接 注意
前言:
前面5篇博客主要对Python的相关基础知识和重点疑难问题进行了相关整理,本篇博客主要针对文件操作相关知识点来做一个系统性的梳理,以期帮助大家快速掌握文件操作的知识。
在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。
1.打开文件
要想操作文件,我们首先需要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件的绝对路径,读取文件的模式,以及文件的编码模式,如下:
file_obj = open(‘bigdata.txt‘,encoding=‘utf-8‘,mode=‘r‘)在默认情况下,文件的操作模式是只读,因此如果我们只想以只读的模式操作文件,通常这里
不用写操作模式。这样,我们就成功地打开了一个文件。
但是如果文件不存在,open()函数会抛出一个IOError的错误,一旦产生IOError的错误,后面的file_obj就不会执行。为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现
try:
file_obj = open(‘cisco.txt‘, ‘w‘, encoding=‘utf-8‘)
print(file_obj.read())
finally:
if file_obj:
file_obj.close()
但是如果经常这样做会很麻烦,因此我们可以使用with语句来自动帮我们调用close()方法:
with open(‘cisco.txt‘, ‘w‘, encoding=‘utf-8‘) as file_obj:
print(file_obj.read())
2.第二点我们来关注读取文件中的三个方法,read()方法,readline方法,readlines()方法,这三个方法是我们常见的也是必须要掌握的。梳理如下:
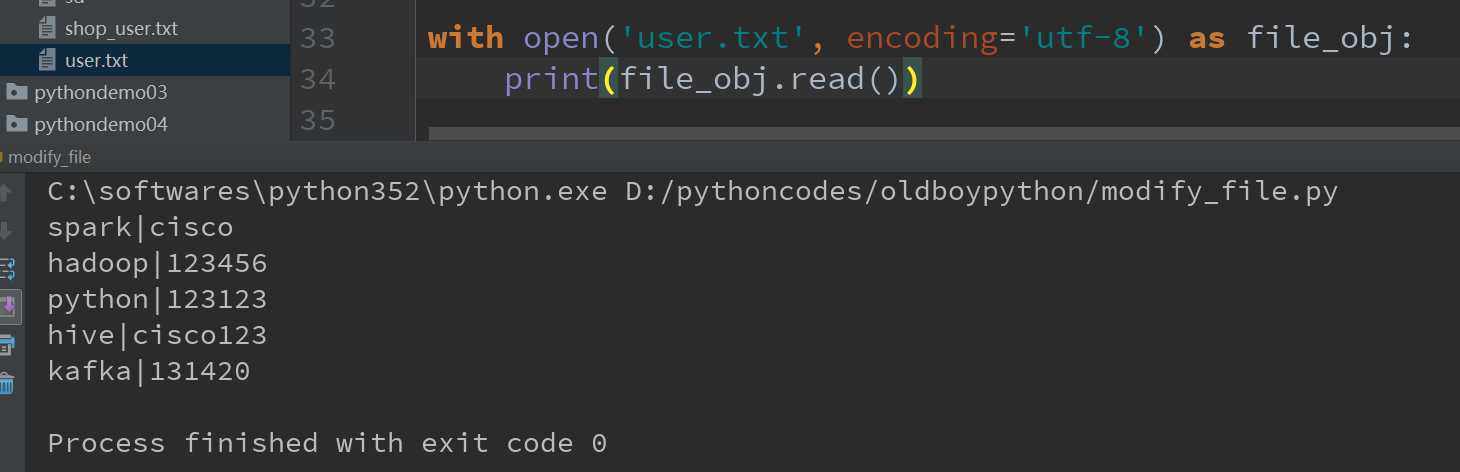
