标签:host 2.0 进一步 目的 when src 物理 区别 idt
双活方案对比:ASM vs V-PLEX
作者:王文杰
Oracle公司 Principle system analyst
Oracle高级服务部
Oracle数据库中心的灾备的演变,经历了多年的演变从最初的冷备份,到热备份,到存储复制,到DG,ADG,RAC one node, RAC,最终演变到了目前最炙手可热的双活双中心构架,也就是我们常说的远程RAC(Extended RAC)。
一般售前工程师口中实现双活的方案有很多种,但我认为真正RTO,RPO趋近于0,且双中心可用(读写)的方案,才能称为真正的双活双中心。复制软件不能算双活,DG/ADG也不是双活,备库不可写,切换时间长。真正比较成熟的双活案例为Oracle ASM host mirror(卷管理),存储虚拟化方案VPLEX(Oracle认证)和IBM SVC方案(Oracle认证),另外还有一些其它厂商的解决方案,例如HDS,HP,华为的解决方案。
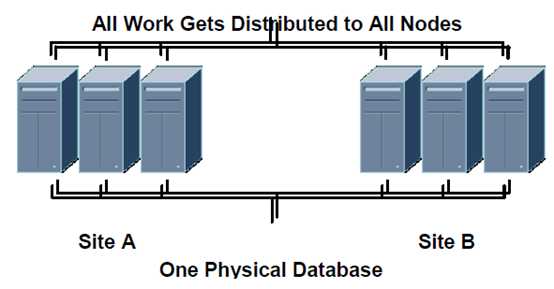
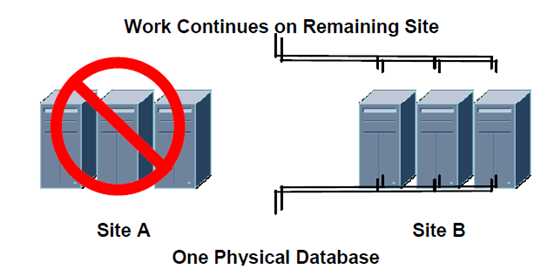
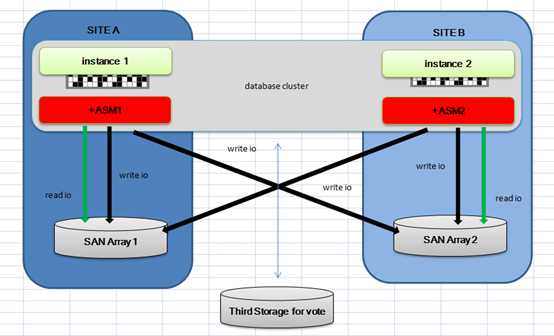
图片来源(extended RAC white paper)
本文作者最近3年参加过多次Vplex双活和ASM双活的数据库实施和运维,以实际经验来聊一聊对目前最主流的两种双活方案的看法。
首先谈一谈Extended RAC和普通RAC的主要区别。主要就是距离,距离是为了防止逐如自然灾害,恐怖袭击等对一个数据中心的损害后,另外一个数据库中心仍然可以提供服务。但距离会带来额外的网络和IO的延时,所以双活建设中对网络的建设特别重要。在Oracle的HA Best practice文档中提到:
■ 距离小于10公里可以使用普通高质量的网络。
■ 距离等于或超过10公里需要密集波分设备
和多路复用(DWDM)的设备。如果使用了DWDM或CWDM用这些,那应该使用专用交换机直接连接。
PS: DWDM(即密集波分复用)是当今光纤应用领域的首选技术,但其昂贵的价格令不少手头不够宽裕的运营商颇为踌躇。那么有没有或能以较低的成本享用波分复用技术呢?面对这一需求,CWDM(稀疏波分复用)便应运而生了。DWDM(即密集波分复用)与CWDM(稀疏波分复用)从字面上我们便可以大概看出两者的区别在于:密集和稀疏第二、CWDM调制激光采用非冷却激光,而DWDM采用的是冷却激光。冷却激光采用温度调谐。CWDM避开了温度调谐实难点因则大幅降低了成本,
CWDM成本只有DWDM1/3,CWDM很受欢迎
■ 距离10到50公里需要存储网络(SAN)缓存来抵消,由于距离对性能的影响。否则,性能退化会很明显。
■ 对于距离超过50公里,任何构架都需要经过严格的性能测试来证明它的性能是可接受的。实际任何距离的双活都需要做性能测试和压力测试。
国内双活近些年最常见的方案即为EMC的VPLEX的方案,和采用Oracle ASM host Mirror的双活。
下图为这两种方案的对比:
VPLEX
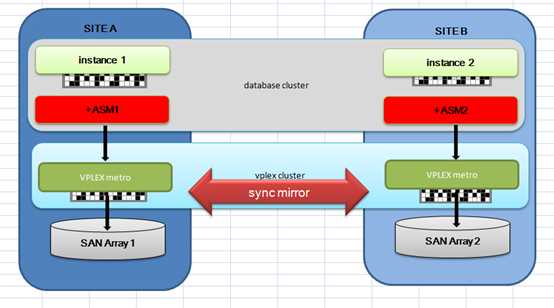
ASM
这两种方案作者参与最多为EMC的方案,一般从方案审核,installation,testing,go-live support,运维,优化,都有参与,ASM方案则更多是参加整体crosscheck,trouble shooting,优化调整等。下面,具体谈一谈对这两种方案的个人感悟。
VPLEX的最大优点在于VPLEX大大简化DBA的工作,不用配置failure group, path preference,第三方quorum磁盘。DBA可以不用参与管理存储,VPLEX处理了一切的细节,DBA不用看到磁盘,VPLEX工程师会处理好一切,从而减少了硬件故障导致数据库crash的风险。数据库从性能上讲,VPLEX所有的读都是本地读,不用额外进行设置。读可以受益于VPLEX的高速缓存。其实更重要的是,所有的IO的分发和复制,都是在VPLEX集群中进行管理,IO工作的workload从计算节点下移了存储集群层面。缓解了数据库节点的资源压力。
