标签:*** public -- creat 解决方案 实体 tor _id 同步
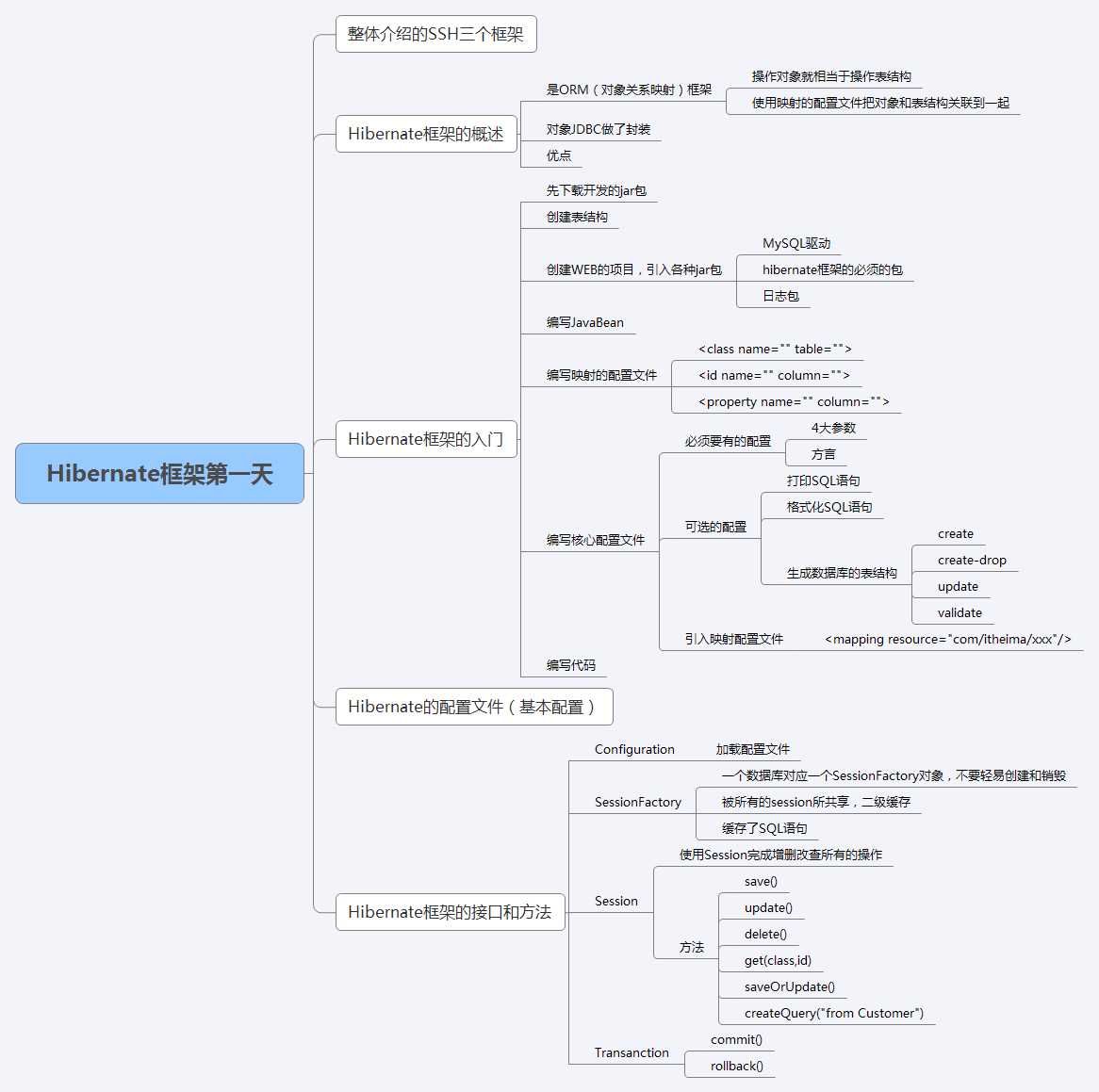
掌握清单
1.持久化类 (javabean+映射文件)
1.1配置文件标签
1.2主键生成策略
2.hibernate核心配置文件
3.hibernate核心组件
3.1 hibernate运行过程
4.持久化对象的状态转变
5.Session对象的一级缓存
6.Hibernate中的事务与并发
6.1事务相关的概念
6.2丢失更新的问题
7.绑定本地的Session
8.Hibernate框架的查询方式
8.1 Quert接口查询
8.2 Criteria接口查询
9.hibernate 关联映射
9.1 Hibernate的关联关系映射之一对多映射
9.2 Hibernate的关联关系映射之多对多映射
10.hibernate annotation注解方式来处理映射关系