1.read方法;它会一次性读取文件的全部内容,文件的所有内容为字符串形式。如果文件有10G,内存就爆了,所以,为了保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。
在Pycharm中的一个文件user.txt内容如下:
spark|cisco
hadoop|123456
python|123123
hive|cisco123
kafka|131420
我们使用read()方法读取全部内容,如下图所示:
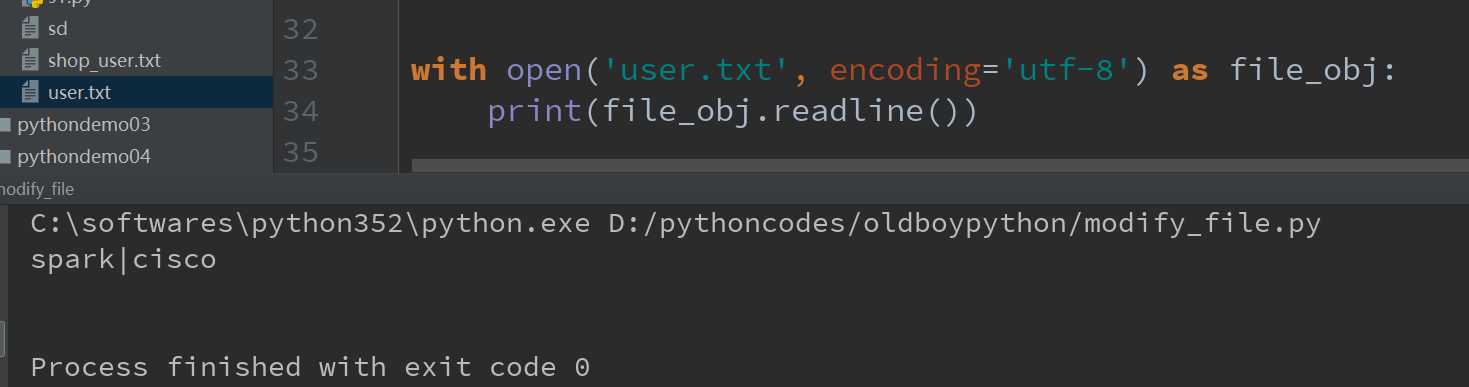
2.readline方法:该方法表示每次只读取一行内容到内存中,相比于read()方法,该方法更节省内存。注意该方法得到的仍然是字符串格式,但是得到的是文件中第一行数据的字符串形式,再次使用,则得到第二行数据的字符串格式,以此类推。
如图所示:
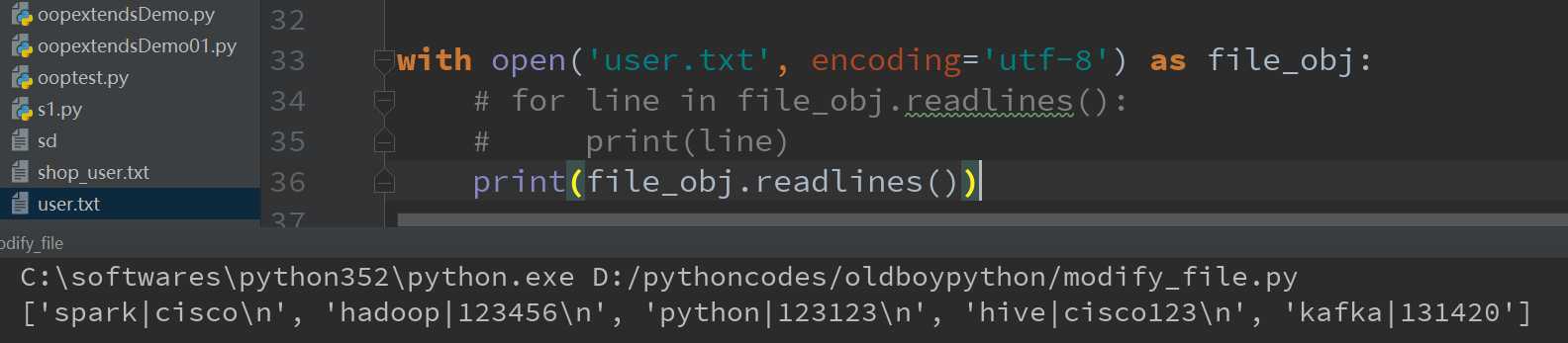
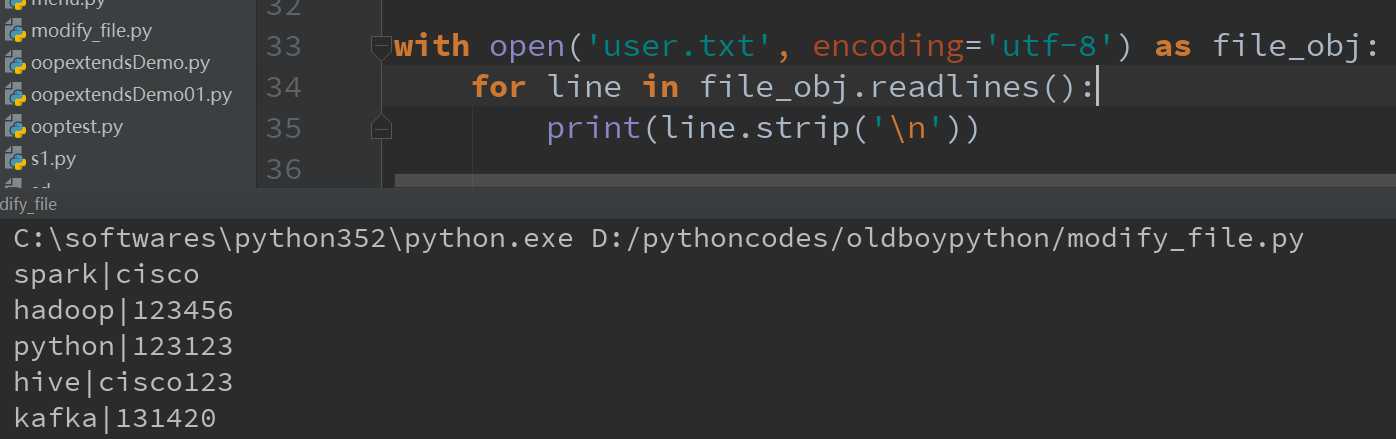
3.readlines()方法:该方法会一次性读取所有内容并按行返回list;注意和前面两个方法不同,该方法得到的是列表结构,列表的元素是字符串。列表中的每一个元素为文件中每一行数据的字符串格式。
注意上述方法均含有不可见字符——换行符:\n;我们可以打印看看,如图:
因此如果在使用上述方法时,一定要注意后面默认有一个不可见字符:\n。因此想按照原文user.txt中的内容原样输出,必须要使用strip()方法去掉‘\n‘,如图所示:
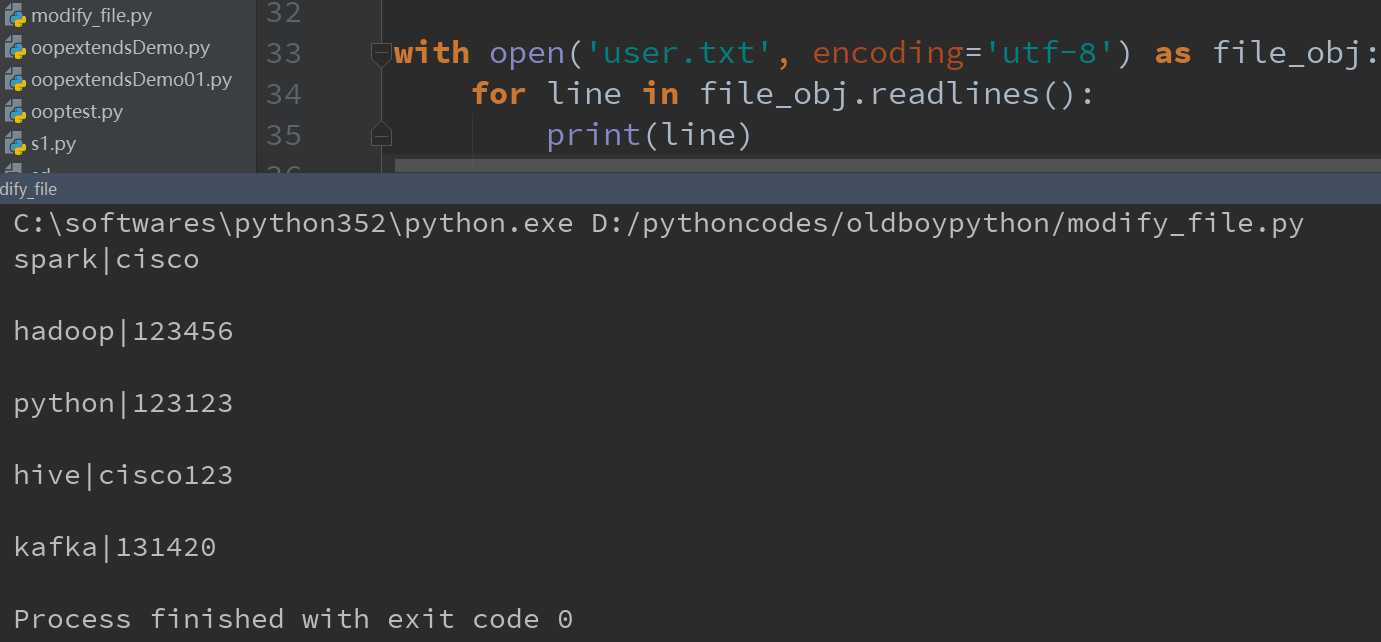
可以看到上面每行之间都有空格,不符合我们的输出需求,因此我们需要去掉空格,使用strip()方法,如图所示:
上面3个方法是我们经常使用的,下面我们通过一个题目来综合使用下这几个方法
需求:为user.txt中的每个用户名都添加后缀:_somebody。最终的输出结果为:
user.txt中的内容为:
spark|cisco|23
hadoop|123456|34
python|123123|333
hive|cisco123|12
kafka|131420|90