至于VPLEX的缺点,有两点是无须质疑的。第一厂商绑定,实际这个议题已经被弱化了很多,很大程度是CTO的风格有关系,第二价格,这个的确VPLEX一开始的价格是不便宜。很多人都想问,那么抛开VPLEX我们可不可以做到这一切。答案是可以。前提是你有足够的好构架师,存储管理员和DBA,在存储,网络,数据库的配置中,不要犯任何错误,做好构架设计,高可用测试,性能测试,压力测试(稳定性)等工作。简单来讲使用ASM mirroring,会面临以下的挑战
1)由于是ASM来管理IO的分发和复制,Host Mirroring会消耗一定的数据库节点上的资源。
2)存储管理员和DBA需要仔细的协作,配置好failure groups, path preferences,第三方quorum磁盘,并且需要长期保持警惕。一个错误的配置,都可能导致容灾失效,或者性能降级。
3) DBA需要介入打通大二层SAN链路的配置,进行完善的网络测试。重点关注远程网络带来的延时,心跳的质量。高可用测试,同样需要进行复杂的设计,确保涵盖各种故障场景,复杂度。
4)DBA需要涉及复杂的性能测试,稳定性测试和灾难测试,充分测试和理解这种构架下IO的性能情况。比如本地fail group和远程fail group的单读测试,双failgroup同时online的双活测试,及其对比情况,主要关注物理读和写测试(比如顺序读,散列读,直接路径读,直接路径写,并行写,控制文件读,日志文件写等等)。RAC cache fusion测试,最大流量下interconnect的质量,GC掉包率,GC CR/CURRENT块延时。国内很多客户选择ASM的原因,就是因为预算,往往采用老旧的硬件来实施,经常RAC集群中,节点配置不一样,比如服务器型号不同,CPU核数/频率存在差异等等,这样更需要测试来验证方案的健壮性。
5)上线后维护更复杂,对DBA要求更高。后期如果需要横向扩展,一样具有复杂性,需要同样的人力资源配置。
如果说ASM方案在的天然的优势,我想是ASM不需要通过SAN网络来同步数据(第三方存储集群软件仍然需要心跳,一般都部署在数据库节点上,例如veritas CVM),ASM的IO复制是从数据库节点发起。VPLEX则需要通过SAN心跳网络同步数据,如果SAN心跳网络断开,VPLEX一个site会shutdown,同时数据库会崩溃,主机会reboot。但如果是纯粹的某一边site的存储DISK损坏,无论是ASM和VPLEX,均不会影响所有数据库实例。在磁盘修复以后,会重新同步数据。ASM从11.2开始引入了fast resync option特性,可以快速恢复disk的同步。
我见过一个客户采用ASM方案,匆忙上线后,由于性能严重达不到预期。甚至在上线后,才开始考虑设置ASM_PREFERRED_READ_FAILURE_GROUPS这个最基本双活参数。最后不得不再次采购硬件,最后甚至整体替换到原有硬件。付出的代价也是惊人的。也有某些客户采用ASM双活的系统,负载实际是非常低的,远程节点常年是关闭的。
关于VPLEX另外的几个网络上提及的几个问题:
第一性能,双活的性能,主要关注什么:IO和心跳, 如果IO延时和心跳延时都性能良好,那么双活就成功了一大半。 某些厂商称VPLEX MTERO会额外增加IO延时,不建议采用,而这个测试据说通过dd得来的。我认为这个实在的来得太过草率,数据库的一个IO在双活构架的从发起到结束的生命周期远不是一个dd能够模拟。ASM层的IO分发也会有额外的开销,同时这部分开销是在计算节点,而VPLEX则是off loading到存储层。