11.hibernate思维导图
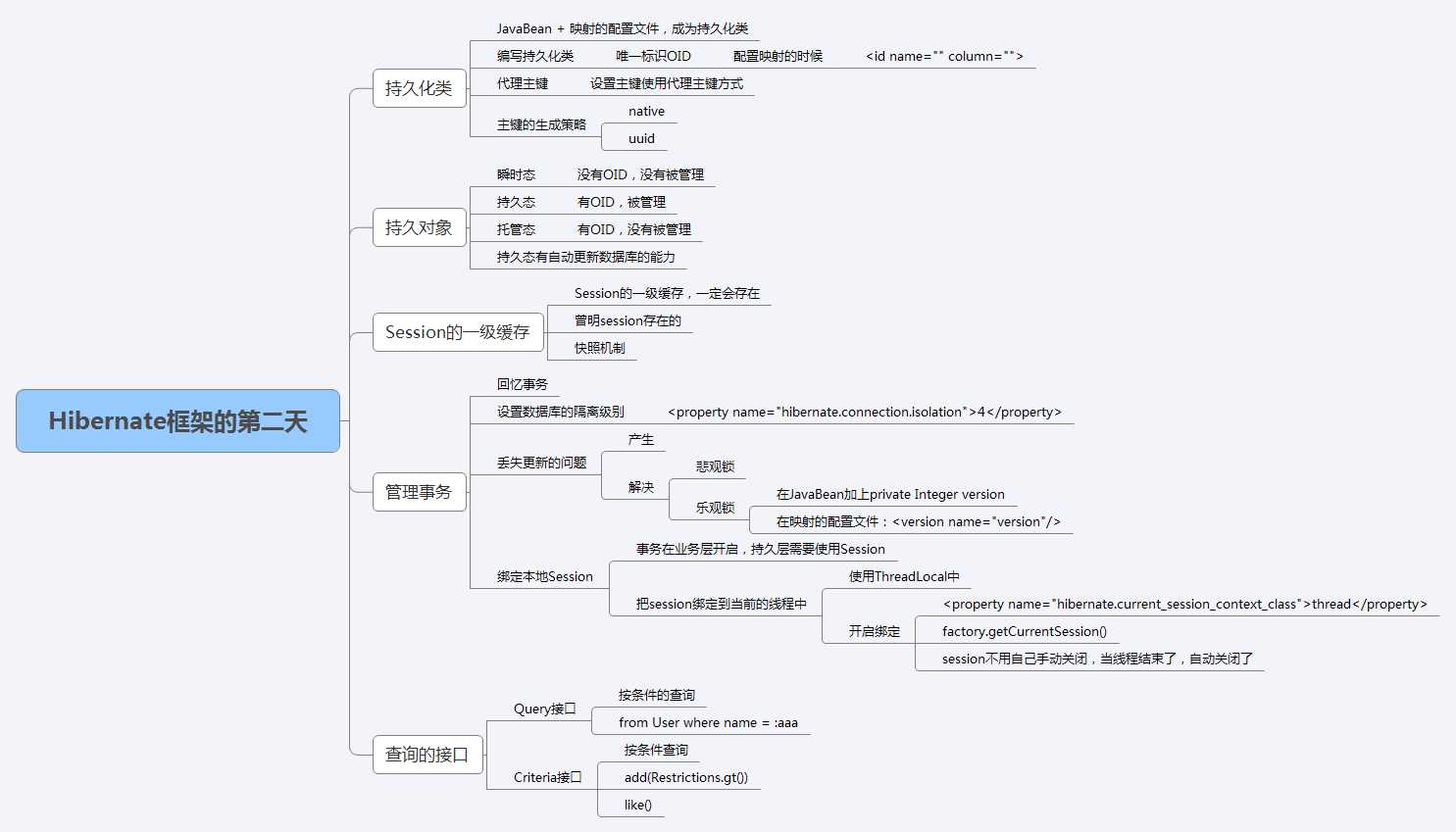
1.持久化类
javabean :无参构造方法、提供一个唯一标识属性、提供成员属性的get set方法 、实现Serializable接口
映射配置文件:xxx.hbm.xml
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
* <class>标签 -- 用来将类与数据库表建立映射关系
* name -- 类的全路径
* table -- 表名.(类名与表名一致,那么table属性也可以省略)
* catalog -- 数据库的名称,基本上都会省略不写
* <id>标签 -- 用来将类中的属性与表中的主键建立映射,id标签就是用来配置主键的。
* name -- 类中属性名
* column -- 表中的字段名.(如果类中的属性名与表中的字段名一致,那么column可以省略.)