spark_somebody|22|male
hadoop_somebody|34|female
hive_somebody|111|female
import os
with open(‘user.txt‘, encoding=‘utf-8‘) as file_obj1, open(‘user1.txt‘, ‘w‘, encoding=‘utf-8‘) as file_obj2:
for line in file_obj1.readlines():
user_list = line.split(‘|‘)
user_list[0] = user_list[0] + "_somebody"
line = ‘|‘.join(user_list)
file_obj2.write(line)
os.remove(‘user.txt‘)
os.rename(‘user1.txt‘, ‘user.txt‘)
笔者自己在做这题的过程中遇到了很多坑,现整理如下:
【001】这里既然要对源文件做修改,因此这里涉及到写文件,因此我们需要打开一个文件user1.txt,并且设定文件的操作模式为只读,另外这里指定模式时,模式的指定和编码的顺序不能颠倒,否则会报错;
【002】本题涉及到操作两个文件 ,因此需要使用with关键字来打开文件,两个同时写时,需要使用如下的形式:
with open(‘user.txt‘, encoding=‘utf-8‘) as file_obj1, open(‘user1.txt‘, ‘w‘, encoding=‘utf-8‘) as file_obj2:
【003】这边我们是每修改一行就往新文件中写入一行,在开始对每行用户字符串进行切分时,使用了line.strip(‘\n‘).split(‘|‘),但是当我们在修改完用户名后往user2.txt中写入文件时,发现所有的用户信息字符串都在一行了,最后通过分析发现原来是在写入字符串时,没有加入换行符:‘\n‘。所以会导致这样的结果。为了避免这样的错误,修改如下:line = ‘|‘.join(user_list) + ‘\n‘
