标签:如何 apach pac less str curl 包含 查看 .com
写在前面的话:最近帮朋友弄弄微信商城,对于微信的基础开发,基本上就是各种post、get,有时是微信服务器向我们的服务器post、get数据,有时需要我们自己的服务器向微信服务器各种post、get,之间通过json或者xml传送数据。今天就来总结一下http相关的request和response,就从以下几个问题入手吧。
======正文开始========
1、什么是HTTP Request 与HTTP Response?
我们平时打开浏览器,输入网址,点击Enter按键,然后我们想要的网页就呈现在我们的面前,可是这个过程是怎么实现的呢?
简单来说是这样的:
(1)当我们按下Enter按键后,浏览器就会发送消息给该网址所在的服务器,这个过程叫做HTTP Request,Request故名思议,就是浏览器要向服务器发出请求。
(2)服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response,Response故名思议,就是服务器针对浏览器的请求Request,进行相应Response。
(3)浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示给我们。
上面的三个过程,其实就是两个程序之间的对话,或者叫做两个进程之间的对话,其中一个程序是浏览器,被称作客户端或者Client,用来发送Request;另一个程序是Web服务器,可以是apache等等,用来针对用户的Request,做出相应的Response,称为服务器端或者Server。
Client除了是浏览器,还可以是我们自己写的程序,这样我们就需要在程序里面通过自己写代码去完成上面操作:发送Request-->收到Response信息-->分析Response信息,进行处理。
这里需要注意一下:比如我们自己建立了一个网站,需要与第三方的网站服务器如微信服务器进行交互,如果是我们自己的网站向微信服务器发送Request,微信服务器返回Response信息,那么我们的网站就是客户端,而微信服务器是服务端;如果是微信服务器向我们的网站发送Resquest,而我们的服务器回复Response服务器,那么我们的网站就是服务器端,而微信服务器就是客户端。总之,就是两个进程之间的通信而已。
理解了上面的过程,接下来就又出现另外一个问题,Client与Server之间传送数据,对方如何能够识别彼此之间传送的信息呢?那么就需要彼此之间传送信息遵循一定的规范,这就是HTTP协议,因此叫做HTTP Request和HTTP Response。
HTTP协议的全称为Hyper Text Transfer Protocol,目前为止主要有三个版本:HTTP/0.9,HTTP/1.0,HTTP/1.1,详细内容就不说了,有兴趣的可以看看http协议的历史。这里我们需要关注的是,Client与Server端都遵循HTTP协议进行Request和Response,而我们如果想要对数据进行分析,有必要知道彼此之间通信的数据格式到底是什么样子的,请看下面一个问题。
2、HTTP Request 与HTTP Response数据格式?
(1)HTTP Request数据格式
主要由三部分组成:
1)HTTP Request Method,URI,Protocol Version
该部分位于HTTP Request的首行,包含HTTP Request Method,URI,Protocol Version三部分,例如“GET /test.html HTTP/1.1”,表示HTTP Request Method为GET方法,URI为/test.htlm,HTTP协议版本号为1.1。
2)HTTP Request Headers:
该部分为Request的头部信息,包含有编码信息,请求客户端类型等等信息。
3)HTTP Request Body:
该部分含有Request的主体信息,与HTTP Request Header之间隔开一行。
(2)HTTP Response数据格式
与HTTP Request数据格式类似,也包含三部分信息。
1)Protocol/Version,Status Code,Description
2)HTTP Response Headers
3)HTTP Response Body
可以使用Chrome浏览器按F12查看,也可以使用cUrl或wireshak查看,也可以自己编写程序获得各个信息去查看,再对HTTP Request和HTTP Response数据格式进行理解,印象会更深一些。
3、为什么我们需要Session?
客户端与服务器端通过HTTP Request和HTTP Response进行数据通信,根据HTTP Request和HTTP Response数据格式进行数据解析,但是还有一个问题,那就是HTTP是无状态协议( stateless protocol),也就是说每次客户端向服务器端Request,服务器端都会认为是一个新的Request,无法记录客户端的信息,这种情况就会导致很多问题,例如我们登陆进一个网站,如果我们需要访问别的页面,我们点击完链接后,服务器会认为是一个新的用户,如果该页面需要验证用户信息,那么客户端就需要重新输入登陆信息,导致很多的问题。
如何解决这个问题呢?就是通过Session。
服务器端对于访问的客户端,会生成该客户端的唯一信息,存储在Session中,Session位于服务器,可以保存在服务器的内存中,也可以保存在文件系统中,也可以保存在服务器的数据库中,对于Session的管理,也是值得琢磨的一件事情。
有了Session还不够,因为每次访问的客户端都是一次新的Request,因此需要在Request的信息中包含有客户端的信息,才能够与服务器端的Session进行对比,来确定是不是同一个客户端。所以需要Session Tracking,才能正确的辨识客户端。
4、如何进行Session Tracking?
Request的信息中包含有客户端的信息,主要有三种方式:
1)Cookies
存储在客户端,每一个cookie与一个唯一的SessionID关联,当客户端发送Request的时候,该信息会一块发过去,然后服务器端就能够根据Cookie的信息与Session的信息比对,来判断客户端的Request是否第一次请求;
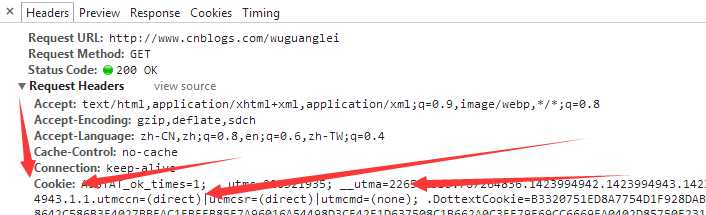
Cookie中会包含过期时间信息,如果Cookie过期,那么服务器端也会认为是第一次Request,进而需要用户登录;
Cookies中还能包含其他敏感信息,而且在客户端保存,因此可能会产生风险,想想也是,毕竟尝到了小甜头,自然要承受一定的风险;
为了避免Cookies产生的风险,许多浏览器可以禁止Cookie;
禁止Cookie后,有些网站就无法登录了,例如博客园,如果在浏览器中禁止Cookie,就无法登录了。
2)URL Rewriting
对于客户端禁用Cookie的情况,如果还想能够识别Request,那么就可以使用URL Rewriting的方法,在URL中会包含一段信息,这段信息能够与相应的Session唯一对应,这样当URL传到服务器端后就能够判断特定的Session了。通过URL Rewriting,无需在客户端保存有Cookies信息,与特定Session相关联的信息直接通过URL来回传输。
对于采用URL Rewriting方法的,如果我们保存一个网址为标签后,那么以后再打开标签的话,会提示Session过期,因为Session有一定的时间期限,过期后,服务器端就会删除相应的Session信息,以节省资源。
3)使用Hidden类型的Form标签
除了上面的两种方法,也可以通过 hidden类型的form标签,例如<input type="hidden".../>,这种方式有两个缺点:一是我们可以通过HTML源代码就能够看到一些信息,甚至是一些敏感信息;二是为了区分不同的用户,该方法只能够用在动态网页中,对于纯HTML的,就没有办法了。
谈一谈Http Request 与 Http Response
标签:如何 apach pac less str curl 包含 查看 .com
原文地址:http://www.cnblogs.com/dachengxiaomeng/p/7458210.html