* length -- 字段的程度,如果数据库已经创建好了,那么length可以不写。如果没有创建好,生成表结构时,length最好指定。
*generator --主键生成策略 native、UUID、identity、sequence、assigned、increment
* <property> -- 用来将类中的普通属性与表中的字段建立映射.
* name -- 类中属性名
* column -- 表中的字段名.(如果类中的属性名与表中的字段名一致,那么column可以省略.)
* length -- 数据长度
* type -- 数据类型(一般都不需要编写,如果写需要按着规则来编写)
* Hibernate的数据类型 type="string"
* Java的数据类型 type="java.lang.String"
* 数据库字段的数据类型 <column name="name" sql-type="varchar"/>
主键生成策略
identity:使用数据库的自动增长策略,不是所有数据库都支持,比如oracle就不支持。
sequence:在 DB2,PostgreSQL,Oracle,SAP DB,McKoi 中使用序列(sequence)在使用Oracle数据库时可以使用这一个。
native:根据底层数据库的能力选择 identity、sequence 中的一个。
assigned:手工指定主键值。
uuid:由Hibernate自动生成UUID并指定为主键值。
increment:适用于short,int,long作为主键.不是使用的数据库自动增长机制.
2.hibernate核心配置文件
* 必须有的配置
* 数据库连接信息:
hibernate.connection.driver_class -- 连接数据库驱动程序
hibernate.connection.url -- 连接数据库URL
hibernate.connection.username -- 数据库用户名
hibernate.connection.password -- 数据库密码
* 方言:
hibernate.dialect -- 操作数据库方言
* 可选的配置
* hibernate.show_sql -- 显示SQL
* hibernate.format_sql -- 格式化SQL
* hibernate.hbm2ddl.auto -- 通过映射转成DDL语句
* create -- 每次都会创建一个新的表.---测试的时候
* create-drop -- 每次都会创建一个新的表,当执行结束之后,将创建的这个表删除.---测试的时候
* update -- 如果有表,使用原来的表.没有表,创建一个新的表.同时更新表结构.
* validate -- 如果有表,使用原来的表.同时校验映射文件与表中字段是否一致如果不一致就会报错.
* 加载映射
* 如果XML方式:<mapping resource="cn/itcast/hibernate/domain/User.hbm.xml" />
3.hibernate核心组件
在基于MVC设计模式的JAVA
WEB应用中,Hibernate可以作为模型层/数据访问层。它通过配置文件(hibernate.properties或hibernate.cfg.xml)和映射文件(***.hbm.xml)把JAVA对象或PO(Persistent
Object,持久化对象)映射到数据库中的数据库,然后通过操作PO,对数据表中的数据进行增,删,改,查等操作。
除配置文件,映射文件和持久化类外,Hibernate的核心组件包括以下几部分:
a)Configuration类:用来读取Hibernate配置文件,并生成SessionFactory对象。
b)SessionFactory接口:产生Session实例工厂。
c)Session接口:用来操作PO。它有get(),load(),save(),update()和delete()等方法用来对PO进行加载,保存,更新及删除等操作。它是Hibernate的核心接口。
d)Query接口:用来对PO进行查询操。它可以从Session的createQuery()方法生成。
e)Transaction接口:用来管理Hibernate事务,它主要方法有commit()和rollback(),可以从Session的beginTrancation()方法生成。
Hibernate的运行过程
Hibernate的运行过程如下:
A:应用程序先调用Configration类,该类读取Hibernate的配置文件及映射文件中的信息,并用这些信息生成一个SessionFactpry对象。