【004】另外要注意这里os模块的使用:os模块是用来和操作系统交互的模块,由于文件操作需要与操作系统交互,所以我们这里在删除文件和对文件重命名时,导入了os模块。这里的两个方法,remove()方法:删除一个文件,rename(老文件,新文件):为文件重命名。后期将针对os模块专门开设一篇博客进行梳理。
整理完读取文件的方法,下面继续梳理将内容写入文件的方法:write(),writeline(),writelines()方法。
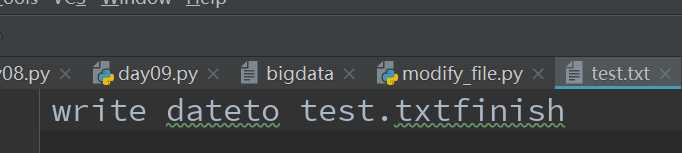
4.write()方法:往文件中写入内容,例如往文件test.txt中写入内容,如果test.txt文件不存在,则新建然后写入。如果存在,则首先会清空test.txt文件中的内容,然后写入内容。而writelines()方法是针对列表的操作,它接收一个字符串列表作为参数,将他们写入到文件中,换行符不会自动的加入,因此,需要显式的加入换行符。我们通过以下的实际案例来说明这2个方法的用法。
# 将列表msg中的内容写入文件test.txt中,如下:
with open(‘test.txt‘, mode=‘w‘, encoding=‘utf-8‘) as file_obj1:
msg = [‘write date‘, ‘to test.txt‘, ‘finish‘]
for item in msg:
file_obj1.write(item)
#文件运行完毕后的内容如下:
 、
、
由于这里并没有显示地给出换行符,所以最终文件中的内容为一行。
下面我们再来显示地给出换行符,然后观察test.txt文件中的变化,注意这里既然test,txt文件已经存在,所以再次写文件时会覆盖源文件中的内容;代码如下:
with open(‘test.txt‘, mode=‘w‘, encoding=‘utf-8‘) as file_obj1:
msg = [‘write spark\n‘, ‘to test.txt\n‘, ‘finish\n‘]
for item in msg:
file_obj1.write(item)
这里显示指定了换行符,因此文件中的内容为:
