标签:https 运算 http 情况 偏差 获取 正数 int 排除
To "transpose" a matrix, swap the rows and columns.
We put a "T" in the top right-hand corner to mean transpose:
![]()
The Inverse of A is A-1 only when:
A × A-1 = A-1 × A = I
Sometimes there is no Inverse at all.
m: 训练集的数量;
X: 输入的训练集
y:输出
(x(i), y(i)):第 i 个训练集
确定了 hθ(x) = θ0 + θ1x,那么如何选择 θ?
选择合适的 θ 使 hθ(x) 可以靠近 y 在我们的训练集数据中。hθ(x) 靠近 y 用数学形式表示为  。,在前面加上 1/m,表示平均值。再除以2,平均值的一半。所以最后变为
。,在前面加上 1/m,表示平均值。再除以2,平均值的一半。所以最后变为 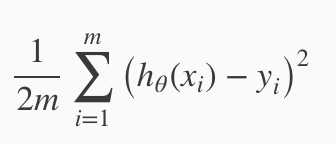 。理论上来说,1 / 2m 不影响函数的趋势。但是加上之后可以排除 m 的影响,获取数据偏差大小,便于比较、观察。
。理论上来说,1 / 2m 不影响函数的趋势。但是加上之后可以排除 m 的影响,获取数据偏差大小,便于比较、观察。
hθ(x) 是对 y 的预测。当 θ 固定时才存在。hθ(x) 为纵坐标,X 为横坐标。
J(θ) 是 cost function,计算不同 θ 情况下,预测与实际的偏离程度。J(θ) 为纵坐标,θ 为横坐标。
上一节提到,cost function 是随着 θ 变化的,所以要找到 cost function 的最小值,就要改变 θ。就由本函数来完成。
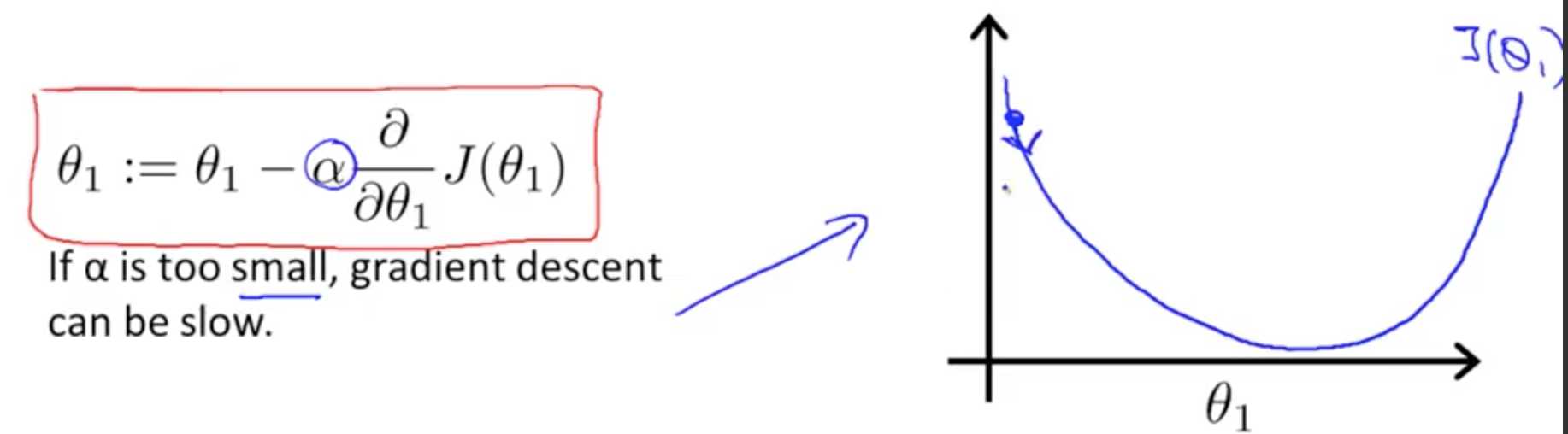
α 是学习速率。右图中学习速率 * 斜率是正数,可知 θ 是逐渐减小的。
梯度下降能够到达最低点,即使学习速率是固定的。由于越接近最低点,斜率越小。所以,不需要随着时间减小 α。
上节介绍了 Gradient Decent 的是什么,这里介绍其与 Linear Regression 的结合。
hθ(x) = θ0 + θ1x
对 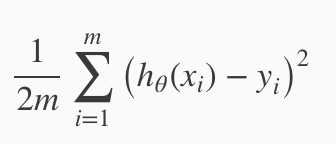 ,对 θ0 求导变为
,对 θ0 求导变为 ![]() ;
;
对 ,对 θ1 求导变为 ![]() (复合函数求导);
(复合函数求导);
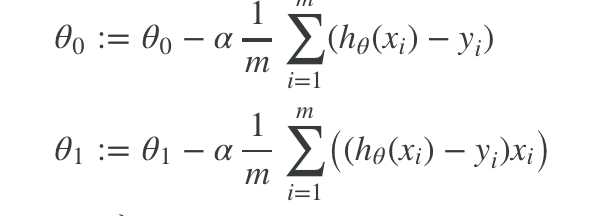
标签:https 运算 http 情况 偏差 获取 正数 int 排除
原文地址:http://www.cnblogs.com/jay54520/p/7305173.html