B:然后从SessionFactory对象生成一个Session对象,并用Session对象生成Transaction对象;可通过Session对象的get(),load(),save(),update(),delete()和saveOrUpdate()等方法对PO进行加载,保存,更新,删除等操作;在查询的情况下,可通过Session对象生成一个Query对象,然后利用Query对象执行查询操作;如果没有异常,Transaction对象将
提交这些操作结果到数据库中。
4.持久化对象的状态转变
持久化对象可以是普通的Javabeans,惟一特殊的是它们与(仅一个)Session相关联。JavaBeans在Hibernate中存在三种状态:
1.瞬时态(transient):当一个JavaBean对象在内存中孤立存在,不与数据库中的数据有任何关联关系时,那么这个JavaBeans对象就称为临时对象(Transient Object)。
2.持久化状态(persistent):当一个JavaBean对象与一个Session相关联时,就变成持久化对象(Persistent Object)
3.脱管状态(detached):在这个Session被关闭的同时,这个对象也会脱离持久化状态,就变成脱管状态(Detached
Object),可以被应用程序的任何层自由使用,例如可以做与表示层打交道的数据舆对象(Data Transfer Object)。
**Hibernate持久化对象的状态的转换**
1). 瞬时态 -- 没有持久化标识OID, 没有被纳入到Session对象的管理
* 获得瞬时态的对象
* User user = new User()
* 瞬时态对象转换持久态
* save()/saveOrUpdate();
* 瞬时态对象转换成脱管态
* user.setId(1)
2). 持久态 -- 有持久化标识OID,已经被纳入到Session对象的管理
* 获得持久态的对象
* get()/load();
* 持久态转换成瞬时态对象
* delete(); --- 比较有争议的,进入特殊的状态(删除态:Hibernate中不建议使用的)
* 持久态对象转成脱管态对象
* session的close()/evict()/clear();
3). 脱管态 -- 有持久化标识OID,没有被纳入到Session对象的管理
* 获得托管态对象:不建议直接获得脱管态的对象.
* User user = new User();
* user.setId(1);
* 脱管态对象转换成持久态对象
* update();/saveOrUpdate()/lock();
* 脱管态对象转换成瞬时态对象
* user.setId(null);
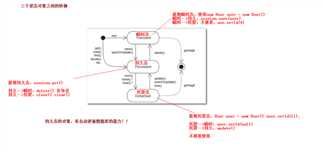
4). 注意:持久态对象有自动更新数据库的能力!!!
5.Session对象的一级缓存(重点)**
1. 什么是缓存?
* 其实就是一块内存空间,将数据源(数据库或者文件)中的数据存放到缓存中.再次获取的时候 ,直接从缓存中获取.可以提升程序的性能!
2. Hibernate框架提供了两种缓存
* 一级缓存 -- 自带的不可卸载的.一级缓存的生命周期与session一致.一级缓存称为session级别的缓存.
* 二级缓存 -- 默认没有开启,需要手动配置才可以使用的.二级缓存可以在多个session中共享数据,二级缓存称为是sessionFactory级别的缓存.
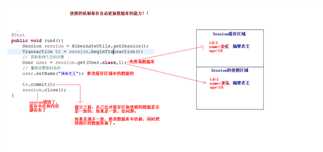
3. Session对象的缓存概述
* Session接口中,有一系列的java的集合,这些java集合构成了Session级别的缓存(一级缓存).将对象存入到一级缓存中,session没有结束生命周期,那么对象在session中存放着
* 内存中包含Session实例 --> Session的缓存(一些集合) --> 集合中包含的是缓存对象!
4. 证明一级缓存的存在,编写查询的代码即可证明
* 在同一个Session对象中两次查询,可以证明使用了缓存
5. Hibernate框架是如何做到数据发生变化时进行同步操作的呢?
* 使用get方法查询User对象
* 然后设置User对象的一个属性,注意:没有做update操作。发现,数据库中的记录也改变了。
* 利用快照机制来完成的(SnapShot)
6.Hibernate中的事务与并发
----------
6.1事务相关的概念
1. 什么是事务
* 事务就是逻辑上的一组操作,组成事务的各个执行单元,操作要么全都成功,要么全都失败.
* 转账的例子:冠希给美美转钱,扣钱,加钱。两个操作组成了一个事情!
2. 事务的特性
* 原子性 -- 事务不可分割.
* 一致性 -- 事务执行的前后数据的完整性保持一致.
* 隔离性 -- 一个事务执行的过程中,不应该受到其他的事务的干扰.