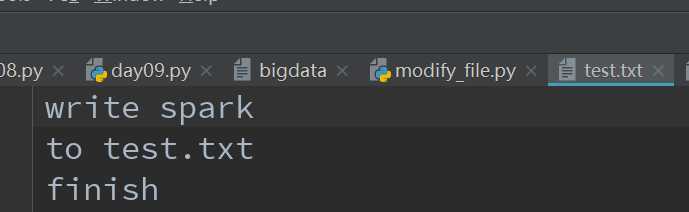
这是写文件要格外注意的点,默认是没有换行符的。
下面接着演示writelines()方法:
由于writelines()方法接受一个列表作为参数,因此它可以一次性将列表中的所有内容都写入文件中,所以这里我们就不必使用for循环遍历列表中的内容
然后再次写入了,一起来看看下面的代码:
with open(‘demo.txt‘, mode=‘w‘, encoding=‘utf-8‘) as file_obj1:
msg = [‘write hadoop\n‘, ‘to test.txt‘, ‘finish‘]
file_obj1.writelines(msg)
程序最终的打印结果是:
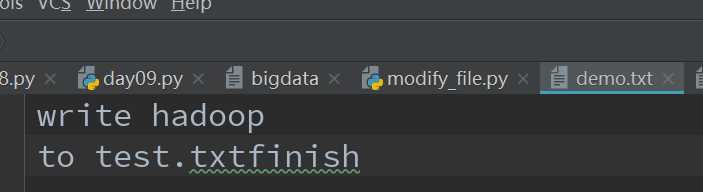
可以看到列表中的内容被全部写入到文件中。
5.我们接着来梳理Python文件中文件读取模式的权限,这个是笔者经常忘记的事情,所以在这里笔者进行一个统一的梳理,以期解决大家的疑问。
【001】r:只读模式(默认情况),如果文件不存在会报错
【002】w:只写模式,如果文件不存在,则创建;如果文件存在,则覆盖掉原有文件中的内容
【003】a:追加模式,不可读,只能写。如果文件存在,则从底部添加内容,如果文件不存在,则创建。我们一起来看看下面的例子:
原始文件demo.txt中文件的内容为:
北京欢迎您,我喜欢大数据这份工作
早上好
您好
how are you?
使用a模式然后来读取文件发现报错:
with open(‘demo2.txt‘, mode=‘a‘, encoding=‘utf-8‘) as file_obj1:
print(file_obj1.read())
#打印结果为:io.UnsupportedOperation: not readable
证明a模式不可读。
下面我们接着来验证a的追加模式,当文件存在时怎么样?代码和打印结果如下所示:
demo3文件存在,其文件内容为:
北京欢迎您,我喜欢大数据这份工作
早上好
您好
how are you?