VPLEX METRO的写操作的流程是,首先,该Director判断是哪个数据块需要修改,同时也通知在Metro-Plex中的其他Directors,这样在 cache中拥有这个块的local 和remote Director将更新各自的dictionary拷贝以示在其cache中的数据是过期的,然后将数据写入cache,最后写入到磁盘中,然后从两站点返回ACK消息给到发出写的那个Director,然后ACK被返回给到计算节点。
VPLEX METRO的读操作的流程是,主机将读请求发给在Metro-Plex中的Directors,本地Director会首先检查Local cache是否有该数据,若有即返回数据,若没有则从后端本地存储去读数据块。
EMC这一特性叫做:EMC VPLEX的分布式缓存一致性
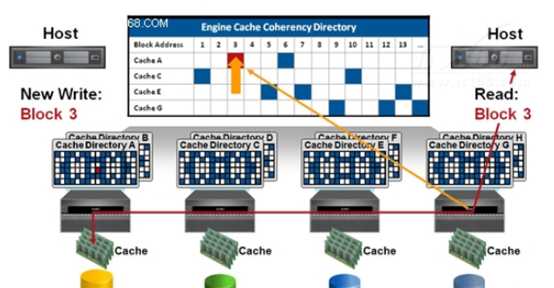
ASM的IO管理则比VPLEX要简单,因为ASM是只是一个卷管理软件。ASM早期在没有参数ASM_PREFERRED_READ_FAILURE_GROUPS能指定优先读取fail group前,读性能无疑是较大损耗,在设置了ASM_PREFERRED_READ_FAILURE_GROUPS参数后,ASM读IO也是走local(前提是要配置得当)。ASM的写IO则需要本地failgroup和远程failgroup都同时写成功,IO才认为完成。如果某一个failgroup的IO写失败,Oracle会再次寻找新的extent写入,如果再次失败,则会offline磁盘。
下面是一些主要双活的客户的性能采样情况:
某客户VPLEX双活,距离25公里,存储带闪盘,最近的IO情况。可以看出数据最主要的等待事件db file sequential read基本稳定维持在1ms左右。db file scatter read在1.2ms左右。log file sync在4.5ms左右。性能优异。该客户数据库节点1,日常情况下,平均每秒事务数为1500左右,每秒SQL执行为10000左右,每秒逻辑读为200万左右。账期事务数会提高3倍。Interconnect traffic bytes大约在97MB每秒,GC BLOCK LOST基本接近0,各GC指标均表现良好。这里的心跳流量其实很大了,我们在一般的RAC中都很少见GC bytes超过50MB,该客户的GC等待已经占到了db time的40%左右,但业务端仍然可以接受目前的性能情况。另外该客户上线前在数据库性能测试和压力测试都遇到过各种问题,不同多路软件的性能差异,网络不稳定导致GC掉包高,经过2个月左右的逐步调整后,到达了较好状态。
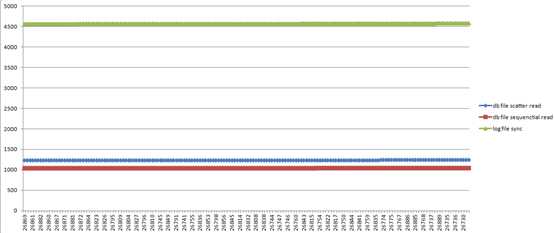
某客户VPLEX双活,4套库16节点,共用2个交换机,8根裸光纤,距离35公里,存储无闪盘。可以看出该客户的IO延时大部分时间处于Oracle推荐的正常延时区间,数据库最主要等待事件db file sequential read一直维持在5ms左右,该客户GC流量目前较少。其中有一个区间IO延时比较高是由于备份发起导致。每秒逻辑读在120万左右。该客户的构架,存在光纤共用,几个库之间互相可能造成影响,每天CRM备份发起后,4套裤的IO同时降级。在结算期,每秒事务数会到4000笔每秒(这里指的就是数据库的user commits),会对redo log造成巨大的压力,但log file sync的指标依旧维持在<5ms左右的良好水平。上线前,利用数据库专家测试软件OTest进行了完整的性能基准测试和最大压力测试,在测试中发现了数据库bug导致instance crash问题,网络不稳定掉包问题,逐一解决后,再上线确保了双活构架下数据库的性能和稳定。
该客户的心跳流量在40M每秒左右,同时有一些GC BLOCK LOST发生
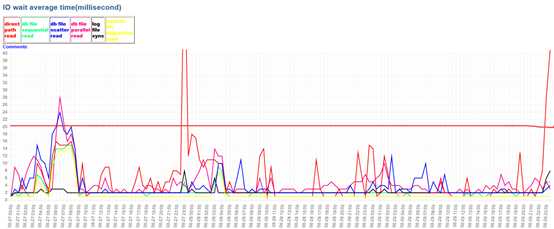
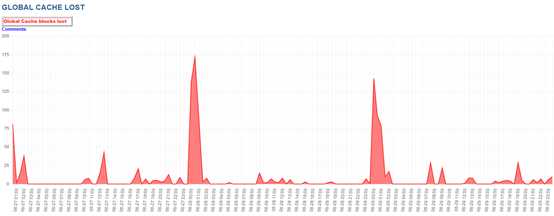