* 持久性 -- 事务一旦提交,数据就永久保持到数据库中.
3. 如果不考虑隔离性:引发一些读的问题
* 脏读 -- 一个事务读到了另一个事务未提交的数据.
* 不可重复读 -- 一个事务读到了另一个事务已经提交的update数据,导致多次查询结果不一致.
* 虚读 -- 一个事务读到了另一个事务已经提交的insert数据,导致多次查询结构不一致.
4. 通过设置数据库的隔离级别来解决上述读的问题
* 未提交读:以上的读的问题都有可能发生.
* 已提交读:避免脏读,但是不可重复读,虚读都有可能发生.
* 可重复读:避免脏读,不可重复读.但是虚读是有可能发生.
* 串行化:以上读的情况都可以避免.
5. 如果想在Hibernate的框架中来设置隔离级别,需要在hibernate.cfg.xml的配置文件中通过标签来配置
* 通过:hibernate.connection.isolation = 4 来配置
* 取值
* 1—Read uncommitted isolation
* 2—Read committed isolation
* 4—Repeatable read isolation
* 8—Serializable isolation
6.2丢失更新的问题
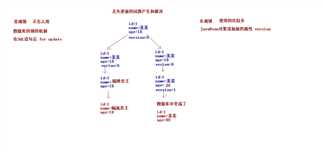
1. 如果不考虑隔离性,也会产生写入数据的问题,这一类的问题叫丢失更新的问题。
2. 例如:两个事务同时对某一条记录做修改,就会引发丢失更新的问题。
* A事务和B事务同时获取到一条数据,同时再做修改
* 如果A事务修改完成后,提交了事务
* B事务修改完成后,不管是提交还是回滚,如果不做处理,都会对数据产生影响
3. 解决方案有两种
* 悲观锁
* 采用的是数据库提供的一种锁机制,如果采用做了这种机制,在SQL语句的后面添加 for update 子句
* 当A事务在操作该条记录时,会把该条记录锁起来,其他事务是不能操作这条记录的。
* 只有当A事务提交后,锁释放了,其他事务才能操作该条记录
* 乐观锁
* 采用版本号的机制来解决的。会给表结构添加一个字段version=0,默认值是0
* 当A事务在操作完该条记录,提交事务时,会先检查版本号,如果发生版本号的值相同时,才可以提交事务。同时会更新版本号version=1.
* 当B事务操作完该条记录时,提交事务时,会先检查版本号,如果发现版本不同时,程序会出现错误。
4. 使用Hibernate框架解决丢失更新的问题
* 悲观锁
* 使用session.get(Customer.class, 1,LockMode.UPGRADE); 方法
* 乐观锁
* 1.在对应的JavaBean中添加一个属性,名称可以是任意的。例如:private Integer version; 提供get和set方法
* 2.在映射的配置文件中,提供<version name="version"/>标签即可。
----------
7.绑定本地的Session
