标签:pinning manage saving log event 重复 com 特定 into
集中的HDFS缓存管理,该机制可以让用户缓存特定的hdfs路径,这些块缓存在堆外内存中。namenode指导datanode完成这个工作。Centralized cache management in HDFS has many significant advantages.
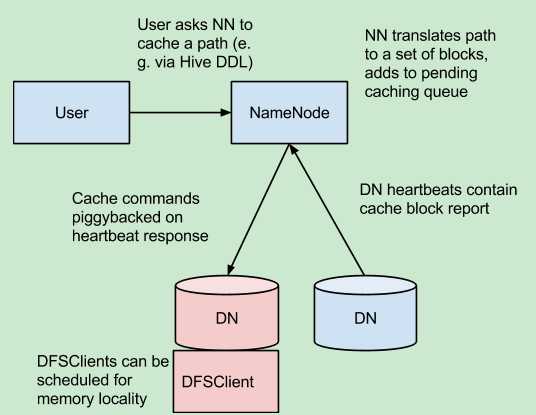
十一:Centralized Cache Management in HDFS 集中缓存管理
标签:pinning manage saving log event 重复 com 特定 into
原文地址:http://www.cnblogs.com/skyrim/p/7455607.html