某客户的VPLEX双活的,带闪盘, 4节点RAC,主要业务在1节点, Estd Interconnect traffic大约5M每秒,较小。主要IO等待事件,性能良好。该客户实际3,4节点处于闲置状态。硬件冗余程度较高。
Avg
%Time Total Wait wait Waits % DB
Event Waits -outs Time (s) (ms) /txn time
-------------------------- ------------ ----- ---------- ------- -------- ------
log file sync 6,488,667 0 41,258 6 1.0 34.0
db file sequential read 11,293,347 0 15,307 1 1.7 12.6S
direct path read 65,267 0 1,336 20 0.0 1.1
Event Waits -outs Time (s) (ms) /txn time
-------------------------- ------------ ----- ---------- ------- -------- ------
db file sequential read 14,988,301 0 15,358 1 6.1 22.3
log file sync 1,660,630 0 4,488 3 0.7 6.5
db file scattered read 437,281 0 916 2 0.2 1.3
某客户的ASM的双活方案的性能情况,数据库为2节点RAC,两套存储在距离10公里的两个机房,第一阶段实施过程中由于节约成本,采用老的存储和链路,在上线前大量发生DISK超时,远程site的failgroup的磁盘被offline drop掉了大半,性能测试发现IO延时较高。这个阶段的问题,在上线前被逐一解决。上线后,数据库性能尚可接受,数据库最主要等待事件db file sequential read一直维持在10ms左右,但一旦遇到结算日,或者客户活动日,IO性能就降级到不可接受的程度,db file sequential read会降级到80ms左右。随后客户进行了大规模的优化,效果并不明显。最终客户换装了全套新存储(带闪盘)后,性能问题暂时得以解决。
另外一个早期客户的10g ASM extended RAC方案,I/O性能一般,为了减少由于cluster interconnect带来的延迟,远程节点始终处于关闭状态。存储双活,数据库cluster实际为单活。
总的来说,鉴于双活构架的复杂性,无论是VPLEX还是ASM的方案,都曾经遇到过各种问题。
第二集群斗争问题。VPLEX cluster和Oracle cluster一样,在发生cluster interconnect通讯故障后,会发生脑裂的驱逐。这种情况下,如果VPLEX cluster和Oracle cluster的 interconnect同时断开,则需要同步,才能避免整个集群不可用。Oracle的脑裂驱逐算法,简单来说为Oracle的脑裂算法简单来说是,保留拥有节点最多的子集群,如果节点数一样,则保留拥有instance number较小的子集群。注意:从12.1.0.2开始Oracle cluster引入了集群权重这一概念,进群权重高的子集群会存活。
a. The group with more cluster nodes
survive
b. The group with lower node member in case of same number of node(s) available
in each group
c. Some improvement has been made to ensure node(s) with lower load survive in
case the eviction is caused by high system load.