1. 之前在讲JavaWEB的事务的时候,需要在业务层使用Connection来开启事务,
* 一种是通过参数的方式传递下去
* 另一种是把Connection绑定到ThreadLocal对象中
2. 现在的Hibernate框架中,使用session对象开启事务,所以需要来传递session对象,框架提供了ThreadLocal的方式
* 需要在hibernate.cfg.xml的配置文件中提供配置
* <property name="hibernate.current_session_context_class">thread</property>
* 重新HibernateUtil的工具类,使用SessionFactory的getCurrentSession()方法,获取当前的Session对象。并且该Session对象不用手动关闭,线程结束了,会自动关闭。
public static Session getCurrentSession(){
return factory.getCurrentSession();
}
* 注意:想使用getCurrentSession()方法,必须要先配置才能使用。
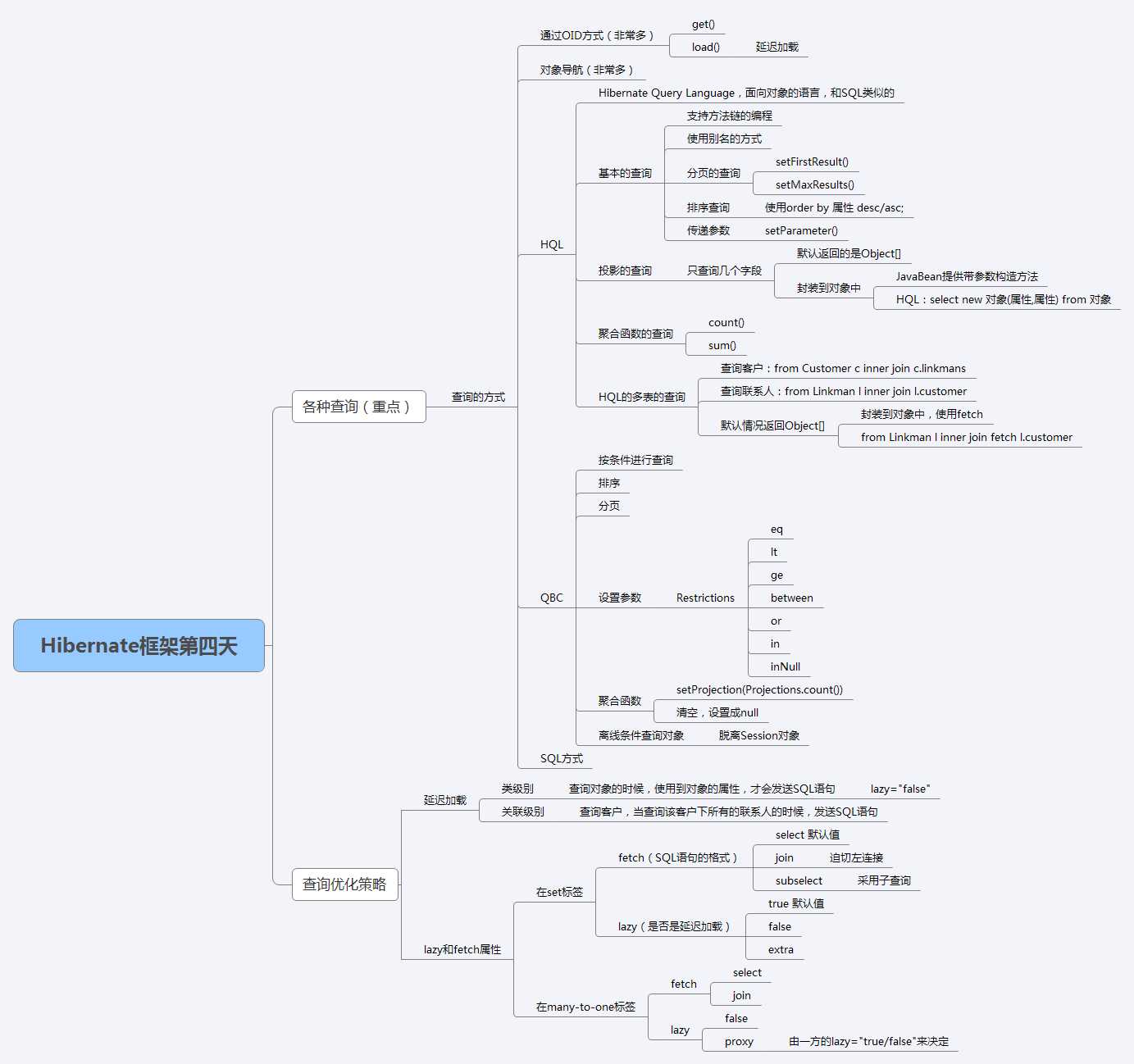
8.Hibernate框架的查询方式
Query查询接口
1. 具体的查询代码如下
// 1.查询所有记录
/*Query query = session.createQuery("from Customer");
List<Customer> list = query.list();
System.out.println(list);*/
// 2.条件查询:
/*Query query = session.createQuery("from Customer where name = ?");
query.setString(0, "李健");
List<Customer> list = query.list();
System.out.println(list);*/
// 3.条件查询:
/*Query query = session.createQuery("from Customer where name = :aaa and age = :bbb");
query.setString("aaa", "李健");
query.setInteger("bbb", 38);
List<Customer> list = query.list();
System.out.println(list);*/
Criteria查询接口(做条件查询非常合适)**
1. 具体的查询代码如下
// 1.查询所有记录
/*Criteria criteria = session.createCriteria(Customer.class);
List<Customer> list = criteria.list();
System.out.println(list);*/
// 2.条件查询