with open(‘demo3.txt‘, mode=‘a‘, encoding=‘utf-8‘) as file_obj1:
msg = [‘write hadoop\n‘, ‘to test.txt‘, ‘finish‘]
file_obj1.writelines(msg)
程序运行结束后如图所示:
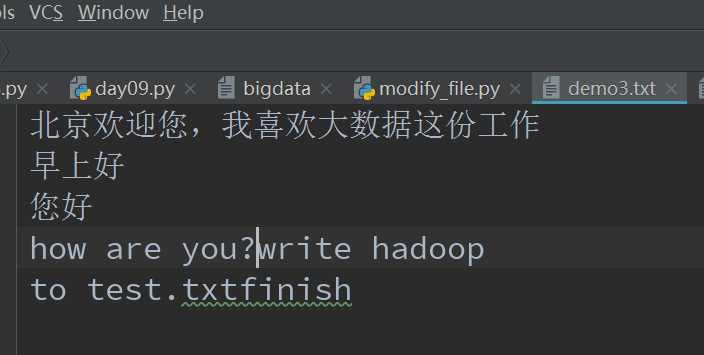
我们发现通过writelines()方法添加列表中的内容是往原始文件demo3.txt的末尾how are you?后面添加。至此就证明了a追加模式的权限。
【004】r+:可读,可写,可追加。如果文件不存在,它不会创建,如果文件存在,它会从原始文件的顶部开始写,并覆盖掉之前的内容。程序举例如下:
demo2.txt中文件内容如下,且该文件存在: 早上好 您好 how are you?
运行程序:
with open(‘demo2.txt‘, mode=‘r+‘, encoding=‘utf-8‘) as file_obj1:
file_obj1.write(‘北京‘)
运行后的结果如下:
北京好
您好
how are you?
结论:当文件存在时,使用r+操作文件,它会从原始文件的顶部开始写,并覆盖掉之前的内容。下面来验证当文件不存在时,会发生什么样的效果?
删除掉刚才的文件demo2.txt文件,然后运行如下程序观察会发生什么样的情况?
运行程序:
with open(‘demo2.txt‘, mode=‘r+‘, encoding=‘utf-8‘) as file_obj1:
li = [‘北京好‘, ‘您好‘, ‘how are you?‘]
file_obj1.writelines(li)
会报错:FileNotFoundError: [Errno 2] No such file or directory: ‘demo2.txt‘
证明r+不会创建一个不存在的文件。
【005】w+:先写再读;这个方法打开文件会清空原本文件中的所有内容,将新的内容写进去,之后也可读取已经写入的内容。如果文件不存在,则创建。继续验证:
原始存在文件demo3.txt,文件内容如下:
北京欢迎您,我喜欢大数据这份工作
早上好
您好
how are you?write hadoop
to test.txtfinish
hadoop|123456|5
hadoop|123456|9
程序如下:
with open(‘demo3.txt‘, ‘w+‘, encoding=‘utf-8‘) as file_obj:
li = ["cisco123", "sdwd", "spark is good"]
file_obj.writelines(li)
运行程序完毕后,结果为:
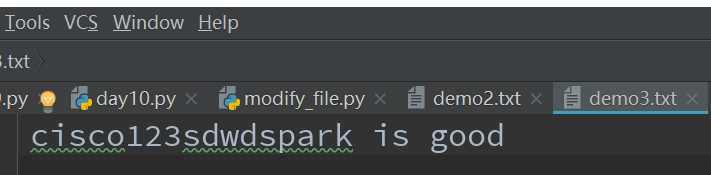
由此可知,w+首先是将源文件中存在的内容情况,然后再写入新的内容。
【006】a+:a+ 可读可写 从文件顶部读取内容 从文件底部添加内容 不存在则创建。a+的权限和a一样,在此不再通过程序验证。
6.下面我们接着来梳理文件操作中的两个重要方法seek和tell方法。
seek()方法用于移动文件读取指针到指定位置;tell()方法表示返回文件读取指针的位置。
seek()方法语法如下:
fileObject.seek(offset[, whence])
参数
offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
因此我们可以总结下seek方法的三种形式,如下:
(1)f.seek(p,0) 移动当文件第p个字节处,绝对位置
(2)f.seek(p,1) 移动到相对于当前位置之后的p个字节
(3)f.seek(p,2) 移动到相对文章尾之后的p个字节
=============================================================
关于文件操作相关的问题,这篇博客暂时总结到这里!后期我们将结合具体的需求来说明!大家主要需要掌握文件操作的六大权限。
标签:nis nal 整理 分析 打开 操作模式 es2017 直接 注意
原文地址:http://www.cnblogs.com/pyspark/p/7449861.html