|
d. For 12c, node(s) with more weight will survive, see Note 1951726.1 12c: Which Node Will Survive when Split Brain Takes Place[This section is not visible to customers.] |
Vplex cluster的构架其实和RAC类似,也存在心跳网络和总裁机制,见下图
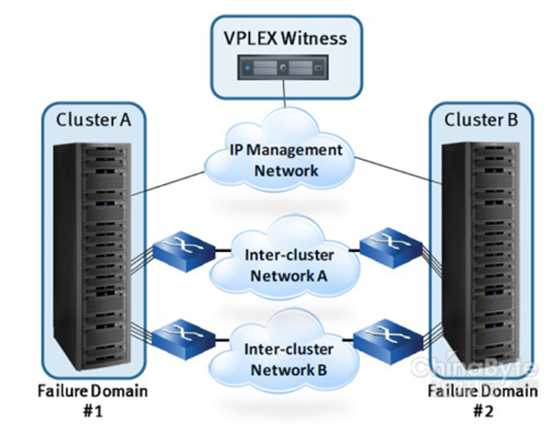
Witness就类型RAC的vote disk的功能。在VPLEX集群中,2个cluster中一个是preferred (优先的)另一个是non-preferred,假如集群之间的心跳连接完全中断了,Witness会通知preferred cluster继续服务,而non-preferred停止服务直至内联恢复,这一点,我从EMC工程师口中得到的说法,EMC也是保留节点号小的节点。这和11.2.0.4的Oracle的集群的行为基本一致。目前VPLEX的RAC一般都是2节点,或者4节点的,这样发生数据库心跳和存储心跳同时断开后,驱逐是一致的。在网络设计阶段,最好是SAN心跳和数据库心跳各自走不同的交换机和光纤,并有冗余机制。
简单来说,VPLEX不怕某个site storage system崩溃,数据库实例继续访问本地cache和remote storage system,也不怕某一个个site的崩溃(该site数据库同步崩溃),但另外一个site的storage system和数据库继续服务。
唯一有一定concern的就是storage和数据库心跳同时断开,这种小概率的风险理论上是的确存在的,如果集群节点多,心跳网络断开后形成了子集群多的恰好位于VPLEX的踢出site,Oracle版本>=12.1.0.2,配置有专门node weight,那么的确可能存在脑裂不一致的情况。
所以,第一双活建设中,对存储心跳网络的配置是非常重要的,以高可用性为第一考虑。第二这种驱逐场景,是必须包含在高可用测试中进行反复验证的,从而进一步减小风险。
第三锁定问题,这个问题是说VPLEX一个站点存储损坏后,另外一个站点会有短时间(5秒)的锁定,导致业务无法被顺利接管。这个问题其实很好理解, 任何集群在某一个站点崩溃后,为了维护事务的完整性,数据库的一致性,都会存在锁定的情况,包括Oracle集群:IMR instance membership recovery or reconfig ,一样会发生同样的锁定。这是现阶段集群构架不可避免出现的情况,但大多数集群在完成reconfig是可以继续提供服务的。该问题完全可以在测试阶段进行模拟,确保硬件资源,中间件,应用都可以承受短时间的锁定后,再完成接管。
很多人喜欢问Oracle原厂怎么推荐, 其实这个很难有固定的说法,第一原厂不太可能为你推荐非Oracle产品的细节。第二官方文档,对这个solution的解释简直是少之有少,只有短短的几页。早期版本的Oracle HA文档,推荐的是storage的mirror,在storage mirror不能实现的情况下才考虑ASM mirror, 到了11.2后,Oracle建议采用Host based mirror,采用ASM作为Cluster逻辑卷管理到了12.2,目前还没有HA Best practice文档公布。
如果要问我怎么推荐?VPLEX和ASM都是Oracle认证的解决方案。方案是死的,人才是项目成功关键。
一个典型双活项目的技术流程应该包括:





我推荐由Oracle ACS专家实施团队根据客户的实际情况来全程参与实施基于AMS mirror的双活和基于storage mirror的双活。这两种解决方案都需要比一般数据库中心实施,更规范和完善的数据库构架设计,安装,配置,高可用性测试,基准性能测试,极限压力测试和灾难测试,(推荐采用Oracle 测试,优化,实施最佳实践 :Otest进行数据库测试,http://www.dbfine.net/otest)很明显ASM方案需要更加专业的实施人员。西区原厂团队,是国内最有经验的双活Oracle实施团队之一。
参考资料:Oracle extended RAC white paper
EMC_VPLEX_Overview_and_General_Best_Practices
资深专家孙久江提供多地的双活方案参考
Oracle HA best practice文档
文章来源:http://www.dbfine.net/archives/480
2017-07-06
Oracle数据库中心双活之道:ASM vs VPLEX (转)
标签:host 2.0 进一步 目的 when src 物理 区别 idt
原文地址:http://www.cnblogs.com/wenjiewang/p/7460212.html