/*Criteria criteria = session.createCriteria(Customer.class);
criteria.add(Restrictions.eq("name", "李健"));
List<Customer> list = criteria.list();
System.out.println(list);*/
// 3.条件查询
/*Criteria criteria = session.createCriteria(Customer.class);
criteria.add(Restrictions.eq("name", "李健"));
criteria.add(Restrictions.eq("age", 38));
List<Customer> list = criteria.list();
System.out.println(list);*/
hibernate 关联映射
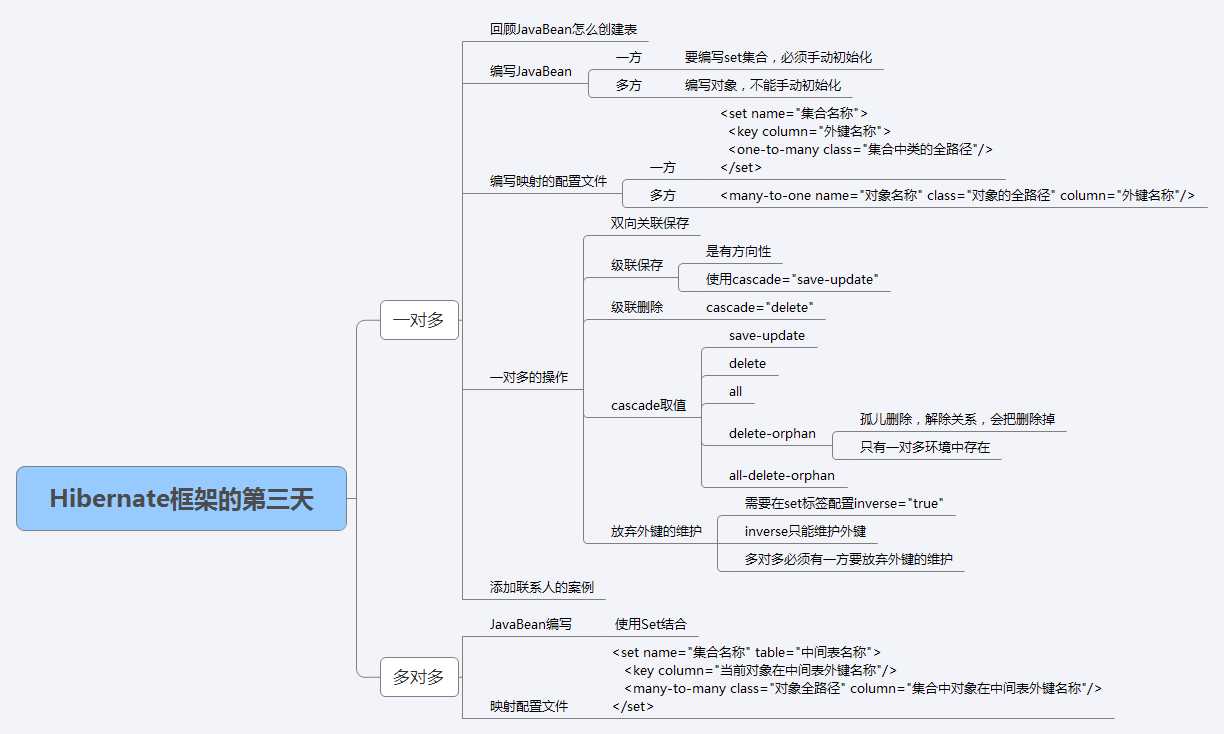
9.1 Hibernate的关联关系映射之一对多映射
编写客户和联系人的JavaBean程序(注意一对多的编写规则)
在一的一方添加set<多的>集合,多的一方添加一的对象
* 客户的JavaBean如下
public class Customer {
private Long cust_id;
private String cust_name;
......
private Set<Linkman> linkmans = new HashSet<Linkman>();
}
* 联系人的JavaBean如下
public class Linkman {
private Long lkm_id;
private String lkm_name;
......
private Customer customer;
}
* 客户的映射配置文件如下
<class name="com.itheima.domain.Customer" table="cst_customer">
<id name="cust_id" column="cust_id">
<generator class="native"/>
</id>
<property name="cust_name" column="cust_name"/>
......
<set name="linkmans">
<key column="lkm_cust_id"/>
<one-to-many class="com.itheima.domain.Linkman"/>
</set>
</class>
* 联系人的映射配置文件如下
<class name="com.itheima.domain.Linkman" table="cst_linkman">
<id name="lkm_id" column="lkm_id">
<generator class="native"/>
</id>
<property name="lkm_name" column="lkm_name"/>
......
<many-to-one name="customer" class="com.itheima.domain.Customer" column="lkm_cust_id"/>
</class>
级联保存:* 级联保存:保存一方同时可以把关联的对象也保存到数据库中!!
* 使用cascade="save-update"
级联删除:注意:级联删除也是有方向性的!! <many-to-one cascade="delete" />
级联的取值(cascade的取值)和孤儿删除
1. 需要大家掌握的取值如下
* none -- 不使用级联
* save-update -- 级联保存或更新
* delete -- 级联删除
* delete-orphan -- 孤儿删除.(注意:只能应用在一对多关系)
* all -- 除了delete-orphan的所有情况.(包含save-update delete)
* all-delete-orphan -- 包含了delete-orphan的所有情况.(包含save-update delete delete-orphan)
2. 孤儿删除(孤子删除),只有在一对多的环境下才有孤儿删除
* 在一对多的关系中,可以将一的一方认为是父方.将多的一方认为是子方.孤儿删除:在解除了父子关系的时候.将子方记录就直接删除。
* <many-to-one cascade="delete-orphan" />
让某一方放弃外键的维护,为多对多做准备
1. 先测试双方都维护外键的时候,会产生多余的SQL语句。
* 想修改客户和联系人的关系,进行双向关联,双方都会维护外键,会产生多余的SQL语句。
* 产生的原因:session的一级缓存中的快照机制,会让双方都更新数据库,产生了多余的SQL语句。
2. 如果不想产生多余的SQL语句,那么需要一方来放弃外键的维护!
* 在<set>标签上配置一个inverse=”true”.true:放弃.false:不放弃.默认值是false
* <inverse="true">
9.1 Hibernate的关联关系映射之多对多映射
双方都添加对方的set集合
多对多进行双向关联的时候:必须有一方去放弃外键维护权
cascade和inverse的区别**
1. cascade用来级联操作(保存、修改和删除)
2. inverse用来维护外键的
10.hibernate annotation注解方式来处理映射关系
1)在hibernate中,通常配置对象关系映射关系有两种,一种是基于xml的方式,另一种是基于annotation的注解方式,在hibernate4以后已经将annotation的jar包集成进来了,如果使用hibernate3的版本就需要引入annotation的jar包。
<!-- 基于annotation的配置 -->
<mapping class="com.xiaoluo.bean.User"/>
<!-- 基于hbm.xml配置文件 -->
<mapping resource="com/xiaoluo/bean/User.hbm.xml"/>
2)
2)注解解析
类上:@Entity ---> 如果我们当前这个bean要设置成实体对象,就需要加上Entity这个注解
@Table(name="t_user") ----> 设置数据库的表名
唯一表示id:
@ID
@GeneratedValue(generator = "xxx")
@GenericGenerator(name = "xxx", strategy = "native")
@GenericGenerator注解配合@GeneratedValue一起使用,@GeneratedValue注解中的"generator"属性要与@GenericGenerator注解中name属性一致,
strategy属性表示hibernate的主键生成策略
基本属性property:
@Column(name="register_date") --->Column中的name属性对应了数据库的该字段名字,里面还有其他属性,例如length,nullable等等
多的一方配置set<1>注解:
@OneToMany(mappedBy="linkmans") ---> OneToMany指定了一对多的关系,mappedBy="linkmans"指定了由多的那一方来维护关联关系,mappedBy指的是多的一方对1的这一方的依赖的属性,(注意:如果没有指定由谁来维护关联关系,则系统会给我们创建一张中间表)
@LazyCollection(LazyCollectionOption.EXTRA) ---> LazyCollection属性设置成EXTRA指定了当如果查询数据的个数时候,只会发出一条 count(*)的语句,提高性能
一的一方配置多的对象注解:
@ManyToOne(fetch=FetchType.LAZY) ---> ManyToOne指定了多对一的关系,fetch=FetchType.LAZY属性表示在多的那一方通过延迟加载的方式加载对象(默认不是延迟加载)
@JoinColumn(name="customer") ---> 通过 JoinColumn 的name属性指定了外键的名称customer(注意:如果我们不通过JoinColum来指定外键的名称,系统会给我们声明一个名称)
标签:*** public -- creat 解决方案 实体 tor _id 同步
原文地址:http://www.cnblogs.com/yiyi16801/p/7461559.html